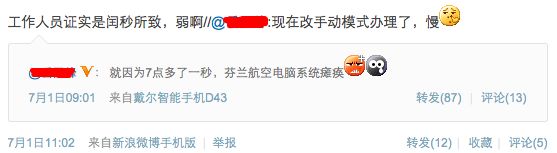
前几天看到一个很有趣的微博(见下图)当然这事儿对发博的人肯定没有趣,又查了一下闰秒的概念:
原来我们的时间计算有两种方式,一种是类似于古人看太阳位置或者用日冕的“天文法”,获得的时间称之为世界史;一种是利用原子振荡周期计算的“原子 法”,我们生活中用的时间都是第一种,而计算机系统则大量使用第二种。在大部分场合这俩时间完全一致,但是由于现在地球越转越慢(或许岁数也大了 Orz),所以还是有微小的误差,为了平衡这种误差,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。2012年7 月1日我们就见证了一个闰秒(北京时间为7:59:60)。
合着闰秒是计时领域的一种调整,但是这个调整却给全世界IT系统带来了麻烦,除了微博中提到的芬兰航空管理系统,许多使用Linux系统服务器也发 生了问题,这是因为,Linux内核2.6.29之前版本存在bug,在进行闰秒调整时可能会引起系统时钟服务ntpd进程死锁。许多使用Linux服务 器的著名网站都遇到了问题(不过看报道,都是国外网站,国内网站似乎很平静,难道我们的网站都是用Windows Server?)
类似的案例,在我国还有一个事件,由于出租车计价器芯片没有2月29日,广州的上千辆出粗车在这天趴窝。(新闻链接:http://news.ifeng.com/mainland/detail_2012_02/29/12864172_0.shtml)
与时间有关的最经典的bug当然还是“千年虫”了,由于采用了两位纪年用于节省存储空间,全世界的软件在2000年1月1日都可能会宕机(系统无法 识别00代表2000还是1900),在那个互联网还不发达,操作系统不能偷偷在后台打补丁的年代,各大软件公司都在四处邮寄补丁光盘,并在惴惴不安中渡 过了新年。
从这些案例我想到的是测试设计的问题:如何优化我们的时间相关数据设计?
首先,时间数据的等价类划分应该更加细致,除了一个有效时间和一个无效时间,还应该有闰年、闰月、闰秒数据。由于时间是广泛相关数据,纵使被测软件 可以正确处理,被测软件相关的其他软件(操作系统,数据库,Java虚拟机等)也有可能会出问题(例如Linux内核的那个bug),所以这种广泛测试是 必要的。这种测试可以作为一个单独的检验用例或者探索测试执行。
其次,时间的广义边界值测试。大部分测试者都知道测试输入框的显性边界值,但是很少有人去测试时间这个隐形边界值。时间可能不是我们手动输入的,但 是它还是每时每刻在做为隐形输入在影响着我们的系统。而当时间处于交界点(跨年,跨天,或者某个时刻)时,问题就会发生。例如我在过去测试中遇到每天早上 8点整某个信息管道就会丢失数据。
再扩展一点就是,我做测试时,经常揪住省份这个选择框不放,别看这是最简单的录入信息(提问,中国有多少个省级单位?如果不知道的话,自己去 baidu吧),要么少了,要么多了,要么名字不对,有相当的机会发现问题。新浪微博不也出过“湖北省省会是哪里”回答武汉,系统提示“您的回答有 误”……这种乌龙事件吗。
时间,省份这都是非常简单的输入,但是这都只是看似简单而已,内里还是有很多门道,因为他们涉及到其他领域的知识:政治、人文,地理,历史等等。
所以,测试(尤其是黑盒测试,手工测试)绝对是一个入门容易,做好难的职位,单单是时间这么常见的数据,就有很多潜在知识,从设计和分析上都需要注 意,更何况复杂的业务系统,或者专业软件。所以终归测试是离不开人的因素的,测试时要“动脑子”,要不断提高理解,要不断的学习,而不是只对着用例文档一 行行的做机器人:这种机器人工程师,早晚会被机器人测试脚本取代。而那些真正动脑子的工程师,才拥有未来。
ps:写完这篇文章的时候,看到一篇报道说“美国政府表示闰秒的推行不是好事,他们指出,因为这个闰秒将会导致很多计算机系统运行困难。目前,国际 电信联盟(ITU)已经接受美国提出的取消闰秒的提案。不过关于这个提案的讨论活动预计要推迟到2015年。”——这听起来好耳熟啊:“我们的软件无法实 现这样的功能,所以请取消这个需求”……