记录自己使用循环神经网络对天气进行预测的过程
本次实验中使用到的数据来自链接: http://www.tianqihoubao.com/lishi/,选择的城市是广西来宾,将会用到2011年至2021年的数据,机器学习的框架是tensorflow2.3.0。
1.数据爬取
首先我们得把数据抓取下来,这里将用到python爬虫中最常见的requests库和BeautifulSoup库,下面是数据爬取的craw.py
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import re
def data_list(numpy):
z = []
for i in numpy:
if i.string is not None:
z.append(i.string)
for m, n in enumerate(z):
z[m] = n.replace('\n', '').replace(' ', '')
return z
class Grab:
def __init__(self, url):
self.url = url
self.header = {'User-Agent': r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
r'like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'}
def analysis(self):
for i in range(3):
try:
resp = requests.get(url=self.url, headers=self.header,
proxies=None, timeout=(3, 7))
if resp.status_code == 200:
break
except:
print('请求超时!')
resp.encoding = 'gbk'
html = BeautifulSoup(resp.text, 'html5lib')
return html
def location(self, str1):
text = self.analysis()
data = text.find_all(str1)
return data
def data(self):
data = self.location('td')
data = data_list(data)
data = np.array(data).reshape(-1, 3)
data_date = self.date()
data = np.c_[data_date, data]
print(data)
return data
def date(self):
date = self.location('a')
date = data_list(date)
data_str = ''.join(date)
date = re.findall(r'\d\d\d\d年\d\d月\d\d日', data_str)
return date
if __name__ == "__main__":
flag = 0
for i in range(2011, 2021 + 1):
for j in range(1, 13):
ur = r'http://www.tianqihoubao.com/lishi/laibin/month/{}{:0>2}.html'.format(i, j)
a = Grab(ur)
b = a.data()
if flag == 0:
weather = b.copy()
flag += 1
else:
weather = np.r_[weather, b]
if i == 2022:
if j == 5:
break
c = ['日期', '天气', '气温', '风力风向']
df = pd.DataFrame(data=weather, columns=c)
df.to_csv('data.csv', header=True, index=False, encoding='gbk')
下面说一下思路:
这个网站对于每一个月的数据都会做成一个网页,而且格式也是固定的形式,这样我们只需要两个for循环就能得到所有想要的网页网址

for i in range(2011, 2021 + 1):
for j in range(1, 13):
ur = r'http://www.tianqihoubao.com/lishi/laibin/month/{}{:0>2}.html'.format(i, j)
format是格式化输入,用于控制输入的年份和月份,由于有些月份前面会带一个0,所以这里使用了{:0>2}来让每个数字都左对齐两位。
下面进入到Grab类,初始化从循环中得到的网址和请求头。
def __init__(self, url):
self.url = url
self.header = {'User-Agent': r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
r'like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'}
请求头可以去百度一下常用的即可。
接下来就是请求访问了,调用requests库中的get方法(这里由于这个网址有时会请求失败导致一直卡住,所以设置了一个for循环来多次进行请求访问),get中timeout=(3,7)表示连接时间为3,响应时间为7,使用得当可以提高访问速度,节省时间。resp.status_code根据自己实际访问的网页来填写,编码使用汉字最常见的gbk,最终再使用BeautifulSoup根据html5lib格式来解析即可得到一个类似其实就是 json格式的文本。
def analysis(self):
for i in range(3):
try:
resp = requests.get(url=self.url, headers=self.header,
proxies=None, timeout=(3, 7))
if resp.status_code == 200:
break
except:
print('请求超时!')
