从存储角度看自动驾驶必经之路
当前,我们生活在一个数字时代,不断通过技术与其他人联系已经成为日常需求。生活中大家使用的机器也开始逐渐变得更智能、更方便,包括每天在路上行驶的车辆。
随着车辆联网程度变得越来越高,汽车联网逐渐成为人们对车辆的正常需求,而不再是妄想。在疫情、燃料成本和环境的倒推下,全球正在迅速向电动汽车过渡,加速向可持续化的方向发展。
一辆普通汽车每天都会产生大量的数据,车辆相当于是一台“长了轮胎”的电脑,每当它们移动的时候,就会产生大量的数据。与普通汽车相比,电动汽车的运动部件就更少了,更像一台“长了轮胎”的智能手机,它们需要一个操作系统,不仅可以让车辆与用户有更多互动,还可能操控电动汽车的所有系统和子系统,比如传动系统、电池管理系统、电机控制单元等等。
可以说,如今汽车已经远远摆脱了单纯运输的局限,实现从基于数据的服务中创造巨大的市场价值。据分析师预测,到 2025 年,联网汽车将增加 90%。同时,联网汽车将占据所有联网设备的 5% 以上。这也使得汽车行业开始利用软件的形式,通过模拟和基于设备数据收集解决方案的方式,摆脱负载的形式。
数据是新“石油”,信息是力量
车联网的出现,改变了汽车的价值链和相关产业的整个生态系统。软件驱动的车辆具有独特的记录和共享能力,有效帮助企业利用车辆数据实现真正个性化驾驶体验。如果说,在工业革命期间,石油是推动技术进步的燃料,那么现在的车辆数据将成为推动我们数字革命时代的新催化剂。
未来的汽车将是电动的、互联的和自主的,它们需要不断地积累、处理和共享从传感器和信息娱乐系统接受的数据。据相关机构预测,到 2025 年,全球销售的汽车中约有 30% 将支持 2 级或以上的自动化。
因此,将出现越来越多的车辆拥有本地收集、处理和存储数据的功能,并在适当的时间上传云端。尤其是自动驾驶汽车,他们在日常训练过程中,难免产生大量的数据。以前置摄像头为例,它们在日常产生的数据大概是 70GB/小时到 300GB/小时之间,具体数据量还要取决于其分辨率、帧速率和压缩级别等等。
另外,不同车辆类型也会产生不同的数据。根据 Counterpoint Technology Market Research 高级分析师 Aman Madhok 在 Autonomous Vehicles to Boost Memory Requirement 一文中所说,与乘用车相比,机器人出租车和 OEM 测试车辆对硬件成本的敏感性较低,将产生更多的数据。与具有相同自主水平的乘用车相比,典型的 OEM 测试车辆将产生约 80% 的数据。通过 20 多种不同类型的传感器可以集成到 4 级 AV 的 ADAS中,车辆可以生成 1-2TB / hr 范围内的数据,具体取决于它是乘用车、商用车还是机器人出租车。
同时,与当前汽车中使用的 2D 地图不同,自动驾驶汽车的高精度(HD)地图在刷新率的频率和采样方法方面差异很大。高清地图将无线进行实时更新,以精确和安全的方式精确驾驶 AV。高清地图非常精确,可以补充一些传感器缺陷,以提高位置精度。当前的 2D 地图只有一个静态图层,可以每月更新一次。但是,高动态地图具有静态图层、半静态图层、半动态图层和动态图层。高清地图每小时、每分钟和每秒更新一次。
总而言之,自动驾驶汽车在快速发展过程,一定会产生越来越庞大的数据量,随之而来就需要面临诸多存储挑战,诸如:
-
海量小文件;
-
存储性能局限;
-
数据管理困难;
-
冷数据无从下手;
-
数据类型繁杂。
通常来说,汽车制造厂商更喜欢将数据存储在本地,因为原本汽车能生成的数据相对较少。但是随着汽车开始向 L4-L5 自动化演进,云计算和边缘计算战略的结合将占上风。在这个阶段,数据存储面临更多的挑战,比如需要更谨慎的数据收集、存储和使用战略。同时,自动驾驶车辆将面临设计和成本限制,以及网络和云将受到带宽、延迟、安全性和连接性的限制。故而,自动驾驶汽车需要一个更智能的存储。
如何从容应对自动驾驶数据洪流?
