kafka 密码_62.Kafka消息队列订阅发布
参考文档
http://kafka.apachecn.org/
https://www.cnblogs.com/linjiqin/p/11950758.html
https://blog.csdn.net/dayonglove2018/article/details/106925513
https://blog.csdn.net/valada/article/details/80892612
https://www.jianshu.com/p/18d03c6b2931
https://blog.csdn.net/m0_37867405/article/details/80944125
https://blog.csdn.net/godloveayuan/article/details/107361601
https://www.cnblogs.com/listenfwind/p/12465409.html
https://www.jianshu.com/p/23c678e39162
概念
简介
Kafka有四个核心的API:
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic.
- The Consumer API 允许一个应用程序订阅一个或多个 topic,并且对发布给他们的流式数据进行处理.
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换.
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统.比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容.
zookeeper
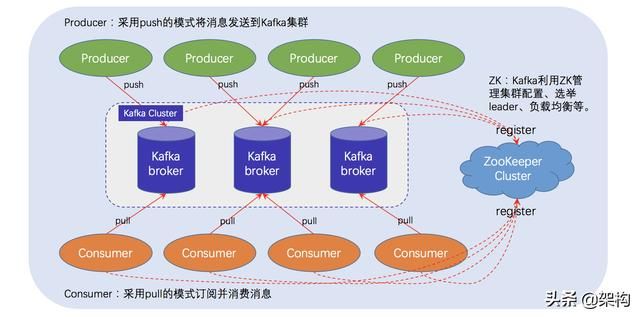
kafka的发送与接收
发送:kafka的发送程序(代码)会指定broker服务地址,那么消息的发送会直接发送到broker提供的地址中.
如果地址是列表(指定了多个broker地址),那么则随机选择一个可用的发送.接收到消息的kafka机器会向zookeeper查询拥有该topic下partition决定权(leader)的机器,然后由该leader选择机器存储数据,最终存储数据.
接收:kafka的接收会指定zookeeper地址,那么接收到消费任务的zookeeper将任务报告给该topic下partition的leader,由该leader指定follower完成数据的获取并返回.
cd /usr/local/etc/kafka# 复制一份cp server.properties server_sasl.propertiesvim server_sasl.properties# 设置broker的唯一标识(集群唯一随便设置).broker.id=0#设置带SASL安全认证的服务监听(域名或者IP修改为机器的正式IP或者域名就好其他照抄)listeners=SASL_PLAINTEXT://192.168.1.159:9092# 使用的认证协议security.inter.broker.protocol=SASL_PLAINTEXT#SASL机制sasl.enabled.mechanisms=PLAINsasl.mechanism.inter.broker.protocol=PLAIN# 完成身份验证的类authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer# 如果没有找到ACL(访问控制列表)配置,则允许任何操作.allow.everyone.if.no.acl.found=true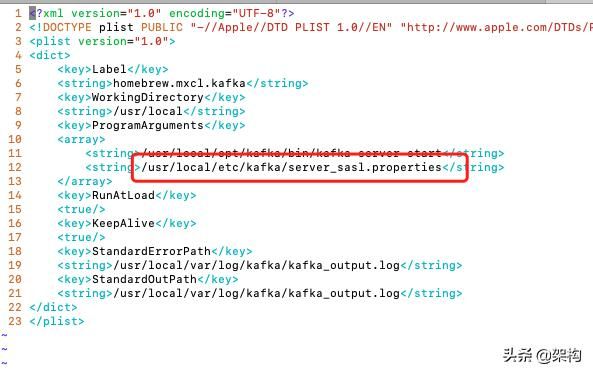
config添加kafka_server_jaas.conf 文件
vi kafka_server_jaas.conf#此文件是服务端 设置用户名和密码KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="kafkaadmin"password="kafkaadminpwd"user_kafkaadmin="kafkaadminpwd"user_kafkaclient1="kafkaclient1pwd"user_kafkaclient2="kafkaclient2pwd";};Client {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="zooclient"password="zooclientpwd";};username/password是给kafka brokers之间作为client初始请求连接访问使用的,会被作为server的broker验证.
user_kafkaadmin这个就是1中提到的连接访问请求验证信息,所以这条是必须的.
user_kafkaclient1/user_kafkaclient2定义了kafka的client,其值就是密码.
Client是把kafka作为client端,访问zookeeper(作为server端)的时候用的.对应的必须在zookeeper里面做相应的配置.
kafka-server-start.sh添加
cd /usr/local/opt/kafka/libexec/binif [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G-Djava.security.auth.login.config=/usr/local/etc/kafka/kafka_server_jaas.conf"fi添加zookeeper_jaas.conf
cd /usr/local/etc/kafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="zooadmin"password="zooadminpwd"user_zooclient="zooclientpwd";};user_zooclient这个用户就是前面kafka_server_jaas.conf里面的Client信息;
这样就对上了:这两个用户名和密码必须一致,作为kafka client和zookeeper server之间认证使用.
