【Linux】详解自主实现HTTP服务器
文章目录
- 项目介绍
- 套接字编写
- HttpSever.hpp
- 线程池
- Task任务
- 工具类
-
- ReadLine
- CutString
- CallBack模块
- 前提知识
-
- RecvHttpRequest
- RecvHttpRequestHeader
- ParseHttpRequestLine
- ParseHttpRequestHeader
- RecvHttpRequestBody
- BulidHttpResponse
- CGI
- ProcessNonCgi
- ProcessCgi
- HandlerRequest
- 构建日志
- 编写Makefile
-
- 测试错误请求
- 错误码
- 总结
项目介绍
项目名称: 自主HTTP服务器
功能描述: 采用B/S模型,基于短链接方式的HTTP服务器,目前支持GET,POST方法。
引入CGI模式,可以通过表单上传数据经由服务器创建子进程处理发送回父进程,由父进程构建响应发送给客户端。
引入了日志,将服务器启动的信息按照固定格式输出在标准输出当中。
涉及知识: 网络编程(套接字编写),多线程技术,CGI技术,shell脚本,线程池,进程间通信(管道),哈希表,向量等STL容器。
实现环境: centos 7.6 + vim/gcc/gdb + C/C++
第一步来咯~
套接字编写
编写套接字的工作比较简单,在这里值得一提的是用了setsockopt当中的SO_REUSEADDR,让服务器即使宕机了也能立马绑定端口号。
setsockopt:
第一个参数表示监听套接字,第二个参数位层级,第三个参数为功能,第四和第五即传入一个为真的布尔值或者整型值。

第一步骤:创建一个TcpSever的单例对象。
先前博客有介绍,这里不细说,点击链接跳转码云~
TcpServer.hpp
HttpSever.hpp
HttpServer只调用先前单例对象TcpServer,让TcpServer将服务器起来,然后HttpServer实际上只负责将链接获取上来,然后制造一个任务,将任务放入线程池,让线程池在合适的时候进行处理。
先前博客有介绍,这里不细说,点击链接跳转码云~
HttpSever.hpp
线程池
ThreadPool.hpp
线程池实际上在之前的博客当中有详细讲解,这里唯一值得一题的就是巧妙地编写了Task的回调,这让线程池拿到任务并且处理的逻辑就不用挤在一起了。
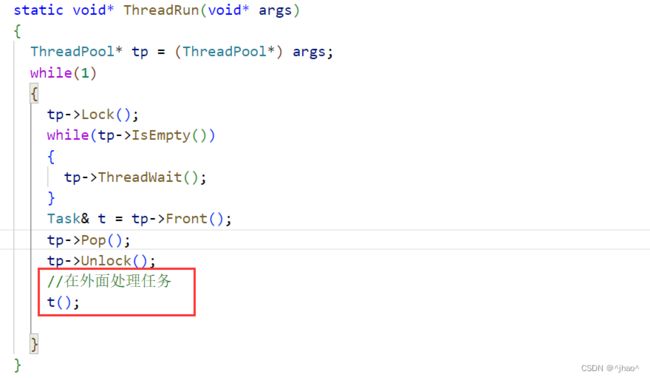
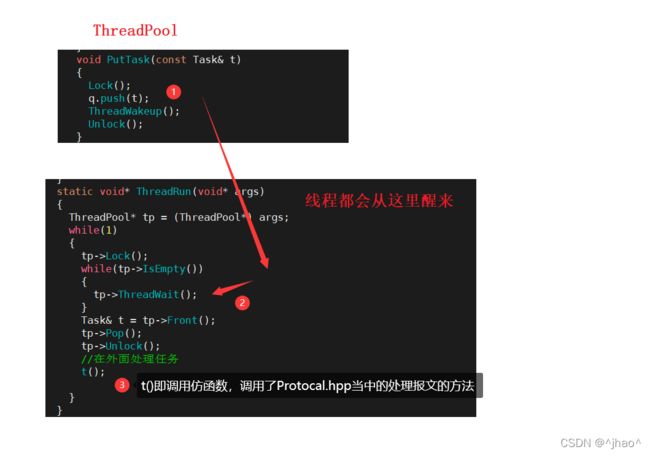
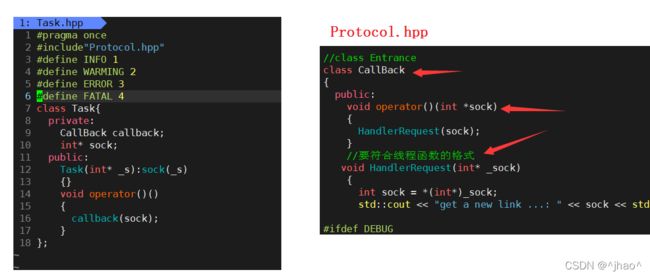
Task任务
每一个任务封装了一个CallBack 对象,调用的时候只需要传入套接字给对象,就可以实现功能。
#pragma once
#include"Protocol.hpp"
#define INFO 1
#define WARMING 2
#define ERROR 3
#define FATAL 4
class Task{
private:
CallBack callback;
int* sock;
public:
Task(int* _s):sock(_s)
{}
void operator()()
{
callback(sock);
}
};
工具类
ReadLine
ReadLine的具体功能是用来读取一行数据,并将末尾置成\n结尾。
static int ReadLine(int sock,std::string& str)
{
//从sock当中读取若干信息,并对换行分隔符做处理
char ch = 'X';
while(ch != '\n')
{
//往ch放入1个字节数据
ssize_t s = recv(sock,&ch,1,0);
if(s > 0)
{
if(ch == '\r'){
//此时需要窥探下一个字符是否为'\n'
recv(sock,&ch,1,MSG_PEEK);
if(ch == '\n')
{
//若时\n,则覆盖式将ch填入\n
recv(sock,&ch,1,0);
}
else
{
//说明是下一行信息,则将ch变为\n即可
ch = '\n';
}
}
// 普通字符
str += ch;
}
else if(s == 0){
//链接关闭了
return 0;
}
else{
//读取出错
perror("recv");
exit(5);
return -1;
}
}