resp.encoding = 'gbk'
html = BeautifulSoup(resp.text, 'html5lib')
return html
将得到的文本复制到记事本里分析一下

想要的数据的标签都在td里,但是时间轴却在a里。那我们先对数据动手,为了方便下面多次访问不同的标签,写了一个可以多次调用的访问函数
def location(self, str1):
text = self.analysis()
data = text.find_all(str1)
return data
下面寻找td标签下的所有数据
def data(self):
data = self.location('td')
data = data_list(data)
data = np.array(data).reshape(-1, 3)
data_date = self.date()
data = np.c_[data_date, data]
print(data)
return data
这里还调用了一个data_list函数,是为了把所有的数据字符串提取出并且去掉空内容和换行符。这样我们会得到一个装了所有数据的列表,由于每个样本的数据都是3列,这里直接就可以创建一个数组再重新塑形就能得到想要的样子:
还得想办法把日期也放进去,因此创建了一个date函数来将日期抓取下来:
def date(self):
date = self.location('a')
date = data_list(date)
data_str = ''.join(date)
date = re.findall(r'\d\d\d\d年\d\d月\d\d日', data_str)
return date
同样的也是也先调用访问函数,然后再调用data_list函数得到一个装满时间数据的列表,和气象数据不同的是还有很多不需要的数据:

这里我的做法是使用join将列表中的字符串拼接成一个字符串,再使用re库中的findall函数正则匹配\d\d\d\d年\d\d月\d\d日型的字符串,这样就能将这个月的时间都装进一个列表了(其实这里的时间有一个更明确的标签 ):如果使用for加格式化输入遍历应该也能得到,但是我嫌还要处理不同的2月天数就放弃了

然后再看回data函数,直接使用c_将气象数据和天气数据合在一起,最终就将一个月的数据得到了:
至此主函数中的a = Grab(ur) b = a.data()也执行完毕,下面就是将每个月的数组纵向拼接在一起,最终创建一个datafarme将其保持为csv文件方便后续的使用。
2.数据预处理
一个机器学习的过程,可能有80%的时间在进行数据预处理,有19%的时间在埋怨数据的不足之处,还有1%在训练模型。对于这个天气数据我就不得不想吐槽数据也太少了,如果后面用5天来预测一天的天气,数据可能就几百行,更别说这么多种天气,还基本没有什么周期性,就用天气,温度和风向风级来预测好像确实会有一点点离谱,而且该数据的风向风级在2017年之前几乎都是北风小于等于3级。
用于数据预处理的data.py
由于数据量的大小,所以觉得并不需要用生成器。
import numpy as np
import pandas as pd
from collections import Counter
import matplotlib.pyplot as plt
import re
def Get_label_dict(y):
dict_l = {}
for i, j in enumerate(y):
dict_l[j] = i
return dict_l
def F(matrix, num):
results = np.zeros((len(matrix), num))
for i, j in enumerate(matrix):
results[i, j] = 1
return results
def load_data(data_dir):
weather_data = Weather(data_dir).pre()
data = (weather_data.loc[:, ['白天天气', '夜间天气', '最高温度', '最低温度', '白天风力风向', '夜间风力风向', '白天风级', '夜间风级']]).to_numpy()
label = weather_data['白天天气'].to_numpy()
train = data[:1].reshape(-1, 1, data.shape[-1])
train_label = label[1]
for i in range(2, data.shape[0], 2):
index = i + 1
if index >= data.shape[0]:
break
else:
train = np.r_[train, data[i:index].reshape(-1, 1, data.shape[-1])]
train_label = np.r_[train_label, label[index]]
train_label = F(train_label, 13).astype('float32')
# mean = np.mean(train, axis=0)
# std = np.std(train, axis=0)
# train = (train - mean) / std
return train, train_label
class Weather:
def __init__(self, file_dir):
self.data = pd.read_csv(file_dir, encoding='gbk')
def pre(self):
col = ['天气', '气温', '风力风向']
list_col = ['白天天气', '夜间天气', '最高温度', '最低温度', '白天风力风向', '夜间风力风向', '白天风级', '夜间风级']
q = 0
for i, j in enumerate(col):
new_data = self.data[j].str.split('/', 1, True)
new_data.columns = [list_col[q], list_col[q + 1]]
q += 2
self.data = self.data.drop([j], axis=1).join(new_data)
