【NLP】Transformer理论解读
前言
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,目前已经在目标检测、自然语言处理、时序预测等多个深度学习领域获得了应用,成为了新的研究热点。
论文题目:Attention Is All You Need
论文地址:https://arxiv.org/pdf/1706.03762v5.pdf
模型结构
不同于传统神经网络的CNN和RNN,Transformer是一种全新的Sequence to Sequence的结构,论文中的网络结构图如下:

图中,左半部分为编码器(Encoder)结构,后半部分为解码器(Decoder)结构。这里的Nx表示编码器和解码器分别有N个,论文中使用的是6个。注意这N个结构并不是简单copy,而是每个单独进行训练。
这张图乍一看有点复杂,下面将根据输入-输出的步骤,对各模块进行拆解分析。
Input Embedding
首先,输入的文字内容,需要进行词嵌入(Word Embedding)的操作,这个在NLP中比较常见。
One-Hot Encoding
在词嵌入之前,首先需要对输入的句子进行独热编码,即每一个单词仅有一个为1,其余为0。

Word Embedding
独热编码带来的问题是如果句子中的词很多,那么对于每一个词来说存在大量0,太浪费存储空间。
于是一个改进想法就是,设计一个可学习的权重矩阵W,将词向量与这个矩阵进行点乘,得到新的表示结果。
10000 和权重矩阵W
[ w00, w01, w02
w10, w11, w12
w20, w21, w22
w30, w31, w32
w40, w41, w42 ]
点乘的结果为[w00, w01, w02],这样就成功将1x5的数据降维成了1x3,完成了Embedding。
Position Encoding
有了词向量之后,下面就需要进行位置编码(Position Encoding),这是因为Transformer处理的都是高度并行化的数据,不像RNN一样,输入的内容是有先后顺序的,是一句话的所有内容一起输入,因此需要对其进行位置编码,防止位置发生错乱。
位置编码的公式如下[2]:

pos代表的是词在句子中的位置, d m o d e l d_{model} dmodel是词向量的维度(通常经过word embedding后是512),2i代表的是d中的偶数维度,2i + 1则代表的是奇数维度,这种计算方式使得每一维都对应一个正弦曲线。
这样就保证了不同位置在所有维度上不会被编码到完全一样的值,从而使每个位置都获得独一无二的编码。同时,它将允许模型通过相对位置轻松学习。
之后,将位置编码的结果和Embedding的结果进行相加,得到的结果输入到模型中。

Self-Attention
多头注意力机制(Multi-Head Attention)是Transformer的核心机制,在此之前,首先需要理解自注意力机制(Self-Attention)。
如下图[3]所示,对于输入的x,乘上w做词嵌入(就是上面提到的操作),得到模型输入的向量a。
然后,对于每一个a,分别乘上 W q W^q Wq, W k W^k Wk, W v W^v Wv,得到三个向量q,k,v。

之后,将每一个q分别点乘k,这样可以得到注意力矩阵。所得结果/根号d,d就是q和k的维度,这样是做一个标准化,方便计算。

对于得到的注意力 α \alpha α,再进行一个soft-max归一化。
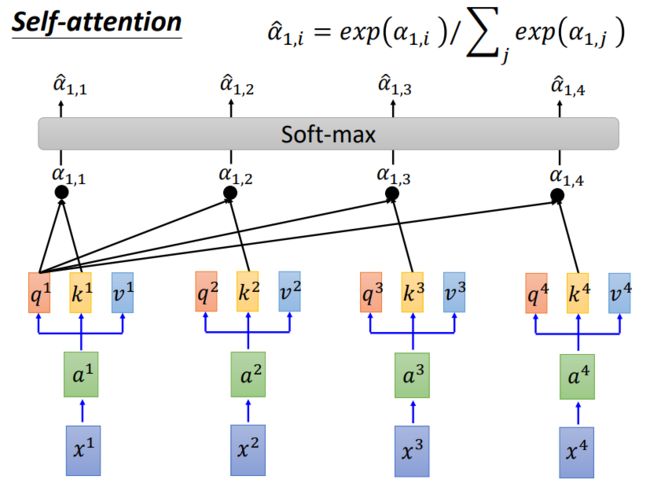
然后,将每个词的注意力分别乘以v,然后进行累加,得到输入的b向量。
论文里给出的公式如下:

例如,下图中展示 b 1 b^1 b1的计算步骤。

同理, b 2 b^2 b2也可以类似得到。

以此类推,通过Self-Attention层之后,输入的a可以转化成b。

上面展现了单行句子输入的场景,而在实际过程中,可以利用线性代数中的矩阵乘法,来实现多行句子一起输入并行处理,这样也能够更好得发挥GPU并行计算的性能。

Multi-Head Attention
理解了Self-Attention之后,多头注意力机制(Multi-Head Attention)就比较容易理解。
如下图所示,所谓多头,就是使用多组不同的 W q W^q Wq, W k W^k Wk, W v W^v Wv,这样就得到了不同的注意力。

直观描述,不同的注意力头的关注点会不同,从而可以提取一段文本中不同的信息。

Add&Norm
Add&Norm包含两个结构:Add和Layer Norm。
Add比较简单,主要是应用到了残差网络(ResNet)的思想,将输入前的向量a直接复制一份添加到输出的b上,这样可以有效防止梯度消失的问题。
Layer Norm计算方式也比较简单,就是对每一个向量做一个标准化(减均值/标准差)。
对于Norm通常用的更多的是Batch Norm,也就是在图像领域频繁使用的BN层。它的方法是对于每一个批次的同维数据做一个标准化,下图是Layer Norm和Batch Norm的直观对比。

那这里为什么不用BN层呢?
这是因为在NLP任务中,输入是动态的。对于BN来说,只有在Batch_Size足够大的情况下,效果才会好。下图就展示了一种特殊情况,对于特别长的句子来说,后面的Batch_Size相当于1,这样效果不好。

Masked Multi-Head Attention
后面的Feed Forward就是一个普通的前馈神经网络,没有特殊之处。这样左侧编码器部分就分析完了,进入到右侧的解码器部分。
在解码器部分可以看到,里面的结构和编码器大致相当,唯一不同的是多了一个Masked Multi-Head Attention。
Masked Multi-Head Attention就是在Multi-Head Attention的基础上增加了一个遮罩(Masked),因为在训练中,处理当前词时,后面的词并不应该存在,但是训练集中后面的词(ground truth)是存在的,不可以做attention,所以要遮盖掉。

至此,关于Transformer的各模块就全部分析完成。
总结
Transformer的出现颠覆了以往CNN提取特征的模式,不过,我也听说Transformer因其巨大的特征量导致非常难以训练。关于这一点,后续我将通过实验去证实。
References
[1]https://www.jianshu.com/p/e6b5b463cf7b
[2]https://www.bilibili.com/video/BV1Di4y1c7Zm
[3]https://www.bilibili.com/video/BV1J441137V6
[4]https://mp.weixin.qq.com/s/73RAMVGpguFw-fteQwFTIw