入口
入口就是线程池执行任务的方法
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) { //入口
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
//请求数量小于最小数量
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//请求数量小于阻塞队列容量
if (isRunning(c) && workQueue.offer(command)) { //入阻塞队列
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
} //请求数量小于最大线程数量
else if (!addWorker(command, false))
reject(command);
}分了好几种情况,按当前并发请求数量的大小来分类:
- 小于最小数量
- 小于阻塞队列容量
- 小于最大数量
小于最小数量的情况
入口
代码位置
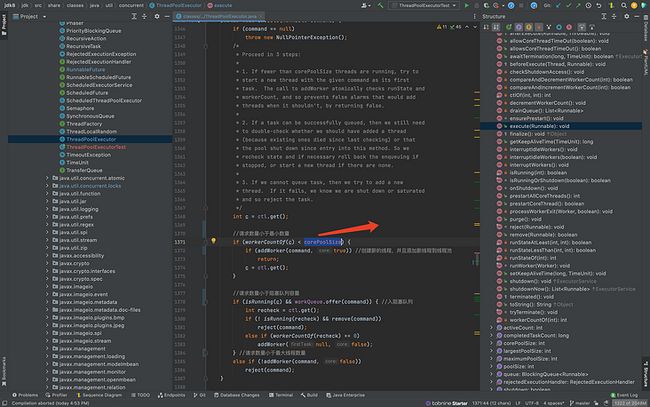
代码说明
//请求数量小于最小数量
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) //创建新的线程,并且添加新线程到线程池
return;
c = ctl.get();
}创建新的线程,并且添加到线程池
核心步骤
- 创建新的线程
- 添加新线程到线程池
- 执行Worker线程
/**
* 创建新的线程,并且添加新线程到线程池
*
* ---
* Checks if a new worker can be added with respect to current
* pool state and the given bound (either core or maximum). If so,
* the worker count is adjusted accordingly, and, if possible, a
* new worker is created and started, running firstTask as its
* first task. This method returns false if the pool is stopped or
* eligible to shut down. It also returns false if the thread
* factory fails to create a thread when asked. If the thread
* creation fails, either due to the thread factory returning
* null, or due to an exception (typically OutOfMemoryError in
* Thread.start()), we roll back cleanly.
*
* @param firstTask the task the new thread should run first (or
* null if none). Workers are created with an initial first task
* (in method execute()) to bypass queuing when there are fewer
* than corePoolSize threads (in which case we always start one),
* or when the queue is full (in which case we must bypass queue).
* Initially idle threads are usually created via
* prestartCoreThread or to replace other dying workers.
*
* @param core if true use corePoolSize as bound, else
* maximumPoolSize. (A boolean indicator is used here rather than a
* value to ensure reads of fresh values after checking other pool
* state).
* @return true if successful
*/
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//创建新的线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//添加新线程到线程池
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//执行Worker线程:注意,这里只是执行Worker线程
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}那业务线程到底在哪里执行?
上面的代码,只是执行了Worker线程,但是并没有执行业务线程。那业务线程,到底在哪里执行呢?
在Worker线程里的run方法里执行。
来看代码,这里是Worker线程的run方法
/** Delegates main run loop to outer runWorker */
public void run() {
//执行业务线程
runWorker(this);
}核心步骤
- 从阻塞队列获取业务线程
- 执行业务线程
/**
* 执行业务线程
*
* ---
* Main worker run loop. Repeatedly gets tasks from queue and
* executes them, while coping with a number of issues:
*
* 1. We may start out with an initial task, in which case we
* don't need to get the first one. Otherwise, as long as pool is
* running, we get tasks from getTask. If it returns null then the
* worker exits due to changed pool state or configuration
* parameters. Other exits result from exception throws in
* external code, in which case completedAbruptly holds, which
* usually leads processWorkerExit to replace this thread.
*
* 2. Before running any task, the lock is acquired to prevent
* other pool interrupts while the task is executing, and then we
* ensure that unless pool is stopping, this thread does not have
* its interrupt set.
*
* 3. Each task run is preceded by a call to beforeExecute, which
* might throw an exception, in which case we cause thread to die
* (breaking loop with completedAbruptly true) without processing
* the task.
*
* 4. Assuming beforeExecute completes normally, we run the task,
* gathering any of its thrown exceptions to send to afterExecute.
