正则学习笔记
用途
字符匹配
语法
常用元字符
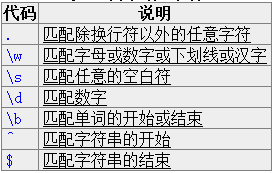
[] 区间范围框 枚举值 [a-z0-9A-Z_]
| 分枝条件或
\ 特殊转义符(取消转义)
\W [^A-Za-z0-9_]
限定符

贪婪匹配:默认的匹配方式,尽量匹配更多的字符 .*
懒惰匹配:若发现匹配立即返回,懒惰搜索 .*?
例:/a.*b/.exec("/abcdedfb") abcdedfb
/a.*?b/.exec("/abcdedfb") ab
分组/捕获组
() 从左向右,以分组的左括号为标志。 \1代表分组1,js中对应RegExp.$1。 (?:exp)可以取消分组纪录
常用分组语法

Javascript的正则
模式
g 全局匹配,匹配后会标记lastIndex用于下一次继续匹配。
i 忽略大小写
m 换行匹配,影响^/$定义
初始化
1)/pattern/flags 2)new RegExp("pattern","flags") 字符串转义 \ => \\
例: /\./i=new RegExp("\\.","i")
api
pattern.exec(str) 执行正则匹配,静态属性RegExp.$1~$9 保存第1~第9个匹配的捕获组()的信息
pattern.test(str) 验证是否满足正则,不关心匹配的字符
参考资料:http://deerchao.net/tutorials/regex/regex.htm
常用正则:
XSS过滤:/^(?:[^#<]*(<[\w\W]+>)[^>]*$|#([\w\-]*)$)/
url匹配正则:/http:\/\/([\w.]+)(\/[\w\/]+\/)([\w.]+)(?:\?([\w=&]+))?/g;