【项目文档】网页钓鱼URL过滤系统总结报告
本博客系作者原创,欢迎转载,转载请注明出处http://www.cnblogs.com/windcarp/
-
课题内容和要求
"钓鱼"是一种网络欺诈行为,指不法分子利用各种手段,仿冒真实网站的URL地址以及页面内容,或利用真实网站服务器程序上的漏洞在站点的某些网页中插入危险的HTML代码,以此来骗取用户银行或信用卡账号、密码等私人资料。网络钓鱼不仅给网民带来经济损失,更阻碍着互联网更深的发展。防御网络钓鱼是当前形势的需要。本题是实现一个简单的钓鱼URL过滤系统,基本功能主要有:
1、黑名单过滤:基于URL黑名单检测技术是当前比较流行的技术,它利用 URL 地址判断 URL 是否为钓鱼网站。该方法主要通过定期收集已经发现的钓鱼网站将其作为黑名单和当前 URL 进行判断。一般黑名单非常庞大,过滤时需要考虑速度,尽可能采用哈希;
2、白名单过滤:相对于黑名单,白名单过滤是指事先收集正常的网页URL,与当前 URL 进行匹配,如果在白名单中则肯定不是钓鱼URL;一般白名单也非常庞大,过滤时需要考虑速度,尽可能采用哈希;
3、黑/白名单管理:提供对黑白名单的添加、删除、检索;
4、网页下载:对不在黑白名单中的URL进行网页下载;
5、关键词过滤:对下载的网页进行关键词过滤;
高级功能主要有:
1、黑白名单的自动更新;
2、本组的创新设计有:
① 基于URL的钓鱼网站检测
② 基于网站内容的钓鱼网站检测
③ 手动更换皮肤
④ 山寨网站类型统计
⑤ 实现正规网站推荐
-
需求分析
2.1 模块功能描述
为了实现防御网络钓鱼这个最终需求,本系统实现了网页钓鱼URL过滤功能,包括:黑名单过滤(需求编号REQ_01)、白名单过滤(需求编号REQ_02)、黑/白名单管理(需求编号REQ_03)、网页下载(需求编号REQ_04)、关键词过滤(需求编号REQ_05)、黑白名单的自动更新(需求编号REQ_06)、基于URL的钓鱼网站检测(需求编号REQ_07)、基于网站内容的钓鱼网站检测(需求编号REQ_08)、手动换肤(需求编号REQ_09)、网站流量统计(需求编号REQ_10)、正规网站推荐(需求编号REQ_11)。
2.1.1 黑名单过滤(REQ_01)
基于URL黑名单检测技术主要通过定期收集已经发现的钓鱼网站,并将其作为黑名单和当前 URL 进行比对,从而判断其是否为钓鱼网站。
2.1.2 白名单过滤(REQ_02)
白名单过滤是指事先收集正常的网页URL,与当前 URL 进行匹配,如果在白名单中则肯定不是钓鱼URL。
2.1.3 黑/白名单管理(REQ_03)
黑/白名单管理提供对现有黑白名单的添加、删除、检索等其他操作。
2.1.4 网页下载(REQ_04)
实现对不在黑白名单中的URL进行网页下载功能,以备后台对网站进行分析实现拓展功能。
2.1.5 关键词过滤(REQ_05)
实现基于关键词对下载的网页进行过滤。
2.1.6 黑白名单的自动更新(REQ_06)
实现现有黑白名单的自动更新操作,其数据来源有定期从网站抓取当日钓鱼网站的数据添加数据库和按照对url和网页特征检测检测结果产生的钓鱼网站数据。
2.1.7 基于URL的钓鱼网站检测(REQ_07)
将待访问网址和钓鱼URL的特征向量进行比对,从而判断其是否为钓鱼网站。
2.1.8 基于网站内容的钓鱼网站检测(REQ_08)
通过对钓鱼网页身份特征及网页行为特征的深入分析,从网页中所包含的超链接这一重要特性出发,引入了网页URL身份这一新的概念,并在此基础上,结合网页行为特征提取出了网页的特征向量,为准确判定钓鱼网页提供了有效的依据。
2.1.9 手动换肤(REQ_09)
考虑用户体验,实现过滤系统界面的换肤功能。
2.1.10 网站流量统计(REQ_10)
对用户所访问的网站进行统计。
2.1.11正规网站推荐(REQ_11)
在用户使用该系统时系统能向其推荐已通过检测认证的正规网站。
2.2系统开发环境
Win 8.1 + Eclipse(Java)
Win 8.1 + MyEclipse2014(Java)
2.3系统开发语言
Java
2.4系统安全性需要
钓鱼URL过滤系统的软件设计应满足下列安全需求:
①不应造成用户个人信息及隐私的泄露和破坏;
