机器学习入门:聚类算法-5
机器学习入门:聚类算法
1、实验描述
-
本实验先简单介绍了一下各聚类算法,然后利用鸢尾花数据集分别针对KMeans聚类、谱聚类、DBSCAN聚类建模,并训练模型;利用模型做预测,并使用相应的指标对模型进行整体的评估,并打印出三种算法的对比结果。
-
实验时长:45分钟
-
主要步骤:
-
加载鸢尾花数据
-
读取对应的样本和标签值
-
建立相应的模型
-
模型的预测
-
模型评估
-
2、实验环境
- 虚拟机数量:1
- 系统版本:CentOS 7.5
- scikit-learn版本: 0.19.2
- numpy版本:1.15.1
- python版本:3.5
- IPython版本:6.5.0
3、相关技能
-
Python编程
-
Sklearn编程
-
聚类算法
4、相关知识点
-
KMeans聚类
-
谱聚类
-
DBSCAN聚类
-
聚类建模、训练
-
模型预测
-
模型评估
5、实现效果
- 不同种类聚类算法效果评估结果如下图示:

6、实验步骤
6.1聚类算法:
6.1.1定义:聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小 ,属于无监督范畴。
6.1.2思想:给定一个有N个对象的数据集,构造数据的k个簇,k≤n。满足下列条件:每一个簇至少包含一个对象;每一个对象属于且仅属于一个簇;将满足上述条件的k个簇称作一个合理划分
6.1.3对于给定的类别数目k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好。
6.1.3K-Means算法:也被称为k-平均或k-均值,是一种广泛使用的聚类算法,或作为其他聚类算
法的基础。假定输入样本为S=x1,x2,…,xm,则算法步骤为:
6.1.3.1选择初始的k个类别中心μ1μ2…μk;
6.1.3.2对于每个样本xi,将其标记为距离类别中心最近的类别
6.1.3.3将每个类别中心更新为,隶属该类别的所有样本的均值
6.1.3.4重复最后两步,直到类别中心的变化小于某阈值。
6.1.3.5中止条件:迭代次数/簇中心变化率/最小平方误差MSE(Minimumd Squared Error)
6.1.4DBSCAN 算法:DBSCAN(Density-Based Spatial Clustering of Applications with Noise),它是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”数据中发现任意形状的聚类
6.1.5谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量,进行聚类,从而达到对样本数据聚类的目的。
6.2数据描述:数据集由150个鸢尾花样本构成;包含了5个属性:Sepal Length(花萼长度,单位:cm),Sepal Width(花萼宽度,单位:cm),Petal Length(花瓣长度,单位:cm),Petal Length(花瓣宽度,单位:cm);Class(类别),包含Setosa(山鸢尾),Versicolor(杂色鸢尾),Virginica(维吉尼亚鸢尾)
6.3进入Anaconda创建的虚拟环境“ML”
6.3.1在zkpk的家目录下执行如下命令
[zkpk@master ~]$ cd
[zkpk@master ~]$ source activate ML
(ML) [zkpk@ master ML]$
6.3.2此时已经进入虚拟环境。键入如下命令,进入ipython交互是编程环境
(ML) [zkpk@ master ML]$ ipython
Python 3.5.4 |Anaconda, Inc.| (default, Nov 3 2017, 20:01:27)
Type 'copyright', 'credits' or 'license' for more information
IPython 6.2.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
6.4在Ipython交互式编程环境中开始进行实验
6.4.1导入实验所需的包
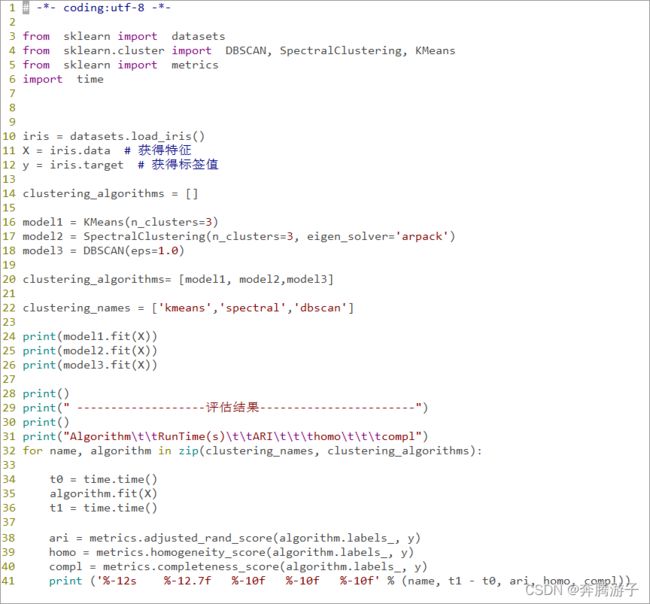
In [1]: from sklearn import datasets
...: from sklearn.cluster import DBSCAN, SpectralClustering, KMeans
...: from sklearn import metrics
...: import time
6.4.2读取数据文件:其中X包含鸢尾花iris数据集中前四列的属性信息,用于本实验的聚类数据;y包含鸢尾花iris数据集中第5列类别信息,用于评测算法
In [2]: iris = datasets.load_iris()
...: X = iris.data # 获得特征
...: y = iris.target # 获得标签值
6.4.2.1打印文件的前几行
In [4]: X[:10]
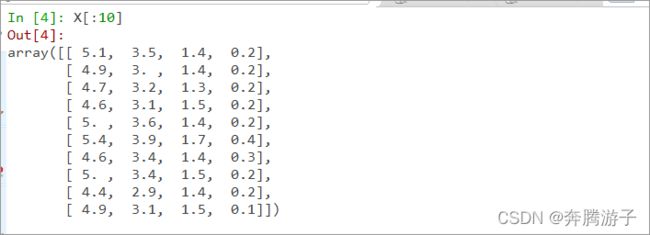
6.4.2.2显示X的shape
In [5]: X.shape

