python第四天学习
python学习
类与对象
类的创建
- 创建类的语法
class 类名:
pass
class Student:
pass
print(id(Student)) # 2373708068384
print(type(Student)) # - 类的组成:
- 类属性
- 实例方法
- 静态方法
- 类方法
class Student:
place = 'China' # 直接写在类里面的变量,称为类属性
def __init__(self, name, age): # 初始化方法
self.name = name # self.name 实例属性
self.age = age # 同样 self.age 也是实例属性
# 实例方法 实例对应于 c++中的对象 在类里面的称方法,在类外面称函数
def eat(self):
print('干饭!')
@classmethod # 用 @classmethod 修饰,则该方法为 类方法
def book(cls):
print('类方法')
@staticmethod # 用 @staticmethod 修饰,则该方法为 静态方法
def walk(): # () 里不能写 self
print('静态方法')
对象的创建
- 对象的创建又叫 类的实例化
- 语法结构:对象 = 类名()
- 意义:有了实例,就可以调用类中的内容
# 需要用到前面创建的 Student 类
# 创建 Student 类的对象
stu1 = Student('wwj', 20)
print(id(stu1)) # 2205897665504
print(type(stu1)) # 之所以能能清楚的创建哪个类的对象,是因为有个类指针指向要创建对象所属的 类
实例属性和实例方法
所创建的对象调用 实例属性 和 实例方法
# 创建 Student 类的对象
stu1 = Student('wwj', 20)
# 调用 实例属性
print(stu1.name) # wwj
print(stu1.age) # 20
# 调用 实例方法 的第一种方式 对象名.实例方法()
stu1.eat() # 干饭!
# 调用 实例方法 的第二种方式 类名.实例方法(所创建的对象)
Student.eat(stu1) # 干饭!
类属性、类方法、静态方法
- 类方法:类中 方法外 的变量称为类属性,被该类的所有对象所共享
stu1 = Student('wwj', 20)
stu2 = Student('sl', 20)
print(Student.place) # China
print(stu1.place) # China
print(stu2.place) # China
Student.place = 'Hunan'
print(Student.place) # Hunan
print(stu1.place) # Hunan
print(stu2.place) # Hunan
# 下面这种情况要特别注意
stu1.place = 'Hengyang'
print(Student.place) # Hunan
print(stu1.place) # Hengyang
print(stu2.place) # Hunan
# 我们发现 只有 stu1.place 是 Hengyang,其他的都是Hunan,注意,这里 stu1 调用的并不是类属性,而是动态绑定了一个属性,关于动态绑定属性后面会有介绍,也就是说stu1.place 指向的是新的一段存储空间。关于类属性的修改,只能通过类名调用类属性去修改
# 我们可以输出一些,就可以发现 stu1.place 的存储空间跟其他二者的存储空间不一致
print(id(Student.place)) # 1375226585456
print(id(stu1.place)) # 1375226554800
print(id(stu2.place)) # 1375226585456
- 类方法:使用@classmethod修饰的方法,使用 类名 直接访问的方法
Student.book() # 类方法
- 静态方法:使用@staticmethod修饰的主法,使用类名直接访问的方法
Student.walk() # 静态方法
本人试了试,发现 类方法 和 静态方法,都可以用 对象来调用,但是 实例方法 不能直接 用类名来调用实例方法,得传入一个 该类所对应的对象
动态绑定属性和方法
- 直接附加
- 动态绑定属性
stu1 = Student('wwj', 20)
stu2 = Student('sl', 20)
stu1.gender = '男'
print(stu1.name, stu1.age, stu1.gender) # wwj 20 男
# print(stu2.name,stu2.age,stu2.gender) AttributeError: 'Student' object has no attribute 'gender'
print(stu2.name, stu2.age) # sl 20
