活体检测 Adaptive Normalized Representation Learning for GeneralizableFace Anti-Spoofing 阅读笔记
论文链接:Adaptive Normalized Representation Learning for Generalizable Face Anti-Spoofing | Proceedings of the 29th ACM International Conference on Multimedia
预备知识
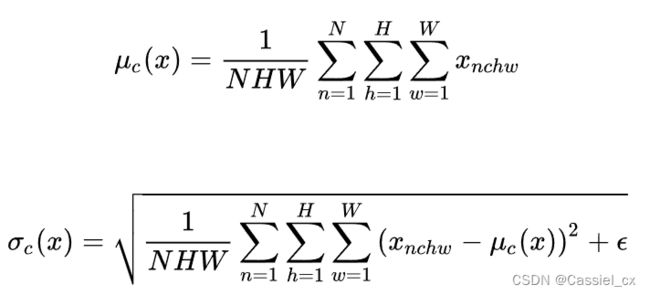
(1)Batch Normalization
定义:假设输入特征的尺寸为 ![]() ,包含 N 个样本,每个样本通道数为 C,高为 H,宽为 W。对其求均值和方差时,将在 N、H、W 上操作,并保留通道 C 的维度。
,包含 N 个样本,每个样本通道数为 C,高为 H,宽为 W。对其求均值和方差时,将在 N、H、W 上操作,并保留通道 C 的维度。
适用范围:常用于判别模型中,比如图片分类模型。因为 BN 注重对每个 batch 进行归一化,从而保证数据分布的一致性,而判别模型的结果正是取决于数据整体分布。但是 BN 对 batchsize 的大小比较敏感,由于每次计算均值和方差是在一个 batch 上,所以如果 batchsize 太小,则计算的均值、方差不足以代表整个数据分布。
BN 的公式如下:
(2)Instance Normalization
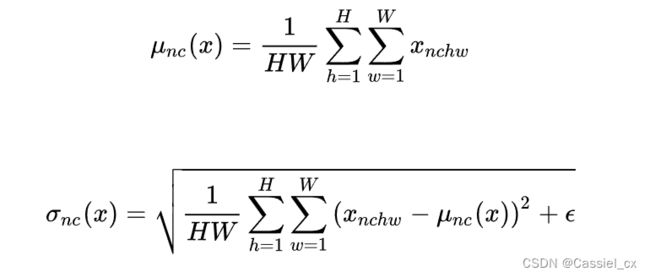
定义:最初用于图像的风格迁移,在生成模型中,特征图的各个通道的均值和方差会影响到最终生成图像的风格,因此可以先把图像在通道层面归一化,然后再用目标风格图片对应通道的均值和标准差“去归一化”,以获得目标图片的风格。IN 在单个样本内部进行,不依赖于 batch 的大小。
适用范围:常用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个 batch 归一化并不适合图像风格化,在风格迁移中使用 IN 不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立。
IN 的公式如下:
引言
由于各种人脸表示攻击的出现,人脸识别系统的安全性已成为公众关注的关键问题。为了解决这个问题,研究人员提出了许多 FAS 方法,这些方法最初利用 LBP (Local Binary Patterns,局部二值模式) 和 HOG (Histogram of Oriented Gradient,方向梯度直方图) 等手工特征来区分真假人脸。 随后,一些方法开始利用 CNN 的强大表示能力来检测人脸攻击。尽管这些方法在同场景下取得了非凡的性能,但在未知场景下测试时,它们的性能都显著下降。性能退化的原因是这些方法只适合具有偏差特征的训练数据,而忽略了源域和未知目标域之间的域差距,从而导致模型泛化能力差。
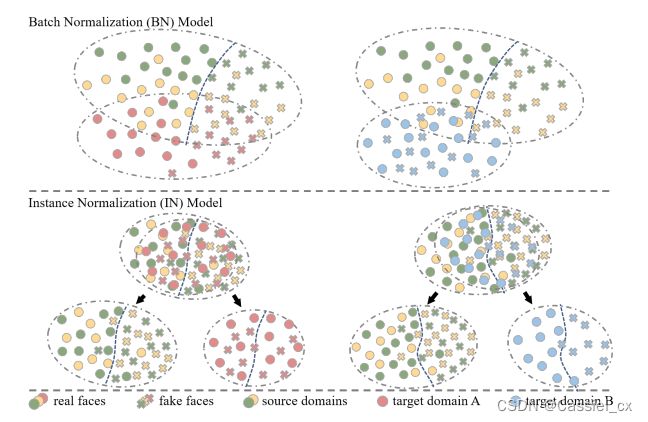
为了解决这个问题,有些方法将域泛化引入 FAS 任务中。具体来说,它们将来自多个源域的特征映射到一个公共特征空间以进行泛化表示,这可以很好地转移到未知的目标域。然而这些方法只关注最终特征的对齐,忽略了特征提取的过程。如下图所示,该文作者在相同的源域上使用 BN 以及 IN 分别训练模型,并在未知目标域上进行测试。作者在目标域 A 上进行测试 (如下图左所示),其中具有 BN 的模型优于具有 IN 的模型。然而,在目标域 B 上测试时,IN 优于 BN。这是因为当未知的目标域与源域相比几乎没有域偏移时,BN 保持高性能。由于 BN 容易受到域信息的影响,因此在遇到大的域偏移时性能会下降。IN 则通过使用统计信息消除了每个样本的特定样式信息,因此在域偏移的场景中性能较好。