6.4.3为每一个聚类算法创建模型
6.4.3.1KMeans算法:n_clusters表示聚类类别的个数,因为鸢尾花iris数据集中共3个类别,于是设置该参数为3
In [6]: model1 = KMeans(n_clusters=3)
6.4.3.2谱聚类算法:eigen_solver表示谱聚类算法所采用的特征值分解方法,这里选用’arpack’;
In [7]: model2 = SpectralClustering(n_clusters=3, eigen_solver='arpack')
6.4.3.3DBSCAN算法:eps表示在基于密度的聚类算法中,属于同一个类的任意两个数据点之间的最大距离。
In [8]: model3 = DBSCAN(eps=1.0)
6.4.3.4将对应的模型和模型名称加入到List中, 便于后续操作
In [9]: clustering_algorithms= [model1, model2,model3]
...:
...: clustering_names = ['kmeans','spectral','dbscan']
6.4.4调用模型的fit方法在数据集X上训练学习。
In [10]: model1.fit(X)
...: model2.fit(X)
...: model3.fit(X)
6.5预测并评价聚类
6.5.1algorithm.labels_是算法学习之后得到的聚类标签,例如,聚类后结果分为3类,那么每一个数据对象的标签值就是0,1,2其中之一,代表所属类别;
6.5.2并估计消耗的时间
6.5.3评测代码调用了metrics库中的adjusted_rand_score,homogeneity_score,completeness_score三个方法,对算法的聚类结果做评价,
In [11]: print("Algorithm\tRunTime(s)\tARI\thomo\tcompl")
...: for name, algorithm in zip(clustering_names, clustering_algorithms):
...: t0 = time.time()
...: algorithm.fit(X) # 训练模型
...: t1 = time.time()
...: ari = metrics.adjusted_rand_score(algorithm.labels_,y)
...: homo = metrics.homogeneity_score(algorithm.labels_,y)
...: compl = metrics.completeness_score(algorithm.labels_, y)
...: print('%-12s %-12.7f %-10f %-10f %-10f' %(name, t1-t0, ari,homo, compl))
...:

6.5.4评价标准介绍:
6.5.4.1Adjusted Rand Index(ARI):用来计算两组标签之间的相似性。本实验中计算了算法聚类后得到的标签algorithm.labels_与数据集中真实类别标签y之间的相似性。取值范围:-1~1,值越大,相似性越高。
6.5.4.2Homogeneity(同质性):对于聚类结果中的每一个聚类,它只包含真实类别中的一个类的数据对象。取值范围:0~1,值越大,同质性越高。
6.5.4.3Completeness(完整性):对于真实类别中的一个类的全部数据对象,都被聚类到一个类中。取值范围:0~1,值越大,完整性越高。
6.6结果分析:根据运行结果下图所示,

6.6.1DBSCAN聚类速度最快,同质性指标值最高,达到了1.0,在DBSCAN算法中,聚类出来的每一个类都只包含真实类别中的一个类的数据对象。而完整性指标值最小,是因为DBSCAN算法将低密度区域中的边缘数据对象,当作噪声点抛弃,导致完整性不高
6.6.2KMeans算法和Spectral算法,聚类速度大致相同,spectral算法的评价指标略优于KMeans算法。
7、参考答案
- 代码清单cluster_test.py
8、总结
完成本次实验,可以基本掌握KMeans聚类、谱聚类、DBSCAN聚类的相关理论及编程知识,主要包括模型的创建、训练、利用模型预测、评测模型等等。实验中对不同的聚类模型进行了各指标的比较,能够清晰的看出个算法的特点。
略优于KMeans算法。