numpy 学习笔记 --《利用python进行数据分析》
numpy学习笔记
- 数组ndarry的基本用法
-
- 创建ndarry
- ndarray的数据类型
- 数组ndarry运算
- 数组ndarry的基本索引和切片
-
- 一维数组
- 二维数组
- 数组的布尔型索引
- 花式索引
- nadarry的转置和轴对换。
- 通用函数:对数组的元素进行挨个进行运算
- 条件逻辑表述数组运算
- 数学和统计方法:
- 数组排序
- 数组唯一化以及其他集合逻辑
- 数组的文件输入以及输出
- numpy中的矩阵运算
- 伪随机数生成
- 广播
数组ndarry的基本用法
创建ndarry
numpy中多维数组对象是ndarry
-
创建ndarray
最简单的方法是调用array函数
调用zero,ones函数(也可以调用empty函数,但数组中全是垃圾值)

至于调用的方法,可以在ide中寻找到函数原型,查看注释。 -
ndarry类中比较重要方法:
data.shape:数组的维度
data.dtype:数组数据类型 默认float64
data.ndim:数组的维度
例子
import numpy as np
# 生成一个1~1000的一维数组
data = np.array([[1, 2, 3], [4, 5, 6]])
print(data)
print(data.shape)
print(data.dtype)
结果是:
[[1 2 3]
[4 5 6]]
(2, 3)
int64
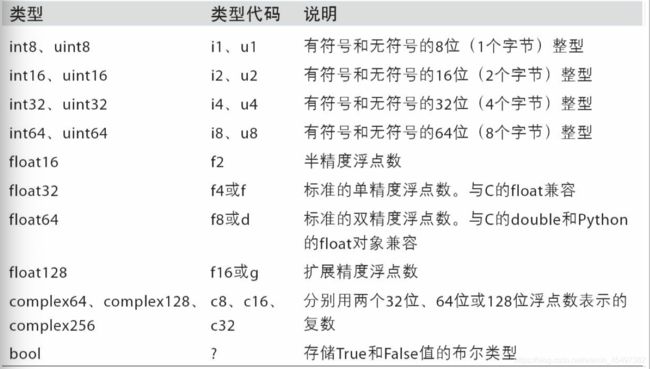
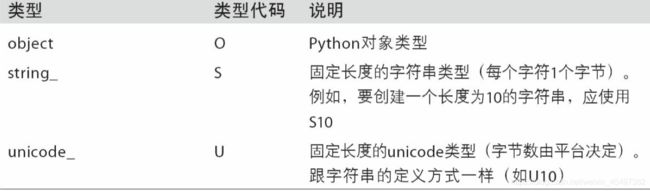
ndarray的数据类型
如果创建数组,默认float64。
numpy所支持的数据类型:
astype可以将数组的数据类型进行转化:
import numpy as np
# 不推荐由高往低转化
data = np.full([2, 3], 10, np.float64)
print(data.dtype)
# astype并不会修改原来数组的数据类型,需要承接结果
data = data.astype(np.int32)
print(data.dtype)
结果为:
float64
int32
astype也可以将改变数组中元素的数据类型,比如数组中的元素都是字符串,可以调用该函数,将其转化为浮点数。
data = np.array(['2.33', '0.56'])
print(data)
print(data.dtype)
data = data.astype(np.float64)
print(data)
print(data.dtype)
结果:
['2.33' '0.56']
<U4
[2.33 0.56]
float64
数组ndarry运算
加减乘除均支持,比如两个矩阵A、B,对其使用加法运算,就是A和B对应的元素相加,A的第一列第一行,和B的第一列第一行元素相加。A第二列第二行,B第二列第二行相加。(当A和B的大小形状相同时,如果不相同时的运算为广播)
数组ndarry的基本索引和切片
一维数组
一维数组与python的相同,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反 映到源数组上。
切片:arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
arr[5:8]
会得到[5, 6, 7],其中 : 的作用跟5~8中的 ~ 传达的意思接近,不过8是取不到的。
如果arr[5:8] = 12 也会触发广播,因为形状不对,5:8有3个元素,而12只是一个元素。
如果想的到一个数组or数组切片的复制需要使用 copy函数
二维数组
二维数组所使用的索引可以是:
[1][2] 或者 [1, 2],所代表的意思都是访问数组的第一行,第二列(包含第0行,第0列)的元素。
在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的 ndarray(它含有高一级维度上的所有数据)
二维数组所使用的切片:
一般而言,我们更偏向与使用[a, b] 而不是[a][b]。
arr[1, :2]表示的是:第一行的第0列,第1列(包含第0行,第0列)
那么arr[:, 1]以及arr[1:, 0]是什么意思?
arr[:, 1]:所有行,第1列的元素
arr[1:, 0]:除第0行外所有行,第0列的元素
data = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# 切片,第0行的第0,一列元素
print(data[0, :2])
# 输出结果
[1 2]
数组的布尔型索引