- 动态绑定方法
def func1():
print('动态绑定方法')
stu1 = Student('wwj', 20)
stu2 = Student('sl', 20)
stu1.show = func1 # func1 不用加() 方法名可以不一致,但是最好一致
stu1.show()
# stu2.show() AttributeError: 'Student' object has no attribute 'show'
面向对象的三大特征
封装
- 提高程序的安全性
- 将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度
- 在Python中没有专门的修饰符用于属性的私有,如果该属性(包括类属性和实例属性)不希望在 类的外部 被访问,前边使用两个”_”
- 被两个"_"修饰的属性,在类的外部不能直接被使用,但是还是有方法 可以使用到,格式: _类名__不想被类的外部访问的变量名
stu1 = Student('wwj', 20)
stu2 = Student('sl', 20)
# print(dir(stu1)) 查看stu1所有能够使用的属性和方法
# 对__修饰的属性的访问,一般不会给出代码提示
print(stu1._Student__age) # 20
print(stu1._Student__place) # China
继承
- 提高代码的复用性
- 如果一个类没有继承任何类,则默认继承object
- Python支持多继承
- 定义子类时,必须在其构造函数中调用父类的构造函数
- 语法格式:
class 子类类名(父类1,父类2):
pass
单继承:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name + '的年龄是' + str(self.age))
class Student(Person):
def __init__(self, name, age, stu_no): # 初始化方法
super().__init__(name, age) # super 要加上 () 及要用 super()来调用父类的构造函数
self.stu_no = stu_no
class Teacher(Person):
def __init__(self, name, age, tea_no):
super().__init__(name, age)
self.tea_no = tea_no
stu1 = Student('wwj', 20, 2019001)
tea1 = Teacher('sl', 20, 2019001)
stu1.info()
tea1.info()
多继承:
class A(object):
pass
class B(object):
pass
class C(A, B):
pass
父类方法的重写
- 有时候父类的方法并不能很好的适用于子类所需的情况,子类需要对父类继承下来的方法做出调整
- 如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其(方法体)进行重新编写
- 子类重写后的方法中可以通过super().xxx()调用父类中被重写的方法
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print(self.name + '的年龄是' + str(self.age))
class Student(Person):
def __init__(self, name, age, stu_no): # 初始化方法
super().__init__(name, age) # super 要加上 () 及要用 super()来调用父类的构造函数
self.stu_no = stu_no
# 重写父类方法
def info(self):
# 调用父类的方法
super().info()
print('该学生的学号为:\t', self.stu_no)
class Teacher(Person):
def __init__(self, name, age, tea_no):
super().__init__(name, age)
self.tea_no = tea_no
# 重写父类方法
def info(self):
# 调用父类方法
super().info()
print('该老师的工号为:\t',self.tea_no)
stu1 = Student('wwj', 20, 2019001)
tea1 = Teacher('sl', 20, 2019002)
stu1.info()
'''
wwj的年龄是20
该学生的学号为: 2019001
'''
tea1.info()
'''
sl的年龄是20
该老师的工号为: 2019002
'''
object类
- object类是所有类的父类,因此所有类都有object类的属性和方法