return str.size();
}
CutString
CutString是将target字符串按照sep分成key_out和value_out两部分。
static bool CutString(const std::string &target, std::string &key_out, std::string &value_out, std::string sep)
{
size_t pos = target.find(sep);
if (pos != std::string::npos)
{
key_out = target.substr(0, pos);
value_out = target.substr(pos + sep.size(), std::string::npos);
return true;
}
return false;
}
CallBack模块
试问浏览器发送报文到我们的服务器,我们的服务器处理任务分成几步骤
- 读取报文
- 解析报文
- 封装回应报文
- 发送数据返回浏览器
CallBack模块运用了EndPoint当中的HttpRequest,封装了以下字段。
读取和解析部分实际上就是填写EndPoint类对象的具体字段。
封装回应报文,发送数据实际上就是填写HttpResponse当中字段,然后区分是CGI模式,若不是,发送对应请求路径的页面即可,若是CGI,则发送response_body回去。
class HttpRequest
{
public:
std::string request_line; //请求行
std::vector<string> request_header; //请求报头,kv模式
std::string blank; //空行
std::string request_body; //请求正文
std::string method; // 请求方法
std::string uri; //请求uri
std::string version; //请求的版本,长短链接
std::unordered_map<std::string, std::string> header_kv; //请求头部的key映射value,方便类似Content-Length的查找
int content_length;
std::string path; //访问的路径
std::string query_string; //请求的参数
bool cgi;
public:
HttpRequest() : content_length(0), cgi(false) {}
~HttpRequest() {}
};
class HttpResponse
{
public:
std::string status_line; //状态行
std::vector<std::string> response_header;//响应头部
std::string blank;//空行
std::string response_body;//相应正文
int code; //状态码
int fd; //发送数据的文件描述符的地点
int size; //浏览器定位的路径文件的大小
int content_length;//CGI过后真正要发送的内容
std::string suffix;//后缀
HttpResponse() : code(404), fd(-1), size(0), content_length(0), blank(LINE_END)
{}
~HttpResponse()
{}
};
前提知识

http请求分为请求行,请求报头,空行和请求正文的,要保证读上来的是一个完整的http请求,读到空行就是读完了请求行和请求报头,请求报头的Content-Legth标识了请求正文的长度,而请求正文的长度不一定是按照行来成列的,通常大部分公司会把这部分的空行取消,让数据包比较小。而空行之前都是按分割符成列的。
每个步骤剖析
RecvHttpRequest
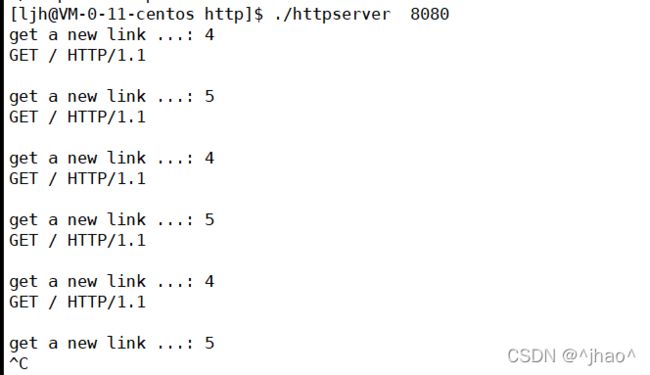
以下实验是谷歌浏览器
该函数只读取第一行,也就是请求行,我们注意不同浏览器发送的请求可能换行不同,如\r\n,\n,我们这里要进行处理,方便适配更多浏览器。
一开始只读取请求行,可以看到请求行的method是大写的,访问的路径是/,即根目录,版本是HTTP/1.1
特殊情况:当读到\r的时候,需要读一个字符判断是否是\n,若不是,则不能将它从缓冲区拿走,若贸然拿走,则下图就会读到请求头部的数据,导致读取报头出错!!!
