第二章 复杂的HTML解析(上)
2.1 不是一直都要用锤子
看到这个小标题是不是想问:啥是锤子?
原文中有一段文字:
当米开朗基罗被问及如何完成《大卫》这样匠心独具的雕刻作品时,他有一段著名的回
答:“很简单,你只要用锤子把石头上不像大卫的地方敲掉就行了。”
锤子就是一个工具,为了帮助我们更好的获得我们想要得到的东西。但是,我们的标题叫“不要一直都要使用锤子”,就说明,我们在爬取信息时,不是要把多余部分都“敲掉”,而是直接找到我们想要的部分,把它保存下来。
用锤子将不需要的地方都敲掉,这话听起来是多么的粗暴。而我们的爬虫可是一个技术活儿,这么粗暴的方式并不适用于我们。所以作者告诉我们,写爬虫要用脑子,多思考,多使用技巧。
千万不要不经思考就写代码,一定要三思而后行。
接下来会介绍基于位置、上下文、属性和内容选择标签的标准方式和创新方式。这里展示的技巧如果运用得当,将会助你在编写更稳定可靠的网络爬虫的路上走得更远。
2.2 再端一碗BeautifulSoup
这一节将介绍通过属性查找标签的方法,标签组的使用,以及标签解析树的导航过程
基本上,你遇到的每个网站都有层叠样式表(cascading style sheet,CSS)。虽然你可能会认为,专门为了让浏览器和人类可以理解网站内容而设计一个展现样式的层,是一件愚蠢
的事,但是 CSS 的 发 明却是网络爬虫的福音。CSS 可 以 让 HTML 元素呈现出差异化,使
那些具有完全相同修饰的元素呈现出不同的样式。
也就是说,通过不同的标签属性,我们能很快的找到我们想要的东西。
这里可能有人对CSS不了解,所以不得不提一下前端“三剑客”了(HTML+CSS+JavaScript)。
1、HTML,中文译为超文本标记语言,是构成网页文档的主要语言,主要用来实现静态页面。一般情况下,用户看到的文字,图形,动画,声音,表格,链接等元素都是由HTML语言描述的。“超”,即超越文本,指可设置样 式、可展示图片,而最核心的是“超级链接”,可以链接到其他文档。由于HTML是由标签组成的,所以使用HTML就是在基本结构上加标签。
2、CSS中文译作层叠样式表,用于控制网页样式
3、JavaScript是一种网页脚本语言。通过在HTML网页中直接嵌入Javascript脚本,可以实现响应浏览器事件,读写HTML元素内容,更改HTML元素样式等功能。JavaScript代码可以很容易的嵌入html页面中。也可以单独将Javascript代码写在一个文件中。浏览器对JavaScript脚本程序进行解释执行
详细内容可看这位大佬的文章:(27条消息) 前端“三剑客”——HTML,CSS,JS_欢迎来到 晨 的博客-CSDN博客_前端三剑客 https://blog.csdn.net/qq_44002167/article/details/101382839?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700934616780274176783%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164700934616780274176783&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-101382839.pc_search_result_cache&utm_term=%E5%89%8D%E7%AB%AF%E4%B8%89%E5%89%91%E5%AE%A2&spm=1018.2226.3001.4187 下面让我们创建一个网络爬虫来抓取这个网页:
https://blog.csdn.net/qq_44002167/article/details/101382839?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700934616780274176783%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164700934616780274176783&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-101382839.pc_search_result_cache&utm_term=%E5%89%8D%E7%AB%AF%E4%B8%89%E5%89%91%E5%AE%A2&spm=1018.2226.3001.4187 下面让我们创建一个网络爬虫来抓取这个网页:
http://www.pythonscraping.com/pages/warandpeace.html
页面是这样的,花花绿绿的,

