Pytorch深度学习快速入门教程 -- 土堆教程笔记(一)
Pytorch入门学习(一)
- Dataset类
-
- Dataset类的认识
- 针对数据集第一种存放方式的读取
- 针对数据集第二种存放方式的读取
- tensorboard
-
- add_scalar()
- add_image()
- transforms
-
- ToTensor类
- __call__方法
- Normalize类
- Resize类
- Compose类
- RandomCrop类
- torchvision中数据集使用-dataset
-
- 简单使用-下载
- 将torchvision数据集中的每张图片都进行相同的transoforms变换
- dataloader
-
- 简单了解
- 将batch_size修改为64,测试drop_last参数效果
- 测试shuffle参数效果
Dataset类
Dataset类的认识
-
Dataset类是获取数据集中的数据及其label。
-
目标:获取每个数据的信息,获取数据集的大小。
-
jupyter notebook上输入
Dataset??查看官方文档,使用需要注意:- 自定义类需要继承Dataset类
- 重写__init__方法,初始全局变量
- 重写__getitem__方法,返回img和label
- 重写__len__方法,返回长度
针对数据集第一种存放方式的读取
-
数据集第一种存放方式如下:

-
数据读取代码
# 使用Dataset类进行读取数据集
from torch.utils.data import Dataset
import os
from PIL import Image
class MyData(Dataset):
# root_dir:根文件路径
# label_dir:标签文件路径,这里标签文件路径即是标签名
def __init__(self, root_dir, label_dir):
# self的作用:定义全局变量,使其能在不同函数间传递
self.root_dir = root_dir
self.label_dir = label_dir
# 使用os.path.join方法来联接路径,获取图片所在文件夹路径(分为训练和测试)
# 此联接方法优势,针对win和linux不同操作系统,会自动生成不同文件路径符号
self.path = os.path.join(self.root_dir, self.label_dir)
# 使用os.listdir方法获取相应文件间下的子文件名(这里就是图片名),以列表的形式存放
self.img_path_list = os.listdir(self.path)
def __getitem__(self, idx):
# 获取图片的名字,根据列表的下表idx
img_name = self.img_path_list[idx]
# 获取图片的路径
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
# 获取图片信息img
img = Image.open(img_item_path)
# 获取图片标签label
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path_list)
# 实例化MyData类
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
# 利用+号拼接尺寸相同的数据集,按前后顺序拼接
train_dataset = ants_dataset + bees_dataset
img, label = train_dataset[0]
# 显示图片
img.show()
print(label)
针对数据集第二种存放方式的读取
-
数据集第二种存放方式如下:

-
数据读取代码
# 按照数据集存放方式的不同,这里书写Dataset类第二种读取数据方式
import os
from torch.utils.data import Dataset
from PIL import Image
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path_list = os.listdir(self.image_path)
self.label_path_list = os.listdir(self.label_path)
# 因为image和label文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_path_list.sort()
self.label_path_list.sort()
def __getitem__(self, idx):
img_name = self.image_path_list[idx]
label_name = self.label_path_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
return img, label
def __len__(self):
assert len(self.image_path_list) == len(self.label_path_list)
return len(self.image_path_list)
if __name__ == '__main__':
root_dir = "dataset2/train"
ants_image_dir = "ants_image"
ants_label_dir = "ants_label"
train_ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
print("训练数据集中蚂蚁图片张数:{}".format(len(train_ants_dataset)))
bees_image_dir = "bees_image"
bees_label_dir = "bees_label"
train_bees_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
print("训练数据集中蜜蜂图片张数:{}".format(len(train_bees_dataset)))
train_datast = train_ants_dataset + train_bees_dataset
print("训练数据集中总图片张数:{}".format(len(train_datast)))
# 测试
img, label = train_datast[124]
img.show()
print(label)
tensorboard
add_scalar()
- 绘制变量间的关系
from torch.utils.tensorboard import SummaryWriter
# 实例化SummaryWriter类,并且定义事件文件的存储路径和名字logs
writer = SummaryWriter("logs")
# add_scalar()方法有三个参数:
# tag为标题
# scalar_value为y轴变量
# global_step为x轴变量,其余参数默认
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
# 不要忘记关闭
writer.close()
- terminal命令行
tensorboard --logdir=logs --port="8008"- logdir指定事件文件的存储路径
- port指定端口号,不指定的话默认6006
- tensorboard显示如下

