深度学习(二):“分类”任务(理论——实践)
深度学习(二):“分类”任务(理论——实践)
- 图像分类
- 图像分类原理与挑战
- 快速上手卷积神经网络LeNet-5
-
- 应用:万能公式
- 卷积神经网络基础知识
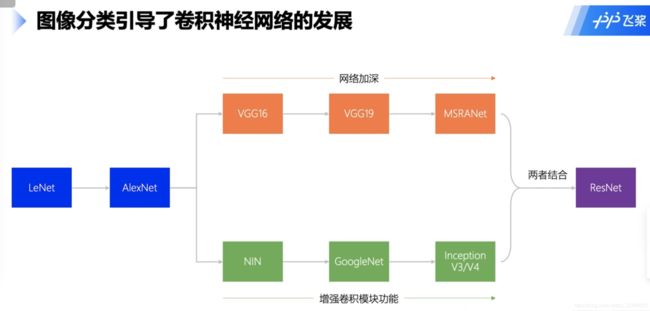
- 几种卷积神经网络(AlexNet、VGG、GoogleNet、ResNet)
- 十二生肖分类实战
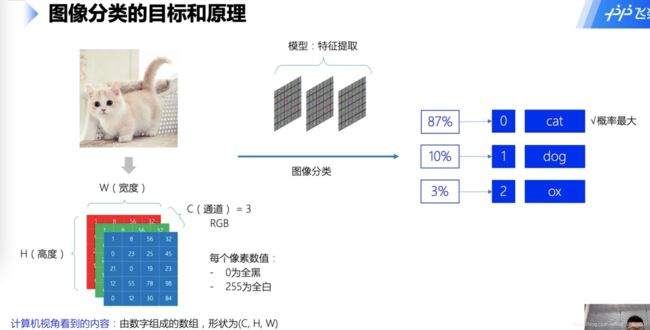
图像分类
二分类、多分类、多标签

图像分类原理与挑战
快速上手卷积神经网络LeNet-5
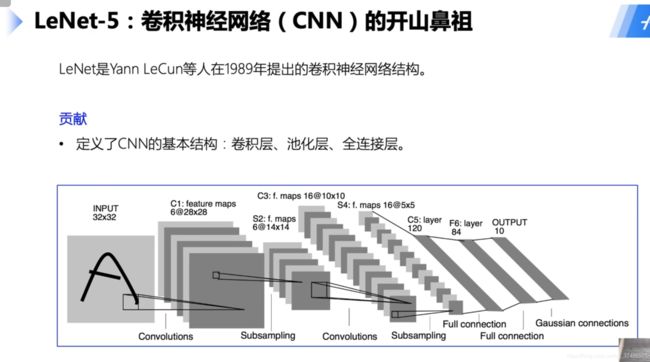
应用:万能公式

① 问题定义:图像分类,使用LeNet-5网络完成手写数字识别图片的分类。
② 数据准备:继续应用框架中封装好的手写数字识别数据集。
2.1 数据集加载和预处理
2.2 数据查看
③ 模型选择和开发
我们选用LeNet-5网络结构。LeNet-5模型源于论文“LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.”,
论文地址:https://ieeexplore.ieee.org/document/726791
3.1 网络结构定义
3.1.1 模型介绍

3.1.2 网络结构代码实现1
理解原论文进行的复现实现,因为模型论文出现在1998年,很多技术还不是最新。
3.1.3 网络结构代码实现2
应用了截止到现在为止新的技术点实现后的模型,用Sequential写法。
3.1.4 网络结构代码实现3
应用了截止到现在为止新的技术点实现后的模型,模型结构和【网络结构代码实现2】一致,用Sub Class写法。
3.1.4 网络结构代码实现4
直接应用高层API中封装好的LeNet网络接口。
3.1.4 模型可视化
通过summary接口来查看搭建的网络结构,查看输入和输出形状,以及需要训练的参数信息。
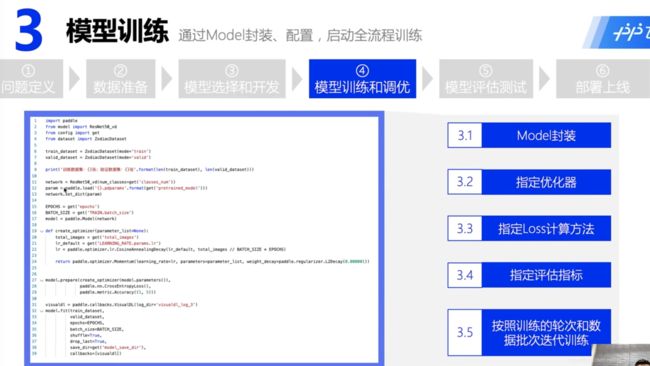
④ 模型训练和优化
模型配置:
优化器:SGD
损失函数:交叉熵(cross entropy)
评估指标:Accuracy
⑤ 模型评估
5.1 模型评估
5.2 模型预测
5.2.1 批量预测
使用model.predict接口来完成对大量数据集的批量预测。
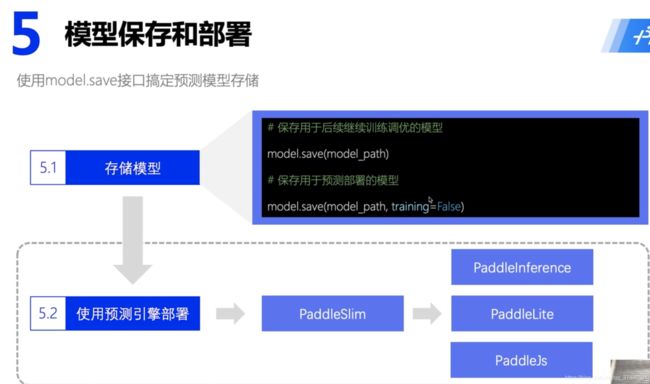
⑥ 部署上线:6.1 保存模型
#!/usr/bin/env python
# coding: utf-8
# # 回顾深度学习万能公式
#
# 
# # ① 问题定义
#
# 图像分类,使用LeNet-5网络完成手写数字识别图片的分类。
# In[2]:
import paddle
import numpy as np
import matplotlib.pyplot as plt
paddle.__version__
# # ② 数据准备
#
# 继续应用框架中封装好的手写数字识别数据集。
# ## 2.1 数据集加载和预处理
# In[3]:
# 数据预处理
import paddle.vision.transforms as T
# 数据预处理,TODO:找一下提出的原论文看一下
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 验证数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练样本量:{},测试样本量:{}'.format(len(train_dataset), len(eval_dataset)))