其实它是列夫托尔斯泰的著名长篇小说《战争与和平》的节选

我们要做的事情是:
在这个页面里,小说人物的对话内容都是红色的,人物名称都是绿色的。我们要抓取所有的绿色的名称然后放在一张表里。
我们返回刚才的页面,按下F12,查看源代码 ,通过观察发现:
xxxxxxx:这个标签中间的字符就是页面里绿色的部分。
例如:
green">Anna Pavlovna
网络爬虫可以通过 class 属性的值,轻松地区分出两种不同的标签。

现在我们就写个爬虫,获取小说中人物的名称:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://www.pythonscraping.com/pages/warandpeace.html')
bs = BeautifulSoup(html.read(),'html.parser')
nameList = bs.findAll('span', {'class':'green'})
for name in nameList:
print(name.get_text())
* findAll也可以写作find_all
通 过 BeautifulSoup 对象,我们可以用 find_all 函数提取只包含在
标签里的文字,这样就会得到一个人物名称的 Python 列表
输出结果(代码执行以后就会按照《战争与和平》中的人物出场顺序显示所有的人名。):
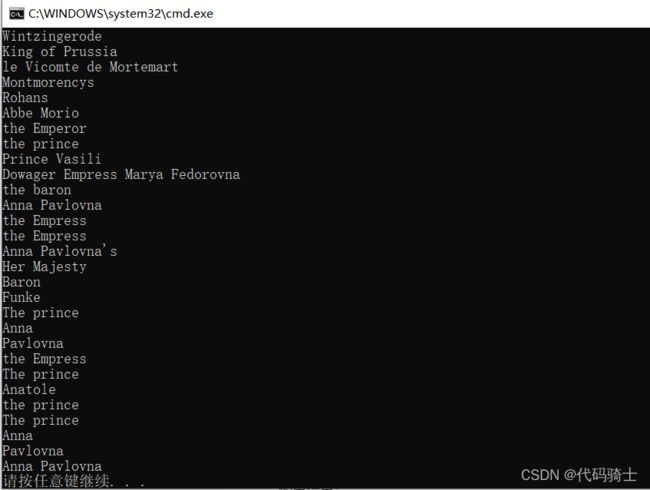 实现之后是不是感觉很兴奋很神奇,那么这有是如何实现的呢?
实现之后是不是感觉很兴奋很神奇,那么这有是如何实现的呢?
之前,我们调用 bs.tagName 只能获取页面中指定的第一个标签。现在,调用
bs.find_all(tagName, tagAttributes) 可以获取页面中所有指定的标签,不再只是第一
个了。
获取人名列表之后,程序遍历列表中所有的名字,然后打印 name.get_text(),就可以把标
签中的内容分开显示了。
.get_text():
.get_text() 会清除你正在处理的 HTML 文档中的所有标签,然后返回一个只包含文字的 Unicode 字符串。假如你正在处理一个包含许多超链接、段落和其他标签的大段文本,那么 .get_text() 会把这些超链接、段落和标签都清除掉,只剩下一串不带标签的文字。
用 BeautifulSoup 对象查找你想要的信息,比直接在 HTML 文本里查找信息要简单得多。通常在你准备打印、存储和操作最终数据时,应该最后才使用 .get_text()。一般情况下,你应该尽可能地保留 HTML 文档的标签结构。
2.2.1 BeautifulSoup的find()和find_all()
BeautifulSoup 里 的 find() 和 find_all() 可能是你最常用的两个函数。借助它们,你可以
通过标签的不同属性轻松地过滤 HTML 页面,查找需要的标签组或单个标签。
这两个函数非常相似,BeautifulSoup 文档里两者的定义就是这样:
find_all(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
下面是这两个函数中的参数解释:
1、标签参数 tag 前面已经介绍过——你可以传递一个标签的名称或多个标签名称组成的
Python 列表做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有标题标签
的列表:
.find_all(['h1','h2','h3','h4','h5','h6'])
2、属性参数 attributes 用一个 Python 字典封装一个标签的若干属性和对应的属性值。例如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.find_all('span', {'class':{'green', 'red'}})
3、递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果 recursive 设置为 True,find_all 就会根据你的要求去查找标签参数的所有子标签,以
及子标签的子标签。如果 recursive 设 置 为 False,find_all 就只查找文档的一级标签。
find_all 默认是支持递归查找的(recursive 默认值是 True); 一 般 情 况 下 这 个 参 数 不 需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递
归参数。
4、文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。假如我们想查找前面网页中包含“the prince”内容的标签数量,可以把之前的 find_all 方法换成下
面的代码:
nameList = bs.find_all(text='the prince')
print(len(nameList))
输出结果为“7”。
5、范围限制参数 limit 显然只用于 find_all 方法。find 其实等价于 limit 等于 1 时的 find_all。如果你想获取网页中的前 x 项结果,就可以设置它。但是要注意,设置这个参数之后,获得的前几项结果是按照网页上的顺序排序的,未必是你想要的那前几项。
6、还有一个关键词参数 keyword,可以让你选择那些具有指定属性的标签。例如:
title = bs.find_all(id='title', class_='text')
上述代码返回第一个在 class_ 属性中包含单词 text 并且在 id 属性中包含 title 的标签。
需要注意的是,通常情况下,页面中每个 id 的属性值只能被使用一次。因此在实际情况
中,上面的代码可能并不实用,而以下代码可以达到同样的效果:
title = bs.find(id='title')
2.2.2 其他BeautifulSoup对 象
看到这里,你已经见过 BeautifulSoup 库里的两种对象了。
BeautifulSoup对象
前面代码示例中的 bs。
标签Tag对象
BeautifulSoup 对象通过 find 和 find_all,或者直接调用子标签获取的一列对象或单个
对象,就像:
bs.div.h1
但是,这个库还有另外两种对象,虽然不常用,却应该了解一下。
NavigableString对象
用来表示标签里的文字,而不是标签本身(有些函数可以操作和生成 NavigableString
对象,而不是标签对象)。
Comment对象
用来查找 HTML 文档的注释标签,。
这 4 个对象是你用 BeautifulSoup 库时会遇到的所有对象(写作本书的时候)。
2.2.3 导航树
find_all 函数通过标签的名称和属性来查找标签 。但是如果你需要通过标签在文档中的位
置来查找标签,该怎么办?这就是导航树(navigating trees)的作用。
用一个网页的源代码举例:
https://www.pythonscraping.com/pages/page3.htmlhttps://www.pythonscraping.com/pages/page3.html