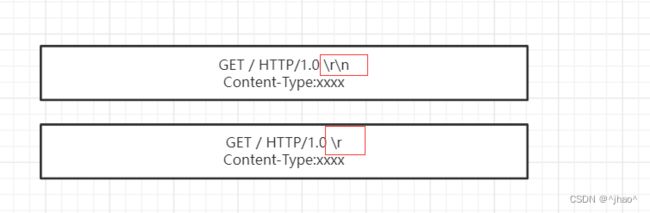
解决方案:
此时需要用到recv的一个flags字段,它能从底层的缓冲区获取并且不移除该数据。MSG_PEEK
MSG_PEEK(man手册)
This flag causes the receive operation to return data from the beginning of the receive queue without removing
that data from the queue. Thus, a subsequent receive call will return the same data.
// 1.接受请求行,只读取一行
bool RecvHttpRequestLine()
{
std::string &line = http_request.request_line;
//读取浏览器发送的请求行数据,填入结构体字段
if (Util::ReadLine(sock, line) > 0)
{
//由于Util::ReadLine方法会将\n也一同放入line,所以这里我们需要手动删除
line.resize(line.size() - 1);
LOG(INFO, line);
}
else
{
stop = true;
}
return stop;
}
RecvHttpRequestHeader
读完了请求行,接下来读请求头部,请求头部的格式Content-Length: 126,注意其中的分隔符是冒号+空格,这个很重要。我们读取的时候先使用vector这个容器来接受,方便接受。
该函数可以读完请求头部和空行。
// 2.读取请求头部,也会同时填充空行字段,有若干行,以空行作为分隔符,读取到的临时存放到request_header,5步骤转化为哈希表存储
bool RecvHttpRequestHeader()
{
//若干行,所以这里需要循环读取
while (true)
{
std::string line;
// 1.读取失败,读取上来返回值小于等于0
if (Util::ReadLine(sock, line) <= 0)
{
stop = true;
break;
}
// 2.读取到空行,此时设置空行字段
if (line == "\n")
{
//若没有读取到空行,则blank为""
http_request.blank = line;
break;
}
// 3.读取到了例如Content-Length: 36的字段
line.resize(line.size() - 1);
//由vector 统一保存
http_request.request_header.push_back(line);
LOG(INFO, line);
}
return stop;
}
解析的原因如下
解析的原因:
- 请求行包括三个字段:方法,uri和版本,分来方便直接使用
- 请求正文要判断是否有没有,以及具体要读多少,这依赖于请求头部的Content-Length字段,想要快速找到这个字段,我们可以遍历前面的
vector,但是如果我们后续需要更多的字段都遍历那么效率就不高,所以我们添加unordered_map,这样就可以通过搜索Content-Length字段得知我们是否需要读取以及读取多少内容当作正文。
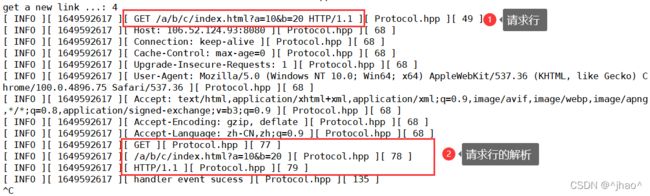
ParseHttpRequestLine
解析请求行:
注意:
- 此处需要矫正get/post,我们需要将get小写都转化为大写,我们可以使用transform进行转化。
// 3.解析请求行,填充method,url,version字段
void ParseHttpRequestLine()
{
//采用stringstream,默认读到string当中以空格为分隔
std::stringstream ss(http_request.request_line);
ss >> http_request.method >> http_request.uri >> http_request.version;
std::string &method = http_request.method;
// get/Get/GET 统一转化为大写GET
transform(method.begin(), method.end(), method.begin(), ::toupper);
LOG(INFO, http_request.method);
LOG(INFO, http_request.uri);
LOG(INFO, http_request.version);
}
一变三,如图下:
ParseHttpRequestHeader
解析请求头部。填充入哈希表,方便后续使用。
// 4.解析请求头部,同时告知是否有正文(content_length)
void ParseHttpRequestHeader()
{
std::string key, value;
//初始化哈希表header_kv
for (auto &str : http_request.request_header)
{
// SEP是:+空格,CutString这里将一个个string重新切分到哈希表当中
