论文阅读--异常检测中实时大数据处理的研究挑战
异常检测中实时大数据处理的研究挑战
- 0、引言:
- 1、给出一些与大数据处理挑战相关的现有机器学习算法模型框架:
-
- 1.1、[Zhou、Pan、Wang 和 Vasilakos (2017)](https://www.sciencedirect.com/science/article/abs/pii/S0925231217300577)
- 1.2、[Fernández、Carmona、del Jesus 和 Herrera (2016)](https://www.atlantis-press.com/journals/ijcis/25868762)
- 1.3、[Suthaharan (2014)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0550)
- 2、分析通过机器学习算法进行异常检测的实时大数据处理及其局限性:
-
- 2.1、[McNeil、Shetty、Guntu 和 Barve (2016)](https://www.sciencedirect.com/science/article/pii/S1877050916302873)
- 2.2、[Lobato、Lopez 和 Duarte (2016)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0395)
- 2.3、[Gonçalves、Bota 和 Correia (2015)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0245)
- 2.4、[(Cui & He,2016)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0155)
- 2.5、[Rettig、Khayati、Cudré-Mauroux 和 Piórkowski(2015 年)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0480)
- 2.6、[Liu and Nielsen (2016)](http://refhub.elsevier.com/S0268-4012%2818%2930165-8/sbref0380)
- 2.7、不足:
- 3、异常检测的实时大数据处理技术中最重要的研究挑战:
-
- 3.1 . 冗余
- 3.2 . 计算成本
- 3.3 . 输入数据的性质
- 3.4 . 噪声和缺失值
- 3.5 . 参数选择
- 3.6 . 架构不足
- 3.7 . 数据可视化
- 3.8 . 数据的异质性
- 3.9 . 准确性
- 4、研究方向的建议
- 【参考文献】
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计5278字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿
0、引言:
现有的大多数分析都普遍评估了大数据处理、异常检测或机器学习技术,主要集中在批处理而不是实时加工。相比之下,我们主要关注使用机器学习进行异常检测的实时大数据处理技术。
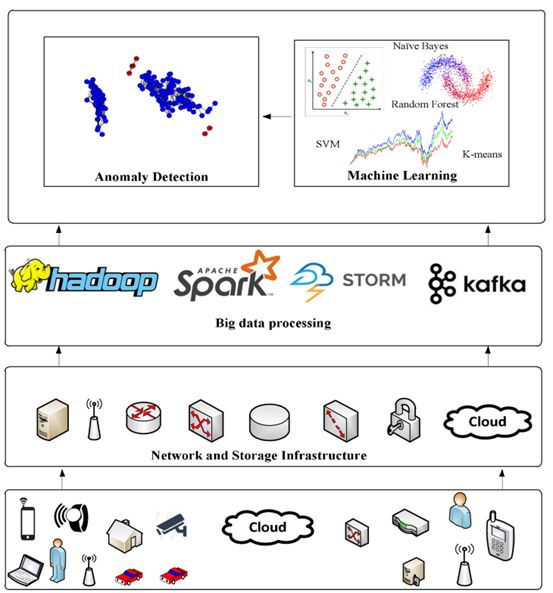
图:实时大数据生成、处理和异常检测的顺序
1、给出一些与大数据处理挑战相关的现有机器学习算法模型框架:
1.1、Zhou、Pan、Wang 和 Vasilakos (2017)
提出了一个大数据机器学习 (MLBiD) 框架,该框架遵循预处理、学习和评估阶段。此外,它还确定了该领域未来几年的各种挑战和机遇。他们还提出了一种具有监督、无监督学习、强化和数据可用性的分类法。此外,他们总结了几个研究问题,包括新的大数据机器学习架构,无缝支持海量异构数据的实时处理。
1.2、Fernández、Carmona、del Jesus 和 Herrera (2016)
解决了与当前算法的数据分布和并行化以及模糊表示相关的各种问题。以及不同的大数据技术挑战,如 Hadoop 生态系统(HDFS、HBASE、YARN、Map Reduce 编程)、Spark 主要概念弹性分布式数据集(RDD)、FlinkML,包括数据预处理、监督学习和推荐系统。
