MySQL 性能调优和优化技巧
介绍
MySQL 是一种流行的开源数据库应用程序,它以一种有意义且易于访问的方式存储和构造数据。对于大型应用程序,庞大的数据量可能会导致性能问题。
本指南提供了一些关于如何提高 MySQL 数据库性能的调优技巧。
先决条件
- 安装并运行 MySQL 的 Linux 系统,Centos或Ubuntu
- 现有数据库
- 操作系统和数据库的管理员凭据
系统 MySQL 性能调优
在系统级别,您将调整硬件和软件选项以提高 MySQL 性能。
1.平衡四大硬件资源
磁盘存储
花点时间评估您的存储空间。如果您使用的是传统硬盘驱动器 (HDD),则可以升级到固态驱动器 (SSD) 以提高性能。
使用sysstat包中的iotop或sar之类的工具来监控磁盘输入/输出速率。如果磁盘使用率远高于其他资源的使用率,请考虑添加更多存储或升级到更快的存储。
处理器
处理器通常被认为是衡量系统速度的指标。使用Linux top命令了解资源的使用情况。注意 MySQL 进程及其所需的处理器使用百分比。
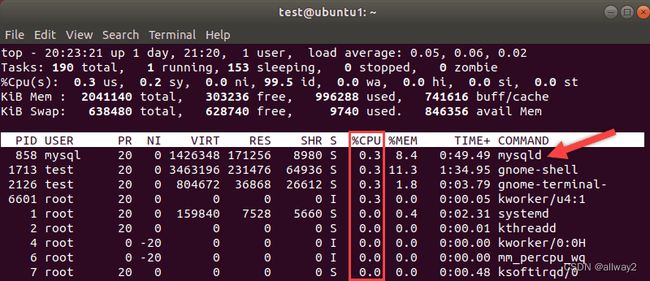
处理器的升级成本更高,但如果您的 CPU 是瓶颈,则可能需要升级。
内存
内存表示您的 MySQL数据库存储服务器中的 RAM 总量。您可以调整内存缓存(稍后会详细介绍)以提高性能。如果您没有足够的内存,或者现有内存没有优化,您最终可能会损害您的性能而不是提高它。
像其他瓶颈一样,如果您的服务器经常耗尽内存,您可以通过添加更多来升级。如果您的内存不足,您的服务器将缓存数据存储(如硬盘)以充当内存。数据库缓存会降低您的性能。
网络
监控网络流量以确保您有足够的基础设施来管理负载非常重要。
网络过载会导致延迟、丢包甚至服务器中断。确保您有足够的网络带宽来容纳正常水平的数据库流量。
2. 使用 InnoDB,而不是 MyISAM
MyISAM是一种较旧的数据库样式,用于某些 MySQL 数据库。这是一种效率较低的数据库设计。较新的InnoDB支持更高级的功能并具有内置的优化机制。
InnoDB 使用聚集索引并将数据保存在页面中,这些页面存储在连续的物理块中。如果某个页面的值太大,InnoDB 会将其移动到另一个位置,然后索引该值。此功能有助于将相关数据保存在存储设备上的同一位置,这意味着物理硬盘驱动器访问数据所需的时间更少。
3.使用最新版本的MySQL
对于旧的和遗留的数据库,使用最新版本并不总是可行的。但只要有可能,您应该检查正在使用的 MySQL 版本并升级到最新版本。
正在进行的开发的一部分包括性能增强。一些常见的性能调整可能会被较新版本的 MySQL 淘汰。一般来说,使用原生 MySQL 性能增强总是比脚本和配置文件更好。
软件 MySQL 性能调优
SQL 性能调优是在关系数据库上最大化查询速度的过程。该任务通常涉及多种工具和技术。
这些方法包括:
- 调整 MySQL 配置文件。
- 编写更高效的数据库查询。
- 构建数据库以更有效地检索数据。
注意:调整配置设置时,最好进行小的增量调整。重大调整可能会使另一个值负担过重并降低性能。此外,建议您一次进行一项更改,然后进行测试。当您一次只更改一个变量时,更容易跟踪错误或错误配置。
4.考虑使用自动性能改进工具
与大多数软件一样,并非所有工具都适用于所有版本的 MySQL。我们将检查三个实用程序来评估您的 MySQL 数据库并推荐更改以提高性能。
第一个是tuning-primer。这个工具有点老,专为 MySQL 5.5 - 5.7 设计。它可以分析您的数据库并建议设置以提高性能。例如,如果感觉您的系统无法足够快地处理查询以保持缓存清晰,它可能会建议您提高query_cache_size参数。
对大多数现代 SQL 数据库有用的第二个调优工具是MySQLTuner。该脚本 ( mysqltuner.pl ) 是用 Perl 编写的。与tuning-primer 一样,它会分析您的数据库配置,寻找瓶颈和低效率。输出显示指标和建议:
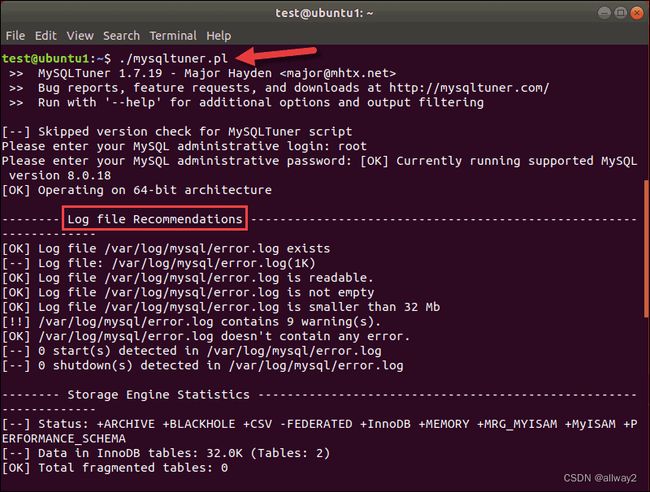
在输出的顶部,您可以看到 MySQLTuner 工具和您的数据库的版本。
该脚本适用于 MySQL 8.x。日志文件建议是列表中的第一个,但如果您滚动到底部,您可以看到提高 MySQL 性能的一般建议。