* We separately handle RuntimeException, Error (both of which the
* specs guarantee that we trap) and arbitrary Throwables.
* Because we cannot rethrow Throwables within Runnable.run, we
* wrap them within Errors on the way out (to the thread's
* UncaughtExceptionHandler). Any thrown exception also
* conservatively causes thread to die.
*
* 5. After task.run completes, we call afterExecute, which may
* also throw an exception, which will also cause thread to
* die. According to JLS Sec 14.20, this exception is the one that
* will be in effect even if task.run throws.
*
* The net effect of the exception mechanics is that afterExecute
* and the thread's UncaughtExceptionHandler have as accurate
* information as we can provide about any problems encountered by
* user code.
*
* @param w the worker
*/
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//从阻塞队列里获取业务线程:准确的说,这里有2种情况,
//1.Worker线程被创建的时候,会持有业务线程,所以Worker线程第一次被执行的时候,是直接获取自己已经持有的业务线程。执行完成之后,会被置为null,表示已经被处理。
//2.除了这个业务线程,其他业务线程都是从阻塞队列获取。而且是循环获取,说白了,其实就是有一个地方不停的往阻塞队列写数据(业务线程),相当于生产者;然后,Worker线程这里会不停的消费数据,相当于消费者。典型的生产者消费者模式。
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行业务线程
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}从阻塞队列获取业务线程
/**
* 从阻塞队列里获取业务线程
*
* ---
* Performs blocking or timed wait for a task, depending on
* current configuration settings, or returns null if this worker
* must exit because of any of:
* 1. There are more than maximumPoolSize workers (due to
* a call to setMaximumPoolSize).
* 2. The pool is stopped.
* 3. The pool is shutdown and the queue is empty.
* 4. This worker timed out waiting for a task, and timed-out
* workers are subject to termination (that is,
* {@code allowCoreThreadTimeOut || workerCount > corePoolSize})
* both before and after the timed wait, and if the queue is
* non-empty, this worker is not the last thread in the pool.
*
* @return task, or null if the worker must exit, in which case
* workerCount is decremented
*/
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 从阻塞队列里获取业务线程
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}线程池是什么?
上面的步骤有提到添加新线程到线程池,那线程池具体是个什么东西呢?就是个集合(Set)。
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet workers = new HashSet(); //线程池:Worker就相当于是线程池里的线程 总结
- 线程池就是集合
- 集合里的元素就是线程
Worker类实现了Runnable。
阻塞队列的数据,从哪里来?
就是当并发请求数量大于最小数量,但是小于阻塞队列容量的时候,就会把数据(即业务线程)写到阻塞队列。
阻塞队列
阻塞队列长这个样子
/**
* The queue used for holding tasks and handing off to worker
* threads. We do not require that workQueue.poll() returning
* null necessarily means that workQueue.isEmpty(), so rely
* solely on isEmpty to see if the queue is empty (which we must
* do for example when deciding whether to transition from
* SHUTDOWN to TIDYING). This accommodates special-purpose
* queues such as DelayQueues for which poll() is allowed to
* return null even if it may later return non-null when delays
* expire.