②满足保护访问行为的安全原则;
③满足一定的安全完整性等级。
2.5系统可靠性需求
钓鱼URL过滤系统的可靠性应定义在给定的时间周期内、给定的条件下完成系统基本功能的概率。
-
概要设计
3.1 系统架构概述





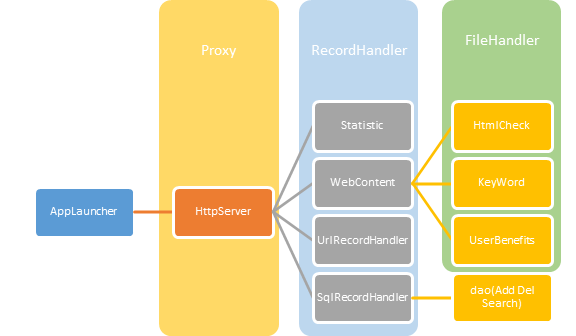
3.2 重要类概述(业务逻辑层)
3.2.1 Record
作用:用于记录每一次的http请求,是整个程序的核心类之一。
public class Record {
private String record; //访问的主机
private Date visitDate;
private int response;//response有多种状态,1代表通过,2代表通过并下载全部,0代表不通过并下载关键字
private String url;//为下载网页提供参数
private int fliter;//过滤开关的开启状态
}
3.2.2 HttpServer
作用:用于处理每一次的http请求,是整个程序的核心类之一。
// 一些与外界交互的标志位
static private boolean isrunning;
static private boolean keywordfilter;// 关键词过滤开关
static private boolean autodownload;
static private boolean urlcheck;
// 类变量与常量
static public int CONNECT_RETRIES = 5;
static public int CONNECT_PAUSE = 5;
static public int TIMEOUT = 10;
static public int BUFSIZ = 1024;
static public boolean logging = false;
static public OutputStream log = null;
// 传入数据用的Socket
protected Socket socket;
public static List<RecordHandler> recordHandlers = new ArrayList<RecordHandler>();
// 执行操作的线程
public void run()
//管道
void pipe(InputStream is0, InputStream is1, OutputStream os0,
OutputStream os1) throws IOException
//启动proxy
static public void startProxy(int port, Class clobj)
3.2.3 Webcontent
作用:用于处理Record.response=0或2时对网站进行关键词提取或下载(包含关键词过滤),是整个程序的核心类之一。
getOneHtml(String htmlurl)
//读取一个网页全部内容,输入为一个url返回网页源代码
public String getOneHtml(String htmlurl,String charset)
//重写此方法,用于读取不同编码格式的网页全部内容。输入为url和网页编码格式,输出为网页源代码
public String getwrite(String s)
//一个写入文件的函数,将分词写入文件,输入为要写入的字符串,输出为是否写入成功
public String getTitle(String s, boolean isnew)
//用于获得网页标题,输入为网页源代码,和布尔型控制变量,输出为网站标题。
public String filterString(String str)
//一个过滤输入流的方法,用于提取其中的中文关键词,输入为用于过滤的字符串,输出为过滤后的字符串
public String getcharset(String s, boolean isnew)
//获取网站编码格式的方法,输入为网页源代码,和布尔型控制变量,输出为网站编码格式。
public static String[] getLineFromTxt(File file, String split)