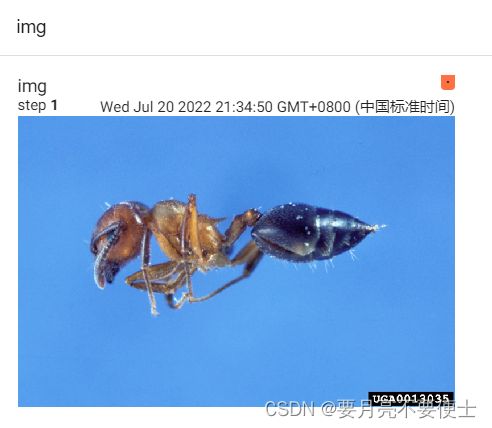
add_image()
- 展示图像情况
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs_image")
# add_images(tag, img_tensor, global_step, walltime, dataformats)方法参数:
# tag为标题
# img_tensor为输入图像,需注意图像的类型是torch.Tensor, numpy.array, or string/blobname,不能是PIL
# dataformats指定图像的shape,默认是(N, 3, H, W),其他类型的NHWC, CHW, HWC, HW, WH, etc.需要专门指定。
image_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
print(type(img_PIL))
# PIL图像类型需要转换成tensor或者array,这里转换成array
img_array = np.array(img_PIL)
print(type(img_array))
# (512, 768, 3)为HWC,需要专门指定dataformats参数
print(img_array.shape)
# global_step为1,指定第1步
writer.add_images("img", img_array, 1, dataformats="HWC")
writer.close()
- 终端命令行
tensorboard --logdir=logs_image - tensorboard显示如下
transforms
ToTensor类
- 将PIL或者numpy图像类型转换成Tensor类型,供神经网络输入需要
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
img_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(img_path) # PIL类型
# 实例化ToTensor类
trans_totensor = transforms.ToTensor()
# ToTensor类的作用:将PIL或者numpy图像类型转换成tensor类型
# 输入是 PIL Image or numpy.ndarray
# 输出就是 tensor image
img_tensor = trans_totensor(img_PIL) # Tensor类型
print(img_tensor.shape) # torch.Size([3, 512, 768])
writer = SummaryWriter("logs")
writer.add_images("Totensor_img", img_tensor, 2, dataformats="CHW")
writer.close()
- tensor图像类型相比于其他类型,含有神经网络训练需要的参数,神经网络的输入图像类型是tensor。

- 网页展示

__call__方法
# 测试__call__(self, args)方法的作用
class Person:
def __call__(self, name):
print("__call__" + "hello" + name)
def hello(self, name):
print("hello" + name)
person = Person()
# 使用__call__方法,直接括号内添加输入变量
person("飞鸿")
# 显示调用和上面隐式写法等价
person.__call__("飞鸿")
# 使用hello方法,需要.
person.hello("飞鸿")
- __forward__方法和__call__方法用法一致,可以直接隐式输入参数。
Normalize类
- 对tensor图像进行归一化,
mean and standard deviation - 计算公式
output[channel] = (input[channel] - mean[channel]) / std[channel]
# Normalize类,输入图像类型是tensor image,进行mean and standard deviation
# output[channel] = (input[channel] - mean[channel]) / std[channel]
import torch
import torchvision
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img_path = "images/pytorch.png"
img_PIL = Image.open(img_path)
# ToTensor
trans_totensor = torchvision.transforms.ToTensor()
img_tensor = trans_totensor(img_PIL)
# 不指定global_step参数,默认就是0,即tensorboard显示时为step 0
writer.add_images("tenosr", img_tensor, dataformats='CHW')
# Normalize
trans_norm = torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
# 不指定global_step参数,默认就是0,即tensorboard显示时为step 0
writer.add_images("norm", img_norm, dataformats='CHW')
writer.close()
- 注意add_images方法中,如果global_step参数不指定,则默认为0,即tensorboard显示时为step 0。
- tensorboard显示

