【对象检测】- 2 - 两阶段对象检测算法发展史
本文为Wilson Ho的讲解影片(圖解兩階段物件偵測算法)笔记
文章目录
-
- 原始对象检测算法
- Overfeat
- R-CNN
- SPP-Net
- Fast R-CNN
- MultiBox
- Faster R-CNN
- FCN 和 U-Net
- Mask R-CNN
- MaskX R-CNN
- Segmentation Is All You Need
- 参考
历年图像识别算法(2014至2019)

原始对象检测算法
对象检测的任务有两个:识别出对象是啥,对象在哪里。
最原始的算法为了实现这两个算法,往往会用滑动窗把一个图片分成在不同位置的很多张小图片,然后挨个识别,选可能性最大的确定真正的对象位置(即穷举法)。这样做效率很低,一方面分成不同位置的小图片需要很大的算力和内存,另一方面滑动窗的长宽是固定的,虽然把图片转为不同长宽比例可以在一定程度上解决这个问题,但转化过程需要很大的算力,所以会进一步降低效率。
一种相对高效的解决方案是把位置检测和对象识别分开,即两阶段对象检测。比如可以先识别分类,再用回归算法求对象的位置和宽高。
对象检测和「对象定位+识别分类」的区别在于:对象检测能识别单个图片中的多种对象,并能识别出没有对象的情况。
Overfeat
Overfeat的前五层在识别任务和定位任务里都会用到,模型的前五层在训练后能同时保留位置信息和类别信息,团队先用分类任务训练后,冻结前五层,然后用回归模型替代后几层,用来训练定位边界框(由左上角和右下角坐标组成)。创新之处:
- 用同一个模型实现了识别分类与对象定位,前五层特征被充分利用
- 在分类部分用全CNN分类算法替代CNN展开分类算法
在传统的CNN展开分类算法里,由于预测输出必须展开成大小为「1个像素x很多层」的结构,在模型结构确定的情况下,图像输入尺寸是确定的,要么把图像转为这个尺寸进行输入(可能会损失一部分图像特征),要么把从过大的图片中剪裁出不同的较小的图片进行输入(即滑动窗),然后求预测结果的平均值。如果把图片剪裁后进行计算,由于这个滑动窗每动一次(每产生一个新的小图片)就得走一遍整个CNN计算流程,所以需要消耗巨量计算资源。你会发现,这些滑动窗的重叠部分被重复进行了CNN运算。Overfeat的全CNN分类算法提高了这个效率,它把滑动窗的过程“整合”进了CNN里,算法输出的是「(nxn)个像素x很多层」。(nxn)的每个像素都对应了一个“滑窗”,而每一层仍然对应一个分类的预测结果,只要把每层的nxn求平均值就可以得到最终预测结果。算完后你会发现CNN只走了一遍就算出了所有“滑动窗”的预测结果。 - 用offset max-pooling实现了密集的滑动
论文里说的total subsampling ratio是啥意思我暂时没搞懂,后面又说沿着每个轴每36个像素才对应一个分类向量,跟10-view scheme比太粗糙了会降低性能。说实话我不确定这部分我是不是理解对了……我的理解是:在第五层后隔着offset进行的max-pooling是为了平衡位置和类别的识别。如果max-pooling面积太大,类别识别会变难,因为特征提取跟对象不匹配,如果max-pooling面积过小,位置识别会变难,因为找不到框在哪里。用offset max-pooling既能把所谓的total subsampling ratio减小到12,又因为隔着offset取样,没降低覆盖面积,所以可以解决这个矛盾。
有关 offset max-pooling 介绍的论文原文:However, the total subsampling ratio in the network described above is 2x3x2x3, or 36. Hence when applied densely, this architecture can only produce a classification vector every 36 pixels in the input dimension along each axis. This coarse distribution of outputs decreases performance compared to the 10-view scheme because the network windows are not well aligned with the objects in the images. The better aligned the network window and the object, the strongest the confidence of the network response. To circumvent this problem, we take an approach similar to that introduced by Giusti et al. [9], and apply the last subsampling operation at every offset. This removes the loss of resolution from this layer, yielding a total subsampling ratio of x12 instead of x36.