# ## 2.2 数据查看
# In[4]:
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
# # ③ 模型选择和开发
#
# 我们选用LeNet-5网络结构。
#
# LeNet-5模型源于论文“LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.”,
#
# 论文地址:[https://ieeexplore.ieee.org/document/726791](https://ieeexplore.ieee.org/document/726791)
#
# ## 3.1 网络结构定义
#
# ### 3.1.1 模型介绍
#
# 
#
# **每个阶段用到的Layer**
#
# 
# ### 3.1.2 网络结构代码实现1
#
# 理解原论文进行的复现实现,因为模型论文出现在1998年,很多技术还不是最新。
# In[39]:
import paddle.nn as nn
network = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # C1 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S2 平局池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # C3 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S4 平均池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # C5 卷积层
nn.Tanh(),
nn.Flatten(),
nn.Linear(in_features=120, out_features=84), # F6 全连接层
nn.Tanh(),
nn.Linear(in_features=84, out_features=10) # OUTPUT 全连接层
)
# **模型可视化**
# In[41]:
paddle.summary(network, (1, 1, 32, 32))
# ### 3.1.3 网络结构代码实现2
#
# 应用了截止到现在为止新的技术点实现后的模型,用Sequential写法。
# In[45]:
import paddle.nn as nn
network_2 = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2, stride=2),
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=400, out_features=120), # 400 = 5x5x16,输入形状为32x32, 输入形状为28x28时调整为256
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)
# **模型可视化**
# In[46]:
paddle.summary(network_2, (1, 1, 28, 28))
# ### 3.1.4 网络结构代码实现3
#
# 应用了截止到现在为止新的技术点实现后的模型,模型结构和【网络结构代码实现2】一致,用Sub Class写法。
# In[47]:
class LeNet(nn.Layer):
"""