- 内置函数 dir() 可以查看指定对象所有属性和方法
# Object有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str(),经常用于print()方法,即输出对象时,调用的就是__str()__方法,帮我们查看对象的信息,我们也可以对__str__()进行重写
# __str()__ 是有返回值的,返回值为 str 类型
class Student:
def __init__(self, name, age): # 初始化方法
self.name = name
self.age = age
# 重写 object 中的方法,用于 自定义对 对象 的描述
def __str__(self):
return '这名学生的姓名是{0}\t年龄是{1}'.format(self.name, self.age)
stu1 = Student('wwj', 20)
print(stu1)
多态
- 提高程序的可扩展性和可维护性
- 简单地说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
- 有类就有数据类型
class Animal(object):
def eat(self):
print('动物吃食物')
class Dog(Animal):
def eat(self):
print('狗吃肉')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person:
def eat(self):
print('人吃饭')
# 定义一个函数
def func1(obj):
obj.eat()
# 开始调用函数
func1(Animal()) # 动物吃食物
func1(Dog()) # 狗吃肉
func1(Cat()) # 猫吃鱼
# 当然,这个跟多态没有关系
func1(Person()) # 人吃饭
特殊属性和特殊方法
- 特殊属性
# __dict__ 获得类对象或实例对象所绑定的所有属性和方法的字典
# __class__ 查看实例对象所属的 类
# __bases__ 查看 一个类 所有父类 返回一个元组
# __base__ 查看 一个类 的基类,即继承的第一个类
# __mro__ 查看 继承结构
# __subclasses__() 查看 一个类 所有的子类 返回一个列表
class A:
pass
class B:
pass
class C(A, B):
# 定义了一些实例属性
def __init__(self, name, age):
self.name = name
self.age = age
class D(A):
pass
c = C('wwj', 20)
# 查看实例对象的 实例属性字典
print(c.__dict__) # {'name': 'wwj', 'age': 20}
# 查看类属性字典
print(C.__dict__) # {'__module__': '__main__', '__init__': , '__doc__': None}
# 查看实例对象所属的 类
print(c.__class__) # , )
# 查看 C 继承的第一个父类
print(C.__base__) # , ]
'''
a = A()
可以 按住ctrl 点object 进去看 object 的源码
可以发现并没有相关的实例属性
所以 print(a.__dict__) 输出为 {}
但是我们可以发现有一些 __修饰的类属性
所以 print(A.__dict__) 输出为
{'__module__': '__main__', '__dict__': , '__weakref__': , '__doc__': None}
'''
- 特殊方法
# __subclasses__() 查看 一个类 所有的子类 返回一个列表
# __len__() 通过重写_len_()方法,让内置函数len()的参数可以是自定义类型
# __add__() 通过重写_add__()方法,可使用自定义对象具有“+”功能
class Student:
def __init__(self, name):
self.name = name
# 重写这个方法,则该类所对应的对象则可以使用 + 进行运算
def __add__(self, other): # self 表示调用这个方法的对象,other表示传入的同类型的对象
return self.name + other.name
# 重写了这个方法,自定义类所对应的对象就可以求长度
def __len__(self):
# 定义该类的对象的长度 为 名字的长度,使用内置函数 len() 来求字符串的长度
return len(self.name)
stu1 = Student('wwj')
stu2 = Student('sl')
# 两个自定义类的对象相加 第一种方式 注意:没有重写 __add__() 方法,自定义类的对象是不能直接 使用 + 进行运算的
print(stu1 + stu2) # wwjsl
