JavaScript数组去重各种方法,看谁最快
本篇文章参考以下博文
- 数组里面对象去重的3种方法
- 数组方法reduce
- JavaScript 高性能数组去重
- JavaScript数组去重(12种方法,史上最全)
文章目录
-
- 前言
- 测试模板
- 一、数组去重性能测试
-
- 1.1 Array.filter() + indexOf
- 1.2 for 循环嵌套
- 1.3 for...of + includes()
- 1.4 利用hasOwnProperty
- 1.5 Array.sort()
- 1.6 new Set()
- 1.7 利用Map数据结构去重
- 1.8 for...of + Object
- 1.9 reduce
- 总结
前言
最近在处理数据时搜到一个去重方法,发现使用起来逼格很高,在此总结记录一下众多去重方法,并比较一下不同方法间的性能,作为以后装逼的谈资。
测试模板
通过 from 方法创建两个数组,一个是 十万数据,一个是 五万数据 ,连接这两个数组之后去重,查看去重时间。
// distinct.js
let arr1 = Array.from(new Array(100000), (x, index)=>{
return index
})
let arr2 = Array.from(new Array(50000), (x, index)=>{
return index+index
})
let start = new Date().getTime()
console.log('开始数组去重')
function distinct(a, b) {
// 数组去重
}
console.log('去重后的长度', distinct(arr1, arr2).length)
let end = new Date().getTime()
console.log('耗时', end - start)
一、数组去重性能测试
1.1 Array.filter() + indexOf
这个方法是通过 filter 筛选,数组中每一个元素的索引,是不是等于它在数组中第一次出现的位置,如果是说明这个元素第一次出现,可以 return 出去,如果不是说明前面已经有相同的数据了,就不 return 。
function distinct(a, b) {
let arr = a.concat(b);
return arr.filter((item, index)=> {
return arr.indexOf(item) === index
})
}
执行时间如下。
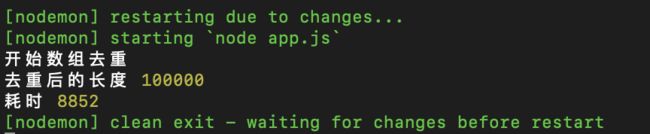
由于是第一个,还没有参照,先做个记录。
1.2 for 循环嵌套
外层循环遍历,内层循环检查是否重复。
function distinct(a, b) {
let arr = a.concat(b);
for (let i=0, len=arr.length; i<len; i++) {
for (let j=i+1; j<len; j++) {
if (arr[i] == arr[j]) {
arr.splice(j, 1);
// splice 会改变数组长度,所以要将数组长度 len 和下标 j 减一
len--;
j--;
}
}
}
return arr
}

难怪大佬们都不喜欢用 for 循环,这效率,差的不是一个量级。
1.3 for…of + includes()
跟上面的用法差不多,都是循环,只不过把 for 变成了 for…of 当然也可以使用 indexOf() 代替 includes() 。
function distinct(a, b) {
let arr = a.concat(b)
let result = []
for (let i of arr) {
!result.includes(i) && result.push(i)
}
return result
}
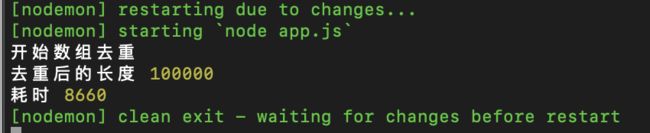
看到 for…of 的效率了不,以后乖乖把 for 都替换掉。
1.4 利用hasOwnProperty
利用 hasOwnProperty 判断是否存在对象属性,利用了对象属性不能重复的特点。
function distinct(a, b) {
let arr = a.concat(b)
var obj = {};
return arr.filter(function(item, index, arr){
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
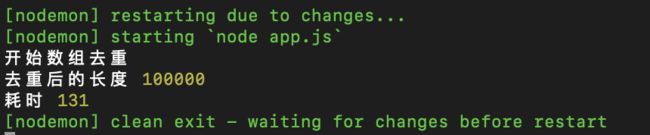
这个性能提升就很明显了,直接从八千多降到一百多。
1.5 Array.sort()
先快排,然后查看相邻数据有没有重复的。
function distinct(a, b) {
let arr = a.concat(b)
arr = arr.sort()
let result = [arr[0]]
for (let i=1, len=arr.length; i<len; i++) {
arr[i] !== arr[i-1] && result.push(arr[i])
}
return result
}
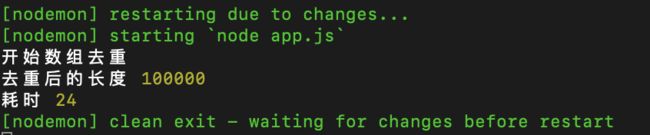
惊不惊喜,意不意外,你就说迪奥不迪奥吧。
1.6 new Set()
这个比较经典了,通过 ES6 的 Set 对象实现,应为 Set 的成员具有唯一性,感觉天生是为去重而创造的。
function distinct(a, b) {
return Array.from(new Set([...a, ...b]))
}
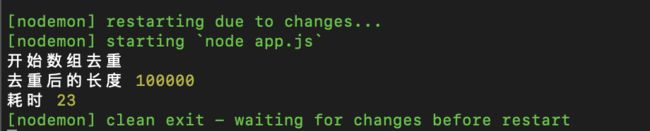
Emmmmmm…这说明在去重的时候,专门做去重的,就是比专门做排序的方法快,快一毫秒也是快。
1.7 利用Map数据结构去重
准确的说,这是用了 map 对象里面的一些方法, map 中存储的键值对会提供一些数组没有的方法,来达到去重的目的。
function distinct(a, b) {
let arr = a.concat(b)
let map = new Map();
let array = new Array(); // 数组用于返回结果
for (let i = 0; i < arr.length; i++) {
if(map.has(arr[i])) { // 如果有该key值
map.set(arr[i], true);
} else {
map.set(arr[i], false); // 如果没有该key值
array .push(arr[i]);
}
}
return array ;
}