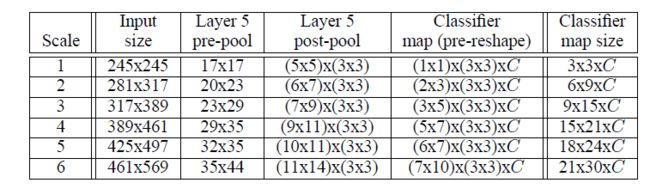
论文里说的 total subsampling ratio 应该出自下图标出来的 Conv. stride 和 Pooling stride (2 x 3 x 2 x 3 = 36)。至于为什么这样会跟图像里的对象不匹配,我不懂,跪求解答。
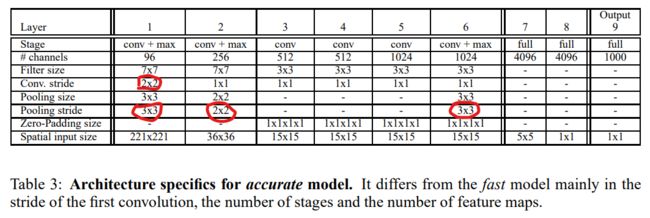
R-CNN
Overfeat 算法在求对象定位的时候还是需要很多滑动框,需要耗费巨量的计算资源。为了节约求定位框的计算资源,我们可以用算法先找出所有可能是对象的东西,再从这些可能的定位框里找出真正的对象定位框。具体实现过程如下:
- 先把图片用Graph-Based Segmentation切成很多小区块,每个小区块对应一个小定位框
- 把所有小定位框转成统一大小,输入ConvNet以提取特征,然后将ConvNet输出的特征输入到SVM来分类,并用ConvNet输出的特征用回归层算定位。
- 回归层得到的定位框用Non-Max Suppression做淘汰,留下的就是最终结果
R-CNN的训练也是分阶段的:
- 还是先把训练集图片用Graph-Based Segmentation切成很多小区块,每个小区块对应一个小定位框
- 拿训练集的Ground truth跟上一步分出来的小定位框做对比,超过IoU阈值的当作正例,其他的为反例,训练完整的分类CNN
- 用Groundtruth作为正例,用IoU小于0.3的小定位框作为反例,用上一步训练的CNN中的ConvNet层提取正例和反例的特征,并保存这些特征到硬盘。(类似迁移学习里冻结参数)
- 给每个分类(包括背景类)做支持向量机(SVM),用上一步提取并保存的正例、反例特征作为输入,用Ground truth里的对应类图片做正例,其他做反例,训练这些SVM。这样分类器就做完了。
- 然后训练定位回归层以调整Graph-Based Segmentation得到的定位框:用Ground truth的定位框做线性回归,是专为定位回归设计的一种线性回归,不详细记了。
SPP-Net
R-CNN的问题: 一方面R-CNN在训练过程中需要很多专用的算法,比较麻烦。另一方面R-CNN的训练非常非常慢,尽管mAP较高,训练时间却是Overfeat的9倍左右。那么R-CNN具体慢在哪呢?主要是一开始从图片中提取的子图片子图片转成统一大小后,每一张都要过一遍CNN,很低效。后来的SPP-Net主要在针对这一部分做优化。
如果像Overfeat那样用ConvNet直接提取特征的话(注意第一代R-CNN是在Overfeat之前出世),CNN输入是统一大小的,而我们想识别的子图片(从图片中提取的定位框)有各种各样的大小(像素长宽),大小不一就很难用同一个ConvNet提取特征。下图展示的是第一代R-CNN和用了SPP-Net的R-CNN的区别。

SPP-Net提出了一种"空间金字塔池化(spatial pyramid pooling)",一开始还是先用Graph-Based Segmentation找出可能的子图片,但是直接用ConvNet对整张图片提取特征(之前是对每个子图片分别提取特征),对特征中对应子图片位置的相对位置用不同大小的Pooling做处理,然后把处理结果并排输出到后面的全连接层。它的优雅之处在于:既能灵活地对不同“子图片”做识别分类,又不用每张子图片都过一遍CNN。
对我个人而言,从整张图片的特征中找相对位置做Pooling比较难消化……我是类比YOLO里grid cell来理解的:对整张图提取的特征里每个像素的相对位置对应着原图像中的相对位置,用这种对应关系就可以推算出子图片在原图片中的定位框。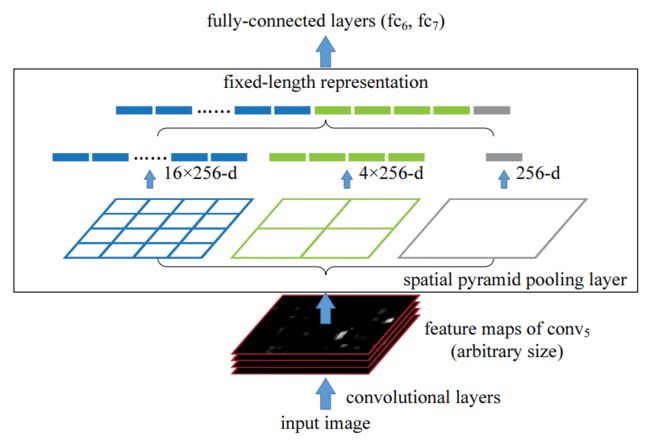