# 两个自定义类的对象相加 第二种方式
print(stu1.__add__(stu2)) # wwjsl
print(stu1.__len__()) # 3
# __new__() 用于创建对象
# __init__() 对创建的对象进行初始化
class Student:
def __new__(cls, *args, **kwargs):
print('__new__()方法被执行,类对象对应的id是:\t{0}'.format(id(cls)))
obj = super().__new__(cls)
print('所创建的对象对应的id为:\t{0}'.format(id(obj)))
return obj # 如果去掉这个 return 则 __init__(self) 不会被执行
def __init__(self, name, age):
print('__init__()方法被执行,实例对象self对应的id为:\t{0}'.format(id(self)))
self.name = name
self.age = age
print('object类对象对应的id为:\t{0}'.format(id(object)))
print('Student类对象对应的id为:\t{0}'.format(id(Student)))
stu1 = Student('wwj', 20)
print('Student对象对应的id为:\t{0}'.format(id(stu1)))
'''
输出结果:
object类对象对应的id为: 140734007594960
Student类对象对应的id为: 2150294680096
__new__()方法被执行,类对象对应的id是: 2150294680096
所创建的对象对应的id为: 2150302101456
__init__()方法被执行,实例对象self对应的id为: 2150302101456
Student对象对应的id为: 2150302101456
'''
'''
输出结果分析:
需要理清程序的执行顺序,
(1)执行 print('object类对象对应的id为:\t{0}'.format(id(object))) 这条语句
得到输出结果 object类对象对应的id为: 140734007594960
(2)执行 print('Student类对象对应的id为:\t{0}'.format(id(Student))) 这条语句
得到输出结果 Student类对象对应的id为: 2150294680096
(3)执行 stu1 = Student('wwj', 20) 这条语句,先执行等号右边,即Student('wwj',20),也就是创建对象,将Student传给 __new__(cls,*args,**kwargs)
方法中的 cls 对象,所以 print('__new__()方法被执行,类对象对应的id是:\t{0}'.format(id(cls))) 输出的结果中的id与 第(2)点一致,输出结果为
__new__()方法被执行,类对象对应的id是: 2150294680096 id都是 2150294680096
然后执行 obj = super().__new__(cls) 利用父类的__new__()创建对象,得到对象 obj,再执行
print('所创建的对象对应的id为:\t{0}'.format(id(obj))) 这条语句,输出结果为: 所创建的对象对应的id为: 2150302101456
然后在 return obj 将创建的对象赋给 __init__(self,name,age) 中的self,所以执行 print('__init__()方法被执行,实例对象self对应的id为:\t{0}'.format(id(self)))
输出结果为 __init__()方法被执行,实例对象self对应的id为: 2150302101456 对应的id与obj的id一致
最后执行 stu1 = Student('wwj', 20) 中的赋值运算,也就是 =
(4)执行 print('Student对象对应的id为:\t{0}'.format(id(stu1))) 语句,输出结果为 Student对象对应的id为: 2150302101456
stu1对应__init__(self):方法中的self,所以 id 也是 2150302101456
'''
类的浅拷贝和深拷贝
class Cpu:
pass
class Disk:
pass
class Computer:
def __init__(self, cpu, disk):
self.cpu = cpu
self.disk = disk
'''
(1) 赋值操作
利用一个变量对象给另一个变量对象赋值,二者对应的内存地址 是一致的
'''
cpu1 = Cpu()
cpu2 = cpu1
