数仓维度建模实例
简介
本文将介绍维度建模理论和基于自己经验的实施步骤
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据....
只有数据模型将数据有序的组织和存储起来之后,大数据才能得到高性能、低成本、高效率、高质量的使用。
一般业务系统报表开发模式是java写sql从业务库算出结果数据,这样是可以快速出来结果,但有几个问题:
1)对业务库的影响
2)扩展性,比如页面又想加表的量程查询维度
3)当数据需求越来越多时,怎么维护
这时就需要数据仓库来对接源系统,计算结果数据给到应用,将数据分析和业务处理分离。 数仓建模描述的就是这么设计数仓里的表和表间关系, 和用powerdesigner做业务系统表设计作用差不多,只不过数仓是面向数据分析(OLAP)而业务系统是面向业务处理的(OLTP)
数仓中一般描述成: 数据模型–>业务过程—>数据域

常见的建模方式有:Inmon提出的ER(3NF)建模 , kimball提出的维度建模,datavalut和anchor模型用得都很少。这里只阐述项目中用到的维度建模。
一、 维度建模理论
根据鄙人多年实施经验, 上去就干的方法多半会凉凉, 表越来越多,重复的,废弃的…所以需要理论指导我们实践,在实践中完善优化理论。《数据仓库工具箱: 维度建模权威指南》,链接:https://pan.baidu.com/s/15LL8MrpNl80skIlFvhnIgg 提取码:ypha 这里只阐述项目中用到的部分。
维度建模的优势: 以用户容易理解的方式发布数据(过程简单易于实施)和高效的数据查询性能
三个重要概念: 总线架构(Bus Architecture),一致性维度(Conformed Dimension)和一致性事实(Conformed Fact)
搭建好大数据平台后,做数仓分层规划,然后就要建立整个企业内具有统一解释的标准化的维度和事实 ,即一致性维度和一致性事实。然其他需求都按这个体系结构来进行迭代开发。
总线架构
总线架构是一种结构化的、增量式的构建数仓的方法。
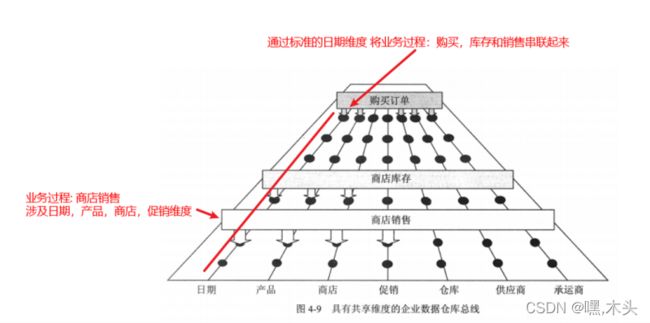
上图的日期,产品…就是一致性维度 , 销售,库存就是一致性事实表。
理解总线:电脑的IO总线,按约定的标准将鼠标,键盘,usb等串联起来使之可以协同工作。 类比过来
企业数仓中,用一致性维度和一致性事实把各个业务动作(销售,库存,订单)串联起来,使之可以方便的分析查询数据
通过总线矩阵梳理出一致性维度和业务过程的关系,就是分析源系统有哪些业务过程, 过程中会涉及什么维度,X越多说明这维度越重要,就应该先建立。
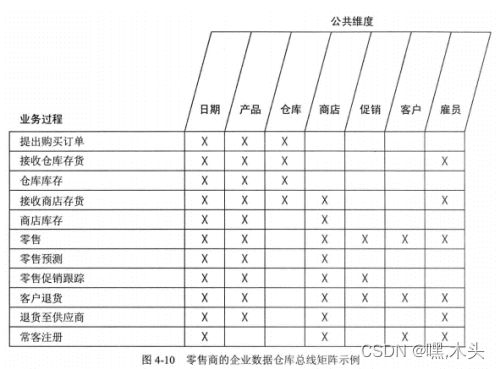
维度建模的主要步骤
上一步已经有了一致性维度的构想,接下来通过以下步骤,构建一个业务数据分析模型
1、选择业务过程
业务过程是组织完成的具体活动,如:接收付款,开具发票,下订单...用户的核心业务是什么?
2、声明粒度
精确定义某个事实表中一行的含义,回答“如何描述事实表中的行内容?”
3、确认维度
维度要解决的问题“业务人员如何描述来自业务过程量事件的数据”,表示承担每个度量环境中所有可能的单值描述符。
4、确认事实
解决“过程的度量是什么?” ...典型的事实是可加性的数值...需要将数据源和用户需求结合起来
一个简单的维度建模结果如下:

可以看到这样的结构
1)可以快速扩展,比如添加一个供应商维度表,就可以分析供应商和零售的关系
2)快速提供结果数据, 比如查询每年农历新年的销售数据
3)结构简单便于理解
当然在实施过程中需求对接,维度变化,数仓标准,一致性维度,快照事实表等等都是问题,在业务场景章节会进行实例解析。
复杂的模型比如Teradata的LDM, 这样的模型是数据分析师和业务专家,对业务的深度沉淀,基于这个模型能提供给财务用户提供想到的以及还没想到的数据信息,指导财务数据分。不用像传统模式去调研开发,直接部署灌入自己的数据就分析,这就是好的模型的牛逼之处

二、实施策略
“道理听了很多,却依旧过不好人生” 怎么办? 那是因为还缺少切实可行的实施策略。
很多方法论都太理想,比如上去就梳理各个系统业务,做大而全的,画大饼;建议:选择最有价值的业务需求,或者领导最关心的作为切入点, 做出来,再逐步增加。 下图是基于OneData结合我项目的实际调整后的实施步骤:
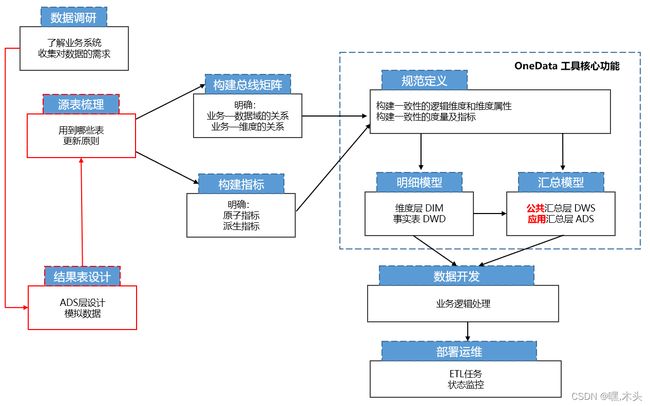
调整原因:
- 阿里或者维度建模理论是没有明确需求的情况下,做一个大而全的数仓,再通过数仓输出数据报表。 而我们的情况是有明确需求(有产品原型图)
- 在资源有限(人力,时间,成本)情况下,通过需求倒推设计统一维度表和事实表, 再结合维度建模的理论形成可扩展的数仓模型。这个策略在之前的项目中有成功的实用
实例
Step 1. 数据调研
由产品经理进行,交付的是需求文档,产品原型图 , 当数仓成熟后可以基于数仓主动为业务提供数据产品。一般会进行需求评审以判断需求的可行性和性价比。 对于比较复杂的指标需要提供指标说明文档,指导数据开发以及作为产品使用文档的一部分交付客户。
说到产品文档,就真一言难尽… 对于复杂的指标希望产品经理能提供类似这样的指标说明

指标说明示例下载地址 https://download.csdn.net/download/BI_Worker/85136111
以下以“水表接入数统计报表”为例说明建模全流程,公司对保密要求比较严我就简化下
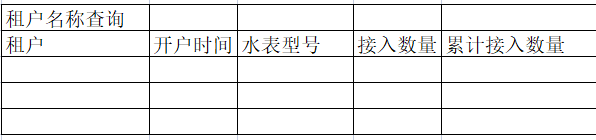
查询条件: 租户名称
展示内容: 租户,开户时间,水表型号,接入数量,累计数据
Step 2. 结果表设计
一般的报表是由数据开发,后端开发和前端开发协同完成。为避免后端等待数据的情况,在明确需求后,数据开发设计ADS层的表结构 与后端、产品评审。评审后确认后填充模拟数据。一般用在线文档的模式方便共享, 这样后端和前端就可以进行开发调试,后续换成真实数据即可快速上线。
ADS层的原则是让数据应用最高效的查询到所需要的数据,但要注意 :
- ADS层并不是严格的一个报表页面对应一个数据库表,根据实际情况做调整可以一张数据库表支撑多张同类型的报表页面
- 列名尽量保持与源系统一致