*/
private final BlockingQueue workQueue; 其实就是一个阻塞队列数据结构,一般是数组阻塞队列(ArrayBlockingQueue)。
数据元素是业务线程。
核心类-Worker线程
注意,Worker线程也是一个线程,它实现了Runnable接口
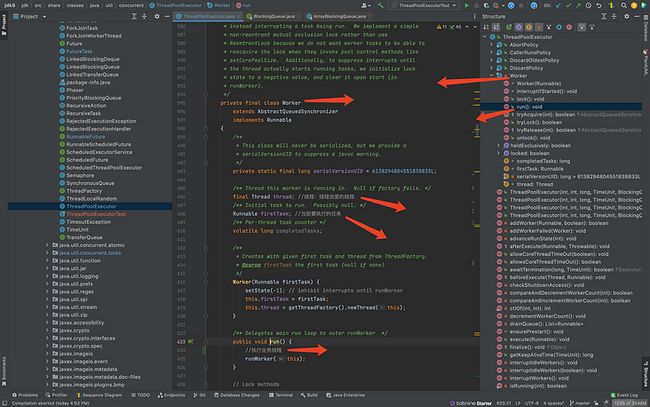
其次,它持有了2个核心对象:
- 业务线程
创建Worker线程的时候,业务线程也会作为构造方法的入参

- 线程池里的线程
新线程是如何创建的?在创建Worker对象的时候,会创建新线程

线程新线程的代码:注意,创建线程构造方法的入参是Worker自己,因为刚才Worker把自己(j即this对象)作为入参。
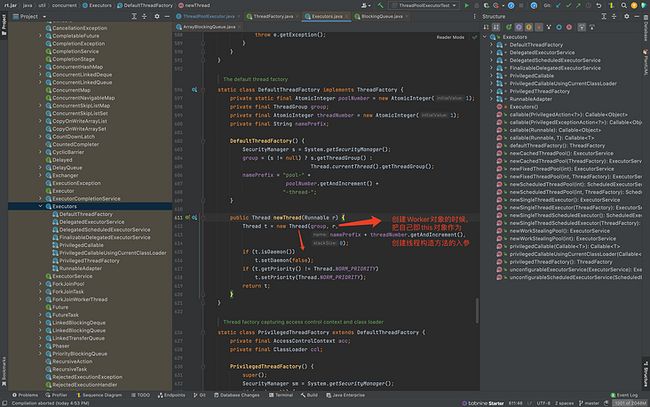
所以,Worker持有的thread就是它自己。所以,下面代码执行thread的时候,就是在执行Worker的run方法。
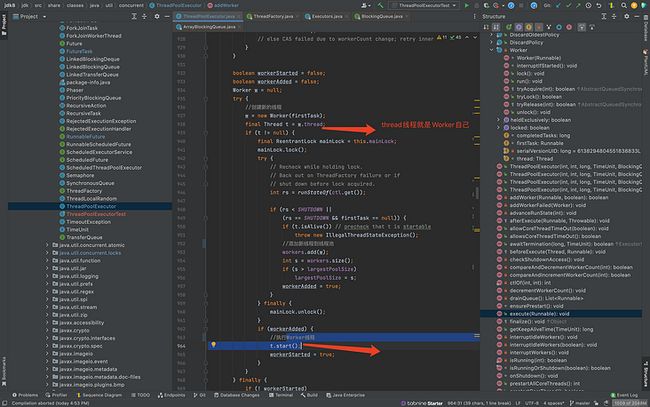
总结
线程和线程池是最重要的数据,流程的核心,就是围绕线程池和线程池里的线程。
注意,线程池里的线程是工作线程,其实本质就是Worker:Worker的作用就是,不断从阻塞队列消费数据。
还有一个线程是业务线程:业务线程的作用就是我们自己的业务逻辑。存储业务线程的地方是阻塞队列。阻塞队列的数据消费之后,数据就没了——大白话就是,业务线程属于临时数据,阻塞队列也是临时存储业务线程。本质是因为业务线程的生命周期很短,就是当前请求结束了,业务线程就会被删除。
而,线程池以及线程池里的工作线程,生命周期则比较久。一个工作线程创建之后,就一直存在,主要作用就是一直不停从阻塞队列消费数据——说白了,其实就是一个工作线程,可以处理多个业务线程。即处理完一个,接着处理下一个。
而且,工作线程并没有归还的操作。什么意思呢?就是工作线程是一个线程,一直在循环处理业务线程,并没有类似数据库连接池的用完归还的操作。因为不需要。
所以,线程池的核心步骤
- 创建工作线程,添加到工作线程线程池
- 执行工作线程,不停的处理业务线程
注意,没有归还工作线程到工作线程线程池的操作。
既然不需要归还,那为什么还要线程池呢?因为需要计算工作线程的数量。
小于阻塞队列容量的情况
入口
//请求数量小于阻塞队列容量
if (isRunning(c) && workQueue.offer(command)) { //入阻塞队列
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);生产者消费者模式
这里是典型的生产者消费者模式,
- 在这里会不断的生产数据
本质就是写数据。即把业务线程写到阻塞队列。
- Worker线程会不断的消费数据
本质是读数据。即从阻塞队列读业务线程。
数据结构
阻塞队列。
小于最大数量的情况
入口
注意,这里的addWorker方法和前面最小数量是同一个方法。唯一的一点点区别是,第二个入参不一样,第二个入参的作用是用来标记是否是最小数量。
//请求数量小于最大线程数量
else if (!addWorker(command, false))
reject(command);核心步骤和最小数量完全一样,都是
- 创建新的线程
- 添加新线程到线程池
- 执行工作线程