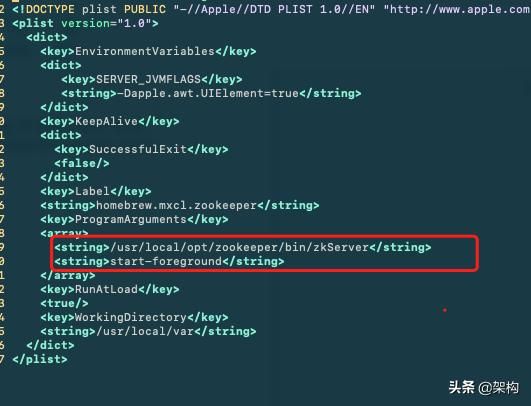
zookeeper-server-start.sh添加
cd /usr/local/opt/kafka/libexec/binif [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G -Djava.security.auth.login.config=/usr/local/etc/kafka/zookeeper_jaas.conf"fi修改brew services 启动文件
cd /usr/local/opt/zookeeper
/usr/local/opt/kafka/bin/zookeeper-server-start/usr/local/etc/kafka/zookeeper.properties直接启动,观察是否有错误
分别启动各个kafka,指定自定义的配置文件,先不要后端启动,观察,日志有没有出错
cd /usr/local/opt/kafka/libexec/./bin/kafka-server-start.sh ./config/server_sasl.properties安装中遇见的问题
- 出现The valid options based on currently configured listeners are PLAINTEXT
查看变红处listeners=SASL_PLAINTEXT://localhost:9092
- 配置错误
KafkaServer{org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="kafka"password="kafka-secret"user_kafka="kafka-secret"user_alice="alice-secret";};逗号的问题
springboot整合
生产者yml中配置
kafka: # 指定kafka server的地址,集群配多个,中间,逗号隔开 bootstrap-servers: localhost:9092 producer: # 写入失败时,重试次数.当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败, # 当retris为0时,produce不会重复.retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失. retries: 0 # 每次批量发送消息的数量,produce积累到一定数据,一次发送 batch-size: 16384 # produce积累数据一次发送,缓存大小达到buffer.memory就发送数据 buffer-memory: 33554432 #procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下: #acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送.在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1. #acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失. #acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置. #可以设置的值为:all, -1, 0, 1 acks: 1 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer ##重要配置## properties: sasl.mechanism: PLAIN security.protocol: SASL_PLAINTEXT sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="kafkaclient1" password="kafkaclient1pwd";kafka: # 指定kafka server的地址,集群配多个,中间,逗号隔开 bootstrap-servers: localhost:9092 consumer: # 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名 group-id: test # 如果Kafka中没有初始偏移量,或者如果当前偏移量在服务器上不再存在(例如,因为该数据已被删除),该怎么办: # earliest最早:自动将偏移量重置为最早的偏移量 # latest最新:自动将偏移重置为最新偏移 # none无:如果未找到消费者组的先前偏移量,则向使用者抛出异常 # anything else其他:向消费者抛出异常. auto-offset-reset: earliest # enable.auto.commit:true --> 设置自动提交offset enable-auto-commit: true #如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000. auto-commit-interval: 1000 # 指定消息key和消息体的编解码方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer ##重要配置## properties: sasl.mechanism: PLAIN security.protocol: SASL_PLAINTEXT sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="kafkaclient2" password="kafkaclient2pwd";更新
kafka更新主要配置的更改
zookeeper可以直接更新而无需其他操作
主题与分区
主题.分区与副本
主题(Topic):
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题,而消费者负责订阅主题进行消费;
分区(Partition):
主题可以分为多个分区,一个分区只属于单个主题;
同一主题下的不同分区包含的消息不同(即,发送给主题的消息具体是发送到某一个分区);
消息被追加到分区日志文件的时候,会分配一个特定的偏移量(offset),offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区的顺序性; offset不跨分区,也就是说Kafka保证的是分区有序而不是主题有序;
副本(Replia):
Kafka为分区引入了多副本机制,通过增加副本数量可以提升容灾能力.
同一个分区的不同副本之间保存的是相同的消息;副本之间是一主多从的关系,其中leader副本负责处理读写请求;follower副本只负责与leader副本的消息同步;
副本处于不同的broker中,当leader副本出现故障时,从follower副本重新选举新的leader副本对外提供服务.
Kafka通过多副本机制实现了故障的自动转移;
多分区与多副本机制
主题和分区是逻辑结构,一个副本对应一个存储消息的日志文件;
分区的多个副本分布在不同的broker上,所以主题和分区都是横跨broker的;
一个主题下对应多个分区,通过增加分区数量可以实现水平扩展,提高性能;
一个分区下有多个副本,通过多副本机制提升容灾能力;
主题正则表达式
topicPattern 为正则表达式主题配置
例子:@KafkaListener(topicPattern = "handle_diag_udsReadDid_.*")
消费者群组
为什么kafka的消费者要有分组的概念
通常一个分区由一个消费者消费,或者说由一个组中的一个消费.
有一种情况,分区数多,且只有一个消费者时,分组的话,消息会被组中唯一一个消费者线性消费,不会发生争抢.因为消息能被组中一个消费者线性消费.
不分组的话会消息都会被消费者拉过去.
删除topic
真删除
server.properties配置delete.topic.enable=true
本文作者:Mr丶Ant (目前单身)