Resize类
# Resize方法,此pytroch版本,对输入图像类型不限制,但低版本可能要求PIL
# 如果输入图像类型时torch,对shape要求时[..., H, W]
# 参数size如果时(h,w),就按照此尺寸进行变换,如果是单个整数int,则图像的最小边为int,另外一边进行等比例变换。
import torchvision
from PIL import Image
img_path = "images/pytorch.png"
img_PIL = Image.open(img_path)
# ToTensor
trans_totensor = torchvision.transforms.ToTensor()
img_tenosr = trans_totensor(img_PIL)
# Resize
# 输入图像类型是tensor,size为(h,w)
print(img_tenosr.shape) # tensor原图像尺寸是torch.Size([3, 364, 701])
trans_resize = torchvision.transforms.Resize([300, 300])
img_tenosr2 = trans_resize(img_tenosr)
print(img_tenosr2.shape) # 裁剪之后,tensor图像尺寸是torch.Size([3, 300, 300])
# 输入图像类型是tensor,size为int
print(img_tenosr.shape) # tensor原图像尺寸是torch.Size([3, 364, 701])
trans_resize = torchvision.transforms.Resize(182)
img_tensor3 = trans_resize(img_tenosr)
print(img_tensor3.shape) # 裁剪之后,tensor图像尺寸是torch.Size([3, 182, 350])
# 输入图像类型是PIL,size为(h,w)
print(img_PIL) # PIL原图像尺寸是701x364
trans_resize = torchvision.transforms.Resize([300, 300])
img_PIL2 = trans_resize(img_PIL)
print(img_PIL2) # 裁剪之后,PIL图像尺寸是300*300
# 如果add_images显示,需要再转换成tensor类型
img_PIL3 = trans_totensor(img_PIL2)
print(img_PIL3.shape) # torch.Size([3, 300, 300])
Compose类
- 可以组合一系列transforms变换
- 我们想要实现对PIL image,先裁剪成(300,300)的尺寸,再转换成tensor类型
# 实现一系列transforms变换的组合
# 实现对PIL image,先裁剪成(300,300)的尺寸,再转换成tensor类型
import torchvision
from PIL import Image
from torchvision import transforms
img_path = "images/pytorch.png"
img = Image.open(img_path)
# Resize
trans_resize = torchvision.transforms.Resize((300,300))
# ToTensor
trans_totensor = torchvision.transforms.ToTensor()
# Compose
trans_compose = torchvision.transforms.Compose([trans_resize, trans_totensor])
print(img) # - 注意点:
- 需要注意的一点是compose的输入图像类型需要和第一个transforms变换的输入图像类型一致,这里就是和ToTensor()输入图像类型一致。
- 第一个transforms变换的输出图像类型和第二个transforms变换的输入图像类型一致,当多个transforms变换时,以此类推。
RandomCrop类
- 随机裁剪,此版本同样对输入图像类型不限制
- size若为(h, w),则原图像尺寸就按照此变换。若为int,则原图像尺寸就变换为(int, int)
# RandomCrop 随机裁剪,此版本同样对输入图像类型不限制
# size若为(h, w),则原图像尺寸就按照此变换。若为int,则原图像尺寸就变换为(int, int)
import torchvision
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
img_path = "images/pytorch.png"
img = Image.open(img_path) # - tensorboard显示

torchvision中数据集使用-dataset
简单使用-下载
- 以CIFAR10为例
# 使用torchvision提供的数据集CIFAR10
import torchvision
# 参数root代表下载的数据集存放路径
# 参数train为True,代表下载的为训练集;为False,代表下载的为测试集。
# 参数download为True,代表在网上下载,并且放到root下;为Falsse,代表本地已经下载好,不需要再下载。
train_dataset = torchvision.datasets.CIFAR10("./dataset", train=True, download=True)
test_dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True)
print(test_dataset[0])
# (, 3)
print(test_dataset.classes)
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
img, target = test_dataset[0]
print(img) # - 如果网上下载的数据集速度比较慢,可以复制下载链接通过迅雷等途径下载到本地,存放到root路径下。
- 下载链接在如下位置:

- 下载链接在如下位置:
将torchvision数据集中的每张图片都进行相同的transoforms变换
- 参数transform
# 对torchvision数据集中的每张图片都进行transforms变换
import torchvision
# 使用参数transform,将CIFAR10中所有图片的类型由PIL变换为tensor。
from torch.utils.tensorboard import SummaryWriter
train_dataset = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()]), download=True)
test_dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()]), download=True)
print(test_dataset[0])
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_dataset[i]
# 由于img的shape是(3, H, W)的形式,需要专门指定dataformats参数
writer.add_images("test_img", img, i, dataformats='CHW')
writer.close()
- tensorboard显示

dataloader
简单了解
- 将数据加载到神经网络中
- 相当于从一副牌中,是一次性摸两张牌,还是一次性摸四张牌,由其参数
batch_size决定 - 参数batch_size 每一次性(batch)取多少样本(samples),即一次性摸几张牌
- 参数shuffle 代表第一轮牌打完了,开始洗牌,第二轮的牌堆顺序和第一轮的牌堆顺序是否一样,为True代表打乱,为False,代表不打乱。
- 参数num_workers 程序运行时是采用多进程还是单进程,默认为0,采用主线程
- 参数drop_last,牌堆中共有100张牌,每次摸3张牌,剩余1张牌是丢弃,还是不丢弃,True丢弃,False不丢弃
- 采样时,随机采样
- 若writer显示dataloader打包的数据包,采用writer.add_images(),而非writer.add_image()
# 参数dataset
# 参数batch_size 每一次性(batch)取多少样本(samples),即一次性摸几张牌
# 参数shuffle 代表第一轮牌打完了,开始洗牌,第二轮的牌堆顺序和第一轮的牌堆顺序是否一样,为True代表打乱,为False,代表不打乱。
# 参数num_workers 程序运行时是采用多进程还是单进程,默认为0,采用主线程
# 参数drop_last,牌堆中共有100张牌,每次摸3张牌,剩余1张牌是丢弃,还是不丢弃,True丢弃,False不丢弃
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()]), download=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中的第一张图片及target
img, target = test_dataset[0]
print(img.shape) # torch.Size([3, 32, 32])
print(target) # 3
# dataloader按顺序打包dataset中的四个数据
# img0, target0 = dataset[0]
# img1, target1 = dataset[1]
# img2, target2 = dataset[2]
# img3, target3 = dataset[3]
# 将img0,img1,img2,img3单独打包imgs,将target0,target1,target2,target3单独打包targets,作为dataloader中的返回
# 怎么取出dataloader中的数据包呢,采用for循环
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
print(imgs.shape) # torch.Size([4, 3, 32, 32]) 代表4张图片(batch_size为4),每张图片为3通道,h为32,w为32
# 需要注意的是dataloader每次从dataset中抓取4张图片,是随机抓取的。sampler采样器为randomSampler
print(targets) # tensor([7, 4, 2, 6])
# 由于imgs是多张图片打包,所以采用add_images,而非add_image
writer.add_images("test_data", imgs, step) #这里imgs的shape为NCHW形式,不需要指定dataformats
step = step + 1
writer.close()
- tensorboard显示