结果表评审内容
▶ 数据开发对指标定义的理解是否准确
▶ 是否有对应的数据支撑,如果没有怎么替换
▶ 用户量,数据量,什么情况下使用?查询频率
▶ 扩展的内容是否合理,比如我新加了开户,销户数
关于生成模拟数据,有对应的python脚本, 参考我其他文章。
注意所有步骤的表名称,字段,分区等都要按照数仓规范进行
Step 3. 源表梳理
明确了ADS的输出再反推回来需要哪些源数据。同时要清楚什么业务动作产生, 来自于哪些数据库,哪些表 。参考第三章相关内容,输出源表-ODS映射

上面收集的信息是通过需要的结果倒推出维度建模的第一步“选择业务过程”, 也是指导ETL开发和数据资料的原始资料,随着业务增多考虑用atlas进行管理。
tips:
多多仔细查阅:
1)公司svn上的产品使用手册
2)业务系统原型图产品设计文档
3)业务系统据库设计文档
在与相关人员讨论,需要准备具体的有价值的问题
建模的第二步“声明粒度”其实也完成了, water_meter表就是就是我们达成共识的,最细粒度每一行表示每个表计的状态信息。
这些表都会进入ODS层,所以在抽取之前就要输出ODS数据表设计文档,建议用PowerDesigner 做,主要信息是表间关系和关联字段,但没有键约束后续要在ODS层新加表之前,要先查询本设计文档,避免重复抽取。
Step 4. 构建总线矩阵
通过总线矩阵分析业务动作中涉及到的维度信息, 将同类型的维度提炼成维度表,这里完成了第三步“确认维度” 就是生成对应的维度表。 维度表设计有很多技巧,建议大家阅读原书
将尽可能的多的维度信息放入维度表中,方便聚合查询。 比如日期维度表中加入节假日,是否放假。 就能快速统计节假日相关的数据

Step 5. 构建指标
对应第四步“确定事实”,简单说:业务过程可以沉淀出哪些可加性指标?把这些指标设计成宽表再关联上一致性维度表,DWD层的明细模型就完成了。
gas_meter上卷一层后从最细的设备id到了用户id,设备id的通气日期汇总后得到接入数(原子字表), 计算截止到统计日期的累计值(派生指标)

后面DWS就是基于这一层再加工一次形成汇总模型:
▶ 更粗粒度的汇总,比如dwd存的是没个每天的接入量, dws再汇总一次计算每月的接入
▶ ADS直接存结果表记录
Step 6. 数据开发及上线
1) 开发对的脚本生成以上5步的结果数据
2) 进行数据验证确保准确
3)部署到调度平台调度监控
交付的是相关脚本及etl流程说明
相关术语说明
| 名词术语 | 解释 |
|---|---|
| 数据域/主题域 | 一系列相关业务过程的合集,其中,业务过程可以概括为一个个不可拆分的行为事件,在业务过程之下可以定义指标和维度 |
| 业务过程 | 指企业的业务活动事件,如下单、支付、退款都是业务过程。请注意。业务过程是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件 |
| 统计周期 | 用来明确数据统计的时间范国或者时问点。如最近 30天、自然周、截至当日等 |
| 修饰词类型 | 是对修饰词的一种抽象划分。修饰类型从底于菜个业务城,如日志域的访向终赏类型涵盖无线淌、PC端等修饰词 |
| 度量/原子指标 | 原子指标和度量含义相同,基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,具有明确业务含义的名词,如支付金额 |
| 派生指标 | 派生指标=一个原子指标+多个修饰词+统计周期 |
| 维度 | 实时表中的描述性信息,如国家,时间,地点等 |