在后面几节内容里,我们仍然以这个 HTML 标签结构为例。

1. 处理子标签和其他后代标签
在计算机科学和一些数学领域中,你经常会听到“虐子”事件(比喻对一些子事件的处理 方 式 ): 移 动 它 们 , 储 存 它 们 , 删 除 它 们 , 甚 至 杀 死 它 们 。 值 得 庆 幸 的 是 , 这 里 只 选择它们。
和许多其他库一样,在 BeautifulSoup 库里,孩 子(child) 和后 代(descendant)有显著的不同:
子标签:就是父标签的下一级
而后代标签:是指父标签下面所有级别的标签。
举个例子:

tr 标签是 table 标签的子标签,而 tr、th、td、img 和 span 标签都是table 标签的后代标签
一句话总结就是:所有的子标签都是后代标签,但不是所有的后代标签都是子标签。
一般情况下,BeautifulSoup 函数总是处理当 前标签的后代标签。例如,bs.body.h1 选 择 了body 标签后代里的第一个 h1 标签,不会去找 body 外面的标签。bs.div.find_all("img") 会找出文档中的第一个 div 标签,然后获取这个 div 后代里所有 img 标签的列表。
如果你只想找出子标签,可以用 .children 标签:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
for child in bs.find('table',{'id':'giftList'}).children:#打印table标签中id赋值为giftList标签的子标签
print(child)输出结果:

这段代码会打印 giftList 表格中所有产品的数据行,包括最开始的列名行。如果你用
descendants() 函数而不是 children() 函数,那么就会打印出二十几个标签,包括 img 标
签、span 标签,以及每个 td 标签。掌握子标签与后代标签的差别十分重要!
2. 处理兄弟标签
BeautifulSoup 的 next_siblings() 函数使得从表格中收集数据非常简单,尤其是带标题行
的表格:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
for sibling in bs.find('table',{'id':'giftList'}).tr.next_siblings:
print(sibling)输出结果:
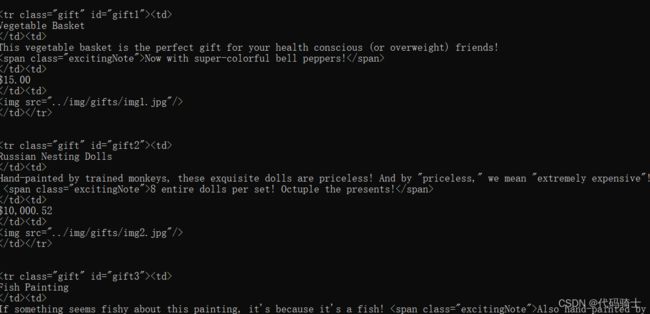
这段代码会打印产品表格里所有行的产品,第一行表格标题除外。为什么标题行被跳过了
呢?对象不能是自己的兄弟标签。任何时候你获取一个标签的兄弟标签,都不会包含这个
标签本身。正如函数名本身揭示的,这个函数只调用后面的兄弟标签。例如,如果我们选
择一组标签中位于中间位置的一个标签,然后调用 next_siblings() 函数,那么就只会返
回在它后面的兄弟标签。因此,选择标题行,然后调用 next_siblings,就可以选择表格
中除了标题行以外的所有行。
使标签具体化:
如果我们选择 bs.table.tr 或直接用 bs.tr 来获取表格中的第一行,上面的代码也可以获得正确的结果。但是,我还是写了一行更长、更完整的代码:
bs.find('table',{'id':'giftList'}).trfrom urllib.request import urlopen from bs4 import BeautifulSoup html=urlopen('http://www.pythonscraping.com/pages/page3.html') bs = BeautifulSoup(html,'html.parser') for sibling in bs.find('table',{'id':'giftList'}).tr: print(sibling)输出结果:
即使页面上只有一个表格(或其他目标标签),只用标签也很容易丢失细节。
另外,页面布局是不断变化的。一个标签这次是在表格中第一行的位置,没准儿哪天就在第二行或第三行了。如果想让你的爬虫更稳定,最好还是让标签的选择更加具体。如果有属性,就利用标签的属性。
和 next_siblings 一样,如果你很容易找到一组兄弟标签中的最后一个标签,那么
previous_siblings 函数也会很有用。
当 然, 还 有 next_sibling 和 previous_sibling 函 数, 它 们 的 作 用 跟 next_siblings 和
previous_siblings 类似,只是它们返回的是单个标签,而不是一组标签。

3. 处理父标签
在抓取网页的时候,查找父标签的需求比查找子标签和兄弟标签要少很多。通常情况
下,如果以抓取网页内容为目的来观察 HTML 页面,我们都是从最上层标签开始的,然
后思考如何定位我们想要的数据块所在的位置。但是,偶尔在特殊情况下你也会用到
BeautifulSoup 的父标签查找函数 parent 和 parents。例如:from urllib.request import urlopen from bs4 import BeautifulSoup html=urlopen('http://www.pythonscraping.com/pages/page3.html') bs = BeautifulSoup(html,'html.parser') print(bs.find('img',{'src':'../img/gifts/img1.jpg'}).parent.previous_sibling.get_text())输出结果:
这段代码会打印 ../img/gifts/img1.jpg 这个图片所对应商品的价格(这个示例中价格是 $15.00)。
这又是怎么实现的呢?
下面是我们正在处理的 HTML 页面的部分结构,其中用数字表示了步骤。


这章内容比较多,分成两部分学习,易于消化吸收。