//方便后续直接通过哈希表O(1)查找类似Content-Length,不需要到request_header当中遍历寻找
Util::CutString(str, key, value, SEP);
std::cout << "debug " << key << ":" << value << std::endl;
http_request.header_kv[key] = value;
}
RecvHttpRequestBody
读取正文需要判断是否有,以及若要读取多少的问题,所以我们采用一次性读一个字符,这样子当读不到就说明报文有问题,此时可以销毁这个套接字。stop字段的使用如果在读取阶段错误我们删除套接字,后续过程出错我们返回错误页面。
// 5.1 是否需要读取正文,若是POST并且存在Content-Length返回true,其他返回false
bool IsNeedRecvHttpRequestBody()
{
if (http_request.method == "POST")
{
auto iter = http_request.header_kv.find("Content-Length");
if (iter != http_request.header_kv.end())
{
// 1.找到了Content-Length
//设置请求结构的content_length正文长度
http_request.content_length = stoi(iter->second);
return true;
}
else
{
// 2.找不到Content-Length
return false;
}
}
return false;
}
// 5. 读取正文,返回值为stop表示是否需要暂停
bool RecvHttpRequestBody()
{
//判断是否需要读取正文
if (IsNeedRecvHttpRequestBody())
{
std::string &body = http_request.request_body;
int content_length = http_request.content_length;
char ch = 0;
//一个字符的读取,防止粘包
while (content_length)
{
if (recv(sock, &ch, 1, 0) > 0)
{
content_length--;
body += ch;
}
else
{
//读取失败就不用继续了
stop = true;
break;
}
}
}
return stop;
}
BulidHttpResponse
制造回应的过程比较复杂。
分为以下步骤:
- 判断是否是CGI程序,更改访问的路径(默认不修改访问的是根路径!)
- 判断文件是否存在
判断路径是否存在:
- 即确认wwwroot下的某种文件是否存在,这里用stat(函数说明: 通过文件名filename获取文件信息,并保存在buf所指的结构体stat中),系统调用,获取一个属性,当我们获得一个文件的属性,就说明存在,获取失败,就说明不存在此文件。
即传入路径和一个输入型参数,就可以获取到该路径对应文件的信息。
SYNOPSIS
#include
#include
#include
int stat(const char *path, struct stat *buf);
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* inode number */
mode_t st_mode; /* protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device ID (if special file) */
off_t st_size; /* total size, in bytes */
blksize_t st_blksize; /* blocksize for file system I/O */
blkcnt_t st_blocks; /* number of 512B blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last status change */
};
mode_t st_mode; /* protection */使用的较多
存在需要考虑的情况:
- 是目录(S_ISDIR判断),那么默认每一个目录底下都有一个index.html,需要将访问的路径进行调整(即添加index.html),最终返回的是这个资源。
- 是可执行程序,那么需要设置它是CGI程序,CGI通过处理过后返回结果再由父进程发送给客户端。
存在就是可以访问读取的吗?
也不一定,需要给出对应的权限。
Linux的目录结构是树状从跟开始,但是这里的请求报头的/并不是Linux的根目录开始,通常我们会有一个web目录,我们所提供的jsp页面,等等图片,视频资源通常放在web目录下。
我们通常由http服务器设置为自己的WEB根目录,就是一个Linux下一个特定的路径。我创建的wwwroot就是网页的目录。
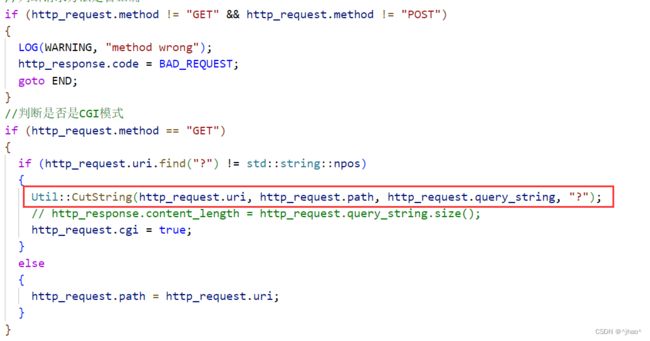
// 6.BulidHttpResponse负责将内部负责报文的完成,并且处理两种模式