您可能已经拥有的第三个实用程序是phpMyAdmin Advisor。与其他两个实用程序一样,它会评估您的数据库并建议调整。如果您已经在使用 phpMyAdmin,Advisor 是您可以在 GUI 中使用的有用工具。
注意:查看我们的顶级 SQL 查询优化工具列表,并使用我们对每个工具的深入分析来找到最适合您任务的工具。
5.优化查询
查询是一个编码请求,用于在数据库中搜索与某个值匹配的数据。有一些查询运算符,就其本质而言,需要很长时间才能运行。SQL 性能调优技术有助于优化查询以获得更好的运行时间。
检测执行时间很短的查询是性能调优的主要任务之一。通常在大型数据集上实现的查询速度很慢并且占用数据库。因此,这些表不可用于任何其他任务。
注意:考虑研究数据仓库架构,它将生产数据库与分析数据库分开。
例如,OLTP 数据库需要快速事务和有效的查询处理。运行效率低下的查询会阻止数据库的使用并停止信息更新。
如果您的环境依赖于触发器等自动查询,它们可能会影响性能。检查并终止可能及时堆积的MySQL 进程。
6. 在适当的地方使用索引
许多数据库查询使用与此类似的结构:
SELECT … WHERE这些查询涉及评估、过滤和检索结果。您可以通过为相关表添加一小组索引来重组它们。查询可以直接指向索引,加快查询速度。
7. 谓词中的函数
避免在查询的谓词中使用函数。例如:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'该UPPER符号创建一个函数,该函数必须在操作期间SELECT运行。这会使查询的工作加倍,如果可能,您应该避免它。
8. 避免在谓词中使用 % 通配符
在搜索文本数据时,通配符有助于进行更广泛的搜索。例如,要选择所有以ch开头的名称,请在 name 列上创建索引并运行:
SELECT * FROM person WHERE name LIKE "ch%"查询扫描索引,使查询成本低:
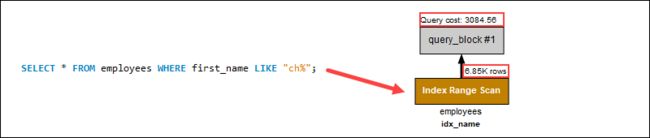
但是,在开头使用通配符搜索名称会显着增加查询成本,因为索引扫描不适用于字符串的结尾:
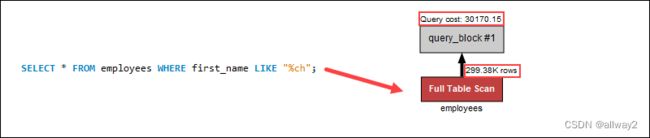
搜索开头的通配符不应用索引。相反,全表扫描单独搜索每一行,增加了该过程中的查询成本。在示例查询中,在末尾使用通配符有助于降低查询成本,因为要经过更少的表行。
注意:查看我们的MySQL 命令备忘单,其中包含索引命令。
搜索字符串结尾的一种方法是反转字符串,索引反转的字符串并查看起始字符。现在将通配符放在末尾会搜索反转字符串的开头,从而提高搜索效率。
9.在SELECT函数中指定列
分析和探索性查询的常用表达式是SELECT *. 选择超出您的需要会导致不必要的性能损失和冗余。如果您指定您需要的列,您的查询将不需要扫描不相关的列。
如果需要所有列,则没有其他方法可以解决。但是,大多数业务需求不需要数据集中所有可用的列。考虑改为选择特定列。
总而言之,避免使用:
SELECT * FROM table相反,请尝试:
SELECT column1, column2 FROM table10. 恰当地使用 ORDER BY
该ORDER BY表达式按指定列对结果进行排序。它可用于一次按两列排序。这些应该以相同的顺序排序,升序或降序。
如果您尝试以不同的顺序对不同的列进行排序,则会降低性能。您可以将其与索引结合起来以加快排序。
11. GROUP BY 代替 SELECT DISTINCT
尝试删除重复值时,SELECT DISTINCT 查询会派上用场。但是,该语句需要大量的处理能力。
只要有可能,请避免使用SELECT DISTINCT,因为它效率非常低,有时会令人困惑。例如,如果一个表列出了具有以下结构的客户信息:
| id | name | lastName | address | city | state | zip |
|---|---|---|---|---|---|---|
| 0 | John | Smith | 652 Flower Street | Los Angeles | CA | 90017 |