print('cpu1的id为:\t{0}'.format(id(cpu1))) # cpu1的id为: 2446832206848
print('cpu2的id为:\t{0}'.format(id(cpu2))) # cpu2的id为: 2446832206848
'''
(2) 浅拷贝
要导入 copy 模块
拷贝得到的对象 = copy.copy(要拷贝的对象)
两个对象对应的内存空间不一致,但是内存空间里面对其他内容的引用是一致的
'''
import copy
disk1 = Disk()
computer1 = Computer(cpu1, disk1)
computer2 = copy.copy(computer1)
print('computer1的情况:\t', computer1, computer1.cpu, computer1.disk)
print('computer2的情况:\t', computer2, computer2.cpu, computer2.disk)
'''
输出结果:
computer1的情况: <__main__.Computer object at 0x00000200854F70A0> <__main__.Cpu object at 0x0000020085518400> <__main__.Disk object at 0x00000200854F7640>
computer2的情况: <__main__.Computer object at 0x0000020085A120A0> <__main__.Cpu object at 0x0000020085518400> <__main__.Disk object at 0x00000200854F7640>
'''
'''
(3) 深拷贝
要导入 copy 模块
拷贝得到的对象 = copy.deepcopy(要拷贝的对象)
两个对象对应的内存空间不一致,内存空间内对其他内容的引用也不一致,但是内容对应的数据是一致的,因为是拷贝嘛
拷贝拷贝,肯定内容的数据是一致的
'''
computer3=copy.deepcopy(computer1)
print('computer1的情况:\t', computer1, computer1.cpu, computer1.disk)
print('computer3的情况:\t', computer3, computer3.cpu, computer3.disk)
'''
输出结果:
computer1的情况: <__main__.Computer object at 0x000001C5953A70A0> <__main__.Cpu object at 0x000001C5953C8400> <__main__.Disk object at 0x000001C5953A7640>
computer3的情况: <__main__.Computer object at 0x000001C595513DF0> <__main__.Cpu object at 0x000001C595642C10> <__main__.Disk object at 0x000001C595642CA0>
'''
模块
- 在Python中一个扩展名为.py的文件就是一个模块
- 使用模块的好处:
- 方便其它程序和脚本的导入并使用
- 避免函数名和变量名冲突
- 提高代码的可维护性
- 提高代码的可重用性
自定义模块
- 创建模块
- 新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同,即不要跟官方的模块重名
- 导入模块
- import 模块名称 [as 别名] [ ] 表示可写 可不写
- 导入该模块下所有的 函数/变量/类
- from 模块名称 import 函数/变量/类
- 导入该模块下指定的 函数/变量/类
- import 模块名称 [as 别名] [ ] 表示可写 可不写
关于数学计算的模块
- math
# 第一种导入方式
import math
print(id(math)) # 2075028989168
print(type(math)) # # 第二种导入方式
from math import pi
import math
# 可直接使用 pi 因为 from math import pi 明确导入 pi
print(pi) # 3.141592653589793
# 注意下面这两者不是同一个方法,一个是内置的pow,一个是math的pow
print(pow(2, 3)) # 8
print(math.pow(2, 3)) # 8.0
导入自定义模块
- 新建.py文件
- 右键改文件所在的文件夹,选择Make Directory as,再选择Sources Root
以主程序形式运行
- 以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__
if __name__ == '__main__':
pass
calc.py
def add(a, b):