针对自动驾驶企业常常面临的几大问题,焱融科技认为如果能全面提升存储系统的元数据处理能力、目录热点、多级智能缓存、智能分层等方面,那么自动驾驶在现阶段面临的存储问题便可以迎刃而解。
元数据压力大
由于自动驾驶的训练数据文件通常会分散在不同的路径下,读取文件需要耗费大量的时间在 list 操作上。由于对象存储 list 操作性能较差,因此在进行大规模 list 时对 OSS 元数据压力很大,经常出现超时或者 list 失败的情况。
为了解决训练文件分散,元数据压力大的问题,YRCloudFile 选择通过可水平扩展设计的 MDS 架构,实现 MDS 集群化,并主要采用静态子树 + 目录 Hash 两者结合的方式搭建可水平扩展设计的 MDS 架构。通过此架构,不仅实现了元数据的分布存储,通过扩展元数据节点,即可支持百亿级别的文件数量,而且在一定程度上,保证了元数据的检索性能,减少在多个节点上进行元数据检索和操作。
训练模型 IO 特点难把控
在训练过程中,数据 90% 以上都是读操作,并且是小文件的顺序读或大文件的随机读。在训练过程中,数据集是不会被修改和删除的,元数据的操作集中在 open/close/stat/revalidate,不会有特殊的元数据操作,数据操作就是 read。基于这种 IO 特点,当需要进一步提升性能时,可以选择性弱化某些 POSIX 语义,甚至是降低数据的一致性,比如说在客户端增加弱化一致性之后的读缓存,从而大大提升训练过程中对数据的读取速度,缩短训练时间。
在大规模存储系统中,分析业务的 IO 行为是一套非常复杂的流程,尤其是分布式文件存储,文件存储需要实现一套标准 POSIX 语义的文件接口,丰富的接口带来的困扰就是需要监控和分析更多的 IO 操作类型,分析的难度也就更大。对文件存储来说,我们需要关注两类 IO,元数据和数据。元数据 IO 主要包括文件/目录的元数据操作,比如说 open/close/mkdir/rmdir/stat/unlink/revalidate/hardlink/rename 等,数据 IO 主要包括 read/write,在统计 read/write 的时候,还要统计对应的 IOPS 和 BW。遗憾的是,市场上常用的文件存储产品和方案也很少提供方便的工具帮助管理员系统地了解业务 IO 特点。
针对自动驾驶训练模型的 IO 特点,YRCloudFile 设计出多级智能客户端缓存,在最大范围内提高了整个 IO 训练过程中的性能:
-
在客户端缓存过程中,由内存缓存 + GPU 服务器本地 SSD 缓存组成;
-
可以指定缓存大小和位置;
-
训练程序先从客户端内存缓存中加载,未命中则从客户端服务器 SSD 加载,不命中最后从文件系统集群中加载;
-
对训练框架、应用程序完全透明。
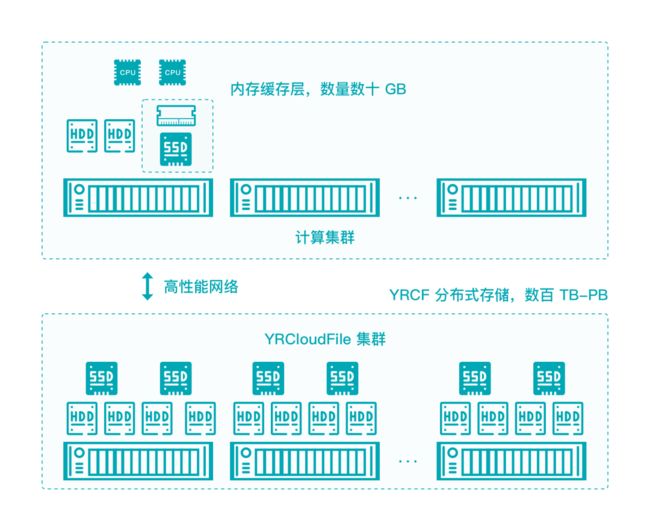
YRCloudFile 客户端多级智能缓存工作图
通过焱融 YRCloudFile 所提供的方案,可实现在整个训练中,数据集加载速度提升 5 倍。
冷热数据难分离
在自动驾驶训练过程中,难免会出现冷数据,但是一旦冷数据过多,不仅会占用大量的存储空间,存储成本在总成本中的占比将会越来越高。如何有效降低存储成本的问题就摆在了许多用户面前。
目前,市面上众多的存储解决方案中,有一种方法是将冷热数据实现分层存储。在极大部分场景里,数据都可以分为“冷数据”和“热数据”。数据类型划分的原则是,根据时间远近、热点/非热点用户等等。用户如果在一段时间内频繁访问就定义为“热数据”,反之就为“冷数据”。如果数据类型不做划分,那么对存储性能和存储成本都会带来一定的负面影响。
在冷热数据问题上,YRCloudFile 就考虑到了这一点,选择用文件存储系统目录级的智能分层功能来降低存储成本,提高存储性能。主要是通过“高性能文件存储+低成本对象存储”进行组合的方式,实现热数据依然为人工智能等新兴业务提供高性能访问的特性,而冷数据可以在用户现有低成本的对象存储中有效保存。
结语
自动驾驶时代的来临,让汽车变得更加复杂,产品形态也将重新被定义。面对多样化的企业用户场景化需求,焱融科技将持续秉持着在存储领域的专业技术和态度,以更多的姿态迎接自动驾驶时代商业化的来临。