由于这两种归一化方法都有各自局限性,因此研究人员提出了一些归一化组合方法来处理更多的情况。但是,由于 FAS 任务中的样本在场景、光照等方面存在差异,直接利用共享参数进行组合,可能会导致性能下降。为了解决上述问题,作者提出了一个新的框架,自适应归一化表示学习(Adaptive Normalized Representation Learning,ANRL),通过从不同的归一化中自适应地选择特征来获得在未知域中的特征表示。具体来说,使用自适应特征归一化模块 (Adaptive Feature Normalization Module,AFNM) 来获取样本之间的区别。此外,为了帮助 AFNM 学习样本因素,作者还提出了双校准约束 (Dual Calibrated Constraints,DCC),包含域间兼容损失和类间可分离损失。前一种损失能够对齐不同域的特征分布,而后一种损失用于扩大真人样本和假体本之间的距离。主要创新点如下:
(1)提出自适应地选择不同的归一化特征以获得可泛化的判别表示。
(2)提出了双重校准约束,包括域间兼容损失和类间可分离损失,以指导 AFNM 实现更好的泛化。
方法论
整体框架
由于 BN 提取的特征本质上易受域迁移的影响,而 IN 提取的特征可能会丢失一些判别信息,因此它们在未知域的泛化能力都受到了限制。如下图所示,作者提出了 ANRL 来获取泛化的特征,它不仅保留了判别信息,而且还消除了域变化。具体来说,由于一些样本的域偏差很小,而一些样本的域偏差很大,因此设计了 AFNM,以自适应地将 BN 和 IN 的特征与最合适的样本因子相结合。此外,作者提出了 DCC,它包括域间兼容损失和类间可分离损失。具体来说,前者是双向设计的,不仅可以减少域间距离,而且可以分散同一域的样本,进一步促进域的混合,而后者则利用更大的间隔来分离真假样本,从而构建了一个紧凑且有区别的归一化表示空间。
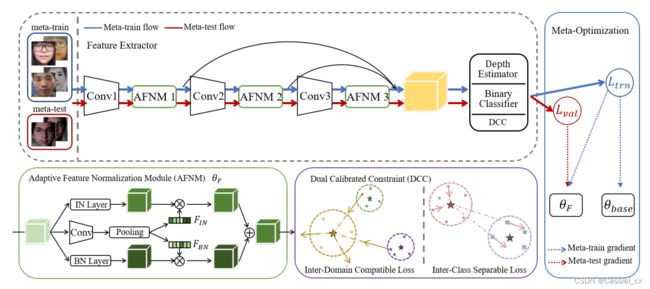
AFNM
尽管 BN 提取了源域上的判别信息以进行反欺骗,但在转移到变化较大的未知目标域时,它可能表现不佳。为了解决这个问题,IN 被证明是一种有效的方案,因为它具有消除域差异的能力。 作者因此设计了 AFNM,以将 BN 和 IN 提取的特征与为每个样本定制的自适应平衡因子相结合。
输入图片的特征图为 ![]() ,作者利用 BN 和 IN 分别获得归一化表示,分别用
,作者利用 BN 和 IN 分别获得归一化表示,分别用 ![]() 和
和 ![]() 表示。由于平衡因子应该适合每个样本,因此从它们的相应特征中挖掘信息以生成平衡因子 (对输入特征图 X 进行 Conv+Pooling 操作)。具体来说,首先使用全局平均池化来获取逐通道的统计值
表示。由于平衡因子应该适合每个样本,因此从它们的相应特征中挖掘信息以生成平衡因子 (对输入特征图 X 进行 Conv+Pooling 操作)。具体来说,首先使用全局平均池化来获取逐通道的统计值 ![]() ,公式如下:
,公式如下:
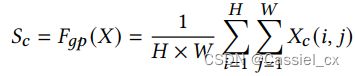
然后,使用一个全连接层来获取紧凑的特征表示,公式如下:
![]()
式中,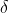 表示 ReLU 激活函数,
表示 ReLU 激活函数,![]() 表示全连接层的权重。由于
表示全连接层的权重。由于 ![]() 和
和 ![]() 关注不同的信息,作者分别利用跨通道的注意力来自适应地选择有用的信息,公式如下:
关注不同的信息,作者分别利用跨通道的注意力来自适应地选择有用的信息,公式如下:
![]()
式中, 表示 sigmoid 激活函数,
表示 sigmoid 激活函数,![]() ,
, ![]() 分别表示 BN 和 IN 层的权重。
分别表示 BN 和 IN 层的权重。
随后,引入一个归一化平衡因子 ![]() ,公式如下:
,公式如下:
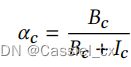
最终的特征图 Y 通过对来自 BN 和 IN 的不同特征图加权求和得到,公式如下:
![]()
式中,![]() ,
,![]() 。
。
DCC
为了指导 AFNM 估计更好的平衡因子以融合来自 BN 和 IN 的特征,作者提出了双校准约束 (DCC)。 与 FAS 任务中常用的三元组损失仅基于类构建三元组不同,DCC 从域和类的角度同时对特征进行更全面的约束。
域间兼容损失
由于 BN 容易受到域差异的影响,将域间分布打乱以缩小多源域之间的差距。为此,设计了双向域间兼容 (Inter-Domain Compatible,IDC) 损失,以将不同域的样本拉近,并将同一域的样本分散开。 具体来说,假设一个局部 mini-batch 中有 源域,将域 中的局部质心引入为:
![]()
式中,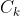 表示 域的质心,
表示 域的质心,![]() 表示样本数量,
表示样本数量,![]() 表示域 中第 个样本的提取特征。
表示域 中第 个样本的提取特征。
此外,为了更准确地估计质心,使用动量更新机制通过不同批次计算全局质心,公式如下:
![]()
式中, 表示动量因子。
表示动量因子。
然后,对于特定域 ,计算样本与相关全局质心之间的域内距离,公式如下:
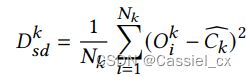
接着,计算域 中的样本与其他域的全局质心之间的距离,公式如下:
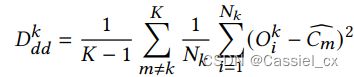
IDC 损失如下:
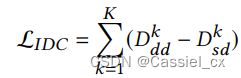
双向设计的 IDC 损失不仅减少了域间距离,而且还分散了域内的样本,进一步促进了不同域的混合。
类间分离损失
由于 IN 可能会消除一些对 FAS 任务有益的信息,因此有必要通过扩大真人样本和假体样本之间的距离来保持判别信息。因此,作者设计了类间可分离(Inter-Class Separable,ICS)损失来将同一类的样本聚集在一起,并将不同类的样本分开。
由于攻击的多样性,假体样本的分布可能是分散的,将它们强行聚合在一起会带来负面影响。 但是真人样本的分布比较稳定,适合提高紧凑性。因此从真人样本中计算类间距离,公式如下:
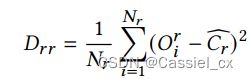
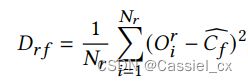
ICS 损失如下:
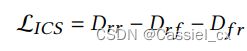
通过 ICS 损失,模型不仅被迫挖掘更多有区别的特征来区分真假样本,而且还缩小了真人样本中的差异,这两者都有助于学习 FAS 的判别性表示。
实验
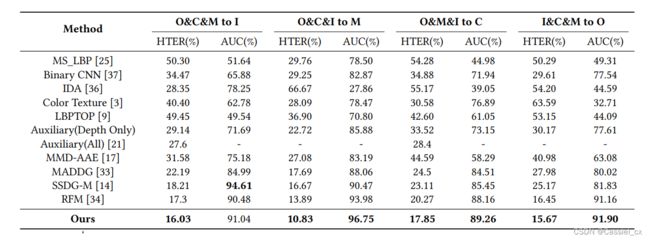
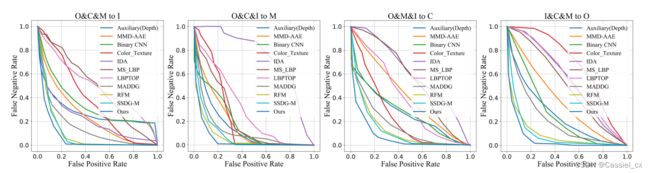
在泛化 FAS 的四个测试任务上与其他方法的对比结果如下:
结论
基于 DG 的 FAS 方法比传统方法表现更好,这证明了传统方法只适合提取源域的区分信息。提出的方法在四种测试设置下优于这些基于 DG 的方法,这证明了 ANRL 能够自适应地从 BN 和 IN 中选择特征来获得与域无关的判别表示。