1.3、Suthaharan (2014)
专注于将大数据和机器学习结合起来处理网络入侵流量时的各种问题和挑战。由于网络入侵检测中的时间敏感应用和预测,它需要非常强大的大数据技术来解决最近的问题。以及与大数据相关的一些主要问题,例如网络拓扑、通信和安全性。
2、分析通过机器学习算法进行异常检测的实时大数据处理及其局限性:
在许多其他异常检测模型中,机器学习得到了最广泛的应用,而越来越多的网络流量成为现有系统的限制,因为它需要执行复杂的计算。
2.1、McNeil、Shetty、Guntu 和 Barve (2016)
分析了检测移动设备中恶意软件的可用工具。这些工具未能集成群组用户分析,这有助于对目标恶意软件检测进行自动化的行为驱动动态分析。此外,他们提出了可扩展的实时异常检测和移动设备中目标恶意软件的通知 (SCREDENT) 架构,以实时分类、检测和预测目标恶意软件。即便如此,对所提议架构的评估未能给出有希望的结果。
2.2、Lobato、Lopez 和 Duarte (2016)
审查了现有的安全方法,例如安全信息和事件管理 (SIEM) 构建,以单点处理数据收集和处理。除此之外,它还会产生大量的误报。此外,他们还提出了一种使用蒸汽处理和机器学习实时检测威胁的架构。这种架构结合了通过批处理对过去可用的数据集进行实时流式传输的好处,并减少了人对系统的参与。所提出的系统还有助于检测已知和零日攻击,以进行攻击分类和异常。然而,尽管有公开可用的数据集(例如 KDD 数据集),但已发现所提出的系统在用于实验的数据集的准确性上较弱。
2.3、Gonçalves、Bota 和 Correia (2015)
在复杂的网络基础设施中提出了挑战,其中包含存储在大量日志文件中的大量设备信息。因此,从该日志中提取有意义的信息是一项艰巨的任务。使用机器学习和数据挖掘技术评估各种基础设施设备的安全日志以发现行为不端的主机的新方法。建议的方法有两个阶段。首先执行一组定义和配置检测机制的步骤,其次在运行时执行检测机制。然而,实验设置是通过批处理进行的,输出效率不够准确,还需要高度的人工干预来自动化一些过程。
2.4、(Cui & He,2016)
提出了模型来处理使用 Hadoop、HDFS、Mapreduce、云和机器学习算法检测异常的更好性能。此外,weka 接口用于模型中,通过朴素贝叶斯、决策树和支持向量机算法评估准确性和效率。事实上,云基础设施和实时输入数据流的实施并没有得到很好的解决。
2.5、Rettig、Khayati、Cudré-Mauroux 和 Piórkowski(2015 年)
解决了检测流数据异常的挑战,主要关注通用性和可扩展性。他们提出了使用熵和皮尔逊相关性来评估具有两个指标的在线异常检测的新方法。此外,大数据流组件,如 Kafka 队列和Spark Stream,用于确保通用性和可扩展性问题。尽管如此,复杂的过程仅限于由数据处理,并且周期性批处理的持续时间也很长。
2.6、Liu and Nielsen (2016)
提出了一种使用内存分布式框架来检测异常的方法。该框架包含Spark Stream和 lambda 系统。它的主要优点是支持可扩展的实时流式传输以进行实时检测。但是,该框架需要更长的时间来训练模型。因此,实时任务的调度是未知的。
2.7、不足:
上述所有讨论的方法及其局限性都需要重新评估框架设计以支持异常检测。特别是,使用机器学习进行异常检测的高级实时大数据分析将为异常检测带来有希望且更好的性能和准确性。
3、异常检测的实时大数据处理技术中最重要的研究挑战:
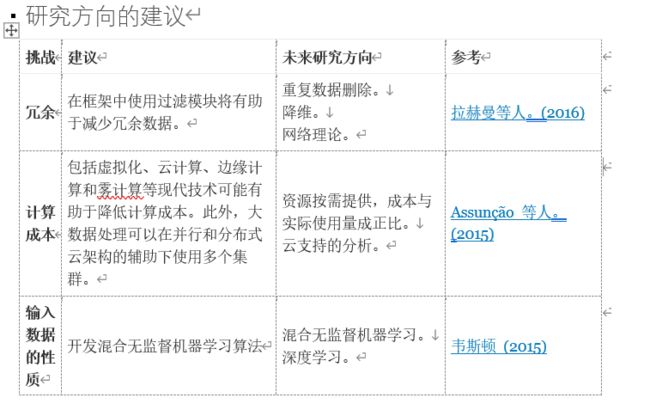
3.1 . 冗余
实时处理从各种网络传感器生成的大量数据是大数据管理中的一个关键因素,尤其是由于先前生成的数据不断重复。
尽管现有的大数据处理技术,如 Hadoop 和 Spark 框架已经被开发用于处理跨多个集群的数据复制,但这些技术仍然不足以解决与数据冗余、数据质量、不一致和维护存储成本相关的挑战(Bhadani 和 Jothimani,2016 年)。此外,这些技术缺乏模式来最大限度地减少冗余,并且不足以存储大量数据(Hashem 等人,2015 年)。因此,设计一个能够解决和最小化旨在满足当前和未来需求的冗余问题的框架变得至关重要。