//一个读取文件函数,输入为文件位置
public byte[] filterword(byte srtbyte[], String charset)
//过滤关键词方法,用于过滤输入流,输入为源byte数组和网页编码格式,输出为byte数组
3.2.3 HtmlCheck&&UrlCheck
作用:从网页的Url和内容出发,提取出网页的身份,并结合网页ICP号,网页版权所有者及网页的行为,对钓鱼网页的特征进行了分析。最终以定量的方式,引入了钓鱼网页特征向量来表示钓鱼网页特征,为准确判定钓鱼网页提供了依据。
public class HtmlCheck implements FileHandler
public void handleFile(String filename, String charset, String url)
public class UrlCheck implements RecordHandler
public void handleRecord(Record record)
3.2.4 其他类与接口
类(接口) |
功能 |
AppLauncher |
用于设置启动时的初始值等,是整个应用程序的入口。 |
ConsoleRecordHandler |
调试用,用于在窗口输出中间值。 |
FileHandler |
接口,继承类需实现FileHandler方法。 |
Keyword |
用于从所给网站中提取中文关键词。 |
RecordHandler |
接口,继承类需实现RecordHanler方法。 |
RecordUrlServer |
用于实现从网站中下载文件(钓鱼网站数据)以实现自动更新 |
SQLRecordHandler |
提供Record在数据库中查询的功能,与DBUtil协同工作实现查询。 |
Statistic |
用于统计网站访问的流量,以供在图表中可视化显示。 |
UserBenefit |
用于通过KeyWord生成的关键词动态生成钓鱼网站提示页并实现正规网站推荐。 |
3.3 工作状态自动机(业务逻辑层)
系统处于工作状态时状态转移的自动机如图所示。
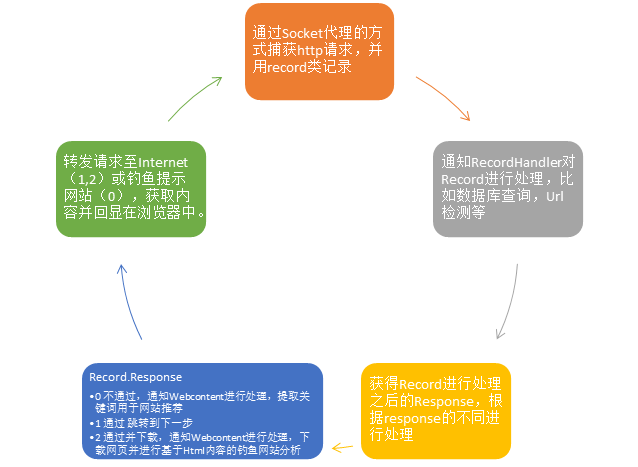
3.4 数据库、网络数据自动更新与界面概要
前端界面
界面使用Swing JFreeChart ProgressBar实现,界面实现过程中使用包:
Ui包:JFrameGame、JFreeChartTip、JPanelGame、Layer、LayerBackGround、LayerBlack、LayerText、Layertip、LayerWhite、ProgressBar。
Swing图像界面的设计:
JFrameGame:Frame面板,包括Button,TextArea,TextField,
JPanelGame:Panel面板,实例化configfactory对象,读取xml文件,处理各个layer对象。
Layer:面板对象,封装方法:protected void creatWindow(Graphics g) 创建窗口方法,将一个png外框通过此方法改变成任意比例,大小。
LayerBackGround:背景图像方法,改变背景图片,监听Begin按钮的Action 与Skin按钮的Action。
LayerBlack:读取xml文件的黑名单class数据来绘制黑名单框,与黑名单框的TextField。
LayerWhite:读取xml文件的白名单class数据来绘制白名单框,与白名单框的TextField。
LayerText:读取xml文件的滚动名单class数据来绘制滚动名单框,与滚动名单框的TextArea。
Layertip:读取xml文件的滚动名单class数据来绘制tips提示框,反应本地流量框。
JFreeChartTip:读取本地流量Log日志,使用JFreeChart来绘制饼图。
ProgressBar:绘制进度条框图,反应自动更新时文件写入数据库时进度。
Config包:ConfigFactory、ConfigReader、GameConfig、LayerConfig