return a + b
def sub(a, b):
return a - b
def mul(a, b):
return a * b
def div(a, b):
try:
return a / b
except ZeroDivisionError:
print('除数不能为0!!!')
if __name__ == '__main__':
# 只有运行calc.py文件时,下面这条语句才会被执行
print(add(10, 20))
test.py
import calc
print(calc.add(10,20)) # 30 如果calc.py的 print(add(10, 20)) 没有main修饰,则这里会有两个 30
python的包
- python程序是由多个包组成的,包又由多个模块组成的,模块下面又有函数/变量/类等
- 包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
- 包的作用:
- 代码规范
- 避免模块冲突,即可能存在不同的包下有模块名相同的模块,为了区分,引入了包的概念
- 包和目录的区别:
- 包含_init_.py文件的目录称为包
- 一般我们平常使用的目录/文件夹不包含_init_.py文件
- 包的导入
- import 包名.模块名
- 导入的注意事项:
- 使用 import 方式导入时,import 后面只能接 包名 或 模块名
- 使用from…import…导入时,import 后面可以接 模块名、函数名、变量
- pycharm里面新建包
- 右键项目/包/文件夹,然后New,然后Python Package
python中常用的模块
sys模块
- 与Python解释器及其环境操作相关的标准库
举个例子
# 获取 对象 所占的内存空间大小 getsizeof()
import sys
print(sys.getsizeof(12)) # 28
print(sys.getsizeof(True)) # 28
print(sys.getsizeof('123')) # 52
time模块
- 提供与时间相关的各种函数的标准库
import time
# 返回当前时间的时间戳(1970纪元后经过的浮点秒数) 注意返回的是 秒数
print(time.time())
# 返回的是本地当前的时间
print(time.localtime(time.time()))
os模块
- 提供了访问操作系统服务功能的标准库
calendar模块
- 提供与日期相关的各种函数的标准库
urllib模块
- 用于读取来自网上(服务器)的数据标准库
- 爬虫的时候会用
import urllib.request
# 读取访问百度返回的内容
print(urllib.request.urlopen('http://www.baidu.com').read())
json模块
- 用于使用JSON序列化和反序列化对象
re模块
- 用于在字符串中执行正则表达式匹配和替换
math模块
- 提供标准算术运算函数的标准库
decimal模块
- 用于进行精确控制运算精度、有效数位和四舍五入操作的十进制运算
logging模块
- 提供了灵活的记录事件、错误、警告和调试信息等目志信息的功能
第三方模块安装和使用
第三方模块的安装
- pip install 模块名 这种一般比较慢
- 使用清华源安装会比较快
pip install 模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple
举个例子 安装 schedule 模块 Schedule—实用的周期任务调度工具
pip install schedule -i https://pypi.tuna.tsinghua.edu.cn/simple
第三方模块的使用
Schedule—实用的周期任务调度工具
schedule的使用
import time
import schedule
def job():
print('输出了')
schedule.every(3).seconds.do(job)
while True:
schedule.run_pending() # 启动
print('休眠前', time.localtime(time.time()))
time.sleep(1)
print('休眠后', time.localtime(time.time()))
'''
结果为:
每三秒输出一次 输出了
如果不要 time.sleep(1) 的话,会在短时间内出现很多 休眠前 休眠后
'''
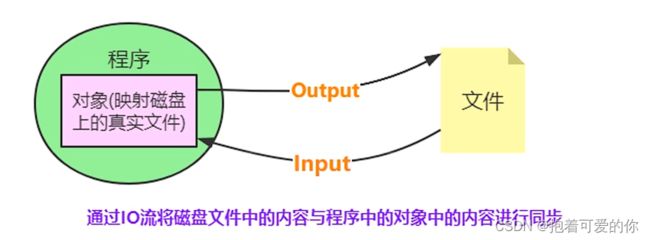
文件的读写原理
- 文件的读写俗称"IO操作"
文件的读写操作
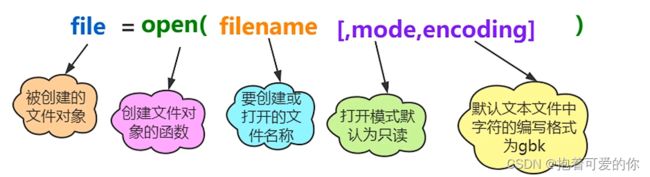
- 使用内置函数 open() 创建文件对象
- 语法规则
# 读操作 read()
file = open('a.txt', 'r',encoding='utf-8') # 如果输出有中文乱码,可以指定解码方式