3.2 . 计算成本
许多研究都集中在合并或合并几种技术以提高异常检测的性能,这导致计算成本增加(Lin et al., 2015)。此外,高维度与大样本量相结合会产生计算成本高和算法不稳定性等问题(Fan, Han, & Liu, 2014)。因此,将大数据技术与云一起使用将通过结合并行和分布式处理来解决计算成本问题,这有助于构建多个集群,从而最大限度地降低计算成本。高芯片和处理器的大规模生产降低了它们的成本,因此这些硬件的使用将增加系统的能力,有助于实时处理大量数据,从而降低计算成本。
3.3 . 输入数据的性质
在构建的任何模型的一个方面,首先要研究的是输入数据的性质。输入数据是数据实例的集合,如对象、记录、点、向量、模式、事件、案例、样本、观察、实体。它们是每个数据实例的各种属性集,例如变量、特征、特征、字段和维度。它有两种不同类型的属性,例如二元、分类或连续。每个数据实例大多属于单变量或多变量类别。输入数据的多样性使得异常检测技术难以选择适当的算法来处理该特定数据。基本上,异常检测技术将根据该应用程序中属性的性质而有所不同(Chandola et al., 2009)。这个问题将通过开发混合无监督机器学习算法来解决。
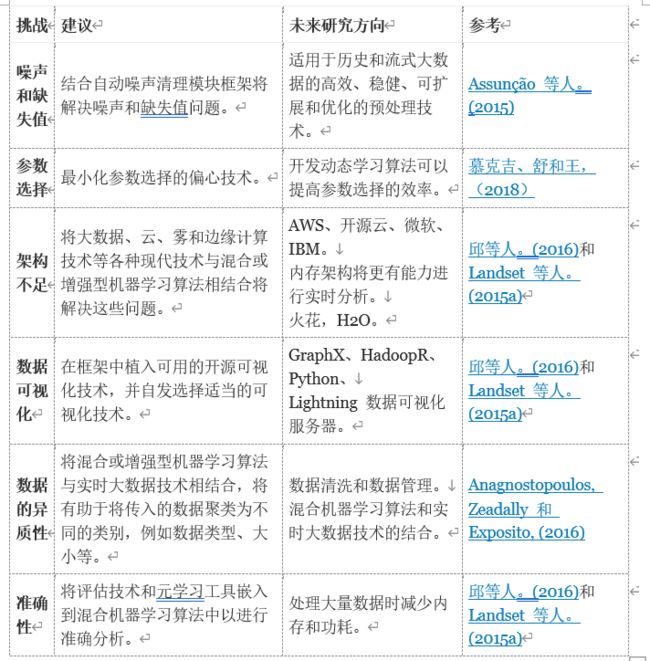
3.4 . 噪声和缺失值
网络传感器中的流数据由不同类型的数据组成,例如二进制、离散、连续、音频、视频和图像。由于数据的传入速度,通过通信通道从各种部署的传感器收集的这些数据包括噪声和缺失值(Chandola 等人,2009 年)。噪声和缺失值可能会在异常检测中产生较高的误报率。大量不相关的特征会在输入数据中产生噪声,从而绕过真正的异常 ( Erfani et al., 2016 )。这些问题将通过在检测框架中加入自动噪声清理模块来解决。自动清理模块还将通过向数据集添加 NA 来解决缺失值问题。
3.5 . 参数选择
找到任何机器学习算法的参数都可能具有挑战性(Mirsky 等人,2017 年)。特别是在处理实时异常检测时,在选择它们之前必须考虑单参数、多参数和超参数。此外,在演化过程的早期阶段运行良好的一组参数可能在后期阶段表现不佳,反之亦然(Sarker, Elsayed, & Ray, 2014)。参数是决定算法性能的主要因素之一。此外,它会对模型的训练产生巨大的影响或延迟。或者,我们可以使用无参数算法来识别流、有向、二分图中的节点分区,并监控它们随时间的演变以检测事件(Akoglu、Tong 和 Koutra,2015 年)。采用偏心技术之类的技术将解决这一挑战,因为它将最大限度地减少参数选择。
3.6 . 架构不足
现有架构能够处理批处理中的异常检测,并且数据量较小,但是它们无法实时处理大数据。组织正在努力构建大数据架构以更好地执行,但是当涉及到实时数据时,它与大数据根本上是不同的架构。实时架构的组件必须合并应用程序和分析,以提出新的工作环境方式,同时满足动态数据(快速)和静态数据(大)的需求。不与现有企业数据集成时,大数据架构效率低下;就像在大数据关联分析之前无法完成分析一样(Katal、Wazid 和 Goudar,2013)。将各种大数据技术与混合机器学习算法相结合将解决架构问题。
3.7 . 数据可视化
处理和分析的数据或报告需要由用户可视化,并且必须从报告中提供洞察力。然而,挑战在于选择适当的可视化技术,以便从各种连接设备进行异常检测。多种可视化技术用于异常检测可视化的设计,从简单图形到 2D 和 3D 视图。当涉及到 2D 和 3D 时,热图、散点图、平行坐标和节点链接图很容易展示输出。3D 交互需要用户完全理解数据才能旋转缩放显示(Shiravi, Shiravi, & Ghorbani, 2012)。在框架中嵌入可用的开源可视化技术可以解决这个问题,此外,该框架使系统能够自动选择合适的可视化技术。
3.8 . 数据的异质性
非结构化数据代表了几乎所有正在生成的数据,例如社交媒体交互、录制的会议、PDF 文档的处理、传真传输、电子邮件等等。结构化数据总是以高度机械化和可管理的方式组织起来。它显示了与数据库的良好集成,但非结构化数据完全是原始的和无组织的。使用非结构化数据很麻烦,当然也很昂贵。将所有这些非结构化数据转换为结构化数据也是不可行的。无监督混合机器学习算法的使用将解决异构数据问题。混合机器学习算法和实时大数据技术的结合将有助于将传入的数据聚类到不同的类别,最终有助于轻松识别数据类型,