self.data['日期'] = self.data['日期'].apply(lambda x: x.replace('年', '-').replace('月', '-').replace('日', ''))
self.data['日期'] = pd.to_datetime(self.data['日期'])
self.data['最高温度'] = self.data['最高温度'].apply(lambda x: int(x.replace('℃', '')))
self.data['最低温度'] = self.data['最低温度'].apply(lambda x: int(x.replace('℃', '')))
weather_c = Counter(self.data['白天天气'])
weather_dict = Get_label_dict(weather_c)
self.data['白天天气'] = self.data['白天天气'].apply(lambda x: weather_dict[x])
self.data['夜间天气'] = self.data['夜间天气'].apply(lambda x: weather_dict[x])
self.data['白天风力风向'] = self.data['白天风力风向'].str.replace('微风', '3级')
self.data['白天风级'] = self.data['白天风力风向'].apply(lambda x: x.replace(re.findall('[\u4e00-\u9fa5]+', x)[0], ''))
wind_level_c = Counter(self.data['白天风级'])
wind_level_dict = Get_label_dict(wind_level_c)
self.data['白天风级'] = self.data['白天风级'].apply(lambda x: wind_level_dict[x])
self.data['白天风力风向'] = self.data['白天风力风向'].apply(lambda x: re.findall('[\u4e00-\u9fa5]+', x)[0])
wind_direction_c = Counter(self.data['白天风力风向'])
wind_direction_dict = Get_label_dict(wind_direction_c)
self.data['白天风力风向'] = self.data['白天风力风向'].apply(lambda x: wind_direction_dict[x])
self.data['夜间风力风向'] = self.data['夜间风力风向'].str.replace('微风', '3级')
self.data['夜间风级'] = self.data['夜间风力风向'].apply(lambda x: x.replace(re.findall('[\u4e00-\u9fa5]+', x)[0], ''))
wind_level_c = Counter(self.data['夜间风级'])
wind_level_dict = Get_label_dict(wind_level_c)
self.data['夜间风级'] = self.data['夜间风级'].apply(lambda x: wind_level_dict[x])
self.data['夜间风力风向'] = self.data['夜间风力风向'].apply(lambda x: re.findall('[\u4e00-\u9fa5]+', x)[0])
wind_direction_c = Counter(self.data['夜间风力风向'])
wind_direction_dict = Get_label_dict(wind_direction_c)
self.data['夜间风力风向'] = self.data['夜间风力风向'].apply(lambda x: wind_direction_dict[x])
df = self.data
return df
# def str_vector(self):
# wind = self.pre()['白天风力风向'].to_list()
# wind_str = []
# wind_str_dict = {}
# data_str = []
# for i, j in enumerate(wind):
# medium = []
# medium.extend(j)
# wind_str.extend(j)
# data_str.append(medium)
# wind_str = set(wind_str)
# for m, n in enumerate(wind_str):
# wind_str_dict[n] = m
# result = np.zeros((4022, 40))
# for z, x in enumerate(data_str):
# for v in x:
# result[z, wind_str_dict[v]] = 1
# return result
我们先将白天夜间天气,风向风级以及最高最低温度分开来:
def pre(self):
col = ['天气', '气温', '风力风向']
list_col = ['白天天气', '夜间天气', '最高温度', '最低温度', '白天风力风向', '夜间风力风向', '白天风级', '夜间风级']
q = 0
for i, j in enumerate(col):
new_data = self.data[j].str.split('/', 1, True)
new_data.columns = [list_col[q], list_col[q + 1]]
q += 2
self.data = self.data.drop([j], axis=1).join(new_data)
print(self.data)
然后我们可以查看一下温度情况(下面的图是基于已经预处理完的数据):
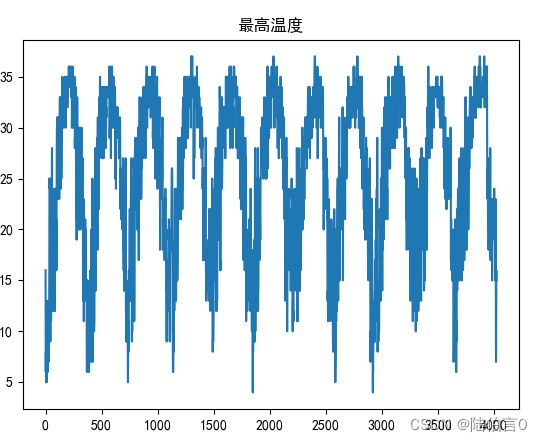
如果这是一个温度回归预测,那么我们甚至只用温度的数据都能预测出未来的温度,可惜这是一个天气分类问题,天气就没有这么好的规律了:
下面继续对数据进行处理,日期随便处不处理,将温度后面的符号去掉:
self.data['日期'] = self.data['日期'].apply(lambda x: x.replace('年', '-').replace('月', '-').replace('日', ''))
self.data['日期'] = pd.to_datetime(self.data['日期'])
self.data['最高温度'] = self.data['最高温度'].apply(lambda x: int(x.replace('℃', '')))
self.data['最低温度'] = self.data['最低温度'].apply(lambda x: int(x.replace('℃', '')))
天气的话使用collections库下的Counter
来统计所有出现过的天气,然后将这些天气进行编号来代替字符。
weather_c = Counter(self.data['白天天气'])
print(weather_c)
weather_dict = Get_label_dict(weather_c)
print(weather_dict)
self.data['白天天气'] = self.data['白天天气'].apply(lambda x: weather_dict[x])
self.data['夜间天气'] = self.data['夜间天气'].apply(lambda x: weather_dict[x])
![]()
Get_label_dict是我写的一个函数,用于编号(摆烂 ),返回的是一个字典
def Get_label_dict(y):
dict_l = {}
for i, j in enumerate(y):
dict_l[j] = i
return dict_l
风向风力也是最难处理的地方,首先查看一下具体情况
print(Counter(self.data['白天风力风向']))
发现风级除微风外都是数字,微风也就是3级风,那么将微风用3级来代替。然后将风向和风级分开,这里我再次使用了re库中的findall将’白天风力风向’这个字段中的非中文提取出来成为一个全新的列,然后使用Get_label_dict函数用编号来代替出现的风级(应该会有更好的处理方法,但是摆烂,上文中其实有一个用于向量化风向风级文本的函数def str_vector() )
self.data['白天风力风向'] = self.data['白天风力风向'].str.replace('微风', '3级')
self.data['白天风级'] = self.data['白天风力风向'].apply(lambda x: x.replace(re.findall('[\u4e00-\u9fa5]+', x)[0], ''))
wind_level_c = Counter(self.data['白天风级'])
wind_level_dict = Get_label_dict(wind_level_c)
self.data['白天风级'] = self.data['白天风级'].apply(lambda x: wind_level_dict[x])
风向和风级一样,使用了re库中的findall将’白天风力风向’这个字段中的汉字提取出来,只要第一个元素即可,然后使用Get_label_dict函数用编号来代替出现的风向。
self.data['白天风力风向'] = self.data['白天风力风向'].apply(lambda x: re.findall('[\u4e00-\u9fa5]+', x)[0])
wind_direction_c = Counter(self.data['白天风力风向'])
wind_direction_dict = Get_label_dict(wind_direction_c)
self.data['白天风力风向'] = self.data['白天风力风向'].apply(lambda x: wind_direction_dict[x])
再对夜间天气做同样的处理,这样就得到了全新的df:

将白天天气, 夜间天气, 最高温度, 最低温度, 白天风力风向, 夜间风力风向, 白天风级, 夜间风级的数据提取为一个数组(作训练数据),再将**白天天气,提取为一个数组(作标签),然后进行到的操作是定前多少天的训练数据来预测一天的天气,这里由于数据太少的缘故,只能用前一天的数据来预测后一天的数据。总之这个函数后面的操作就是将每隔一天的训练数据(一个二维数组,比如说第一个就是[[0 1 16 8 0 0 0 0]])解释一下这个二维数组的维度为什么是(1,1,8),第一个1就是代表一个样本,第二个1就是代表1天的数据,如果你用前2天的数据来预测2天后的天气,那就是2,后面的8应该不用解释了 放入一个三维数组中,预测的那天的数据就不用放进去了,而是把它的标签当成是上面那个二维数组的标签。可能有点抽象,多输出变量就能看懂了。
def load_data(data_dir):
weather_data = Weather(data_dir).pre()
data = (weather_data.loc[:, ['白天天气', '夜间天气', '最高温度', '最低温度', '白天风力风向', '夜间风力风向', '白天风级', '夜间风级']]).to_numpy()
label = weather_data['白天天气'].to_numpy()
train = data[:1].reshape(-1, 1, data.shape[-1])
train_label = label[1]
for i in range(2, data.shape[0], 2):
index = i + 1
if index >= data.shape[0]:
break
else:
train = np.r_[train, data[i:index].reshape(-1, 1, data.shape[-1])]
train_label = np.r_[train_label, label[index]]
train_label = F(train_label, 13).astype('float32')
# mean = np.mean(train, axis=0)
# std = np.std(train, axis=0)
# train = (train - mean) / std
return train, train_label