| 1 | John | Smith | 1215 Ocean Boulevard | Los Angeles | CA | 90802 |
| 2 | Martha | Matthews | 3104 Pico Boulevard | Los Angeles | CA | 90019 |
| 3 | Martha | Jones | 2712 Venice Boulevard | Los Angeles | CA | 90019 |
运行以下查询会返回四个结果:
SELECT DISTINCT name, address FROM person
该声明似乎应该返回一个不同名称的列表及其地址。相反,查询同时查看名称和地址列。虽然有两对同名的客户,但他们的地址不同。
要过滤掉重复的名称并返回地址,请尝试使用以下GROUP BY语句:
SELECT name, address FROM person GROUP BY name结果返回第一个不同的名称以及地址,使语句不那么模棱两可。要按唯一地址分组,GROUP BY参数只需更改为地址并DISTINCT更快地返回与语句相同的结果。
总而言之,避免使用:
SELECT DISTINCT column1, column2 FROM table相反,请尝试使用:
SELECT column1, column2 FROM table GROUP BY column112. JOIN、WHERE、UNION、DISTINCT
尽可能尝试使用内部联接。外连接查看指定列之外的附加数据。如果您需要这些数据,那很好,但是包含不需要的数据会浪费性能。
使用INNER JOIN是连接表的标准方法。大多数数据库引擎也接受使用WHERE。例如,以下两个查询输出相同的结果:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id和....相比:
SELECT * FROM table1, table2 WHERE table1.id = table2.id理论上,它们也具有相同的运行时间。
是使用还是查询的选择取决于数据库引擎。虽然大多数引擎对这两种方法具有相同的运行时,但在某些数据库系统中,一种运行速度比另一种快。JOIN WHERE
注意:了解有关MySQL JOINS以及如何使用它们的更多信息。
和命令有时包含在查询中。与外连接一样,如果需要,可以使用这些表达式。但是,它们增加了对数据库的额外排序和读取。如果你不需要它们,最好找到更有效的表达方式。UNION DISTINCT
13. 使用 EXPLAIN 函数
现代 MySQL 数据库包含一个EXPLAIN函数。
将表达式附加EXPLAIN到查询的开头将读取和评估查询。如果有低效的表达方式或令人困惑的结构,EXPLAIN可以帮助您找到它们。然后,您可以调整查询的措辞以避免无意的表扫描或其他性能损失。
14. MySQL 服务器配置
此配置涉及更改您的/etc/mysql/my.cnf文件。谨慎行事,一次进行细微的更改。
query_cache_size– 指定等待运行的 MySQL 查询的缓存大小。建议从 10MB 左右的小值开始,然后增加到不超过 100-200MB。如果缓存查询过多,您可能会遇到“等待缓存锁定”的级联查询。如果您的查询不断备份,则更好的过程是使用EXPLAIN评估每个查询并找到提高它们效率的方法。
max_connection– 指允许进入数据库的连接数。如果您收到引用“连接太多”的错误,则增加此值可能会有所帮助。
innodb_buffer_pool_size – 此设置将系统内存分配为数据库的数据缓存。如果您有大量数据,请增加此值。记下运行其他系统资源所需的 RAM。
innodb_io_capacity – 此变量设置存储设备的输入/输出速率。这与存储驱动器的类型和速度直接相关。5400 rpm HDD 的容量将比高端 SSD 或 Intel Optane低得多。您可以调整此值以更好地匹配您的硬件。
结论
您现在应该知道如何提高 MySQL 性能和调整数据库。
寻找瓶颈(硬件和软件)、工作量超出需要的查询,并考虑使用自动化工具和EXPLAIN功能来评估您的数据库。
优化 MySQL 表有助于在专用存储服务器中重新排序信息,以提高数据输入和输出速度。查看我们关于如何优化 MySQL 表的指南。