LayerConfig:用于承载xml文件所使用类,public LayerConfig(String className, int x, int y, int w, int h)
ConfigReader:用于读取xml文件所使用类。
GameConfig:调用LayerConfig去读取xml文件,private void setuiConfig(Element frame)
ConfigFactory:将读取xml文件方法封装成factory方法,便于调用。
网页下载模块:
GetUrlDownload、URLRunnable、ResourceURLServer
ResourceURLServer:链接网页,下载最新的黑名单csv到本地
GetUrlDownload:csv文档读写类。
URLRunnable:文件后台更新线程,读取本地csv。调用GetUrlDownload读取,并写入数据库。
数据库使用类:
AddDao:添加数据
DeleteDao:删除数据
SearchDao:寻找数据
Dbutil:建立数据库连接
通过实例化Dbutil类与数据库建立连接,根据不同的要求,与数据库进行增删查改功能。(调用上述三个不同的方法)
3.5 系统技术亮点
数据库部分:使用了哈希索引,增大了查找的效率,插入数据时也采用了先堆处理的方式,减少数据库链接次数与数据库插入次数,增加效率。
UI部分:使用了各种插件,使用了各种jar包,包括:JFreeChart来生成饼图,ProgressBar来生成自动更新进度条,并使用了xml配置文件,告别硬编码。
代理部分:使用透明代理实现且回显网页并进行推荐、在网页处理部分采用jsoup(读取DOM树进行解析)与cpdetector(对网页编码进行识别)等库、正则表达等使系统效果更好。
四、详细设计
以下以系统对数据流的处理大致流程对每个类的详细设计进行说明。
4.1 AppLauncher
系统在启动时调用AppLauncher,AppLauncher是HttpServer的一个子类,在类中重写了一部分方法,启动时首先启动界面,并在状态显示框中显示系统的启动状态,然后连接数据库,设置KeywordFliter等参数为默认值,然后系统得以正常工作。
代码见压缩包中AppLauncher.java。
4.2 HttpServer
系统启动Httpserver类中的run方法进行数据流的处理工作。Startproxy方法在Applauncher中被调用之后创建新线程,在while循环中接受数据包并进行处理,首先与浏览器建立Socket连接,然后获取http请求后根据格式进行分析,提取出主机和url请求,新建Record类并将参数写入,同时通知各recordhandler进行处理,处理之后的response作为请求下一步的处理依据。
如果response=0时,说明可以判断为钓鱼网站,则直接将http请求丢弃,并返回一个经过动态处理的网页,里面说明了网站为钓鱼网站,并为用户推荐了经过认证的网站。
如果response=1时,说明非钓鱼网站,则正常发送http请求到Internet,通过pipe函数对数据流进行读写,并将返回数据回显在浏览器中。
如果response=2时,说明不能明显确定,按照需求将下载该网页进行进一步分析。
代码见HttpServer.java。
4.3 Urlcheck
系统在数据包处理时调用urlcheck类中的方法进行钓鱼网站的判断(既没有黑名单也没有白名单匹配的情况下),其中我们在仔细研究之后使用url特征向量的方法来判断一个网站是否有是钓鱼网站的嫌疑,并实现黑白名单库的自动更新。特征向量有9个分量,分别是
1、判断whois值,作为钓鱼网站一般whois值rank应该比较低,而正规网站也就是钓鱼网站模仿的对象应该rank都比较靠前,通过向data.alaxa.com请求whois数据来判断网站是否为正规网站或者钓鱼网站。
2、通过正则表达式判断url是否为ip地址,如果是则风险等级增加。
3、通过正则判断url中是否有@符号、长度是否大于23个字符、长度是否小于7个字符、'.'的个数是否大于4个、'//'的个数是否大于4个、'http'的个数是否大于1个、是否含有account等敏感词来判断风险等级。
如果风险等级大于阈值(这里根据实验效果取6)则判断为风险钓鱼网站。