// 需要判断是否为CGI程序,以及需要处理访问路径
void BulidHttpResponse()
{
std::string path;
struct stat st;
size_t suffix_index;
int size = 0; //文件的大小
//
///判断是否为CGI程序
//判断请求方法是否正确
if (http_request.method != "GET" && http_request.method != "POST")
{
LOG(WARNING, "method wrong");
http_response.code = BAD_REQUEST;
goto END;
}
//判断是否是CGI模式
if (http_request.method == "GET")
{
if (http_request.uri.find("?") != std::string::npos)
{
Util::CutString(http_request.uri, http_request.path, http_request.query_string, "?");
// http_response.content_length = http_request.query_string.size();
http_request.cgi = true;
}
else
{
http_request.path = http_request.uri;
}
}
else if (http_request.method == "POST")
{
http_request.path = http_request.uri;
http_request.cgi = true;
}
else
{
//若有其他GET/POST其它的类型,可以在这里添加....TODO
}
//
///调整访问路径
///添加wwwroot/ ,防止用户从根目录开始访问
//
path = http_request.path;
http_request.path = WEBROOT;
http_request.path += path;
//若客户访问为111.111.111.111:8080/,浏览器会自动帮你在末尾添加/,此时我们只需要指定访问index页面
if (http_request.path[http_request.path.size() - 1] == '/')
{
http_request.path += HOME_PAGE;
std::cout << "DEBUG path:" << http_request.path << std::endl;
}
else
{
std::cout << "DEBUG path:" << http_request.path << std::endl;
}
//
///判断路径是否合法
/
if (stat(http_request.path.c_str(), &st) == 0)//路径合法
{
//1.该文件是目录,需要添加index.html
if (S_ISDIR(st.st_mode))
{
http_request.path += HOME_PAGE;
//添加HOME_PAGE过后需要更新路径
stat(http_request.path.c_str(), &st);
}
//2.文件若是拥有者执行执行,组内执行,其他人执行,即该文件只要有执行权限,也需要设置CGI模式
if ((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH))
{
//设置CGI模式
http_request.cgi = true;
}
//3.请求文件的大小设置
size = st.st_size;
http_response.size = size;
}
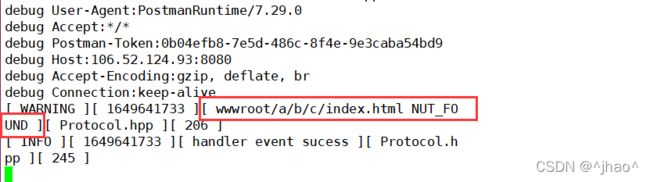
else//路径不合法,跳转到响应404页面
{
//资源不存在
std::string path = http_request.path;
path += " NUTFOUND";
LOG(WARNING, path + " Not Found");
http_response.code = NOT_FOUND;
goto END;
}
//处理后缀
suffix_index = http_request.path.rfind(".");
if (suffix_index == std::string::npos)
{//请求的路径没有后缀,默认设置.html
http_response.suffix = ".html";
}
else
{//设置后缀字段
http_response.suffix = http_request.path.substr(suffix_index);
}
//走到这里默认设置code为正常200
http_response.code = 200;
//
///处理请求的需求
//
if (http_request.cgi == false)
{
//只负责打开文件描述符,END统一建立回应
http_response.code = ProcessNonCgi();
}
else
{
http_response.code = ProcessCgi();
}
END:
BulidHttpResponseHelper();
return;
}//end of BulidHttpResponse
CGI
CGI程序需要根据GET,POST方法读取不同的字段(环境变量)或者管道里的数据,已经重定向,所以可以通过标准输出获取进行处理,CGI程序可以用任何语言实现。
CGI(Common Gateway Interface)是WWW技术中最重要的技术之一,有着不可替代的重要地位(网络服务器和后端业务程序耦合重要机制,理解PhP/Python/Java如何把网络里的数据拿到自身的程序中)。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。
HTTP并不负责处理数据,HTTP负责数据的传递,但是HTTP会提供某种方式对数据进行处理,即CGI模式。
HTTP 调用目标程序,传递目标数据,获取目标结果 --CGI
大部分语言底层都会封装CGI,我们这里旨在学习。通过这个可以理解http如何给我们的java,py拿到数据并响应。
我们这里将整个文件传输过去即可。
SYNOPSIS
#include
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
从in_fd读,写到out_fd,offset为nullptr,count表示你想拷贝的字节数。
CGI程序可以通过输出将结果带回给父进程,并且由于子进程关闭,父进程读端会读到0,即结尾。
#include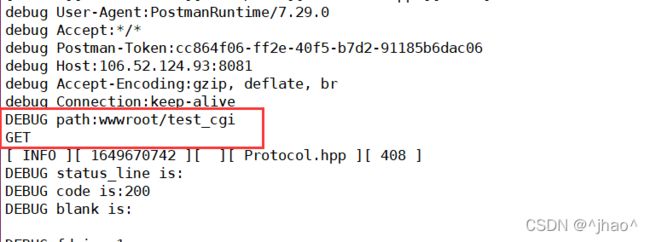
CGI程序和非CGI程序处理函数详解~
ProcessNonCgi
ProcessNonCgi只需要返回打开的文件,比较简单,返回文件描述符,在BuildOk当中就会将该文件用sendfile这种0拷贝技术进行拷贝回去。
//6.2处理非CGI程序
int ProcessNonCgi()
{
http_response.fd = open(http_request.path.c_str(), O_RDONLY);
if (http_response.fd >= 0)
{
return OK;
}
return NOT_FOUND;
}
ProcessCgi
CGI模式的处理稍微复杂,分为以下几步骤
- 创建子进程,创建两个管道(为了父子之间的通信),将数据交给子进程处理,父进程直接可以通过创建孙子进程的方式直接返回。
- 子进程设置环境变量(如GET的方法需要的query,POST方法需要正文的长度,以及发送正文给子进程)。子进程通过进程替换过后直接执行程序来解决,但是需要读取环境变量获取相关信息,如Content-Length,Method方法就可以通过环境变量,而正文可能是大量数据通过管道传输。
- 管道通常是创建之后fork,然后这里的命名是以父进程的身份,父进程在outfd[1]当中写,infd[0]里面读,反之子进程在outfd[0]里面读,infd[1]里面写。然后由于execl函数导致可能
BulidHttpResponse函数内部这里的切分了query_string是不包含?的。
如https://blog.csdn.net/weixin_52344401/article/details/125898517?a=10,则path是https://blog.csdn.net/weixin_52344401/article/details/125898517,query是a=10。
重定向的目的:子进程程序替换过后,虽然文件描述符表还存在,但是在上层,进程的代码和数据都被替换了,所以需要通过重定向,往自定义协议0为读,1为写。
putenv(使用注意string是否已经析构了!!)
SYNOPSIS
#include
int putenv(char *string);
- putenv函数:
putenv 函数会将参数 string 直接填写到环境表中,不会再为 “name=value” 这个字符串再去分配内存。如果是在一个函数中定义的string,那么在调用该函数后,string 指向的内容可能会被释放,就找不到name环境变量的值了。 - setenv 函数:
setenv 函数和 putenv 函数不同,它会将name和value指向的内容复制一份并为其分配内存,形成 “name=value” 的字符串,并将其地址写入到环境表中。所以就不会出现上面putenv 的情况,就算函数返回了,name 和 value指向的内容被释放了,仍然有一份拷贝在。
SYNOPSIS
#include
char *getenv(const char *name);
///
处理CGI程序,需要创建子进程处理,response_body此时才会被设置
//
int ProcessCgi()
{
std::string &bin = http_request.path;
auto &code = http_response.code;
//以父进程的角度创建两个管道进行父子之间通信
int outfd[2];
int infd[2];
if (pipe(outfd) < 0)
{
LOG(ERROR, "create pipe error!");
code = SERVER_ERROR;
return code;
}
if (pipe(infd) < 0)
{