3.9 . 准确性
尽管现有技术能够检测异常,但由于准确性问题,结果的依赖性仍然不可靠。在某些情况下,以高计算处理和时间为代价产生更好的准确性。这个问题将通过将实时大数据技术与混合机器学习算法相结合来解决,混合机器学习算法作为一种替代强大的元学习工具出现,可以准确分析现代应用程序生成的大量数据,并且内存和功耗更少。
4、研究方向的建议
【参考文献】
[1] Habeeb R A A, Nasaruddin F, Gani A, et al. Real-time big data processing for anomaly detection: A survey[J]. International Journal of Information Management, 2019, 45: 289-307.
[2] Thudumu S, Branch P, Jin J, et al. A comprehensive survey of anomaly detection techniques for high dimensional big data[J]. Journal of Big Data, 2020, 7(1): 1-30.
[3] 张浩. 一种新型分类算法及其在网络入侵检测中的应用研究[D].北京邮电大学,2018.
[4] 何经纬,刘黎志,彭贝,付星堡.基于Spark并行SVM参数寻优算法的研究[J].武汉工程大学学报,2019,41(03):283-289.
[5] 吴思远. 基于支持向量机的网络流量分类技术研究[D].南京邮电大学,2019.DOI:10.27251/d.cnki.gnjdc.2019.000104.
[6] 刘建兰,覃仁超,何梦乙,熊健.基于大数据技术的网络异常行为检测模型[J].计算机测量与控制,2020,28(03):62-66+71.DOI:10.16526/j.cnki.11-4762/tp.2020.03.014.
[7] 邵金鑫,行艳妮,南方哲,赵鑫,马廷淮,钱育蓉.改进CK-means+算法及并行实现[J].计算机工程与设计,2022,43(05):1240-1248.DOI:10.16208/j.issn1000-7024.2022.05.006.
[8] Othman S M, Ba-Alwi F M, Alsohybe N T, et al. Intrusion detection model using machine learning algorithm on Big Data environment[J]. Journal of big data, 2018, 5(1): 1-12.
[9] Zhang H, Dai S, Li Y, et al. Real-time distributed-random-forest-based network intrusion detection system using Apache spark[C]//2018 IEEE 37th international performance computing and communications conference (IPCCC). IEEE, 2018: 1-7.
[10] Awan M J, Farooq U, Babar H M A, et al. Real-time DDoS attack detection system using big data approach[J]. Sustainability, 2021, 13(19): 10743.
[11] Kulariya M, Saraf P, Ranjan R, et al. Performance analysis of network intrusion detection schemes using Apache Spark[C]//2016 International Conference on Communication and Signal Processing (ICCSP). IEEE, 2016: 1973-1977.