程序中采用了htmlpaser和正则表达式来实现功能,使程序功能更加强大,效率更高。
代码参见UrlCheck.java。
4.4 SqlRecordHandler
系统通知recordhandler对Record进行处理,其中黑白名单的查询即在此类中进行。在黑白名单中查询之后,如果黑名单命中则response=0,白名单命中response=1,否则response=2。response=2的情况Record还将在UrlCheck中进行检测,此处不再赘述。
类的结构比较简单,代码参见SqlRecordHandler.java。
4.5 WebContent&&KeyWord
系统在Record.response=0或=2时都将对网页进行进一步的处理,这两部分的功能统一在Webcontent中实现。
程序首先对访问的html网页进行下载,首先获取网页的charset以解决乱码的问题,然后对网页数据进行下载。
当response=0时,为了实现正规网站推荐的高级功能,Webcontent对其关键词进行提取,其中用到了中文分词和词频统计中的相关内容,统计之后将关键词编码之后写入返回提示钓鱼网站的网页页面代码中。
当response=2时,直接将html写入html文件中,其文件名为系统当前的时间以防止重复。
代码参见Webcontent.java和Keyword.java。
4.6 Statistic
系统为了实现对网络流量进行统计的功能,专门设计了Statistic类对访问数据进行统计。类比较简单,实现每个记录中提取host与url添加在list和set数组中。
代码参见Statistic.java。
4.7 UserBenefits
系统为了实现为用户推荐正规网站的功能,对Webcontent中提取的关键词、Webcontent中下载的网页交由此类进行处理,并动态生成为用户推荐的网站,具体实现即对关键词编码,通过文件读写写入phishing.html文件中。
代码参见UserBenefits.java,phishing.html。
4.8 HtmlCheck
系统的高级功能之一是通过对html内容的判断来确定是否为钓鱼网站,程序中通过特征向量检测的方式实现这一功能。我们从网页中的超链接这一角度出发,提取出网页的身份,并结合网页ICP号,网页的行为等对钓鱼网页的特征进行了分析。最终以定量的方式,引入了钓鱼网页特征向量来表示钓鱼网页特征,为准确判定钓鱼网页提供了依据。其判据有:
1、是否包含form
2、网页的ICP证号
3、网页域名与网页URL身份的一致性
4、空连接
5、外部链接以及指向网页URL身份的外部链接
6、外部请求及指向网页URL身份的外部请求
在方法中我们通过jsoup中提供的网页DOM的内容解析的方式,对网站中html的各个内容进行提取和分析,并针对上文中给出的特征进行判断得出网站是钓鱼网站的风险等级,如果高于某一个阈值(项目中取3)则判断为钓鱼网站。
代码参见HtmlCheck.java。
4.9 数据库
系统中使用Mysql作为数据库为系统提供数据支持。这样做第一增加了系统工作的效率,避免了程序打开时加载的时间和内存开销,第二方面也方便了数据库的维护与使用。数据库中使用表:urlblack,urlblack。
CREATE TABLE `urlblack` (
`url` varchar(500) DEFAULT NULL,
`url_crc` char(11) DEFAULT '0',
KEY `url` (`url`) USING HASH
) ENGINE=MEMORY DEFAULT CHARSET=utf8;
CREATE TABLE `urlwhite` (
`url` varchar(500) DEFAULT NULL,
`url_crc` char(11) DEFAULT '0',
KEY `url` (`url`) USING HASH
) DEFAULT CHARSET=utf8;
存储方式黑名单使用memory形式存储,因为考虑到黑名单的更新速度比较快,每天作废的钓鱼网站数目比较大,所以需要每天更新。
存储的字段为url url_crc,url为直接存储的url域名,url_crc为11位长度的urlcrc值,作为该url的哈希索引,用于查找匹配。