ES6 的东西就是好用,这几个新提供的对象在性能方面优秀的一批。
1.8 for…of + Object
这个是利用对象的属性不会重复的特性,上面1.4方法也是用了属性不重复特性,不过本方法是直接利用特性去重,而上面的方法是把属性不重复的这一特性转化成了代码,然后再通过代码验证。
function distinct(a, b) {
let arr = a.concat(b)
let result = []
let obj = {}
for (let i of arr) {
if (!obj[i]) {
result.push(i)
obj[i] = 1
}
}
return result
}

这有点吓人,恐怖如斯。 JS 有个特点,它的某些极致的功能,很多都是通过它的一些特性去解决的,这就很有意思。
1.9 reduce
给大伙来个娱乐局,下面这个是通过 reduce 的回调函数, reduce 中回调函数各个形参的含义可以戳这里
function distinct(a, b) {
let arr = a.concat(b)
arr = arr.reduce((prev, current) => {
return prev.includes(current) ? prev : prev.concat(current);
}, []);
return arr
}
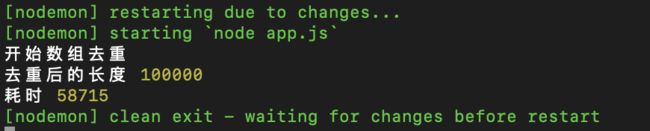
娱乐局嘛,这个的时间有点长的离谱了,不过 reduce 方法用来去重,不是去简单数据类型的,而是用来对引用数据类型进行去重的,比如说:
let arr = [{id: 123, name: 1}, {id: 123, name: 2}, {id: 123, name: 3}]
let newobj = {};
arr = arr .reduce((prev, current) => {
newobj[current.id] ? '' : newobj[current.id] = true && prev.push(current);
return prev
}, [])
//arr[{id: 123, name: 1}]
上面的方法中,就是对数组中的对象按照 id 属性进行去重的。
总结
为了方便查看,我做了个对照表格
| 名次 | 方法 | 耗时(ms) |
|---|---|---|
| 1 | for…of + Object | 16 |
| 2 | new Set() | 23 |
| 3 | Array.sort() | 24 |
| 4 | Map数据结构 | 30 |
| 5 | hasOwnProperty | 131 |
| 6 | for…of + includes() | 8660 |
| 7 | Array.filter() + indexOf | 8852 |
| 8 | for 嵌套 | 14546 |
| 9 | reduce | 58715 |
上面测试用到for循环的时候,都先把arr.length计算出来,然后再进行比较,而不是直接 i
for (let i=1, len=arr.length; i<len; i++)
JavaScript,for循环效率测试,不同遍历循环测试,数组添加效率测试,大数组拼接测试,for循环遍历修改 和 string replace效率