这里还有个F函数,作用就是将标签向量化。
3.构建模型
model.py
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.optimizers import RMSprop
import matplotlib.pyplot as plt
def Model(train_x, train_y, val_x, val_y):
model = Sequential()
model.add(LSTM(128, dropout=0.1, recurrent_dropout=0.5, input_shape=(1, train_x.shape[-1]), return_sequences=True))
model.add(LSTM(64, dropout=0.1, recurrent_dropout=0.5, return_sequences=True))
model.add(LSTM(32, dropout=0.1, recurrent_dropout=0.5, return_sequences=True))
model.add(LSTM(16, dropout=0.1, recurrent_dropout=0.5))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(13, activation='softmax'))
model.summary()
model.compile(optimizer=RMSprop(lr=1e-4), loss='categorical_crossentropy', metrics=['acc'])
history = model.fit(train_x,
train_y,
epochs=200,
validation_data=(val_x, val_y)
)
model.save('1.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
epoch = range(1, len(val_acc) + 1)
plt.plot(epoch, acc, label='train_acc')
plt.plot(epoch, val_acc, label='val_acc')
plt.legend()
plt.show()
这个应该没什么好说的,靠感觉搭建就完事了。
4.训练数据
tarin.py
import data
import model
if __name__ == "__main__":
train, label = data.load_data('data.csv')
train_x = train[:1900, :]
val_x = train[1900:, :]
train_y = label[:1900]
val_y = label[1900:]
model.Model(train_x, train_y, val_x, val_y)
极限的将前1900行用于训练(调优的过程中我从1600一直提升到1900,模型最终的得分也一直在涨,这充分说明了数据还是太少了,如果是每小时的气象数据就好了 ),这里之所以不用validation_split打乱是因为气象这种时间序列的数据总归有一定的规律性,而且我还是前一天预测后一天,不打乱顺序也许效果会好一些。
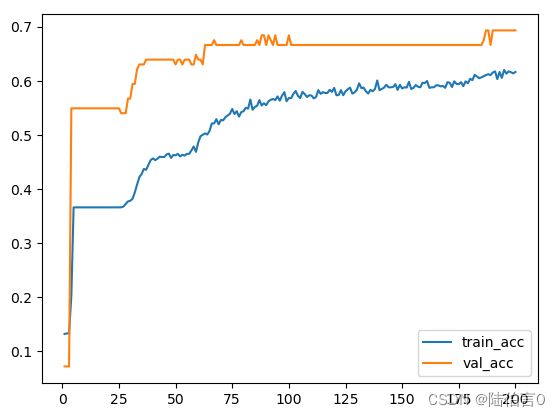
模型的精度差不多到达了70%,感觉还不错,用这么一堆不太行的数据已经远远超过我心中想的50%了。
4.测试数据
test.py
import data
from tensorflow.keras.models import load_model
if __name__ == "__main__":
test_x, test_y = data.load_data('data2.csv')
model = load_model('1.h5')
score = model.evaluate(test_x, test_y)
print(score)
由于大部分的数据(2011年至2021年)都被我用在训练和验证中了,测试就只能用2022年1月1日到2022年5月31日的数据了,处理完后只有短短的75行,得分果然也只有50%的精度,要是测试的数据集有1000行,那么它的准确率肯定能接近70%,可惜并没有。不过也远比瞎猜要远远高的多,毕竟是个13分类问题,瞎猜可能就0.07的概率?而且我发现预测错的天气有很多只是不够那么准确,例如明天是大雨,但是模型给的是阵雨,还是成功预测出了明天白天要下雨。
如果想输入一天的数据来预测明天的天气,则需要这样:
answer = {'多云': 0, '阴': 1, '小雨': 2, '阵雨': 3, '晴': 4, '中雨': 5, '中到大雨': 6,
'暴雨': 7, '小到中雨': 8, '大到暴雨': 9, '雷阵雨': 10, '大雨': 11, '晴间多云': 12}
new_answer = {v: k for k, v in answer.items()}
weather = np.array([[[3, 3, 32, 24, 1, 1, 0, 0]]])
result = model.predict(weather)
my_answer = np.argmax(result[0])
print(new_answer[my_answer])
得到当时编号的字典,交换字典的键值,然后放入一天的数据用predict来得出result,这里我放入的是2022年5月30日的数据,result的维度为(1, 13),我们需要得到值最大的下标,argmax就可以很好的解决这个问题,再输出字典以下标为键的值即可。

去网站上查看这一天白天的天气![]()
5.总结
1.对数据中的风向,风级的编码过于简单,而且和天气一样都是从0开始代替,说不定会造成一定的影响,可以尝试将所有的数据进行向量化或者是其他更好的方法试试。
2.数据量太少,测试集太少,数据记载的风向风级太过于简单和重复。
3.也许可以将大雨,小雨这些下雨的天气一起归为下雨这个分类。
4.训练时,我将1900行的数据用于了训练,这是一种不推荐的做法。
5.编码后的天气,风向,风级的值和温度之间相差最大有37,也许需要标准化。
6.暂时就想到了这么多,总之不是一次成功的过程。