增删查所使用的语句如下。
增:String sql = "insert into " + log + " values('" + url + "',crc32('"
+ url + "')) ";
删:String sql = "delete from " + log + " where url_crc=crc32('" + url
+ "') or url='" + url + "'";
查:String sql = "select * from " + log + " where url='" + url
+ "' and url_crc=CRC32('" + url + "')";
所使用的类如下所示。
AddDao:main method:public static int Add(Connection con, String url, String log)
DeleteDao:main method:public static int Delete(Connection con, String url, String log)
SearchDao:main method:public static int Search(Connection con, String url, String log)
(Con:实例化的dbutil.con,Url:域名,Log:使用的名单名称(black or white))
Dbutil::main method:public Connection getCon()(建立连接) public void closeCon(Connection con)(断开连接)
具体代码参见AddDao.java, DeleteDao.java, SearchDao.java, Dbutil.java。
4.10 数据库自动更新
系统中数据库的自动更新有两种形式,一种是从Url特征、Html内容特征检测使数据库自动更新,另外一种是从提供钓鱼网站库的网站自动下载钓鱼网站数据添加进数据库。
系统首先调用ResourceUrlServer新建线程,从所给网站下载csv文件,然后通过GetUrlDownload类对下载的csv文件进行过滤,提取中URL的相关内容,具体通过正则表达式来实现。最后,UrlRunnable类中新建线程,通过构造数据库插入语句,将所获取的所有url插入数据库中。至此完成数据库自动更新。
代码具体请参见ResourceUrlServer.java, GetUrlDownload.java, UrlRunnable.java。
4.11 界面
系统中界面的实现主要是运用了java中的swing。界面实现类有:
JFrameGame、JFreeChartTip、JPanelGame、Layer、LayerBackGround、LayerBlack、LayerText、Layertip、LayerWhite、ProgressBar。
Layer类:封装前端框架,调用时,通过ConfigFactory类来调用读取xml文件,读取配置好的前端界面参数,来实现不同组件的摆放位置。封装好的Layer类,实现通过读取需要摆放的框图左上角坐标,长,宽四个参数即可在界面中实现一个框架。其余Layerxxxx类通过实继承Layer类来实现不同组件位置,将不同组件分开,便于管理,符合面向对象思想。
JFrameGame:实现Frame面板,为各个组件增加监听,处理不同组件的按钮点击事件,如begin按钮点击开启服务器,关闭服务器,增删查按钮建立数据库连接,skin按钮实现自动换肤,tip按钮调用JFreeChart根据本地数据来显示流量饼图,fliter按钮开启下载网页并过滤功能,refresh开始更新本地数据库,并弹出ProgressBar组件事实看到更新进度,鼠标监听事件,为不同组件实现不同的样式,包括按钮的图标设计,点击效果(按下时显示不一样的图片),按钮边框样式。
JFreechart:读取本地Log日志,显示一个饼图,根据不同网站访问次数不同,占饼图比例不等。