不管是普通索引还是布尔型索引,目的都是为了寻找元素,可能是一个亦或者一行or一列。
import numpy as np
data = np.random.randn(6, 4)
data = data.astype(np.float32)
name = np.array(["C", "python", "C", "Perl", "java", "C++"])
print(data, "\n")
print(name == 'C', '\n')
print(data[name == 'C'])
结果
[[ 1.2061282 -0.16772641 -1.1620077 1.5448773 ]
[ 0.19638498 0.202947 -0.6173979 -1.2912503 ]
[ 0.99586684 1.4563453 -0.41481683 1.0888891 ]
[-1.0562949 0.13072447 -0.5525385 -0.7610103 ]
[ 1.1514093 -1.2749614 -0.39080948 -0.02632377]
[ 0.13824102 -1.4999267 -1.3311701 -0.17354102]]
[ True False True False False False]
[[ 1.2061282 -0.16772641 -1.1620077 1.5448773 ]
[ 0.99586684 1.4563453 -0.41481683 1.0888891 ]]
我们先看看name == ‘C’的结果
[ True False True False False False]
然后把name = ‘C’的结果带入到data的索引框中
输出第0行,和第2行的数据。(只输出true的数据,而没有输出false的数据,这就是布尔型索引)
[[ 1.2061282 -0.16772641 -1.1620077 1.5448773 ]
[ 0.99586684 1.4563453 -0.41481683 1.0888891 ]]
就像运用 if 语句,True了就输出,False就不输出,那对应 if 语句的 and 和 or 是 & 和 | (Python关键字and和or在布尔型数组中无效。要使用&与|。)
值得注意的:通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的 数组也是如此。
花式索引
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索 引。
重点是整数数组。
例子:
import numpy as np
data = np.array([['a', 'b', 'c', 'd'],
['e', 'f', 'g', 'h'],
['i', 'j', 'k', 'l']])
print(data[[0, 1]])
[['a' 'b' 'c' 'd']
['e' 'f' 'g' 'h']]
data[ [0, 1] ]输出第0行,和第一行的数据
与 data[:2] 打印的结果是一样的(两者最大的区别是框框,[:2]只能输出[0,2)区间的数据,万一我想输出的数据不是连续,就只能用花式索引,明确指出我要访问那里),当然如果加上列的限制也一样。
data[ [0, 1], [0, 1]]:输出第0行第0列数据以及第1行第一列数据。[‘a’, ‘f’]
花式索引的书写顺序会影响到输出的顺序:
data[[1, 0], [1, 0]]:输出[‘f’, ‘a’]
nadarry的转置和轴对换。
线性代数中的操作对应numpy中的操作:
假设矩阵名:arr
矩阵的转置 ----> arr.T
矩阵的点乘 -----> arr.dot( 点乘的另一个矩阵 ) (不是之前的乘法)
通用函数:对数组的元素进行挨个进行运算
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将
其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包 装器。
摘取至《利用python进行数据分析》
一元函数(接受一个矩阵)


二元函数

条件逻辑表述数组运算
我们经常会碰到 条件逻辑:即 如果符合条件 则取a值,否则取b值。
if arr >0:
x = a
else:
x = b
如果想在数组中运用这个关系式,大可不必用for循环,直接调用np.where(arr>0, a, b)
参数1:即判断条件
参数2:当条件为真,赋的值
参数3:当条件为假,赋的值
数学和统计方法:
回想起我们计算数组的总和或者平均数,肯定会调用到for循环,当使用矩阵的时候,调用numpy提供的API便可以高效解决这类问题。