print(file.readlines())
file.close() # 记住打开了,一定要记得关闭
常见的文件打开模式
- 文件的类型
- 按文件中数据的组织形式,文件分为以下两类:
- 文本文件:存储的是普通“字符”文本,默认为unicode字符集,可以使用记本事程序打开
- 二进制文件:把数据内容用“字节"进行存储,无法用记事本打开,必须使用专用的软件打开,举例: mp3音频文件,jpg图片.doc文档等
- 按文件中数据的组织形式,文件分为以下两类:
| 打开模式 | 描述 |
|---|---|
| r | 以只读模式打开文件,文件的指针将会放在文件的开头 |
| w | 以只写模式打开文件,如果文件不存在则创建,如果文件存在,则覆盖原有内容,文件指针在文件的开头 |
| a | 以追加模式打开文件,如果文件不存在则创建,文件指针在文件开头,如果文件存在,则在文件末尾追加内容,文件指针在原文件末尾 |
| b | 以二进制方式打开文件,不能单独使用,需要与共它模式一起使用,如rb,或者wb |
| + | 以读写方式打开文件,不能单独使用,需要与其它模式一起使用,如a+ |
文本文件的写操作(覆盖形式)
- write()
file = open('a.txt', 'w')
file.write('fighting')
file.close() # 记住打开了,一定要记得关闭
二进制文件的读写操作
file = open('test01.jpg', 'rb')
file_copy=open('copy.jpg','wb')
file_copy.write(file.read())
file.close()
file_copy.close()
文件对象常用的方法
| 方法名 | 说明 |
|---|---|
| read([size]) []表示可写可不写 | 从文件中读取size个字节或字符的内容返回。若省略[size],则读取到文件末尾,即一次读取文件所有内容 |
| readline() | 从文本文件中读取一行内容 |
| readlines() | 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回 |
| write(str) | 将字符串str内容写入文件 |
| writelines(s_list) | 将字符串列表s_list写入文本文件,不添加换行符 |
| seek(offset,[,whence]) []表示可写可不写 | 把文件指针移动到新的位置,offset表示相对于whence的位置: offset:为正表示往结束方向移动,为负表示往开始方向移动 whence不同的值代表不同含义: 0:从文件头开始计算(默认值) 1:从当前位置开始计算 2:从文件尾开始计算 特别要注意文件编码格式,以及中文还是英文,中文在gbk中占两个字节,在utf-8中占3个字节 |
| tell() | 返回文件指针的当前位置 举个例子: 一个文本文件中只有 hello 一个字符串 h对应的位置是0 因为使用read()读完了之后,再调用tell()方法,会输出5,而o已经读完了,指针已经在o后面了,所以o是4,h是0 |
| flush() | 把缓冲区的内容写入文件,但不关闭文件,所以之后可以继续使用write()写内容 |
| close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源 |
with语句(上下文管理器)
- 可以不用手动来关闭资源,即不用再写close()
- 离开with语句就自动关闭资源,避免忘记要关闭资源
- with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
with open('a.txt', 'r', encoding='utf-8') as file:
print(file.read())
with的原理:
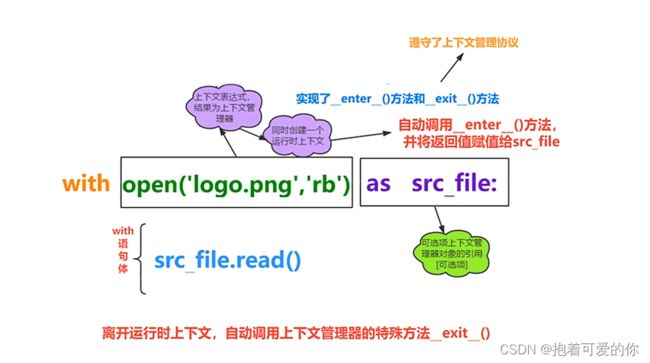
# 一个类 重写了 __enter__() 和 __exit__() 则称该 类对象 遵守 上下文管理器协议
# 该类的实例对象 就称为 上下文管理器 也就是 类名()
# 而 with 后面又得跟一个 上下文管理器 as 后面是别名
class MyTest:
def __enter__(self):
print('__enter__()方法执行...')
return self # 这里必须要 return self,要不然 实例方法中 没有self
# 离开上下文,自动运行该方法,不管是否有异常发生而导致程序终止,下面这个方法都会执行
def __exit__(self, exc_type, exc_val, exc_tb):
print('__exit__()方法执行...')
def testMethod(self):
print('测试方法执行.....')