ProgressBar:建立一个按钮监听,按下时建立数据库连接,获得数据库更新总量与当前连接数,计算出当前更新进度百分比。开设两个线程,一个time线程用于每500ms监听一次事件,判断当前进度是否变化,变化则改变进度条,一个线程事实更新数据库,提供进度参数。
代码实现详细见config包(ConfigFactory.java , ConfigReader.java , GameConfig.java , LayerConfig.java)与ui包(JFrameGame.java , JFreeChart.java, JpanelGame.java, Layer.java, LayerBackGround.java , LayerBlack.java , LayerText.java , LayerWhite.java , ProgressBar.java)。
4.12 其他
系统中还有许多接口以及调试用的类,统一在这里详述如下。
接口:RecordHandler
public interface RecordHandler {
public void handleRecord(Record record) throws UnknownHostException, IOException, Exception;
}
接口:FileHandler
public interface FileHandler {
public void handleFile(String filename, String charset,String url)
throws Exception;
}
类:ConsoleRecordHandler
调试用,在系统标准输出中打印record的信息。
public void handleRecord(Record record) {
System.out.println("@@@@@@@"+record.getRecord());
}
}
类:Main
界面开始工作的入口类。
public class Main {
public Main() {
new JFrameGame().setVisible(true);
}
}
五、测试数据及其结果分析
5.1 数据库方面
数据库测试数据,当天最新数据csv文件写入数据库,因为csv文件数目较大,当天最新的url数目为2万条左右,所以在数据库处理时对效率有较高的要求,首先,数据库链接次数需要控制,挡数据库链接次数超过100的时候,Mysqsl会自我保护拒绝访问,所以必须一次链接,多次写入,并且,如果每次写入一条url时使用一句mysql指令,2万次写入,会使得效率异常低,考虑到效率的原因,每次写入数据库时,先建立缓存块,把多条数据放在一起pstmt.addBatch(); 当数据块满或者文件读完之后,将这些指令用一条sql指令写入,大大增加了数据库插入的效率。
测试数据:17567条url指令,花费时间:3s
插入数据库前校验url是否存在,通过建立的hash索引匹配urlcrc值,加大查找语句的效率。
测试数据:2天的csv文件:38759条url指令,存在重复情况,再次写入数据库,花费时间:5s
删除指令同样使用先校验再删除的模式,删除时同样通过hash索引匹配urlcrc值,加大删除语句的效率。
测试数据:指定url删除,瞬间。
5.2 网页内容方面
Webcontent测试数据及分析如下所示。
1.分词后的结果。

2.写入文件的结果。

3.用于form表单判断的文本格式数据。

4.提取网页信息过后的暂存文本。

5.提取网页源代码和网页编码格式的测试结果。

6.提取百度首页的全部测试结果。
5.3界面测试
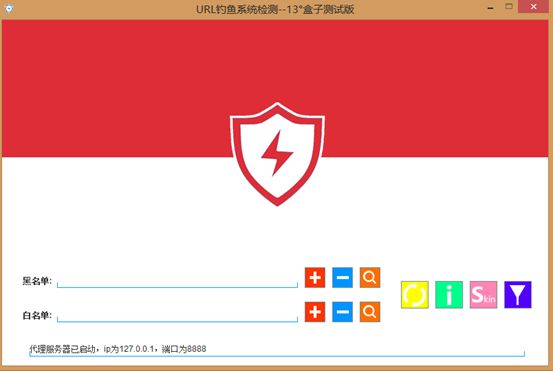
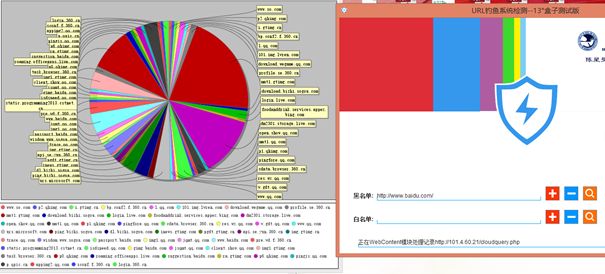
效果图片。
背景图片,中间的盾形按钮为开关,用于开启关闭服务器,开启时背景图和按钮都变蓝色。
黑白名单右边三个按钮分别为对域名的:增删查。
最右边四个按钮分别为:自动更新、流量统计、自动换肤、内容过滤。
自动更新:从网络端下载.csv的黑名单文件,交给后台处理后批量导入数据库中。
流量统计:由Log日志记录所有的访问记录,包括访问次数,由JFreeChart展示
自动换肤:切换背景图。
内容过滤:下载当前访问网页,并将关键词过滤、替换。