使用arr.sum函数的例子:
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# axis = 0 指明按照列运算
answer = data.sum(axis=0)
print(answer)
answer:
[12 15 18]
# 即第一列中所有值相加,第二列所有值相加,第三列所有值相加
# 若干axis = 1 则将列换为行
# 如果没有指明axis 则是矩阵所有元素之和
如果当前数组为布尔数组,可以使用两个函数any,all函数,进行检查:
any:测试数组中是否含有一个or多个True
all:检测数组中所有值是否都为True(非布尔也可用,非0元素将认为True)
数组排序
numpy也可以调用sort函数,当然也可以输入轴,0代表按列从小到大排序(最上面最小),1代表按行排序(最右最小)
值得注意的:排序是原地排序,会修改原数组,并且不会有返回值
数组唯一化以及其他集合逻辑

uninque(x) 函数 例子:
import numpy as np
data = np.array(['a', 'b', 'a', 'a', 'c'])
answer = np.unique(data)
print(answer)
# 结果:如果数组中有重复的元素则去除,并返回有序数组
['a' 'b' 'c']
数组的文件输入以及输出
numpy能够读取磁盘中的文本数据or二进制数据,不过一般使用pandas或者其他工具加载文本or
表格。
主要是np.save与np.load
arr = np.arange(10)
# 存储数据,扩展名为npy,如果没有加会自动加载
np.save('data', arr)
# 加载数据
np.load('data.npy')
# 可以将多个数组加载进同一个文件(npz扩展名)
np.savez('文件名.npz', a = arr_1, b = arr_2)
# 加载npz文件时,会的到一个类似字典的对象
arch = np.load('array_archive.npz')
arch['b']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 数据可以进行压缩
np.savez_compressed('文件名.npz', a=arr_1, b=arr_2)
numpy中的矩阵运算

以 trace 函数为例子:(其余函数在ide中寻找原型的用法)
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
answer = data.trace()
print(answer)
#结果
15
伪随机数生成
修改种子(全局种子):
np.random.seed( 你想输入的数字 )
我们说这些都是伪随机数,是因为它们都是通过算法基于随机数生成器种子,在确 定性的条件下生成的。如果想采用局部种子,使用numpy.random.RandomState,创建一个与其它隔离的随机数生成器:
rng = np.random.RandomState(1234)
rng.randn(10)
np.random.normal(size=(4,4))
生成一个4x4的数组,其中的值符合标准正态分布


广播
只要遵循一定的规则,低维度的值是可以被广播到数组的任意维度的
摘取至《利用python进行数据 第二版》
import numpy as np
data_0 = np.array([[1, 2, 3]])
data_1 = np.array([1, 2, 3])
print("data_0 shape:", data_0.shape)
print("data_1 shape:", data_1.shape)
# 结果
data_0 shape: (1, 3)
data_1 shape: (3,)
这里肯定会有不少问号。[[1, 2, 3]] (简称数组A)与[1, 2, 3](简称数组B)的区别是什么?
A是一个二维数组,仅仅是总行数为1而已。所以(1, 3)表示一行,三列。
B是一个一维数组,没有行列这种概念,(3,)表示这是个一维数组,长度为3。
A与B根本不是同一个事物。
距平化处理:数组中的值 - 列平均值
data_0 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
mean = data_0.mean(0)
data_0 = data_0 - mean
print(mean)
print(data_0)
# 结果
[4. 5. 6.]
[[-3. -3. -3.]
[ 0. 0. 0.]
[ 3. 3. 3.]]
乍一看没有问题,但你细品,mean是一个一维数组,而data_0是一个二维3x3数组,照理来讲,二维数组3x3,只能跟对应的二维数组3x3做减法,可是这里mean竟然能直接做减法。这就是广播的力量。将一维数组mean进行扩充变成一个二维数组3x3
[[ 4. 5. 6.]
[ 4. 5. 6.]
[ 4. 5. 6.]]
然后在对原来的二维数组进行减法运算。广播一般而言,是低维度广播到高维度,而且要遵循一定的方法。不然,很容易黑人问号。