LOG(ERROR, "create pipe error!");
code = SERVER_ERROR;
return code;
}
pid_t pid = fork();
if (pid < 0)
{
LOG(ERROR, "fork fail!");
code = SERVER_ERROR;
return code;
}
else if (pid == 0)
{
// child
///
///子进程负责将环境变量设置好,进行进程替换给对应的进程处理数据
///
close(outfd[1]);
close(infd[0]);
//提前把方法传递给子进程
std::string method = "METHOD=";
method += http_request.method;
putenv((char *)method.c_str());
//若是GET方法,子进程将QUERY_STRING的内容设置到环境变量即可
if (http_request.method == "GET")
{
std::string query_string_env = "QUERY_STRING=";
query_string_env += http_request.query_string;
putenv((char *)query_string_env.c_str());
LOG(INFO, "GET putenv: " + query_string_env);
}
//若为POST方法,子进程将要接受LENGTH长度以环境变量发送
else if (http_request.method == "POST")
{
std::string content_length_env = "LENGTH=";
content_length_env += std::to_string(http_response.content_length);
putenv((char *)content_length_env.c_str());
LOG(INFO, "POST Putenv :" + content_length_env);
}
//进行重定向
//子进程outfd[0]里读,infd[1]里写
dup2(outfd[0], 0);
dup2(infd[1], 1);
//子进程进程替换过后环境变量不会改变,此时协议规定往0文件描述符是写,往1是读。
execl(bin.c_str(), bin.c_str(), nullptr);
//进程替换后这里后面若执行就是出错了
LOG(WARNING, "execl fail!");
exit(1);
}
else
{
///
父进程负责发送请求正文给子进程,对子进程进行等待
///
// father
close(outfd[0]);
close(infd[1]);
//子进程已经获取了LENGTH字段,父进程发送请求正文给子进程处理
if (http_request.method == "POST")
{
size_t total = 0; //以发送多少
const char *start = http_request.request_body.c_str(); // start指向数据起始
ssize_t size = 0; //一次发送的数据
while (total < http_request.request_body.size() && (size = write(outfd[1], start + total, http_request.request_body.size() - total)) > 0)
{
total += size;
}
}
int status = 0;
int ret = waitpid(pid, &status, 0);
if (ret == pid)
{
// std::cerr << "debug father read success: 1"<< std::endl;
char ch = 0;
if (WIFEXITED(status))
{
// std::cerr << "debug father read success: 2"<< std::endl;
if (WEXITSTATUS(status) == 0)
{
// std::cerr << "debug father read success: 3"<< std::endl;
//正常退出,写端关闭,读端会读到0
while (read(infd[0], &ch, 1))
{
//子进程会自动退出,读上来的数据放进response_body当中
http_response.response_body.push_back(ch);
std::cerr << "debug father read success: " << ch << std::endl;
}
//response_body此时才会被设置
std::cerr << "debug :" << http_response.response_body << std::endl;
code = OK;
}
else
{
code = BAD_REQUEST;
}
}
else
{
code = SERVER_ERROR;
}
}
close(outfd[1]);
close(infd[0]);
}