5.4业务逻辑测试
具体效果见整体测试。
5.5整体测试
启动界面。
启动界面,代理服务器启动,默认工作处于暂停状态,点击中间盾牌开关开始工作。界面设计本着简洁美观的原则,通过色彩的搭配和界面的结构设置,以及精心安排的创意功能为用户提供一个很好的用户体验。
自动换肤功能。点击右下角Skin按钮。

首先测试代理功能。
测试下载功能。
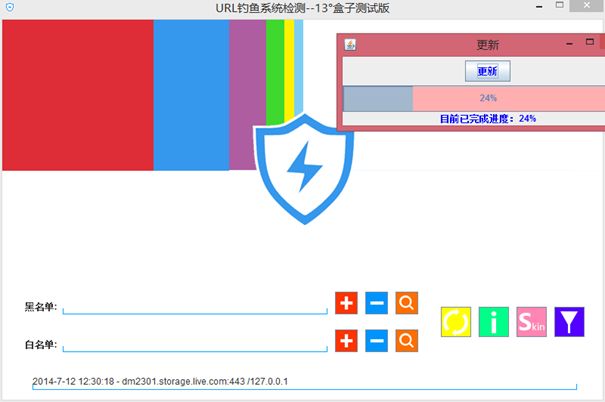
测试网络钓鱼网站数据自动更新功能。
![]()
查看数据库数据。
数据库增删改。
第二次添加。
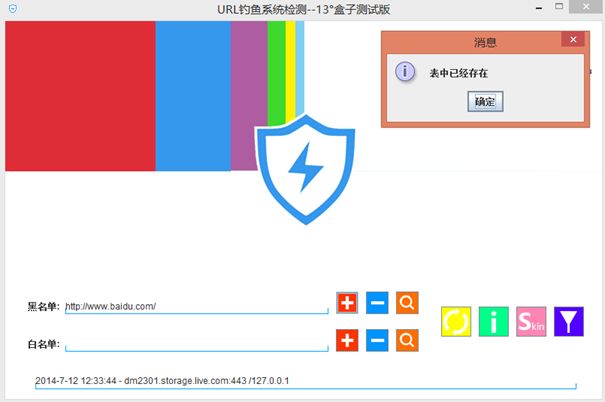
也可以删除或查询。
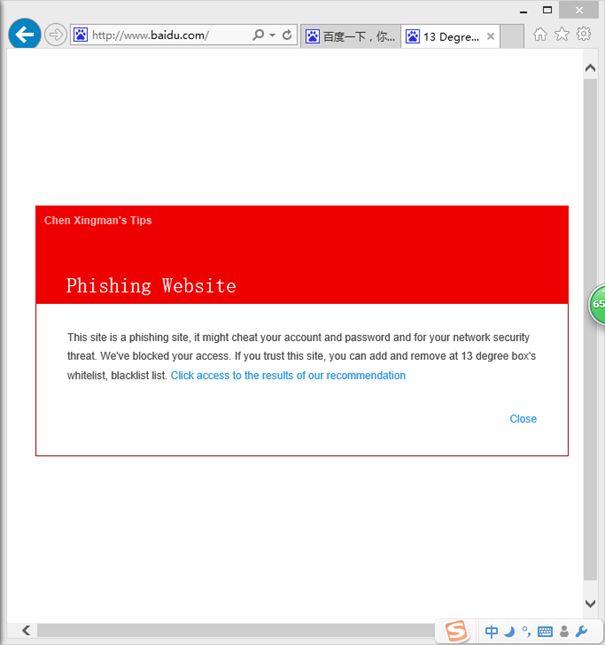
添加过黑名单之后再次访问www.baidu.com,
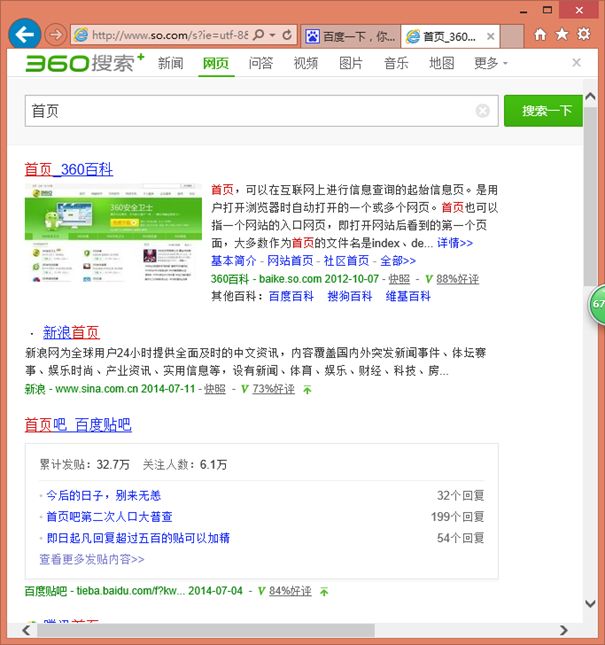
返回我们准备的网页。点击close可以直接关闭,点击推荐链接如下。
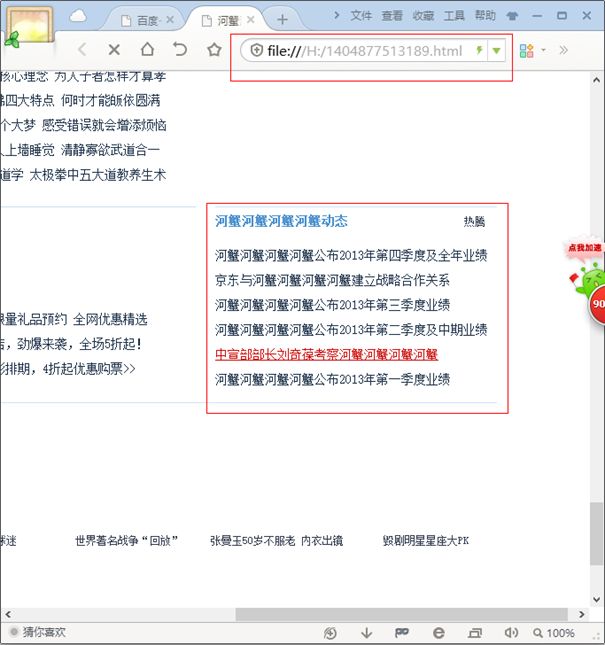
关键字符串过滤功能。这里设置过滤字符串为腾讯,替换为河蟹河蟹河蟹河蟹。
流量统计功能。
效率方面,除下载和统计图生成,每一步操作均可以在1s内完成。
六、调试过程中的问题
1. 在代理工作效率方面,在HttpServer只有代理功能工作时,在默认socket参数的情况下,经测试访问首页类网站(平均大小在300-500KB)的时候需要约1分钟时间。通过查找资料和调试发现这种现象与socket默认参数有关,这里设置相关参数如下:
static public int CONNECT_RETRIES = 5;
static public int CONNECT_PAUSE = 5;
static public int TIMEOUT = 10;
static public int BUFSIZ = 1024;
之后测试访问时间缩短到5s之内,效率提高约12倍。
2. 数据库部分,使用Mysql数据库,连接数据库时,一开始写入数据使用的表urlcrc值所使用的类型是int(11),但是数据库生成11位值报错,换成char(11)后成功写入,可是不知道错误原因。
数据库自我保护:Mysql当连接次数大于100次后拒绝访问,通过修改写入数据库方式解决,
数据库默认表大小过小:修改数据库配置,改变参数解决问题。
数据库连接不释放:一开始连接数据库之后,没有释放连接,导致随着程序的运行,数据库访问的效率越来越低,及时释放即解决问题。
3. Swing界面,使用组件包括JButton,JTextField,JTextArea,JFreeChart,ProgressBar的效果和预想的不一样,一开始硬编码导致界面设计修改麻烦,后期改用xml控制,解决部分问题。组件一些控制效果实现与预想的不太一样。
ProgressBar使用过程需要开设多个线程,对time类不熟悉,导致使用过程中遇到了许多问题。
4. 字符串匹配方面。多字符串匹配可用正则表达式进行大多数情况的匹配,但此次实验中由于要访问不同网页数据,其编码格式的不同以及部分代码的微小差别导致正则表达式较难以书写,因而在程序中采用了较为笨拙的对特定字符判定的方式,通过几次的修改力求简化表达式以提高程序效率。后续改进版本中我们力求使用KMP算法对字符串匹配进行效率提高,KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。可以证明它的时间复杂度为O(m+n).。在使用了KMP算法后我们又发现了一种基于AC自动机的多模匹配算法,其典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。一定程度上解决了效率的问题。而在正则表达式中提取中文字符一直存在调试问题,后为力求程序简洁放弃了一部分效率问题,毕竟和读取写入源代码相比,此处的判断所占用时间不大,在正则匹配中.?*的多字符串匹配起到了很重要的作用,由于正则表达式规则多,十分复杂,此次实验只是使用到了极少的一部分,还有更多的知识需要我们去学习和掌握,因而在今后一定可以在此处更加巧妙地使用正则表达式以提高程序的效率。