Fast R-CNN
Fast R-CNN创新点:
-
用了一个类似于SPP的“Rol Pooling”
-
训练不再分阶段,所以也用不着中途把特征存到硬盘,对象的分类和定位一起训练
-
分类不再使用SVM,而是用softmax

-
在训练中,把定位和分类的损失值作为损失值
-
计算定位的损失值用了smooth L1:smooth L1集合了L1和L2的优点,既能在接近零时减少坡度,也能防治在不接近零时坡度过大
MultiBox
Fast R-CNN训练和推理比SPP-Net和R-CNN都要快,它的推理时间主要浪费在region proposal上(即Graph-Based Segmentation)。为了加快速度,我们希望region proposal能用类神经网络(DNN)实现,MultiBox就是高效地实现了这一步,它会从图片中识别出跟类别无关的很多边界框。
MultiBox像是个极度阉割版的YOLO:首先这个YOLO不分grid cell,输入特征只有一个像素,这个像素就是输入的全连接层。在这个全连接层里有一个包含了k个“bbox”的anchor box,而且这些“bbox”只有可能性和坐标、长宽,没有one-hot分类。
训练时,先把所有Groundtruth的bbox放在一起,用聚类算法(比如k-mean)算出最可能出现的“bbox"。训练模型,使模型预测结果向“最可能bbox”对齐。靠近的过程类似于R-CNN里的bbox回归层的训练方法。
MultiBox没有像Overfeat、SPP-Net 和 Fast R-CNN 做特征共享(MultiBox),所以还是比较低效。
Faster R-CNN
Faster R-CNN在region proposal部分使用类似于MultiBox的方式,并融合进了Fast R-CNN的框架,做到了特征共享。
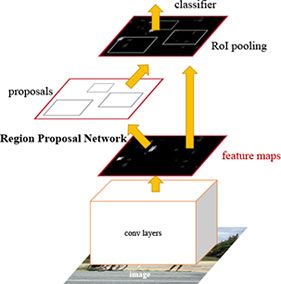
比较不一样的地方在于:Faster R-CNN的Anchor box预设了一些位置固定,尺寸和缩放比例也固定的bbox,根据作者的实验,在固定位置的情况下,三种缩放和三种尺寸比例可以提高定位性能。
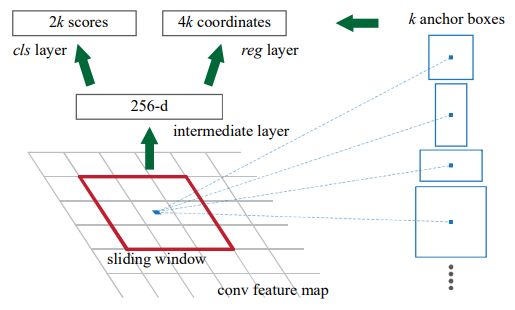
我对classification layer为啥是2倍的k不太懂,知乎上有解释说“每个anhcor要分positive和negative”,但是如果只是要分有没有东西,一个数就够了吧?希望各位老师不吝赐教。
论文原文:The cls layer outputs 2k scores that estimate probability of object / not-object for each proposal.
训练部分讲究相当多,今天耐心用光了,等用到再详细研究吧……
FCN 和 U-Net
在两阶段对象检测算法里用Non-max Suppression有个缺点:如果侦测到同一物件的两个bbox之间的IoU比较大(最常见的情况是一个大的套一个小的),那么算法就不会只留一个bbox。减小IoU阈值能一定程度避免,但不能完全避免这种情况(比如两个框完全不重合的情况,一个框住头,一个框住尾)。语义分割(Semantic Segmentation)技术能解决这个问题。
FCN这个缩写极具误导性,论文全称Fully Convolutional Networks for Semantic Segmentation,所以重点其实是实现语义分割。语义分析用神经网络实现有个致命的缺点:标签是像素级的。

实在想象不到,这么大的工作量用在什么任务的分类上才值呢?
