【Attention机制】YOLOX模型改进之(SE模块、ECA模块、CBAM模块)的添加
文章目录
- YOLOX模型改进
-
- 模块简介
-
- SE模块
-
- SE模块的具体介绍
- 插入位置
- 主要代码
- CBAM模块
-
- 插入位置
- 主要代码
- 目的动机
- ECA模块
-
- 插入位置
- 主要代码
- 模块添加
-
- 建立attention.py
- 修改yolo_pafpn.py文件
- 图解展示
YOLOX模型改进
模块简介
SE模块
-
论文地址:https://arxiv.org/pdf/1709.01507.pdf
-
官方代码地址:https://github.com/hujie-frank/SENet
-
Pytorch代码地址:https://github.com/moskomule/senet.pytorch
SE模块显式地建模特征通道之间的相互依赖关系,通过采用了一种全新的“特征重标定”策略–自适应地重新校准通道的特征响应

SE模块并未改变原有图像的维度与尺寸,因此可以即插即用。
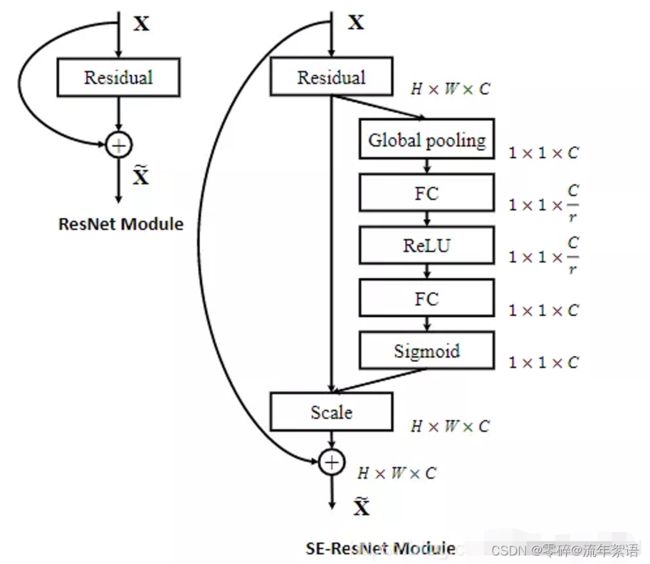
SE模块的具体介绍
- Sequeeze:顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野。具体操作就是对原特征图C * W * H 进行global average pooling,然后得到了一个 1 * 1 * C 大小的特征图,这个特征图具有全局感受野。
- Excitation:输出的1x1xC特征图,再经过两个全连接神经网络,最后用一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性(论文中使用的是sigmoid)。
- 特征重标定:使用Excitation
得到的结果作为权重,然后通过乘法逐通道加权到U的C个通道上,完成在通道维度上对原始特征的重标定,并作为下一级的输入数据。
插入位置
可以插入至每个block的后面。
这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
SENet 通俗的说就是:通过对卷积之后得到的feature map进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将改动之后的分数通过乘法逐通道加权到原来对应的通道上,最后得到输出结果,就相当于在原有的基础上只添加了一个模块而已。
主要代码
import torch
import torch.nn as nn
import math
# SE注意力机制
class SE(nn.Module):
def __init__(self, channel, ratio=16):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
CBAM模块
- 论文地址:https://arxiv.org/pdf/1807.06521.pdf
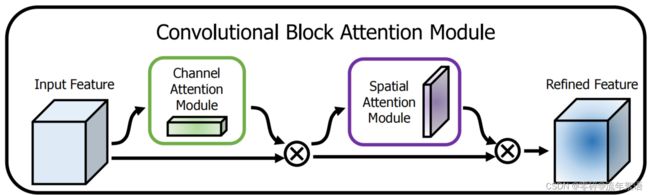
插入位置
可以插入在backbone中的每个block结束位置。
主要代码
import torch
import torch.nn as nn
class CBAM(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(CBAM, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x*self.channelattention(x)
x = x*self.spatialattention(x)
return x
目的动机
- 由于每个feature map相当于捕获了原图中的某一个特征,channel attention有助于筛选出有意义的特征,即告诉CNN原图哪一部分特征具有意义(what)
- 由于feature map中一个像素代表原图中某个区域的某种特征,spatial attention相当于告诉网络应该注意原图中哪个区域的特征(where)
ECA模块
- 代码地址:https://github.com/BangguWu/ECANet
- 论文地址:https://arxiv.org/pdf/1910.03151.pdf
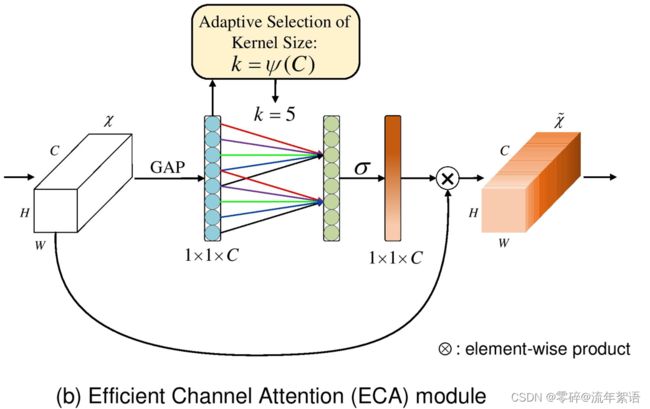
插入位置
可以插入至每个block的后面。
主要代码
import torch
import torch.nn as nn
import math
class ECA(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(ECA, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
print("kernel_size:",kernel_size)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
模块添加
建立attention.py
在目录YOLOX-main\yolox\models下建立attention.py,内容包含所有的模块代码。
import torch
import torch.nn as nn
import math
# SE注意力机制
class SE(nn.Module):
def __init__(self, channel, ratio=16):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
# CBAM注意力机制
class CBAM(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(CBAM, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x*self.channelattention(x)
x = x*self.spatialattention(x)
return x
### ECA注意力机制
class ECA(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(ECA, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
修改yolo_pafpn.py文件
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) 2014-2021 Megvii Inc. All rights reserved.