return code;
}
HandlerRequest
HandlerRequest是CallBack类当中最重要的模块,最终就是调用这个函数,进行一系列操作,结束过后销毁ep对象析构函数会把文件描述符关闭,断开连接。至此,基于短链接多线程池的HTTP服务器就完成了。
void HandlerRequest(int *_sock)
{
int sock = *(int *)_sock;
std::cout << "get a new link ...: " << sock << std::endl;
// EndPoint负责关闭文件描述符
EndPoint *ep = new EndPoint(sock);
ep->RecvHttpRequest();
if (!ep->Stop())
{
LOG(INFO, "Recv no error,begin Build and Send");
ep->BulidHttpResponse();
ep->SendHttpResponse();
}
else
{
LOG(WARNING, "Recv Error ,Stop Bulid And Send");
}
delete ep;
LOG(INFO, "handler event sucess");
#endif
return;
}
最后需要通过退出码得到描述状态信息,使用Code2Desc即可。
std::string Code2Desc(int code)
{
std::string res;
switch (code)
{
case 404:
res = "Not Found";
break;
case 200:
res = "OK";
break;
}
return res;
}
这个工具类读取流的时候是否要加锁??
工具类的使用都在Task的栈上的对象当中,所以不用。
构建日志能够有利于帮助我们快速定位问题,解决问题!
构建日志
日志是我们定位问题的一个比较重要的依据,我们只是需要输出日志格式的函数即可。
[日志级别][时间戳][日志信息][错误文件名称][行数]
日志分级别:
INFO:正常输出
WARNING:表示一些告警。
ERROR:有一些错误。
FATAL:致命信息,程序不能往后面走了。
时间戳可以通过一些函数直接获取时间戳,时间戳获取时间time函数。
time_t是一个无符号整数。
文件名称和行数可以通过C提供的一些。
__FILE__ 会显示所在文件
__LINE__会显示所在行数
我们这里致命的信息会打印感叹号。
Log.hpp实现,通过提供LOG接口,让Log传参的时候不需要频繁传__LINE__和__FILE__。
#pragma once
#include
cgi程序几乎可以用任何的后端语言来实现。
注意:
cgi程序要输入,不能使用cout了,cout就是往标准输出打印了,已经被重定向到管道了,所以我们要打印内容到终端,可以使用cerr
编写Makefile
代码的生成
bin=httpserver
cgi=test_cgi
CC=g++
LD_FLAGS=-std=c++11 -lpthread
src=main.cc
curr=$(shell pwd)
ALL:$(bin) $(cgi)
.PHONY:ALL
$(bin):$(src)
$(CC) -o $@ $^ $(LD_FLAGS)
$(cgi):cgi/test_cgi.cc
$(CC) -o $@ $^
.PHONY:clean
clean:
rm -f $(bin) $(cgi)
生成output文件
.PHONY:clean
clean:
rm -f $(bin) $(cgi)
rm -rf output
.PHONY:output
output:
mkdir -p output
cp $(bin) output
cp -rf wwwroot output
cp $(cgi) output/wwwroot
测试错误请求
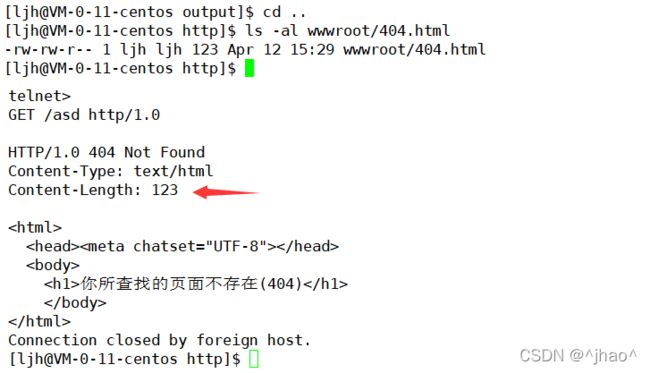
telnet对于访问不存在/asd路径,返回错误页面。
错误码
处理HTTP的两种错误:
- 逻辑错误(已经读取完毕,构建时出问题),如:CGI创建线程失败
- 读取错误 - 读取过程不一定完毕了,此时不给对方回应,此时可以直接close套接字,deleteEndPoint即可。
所以Endpoint需要添加bool stop变量,默认stop为false。
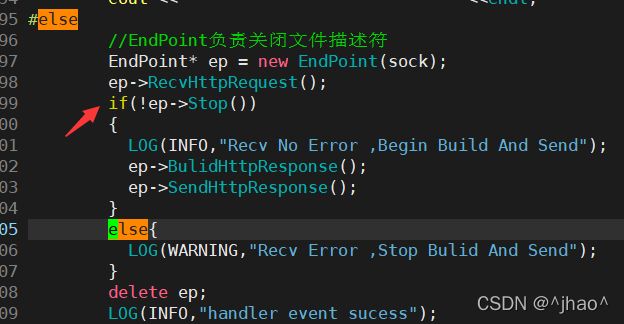
上述第二种错误:
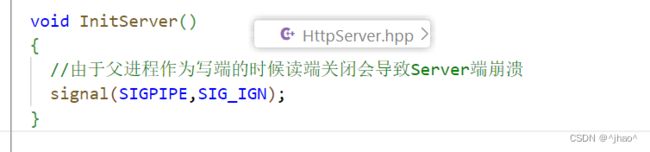
父进程写入的时候出错,或者读端因为某些原因而关闭了,或者由于网络因素关闭了,此时写端会收到信号SIG_PIPE,此时我们的进程会被退出!
所以我们可以将SIG_PIPE忽略即可。
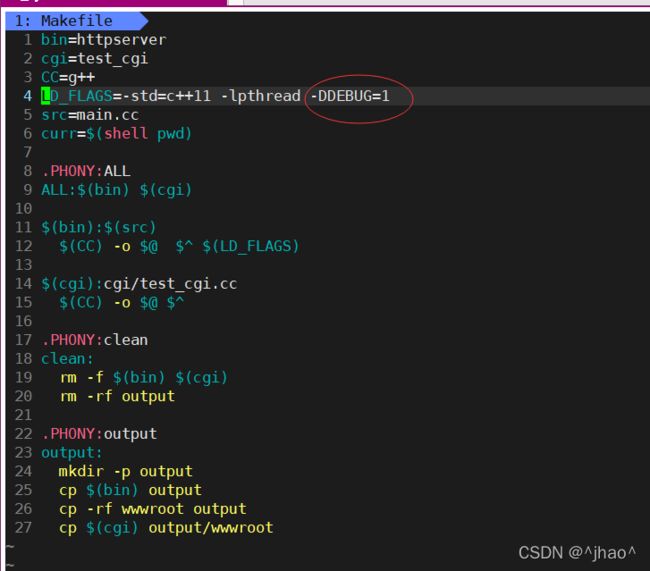
Debug选项打开:
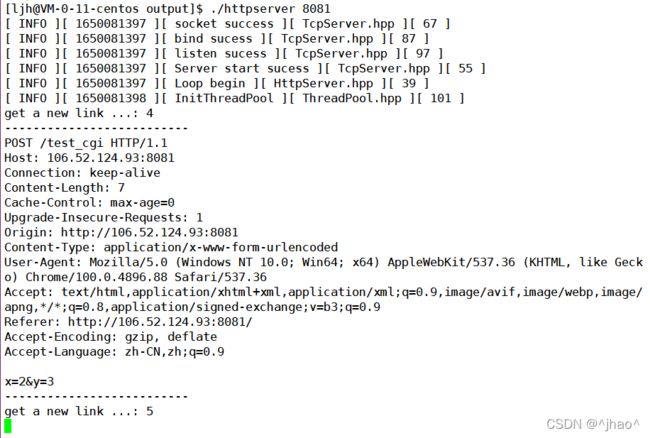
查看POST方法上传的数据。
总结
至此,HttpServer就完成了,后续还会更新相关数据库连接,以及CGI程序的一个优化,弄出一个更有意义的页面。
码云直达
- 喜欢就收藏
- 认同就点赞
- 支持就关注
- 疑问就评论