继承paddle.nn.Layer定义网络结构
"""
def __init__(self, num_classes=10):
"""
初始化函数
"""
super(LeNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1), # 第一层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2), # 最大池化,下采样
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # 第二层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2) # 最大池化,下采样
)
self.fc = nn.Sequential(
nn.Linear(400, 120), # 全连接
nn.Linear(120, 84), # 全连接
nn.Linear(84, num_classes) # 输出层
)
def forward(self, inputs):
"""
前向计算
"""
y = self.features(inputs)
y = paddle.flatten(y, 1)
out = self.fc(y)
return out
network_3 = LeNet()
# **模型可视化**
# In[48]:
paddle.summary(network_3, (1, 1, 28, 28))
# ### 3.1.4 网络结构代码实现4
#
# 直接应用高层API中封装好的LeNet网络接口。
# In[50]:
network_4 = paddle.vision.models.LeNet(num_classes=10)
# ### 3.1.4 模型可视化
#
# 通过summary接口来查看搭建的网络结构,查看输入和输出形状,以及需要训练的参数信息。
# In[52]:
paddle.summary(network_4, (1, 1, 28, 28))
# # ④ 模型训练和优化
#
# 模型配置
#
# * 优化器:SGD
# * 损失函数:交叉熵(cross entropy)
# * 评估指标:Accuracy
# In[53]:
# 模型封装
model = paddle.Model(network_4)
# 模型配置
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估指标
# 启动全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式
# # ⑤ 模型评估
#
# ## 5.1 模型评估
# In[26]:
result = model.evaluate(eval_dataset, verbose=1)
print(result)
# ## 5.2 模型预测
#
# ### 5.2.1 批量预测
#
# 使用model.predict接口来完成对大量数据集的批量预测。
# In[27]:
# 进行预测操作
result = model.predict(eval_dataset)
# In[28]:
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))
# # ⑥ 部署上线
#
# ## 6.1 保存模型
# In[29]:
model.save('finetuning/mnist')
# ## 6.2 继续调优训练
# In[33]:
from paddle.static import InputSpec