将batch_size修改为64,测试drop_last参数效果
- drop_last为False,有剩余图片不丢弃

- drop_last参数为True,剩余图片丢弃
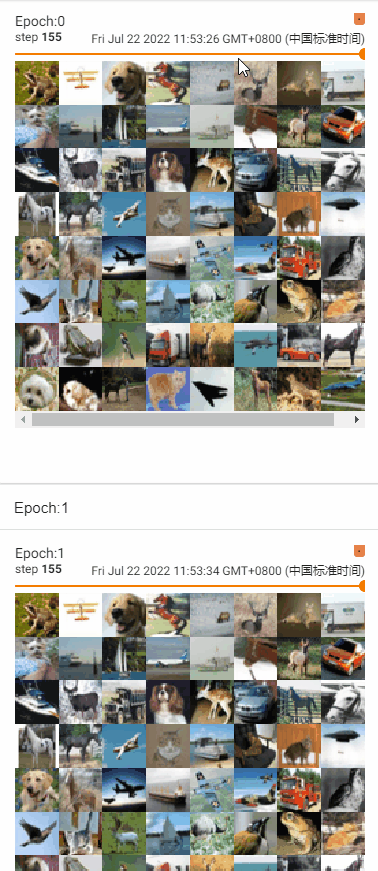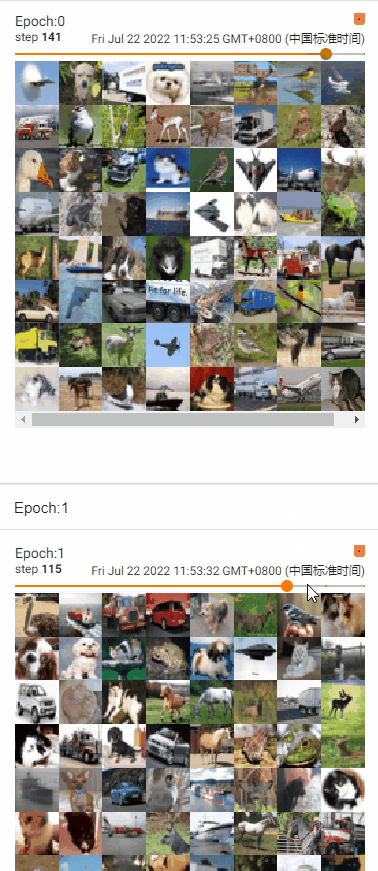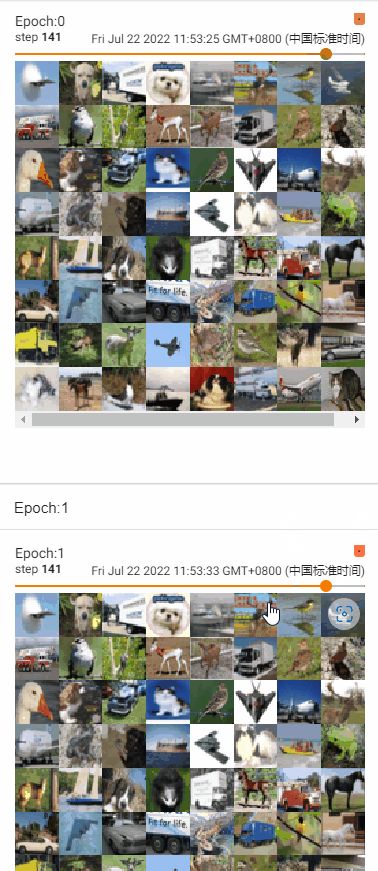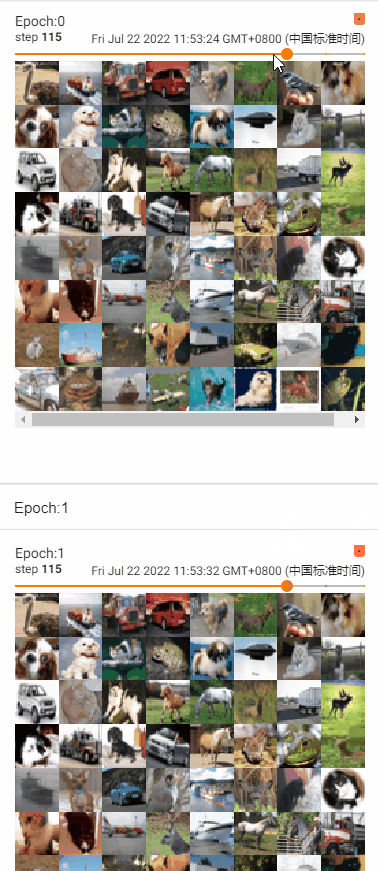
测试shuffle参数效果
- shuffle = False,不改变牌堆顺序
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()]), download=True)
# 参数shuffle=False时,不改变牌堆顺序,每轮(epoch)中每batch获取的图片都一样
# 建议shuffle=True,打乱牌堆顺序
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False, num_workers=0, drop_last=True)
# 测试数据集中的第一张图片及target
img, target = test_dataset[0]
print(img.shape) # torch.Size([3, 32, 32])
print(target) # 3
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()
- shuffle = True,改变牌堆顺序
- 训练过程中,采用shuffle=True