import torch
import torch.nn as nn
from .darknet import CSPDarknet
from .network_blocks import BaseConv, CSPLayer, DWConv
from .attention import CBAM, SE, ECA # 1、导入注意力机制模块
class YOLOPAFPN(nn.Module):
"""
YOLOv3 model. Darknet 53 is the default backbone of this model.
"""
def __init__(
self,
depth=1.0,
width=1.0,
in_features=("dark3", "dark4", "dark5"),
in_channels=[256, 512, 1024],
depthwise=False,
act="silu",
):
super().__init__()
self.backbone = CSPDarknet(depth, width, depthwise=depthwise, act=act)
self.in_features = in_features
self.in_channels = in_channels
Conv = DWConv if depthwise else BaseConv
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.lateral_conv0 = BaseConv(
int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act
)
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
) # cat
self.reduce_conv1 = BaseConv(
int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act
)
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv2 = Conv(
int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act
)
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv1 = Conv(
int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act
)
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
### 2、在dark3、dark4、dark5分支后加入CBAM ECA模块(该分支是主干网络传入FPN的过程中)
### in_channels = [256, 512, 1024],forward从dark5开始进行,所以cbam_1或者eca_1为dark5
# self.cbam_1 = CBAM(int(in_channels[2] * width)) # 对应dark5输出的1024维度通道
# self.cbam_2 = CBAM(int(in_channels[1] * width)) # 对应dark4输出的512维度通道
# self.cbam_3 = CBAM(int(in_channels[0] * width)) # 对应dark3输出的256维度通道
# 使用时,注释上面或者下面的代码
self.eca_1 = ECA(int(in_channels[2] * width)) # 对应dark5输出的1024维度通道
self.eca_2 = ECA(int(in_channels[1] * width)) # 对应dark4输出的512维度通道
self.eca_3 = ECA(int(in_channels[0] * width)) # 对应dark3输出的256维度通道
def forward(self, input):
"""
Args:
inputs: input images.
Returns:
Tuple[Tensor]: FPN feature.
"""
# backbone
out_features = self.backbone(input)
features = [out_features[f] for f in self.in_features]
[x2, x1, x0] = features
# 3、直接对输入的特征图使用注意力机制
# x0 = self.cbam_1(x0)
# x1 = self.cbam_2(x1)
# x2 = self.cbam_3(x2)
# 使用时,注释上面或者下面的代码
x0 = self.eca_1(x0)
x1 = self.eca_2(x1)
x2 = self.eca_3(x2)
fpn_out0 = self.lateral_conv0(x0) # 1024->512/32
f_out0 = self.upsample(fpn_out0) # 512/16
f_out0 = torch.cat([f_out0, x1], 1) # 512->1024/16
f_out0 = self.C3_p4(f_out0) # 1024->512/16
fpn_out1 = self.reduce_conv1(f_out0) # 512->256/16
f_out1 = self.upsample(fpn_out1) # 256/8
f_out1 = torch.cat([f_out1, x2], 1) # 256->512/8
pan_out2 = self.C3_p3(f_out1) # 512->256/8
p_out1 = self.bu_conv2(pan_out2) # 256->256/16
p_out1 = torch.cat([p_out1, fpn_out1], 1) # 256->512/16
pan_out1 = self.C3_n3(p_out1) # 512->512/16
p_out0 = self.bu_conv1(pan_out1) # 512->512/32
p_out0 = torch.cat([p_out0, fpn_out0], 1) # 512->1024/32
pan_out0 = self.C3_n4(p_out0) # 1024->1024/32
outputs = (pan_out2, pan_out1, pan_out0)
return outputs
图解展示