network = paddle.vision.models.LeNet(num_classes=10)
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估函数
# 模型全流程训练
model_2.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=2, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式
# # 6.3 保存预测模型
# In[34]:
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)
卷积神经网络基础知识
1.神经元
2.神经网络
3.卷积操作:
3.1 单通道卷积
3.2 多通道卷积
3.3 多通道输出
3.4 Batch
4. 池化层
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
池化的作用:
池化层是特征选择和信息过滤的过程,过程中会损失一部分信息,但是会同时会减少参数和计算量,在模型效果和计算性能之间寻找平衡,随着运算速度的不断提高,慢慢可能会有一些设计上的变化,现在有些网络已经开始少用或者不用池化层。
Avg Pooling 平均池化:
对邻域内特征点求平均
优缺点:能很好的保留背景,但容易使得图片变模糊
正向传播:邻域内取平均
反向传播:特征值根据领域大小被平均,然后传给每个索引位置
Max Pooling 最大池化:
对邻域内特征点取最大
优缺点:能很好的保留一些关键的纹理特征,现在更多的再使用Max Pooling而很少用Avg Pooling
正向传播:取邻域内最大,并记住最大值的索引位置,以方便反向传播
反向传播:将特征值填充到正向传播中,值最大的索引位置,其他位置补0
5.Padding
角落边缘的像素,只被一个过滤器输出所使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,就会有许多3×3的区域与之重叠。 所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。 那么出现的一个解决办法就是填充操作,在原图像外围以0进行填充,在不影响特征提取的同时,增加了对边缘信息的特征提取。
另外一个好处是,我们在做卷积操作时,每经过一次卷积我们的输入图像大小就会变小,最后经过多次卷积可能我们的图像会变得特别小,我们不希望图像变小的话就可以通过填充操作。
6. 激活函数参考论文:https://arxiv.org/pdf/1811.03378.pdf
7. Dropout
论文:https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过随机丢弃部分特征节点的方式来减少这个问题发生。
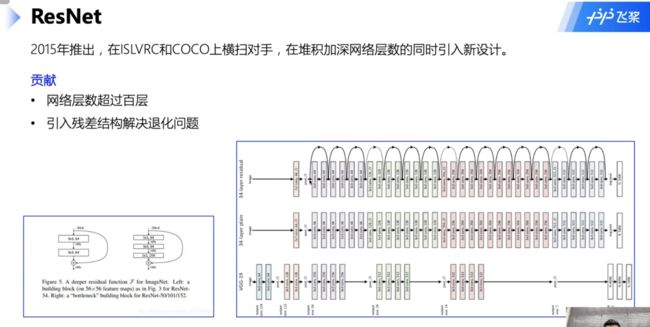
几种卷积神经网络(AlexNet、VGG、GoogleNet、ResNet)
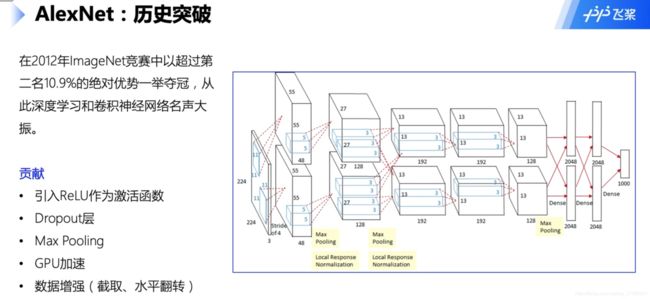
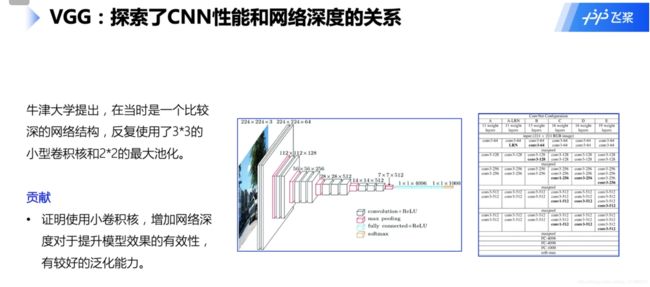
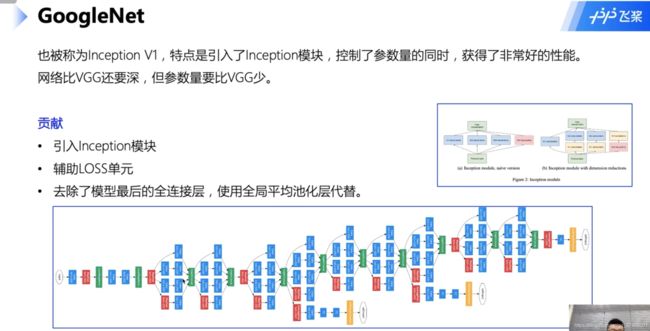
残差网络
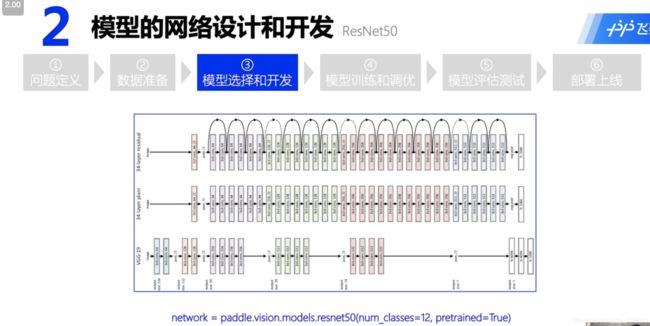
十二生肖分类实战
config.py:生成对应图片数据的标注
dataset.py:数据集定义