Downsampling 和 Upsampling:图像在Fully CNN处理的过程中,为了提取特征,必须进行降采样(Downsampling)的操作,又因为输出的尺寸必须跟输入图像尺寸相同,在降采样后必须再升采样(Upsampling),升采样本质上是一个插值的过程。如果直接先将后升,用后段的特征插值实现升采样,那么出来的图像就相当于把降采样后段的输出直接“放大”,由于降采样后段的输出相当抽象,“放大”后的效果一般会比较差。
于是FCN语义分割在升采样(插值)过程中加入了降采样前段的特征,使得前段较具象的特征和后段较抽象的特征都会影响到插值结果。
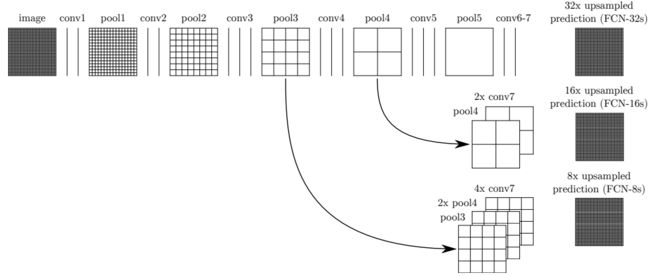
U-Net也是在升采样(插值)过程中加入了降采样前段的特征,只不过FCN升采样时用的是Transpose Convolution

而U-Net在升采样时让特征与降采样过程中得到的的同尺寸的特征堆叠,使得前段较具象的特征和后段较抽象的特征都会影响到插值结果

Mask R-CNN
无论是FCN还是U-Net,语义分割不能避免的一个问题是两个挨着的同类对象被划分为同一对象。Mask R-CNN将语义分割与对象检测结合在一起,实现了实例分割。
读完「stone - 令人拍案称奇的Mask RCNN」后我发现Mask R-CNN跟Faster R-CNN之间跨度还是挺大的……
MaskX R-CNN
Segmentation Is All You Need
参考
- Wilson Ho - 圖解兩階段物件偵測算法
- Overfeat 论文:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun - Overfeat: Integrated recognition, localization and detection using convolutional networks
- 水在瓶 - 解读OverFeat
- 知乎 - overfeat中,offset+pool操作有何意义?
- 小毛激励我好好学习 - OverFeat论文解析
- hjimce - 深度学习(二十)基于Overfeat的图片分类、定位、检测
- Vincent Ho - 【论文阅读】—— OverFeat, Integrated Recognition, Localization and Detection using Convolutional Networks
- MatLab - Specify Layers of Convolutional Neural Network
- Quora - What is meant by a subsampling ratio in a convolutional network?
- R-CNN 论文:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik - Rich feature hierarchies for accurate object detection and semantic segmentation
- v1_vivian - R-CNN论文详解(论文翻译)
- Dean0Winchester - 图像处理—基于图的图像分割(Graph-Based Image Segmentation)
- 白徐行 -【论文笔记】Efficient Graph-Based Image Segmentation
- SPP-Net 论文:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 梦里寻梦 - (三十一)通俗易懂理解——SPP-net
- 大雄的机器梦 - SPPNet-引入空间金字塔池化改进RCNN
- Fast R-CNN论文:Ross Girshick - Fast R-CNN
- 大雄的机器梦 - Fast R-CNN
- MultiBox论文:Dumitru Erhan, Christian Szegedy, Alexander Toshev, Dragomir Anguelov - Scalable Object Detection using Deep Neural Networks
- Faster R-CNN论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 白裳 - 一文读懂Faster RCNN
- FCN论文:Jonathan Long, Evan Shelhamer, Trevor Darrell - Fully Convolutional Networks for Semantic Segmentation
- U-Net论文:Olaf Ronneberger, Philipp Fischer, Thomas Brox - U-Net: Convolutional Networks for Biomedical Image Segmentation (p259)
- stone - 令人拍案称奇的Mask RCNN