with MyTest() as test:
test.testMethod()
# 由上可以知道,前面的 with open('a.txt', 'r', encoding='utf-8') as file: 中的 open('a.txt', 'r', encoding='utf-8') 是一个 上下文管理器,实际上就是一个 实例对象
练习题:使用with结构编写图片的复制 代码
with open('test01.jpg', 'rb') as file:
with open('copy.jpg','wb') as copy_file:
copy_file.write(file.read())
os模块
- os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样
- os模块与os.path模块用于对目录或文件进行操作
import os
# os.system() 通过调用一些操作系统的命令来打开一些系统自带的程序
os.system('notepad.exe') # 打开记事本
# os.system('calc.exe') 打开计算器
# os.system('mspaint.exe') 打开画图
# os.startfile() 直接调用本地可执行程序 不一定是 exe文件,mp4、txt、png、jpg等都行
os.startfile(r'D:\虚拟机手动关服务.png')
os模块中操作目录常见的函数
| 函数 | 说明 |
|---|---|
| getcwd() | 获取当前工作目录 |
| listdir(path) | 查看path下的所有文件和文件夹 |
| mkdir(path) | 创建目录 |
| makedirs(path1/path2…) | 创建多级目录 |
| rmdir(path) | 删除目录,注意只能删除空目录,如果该目录下有文件夹或文件,该方法删除目录失败 |
| removedirs(path1/path2…) | 删除多级目录 |
| chdir(path) | 将path设为当前工作目录 |
import os
print(os.getcwd())
# 可以用相对路径 也可以用绝对路径
print(os.listdir(r'../demo01'))
# os.mkdir('new_dir')
# os.makedirs('new_dir1/a/b')
# os.rmdir('new_dir')
# os.removedirs('new_dir1/a/b')
# os.chdir('./new_dir')
# print(os.getcwd())
练习题:获取指定目录下的所有后缀名为 py 的文件(不包括子目录下的 py 文件)
- 使用 endwith(‘后缀名’) 方法
import os.path
path = os.getcwd()
list1 = os.listdir(path)
print(list1)
for filename in list1:
if filename.endswith('.py'):
print(filename)
os.path模块操作目录的相关函数
| 函数 | 说明 |
|---|---|
| abspath(path) | 用于获取目录或文件的绝对路径 |
| exists(path) | 用于判断目录或文件是否存在,存在即为True,不存在即为False |
| join(path,name) | 路径拼接,实际上就是字符串拼接 |
| splitext() | 分离文件名和拓展名 |
| split() | 将路径和文件名分开 |
| basename(path) | 不管传入的路径是否存在,从 路径 中提取 文件名,意思是 不用将路径和文件名分开,而是直接把文件名拿出来 |
| dirname(path) | 不管传入的路径是否存在,从 整个路径里面 中提取 除掉文件名的路径,意思是 不用将路径和文件名分开,而是直接把路径拿出来 |
| isdir(path) | 判断是否是一个路径,该路径必须实际存在 |
import os.path
# 输出 main.py 的绝对路径
print(os.path.abspath('main.py'))
# 判断 文件 或 目录 是否存在
print(os.path.exists('a.txt'), os.path.exists('new_dir1'))
# 路径拼接
print(os.path.join(r'D:\aa\bb', 'abc.txt')) # D:\aa\bb\abc.txt
# 分离 路径 跟 文件名
print(os.path.split(r'D:\aa\bb\abc.txt')) # ('D:\\aa\\bb', 'abc.txt')
# 分离 文件名 和 后缀名
print(os.path.splitext('a.txt')) # ('a', '.txt')
# 不管传入的路径是否存在,从 路径 中提取 文件名,意思是 不用将路径和文件名分开,而是直接把文件名拿出来
print(os.path.basename(r'D:\aa\bb\abc.txt')) # abc.txt
# 不管传入的路径是否存在,从 整个路径里面 中提取 除掉文件名的路径,意思是 不用将路径和文件名分开,而是直接把路径拿出来
print(os.path.dirname(r'D:\aa\bb\abc.txt')) # D:\aa\bb
# 判断是否是一个路径,该路径必须实际存在
# 下面第一和第二条语句的路径是真实存在的,第三条语句是不存在的
print(os.path.isdir(r'D:\python-workspace\Python学习\第一天学习\demo01\main.py')) # False
print(os.path.isdir(r'D:\python-workspace\Python学习\第一天学习\demo01')) # True
print(os.path.isdir(r'D:\aa\bb')) # False
练习题:获取指定目录下的所有后缀名为 py 的文件(包括子目录下的 py 文件)
- walk() 方法 返回类型为元组 遍历指定目录下的文件和目录,遍历完后,在遍历子目录下的目录和文件,直到指定目录下的所有文件夹和文件遍历完
import os
path = os.getcwd()
# 三个参数分别是 文件夹路径 、文件夹名称 、文件名
for dirpath, dirname, filename in os.walk(path):
# print(dirpath)
# print(dirname)
# print(filename)
# print('---------------')
for file in filename:
if file.endswith('.py'):
print(file)