大数据数仓建模 - 维度建模 实战及思路过程 (两年数仓建模经验 纯干货)
数仓维度建模
维度建模方法论:
维度建模 是以业务过程为驱动
先确定某些业务过程 围绕业务过程去建立模型 通常采用自底向上的方法 从明确关键业务过程开始
再到明确粒度 再到明确维度 最后明确事实
在我们数仓项目初期 我们首先要做的就是 一个数仓建模的设计
建模也是整个数仓最核心的工作 数仓的好坏就取决于你的建模
数仓建模 四个步骤
1. 选择业务过程 》2.声明粒度 》3.确定维度 》4.确定事实
我们在建模的过程中 首先选择公司的核心的业务线 (如果是小公司 业务表只有几十张 可以全选)
比如说 订单业务 支付业务 活动业务 退款业务 物流业务... 一条业务线对应一张事实表
我们根据选择的这些业务线 来确定一些维度和事实 也结合 后端存储在数据库的数据 来确定一些指标 也判断 产品提出来的需求能不能做 如果缺少数据 我们也会和后端部门去沟通 看能不能把需要的数据获取到。
我们确定好业务过程 就要去业务数据库 去抓取采集 这些业务线相关的数据了
我们把这些数据拉取到数据仓库中 要划分维度 事实 去建表 事实表中每一行数据表示的就是我们的声明的粒度 , 粒度越细越好 我做建模 粒度都选用原子级别的粒度去拉取这些数据 粒度越细致 后期的工作越好做 。 举个例子:订单中每个商品项 作为订单事实表中的一行数据 粒度为每次。 将每周的订单次数作为一行数据 粒度为每周。 将每周的订单次数作为一行数据 粒度为每月.如果在DWD层建模采用的粒度是每周或者每月 那么后续就没办法统计粒度更细(比如每天 每次)的指标了选择最细粒度可以应对后期各种各样的需求。
维度的主要作用就是对业务事实的描述 主要表示 “谁、何处、何时”等信息 谁就代表用户维度 何处就代表地区维度 何时就代表时间维度,这些是比较常见和通用的维度。可以根据公司的情况和业务 增加维度.
“事实”这词在数仓建设中一般指的就是业务中的度量值 例如订单表的度量值就是订单件数,订单金额。
我们主要采用维度建模的星型模型进行建模的.(数仓建模不局限一个模型 而是灵活运用单层维度 和 多层维度并存)
星型模型的优点就是性能高,一张事实表 只关联一层的维表 减少后期团队分析数据产生的JOIN
尤其是针对基于Hadoop体系搭建的数仓项目 减少JOIN就是减少中间数据的传输和计算 明显的能改善性能
根据我们确定好的维表以及事实表 最终会确定一张总线矩阵图
星型模型
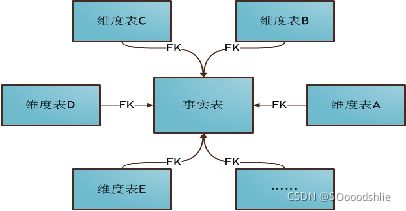
总线矩阵图
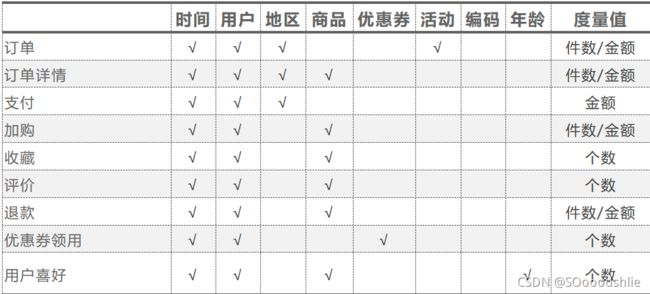
在DWD层进行建模 根据星型模型的思想 会进行维度退化 把地区表和省份表退化为一张地区维表,
sku商品表 spu商品表 品牌表 商品一二三级分类表退化为一张商品维表,活动订单关联表以及活动规则表会退化为一张活动维表等等建立维表
事实表会根据总线矩阵建立事实表 事实表包含涉及维表的主键 以及 业务事实的度量值 也可以适当宽表化。
整体来说
数仓建模的整个过程 非常考验我们的Hive sql的能力和对业务的理解。