用Python把B站视频弹幕爬下来,绘制词云图看看大家最关心什么!
今天带大家做点好玩的,把B站热门视频弹幕爬下来制作词云图!
康康大家都怎么说!

开始之前先给大家啰嗦几句,可能有些兄弟不会安装模块,我大概讲一下。
如何安装模块:
- win(键盘左下角ctrl 和 Alt 中间那个键) + R 输入 cmd 输入安装命令: pip install 模块名 回车
- pycharm里面安装 terminal 输入安装命令: pip install 模块名 回车
如果模块安装失败了,可能是这些问题:
- 提示:pip 不是内部命令
你python环境变量可能没有设置好 - 有安装进度条显示,但是安装到一半出现报错了
因为python安装模块都是在国外的网址进行下载安装的, 国内请求国外 网速很慢,下载速度大概只有 几KB
read time out 网络连接超时 你可以切换为国内的镜像源 - 明明在cmd里面安装好了,但是在pycharm 提示我没有这个模块
你pycharm里面python解释器没有设置,你在pycharm设置里面重新设置一下 - 可能安装了多个python版本
安装一个版本即可
Python做爬虫到底可以做些什么呢?
常规: 爬取网上的数据 / 我可以批量下载图片/文字/音频 视频…
12306抢票 / 京东商城电商网站抢购脚本 / 朋友圈刷票 / 一些问卷调查自动填写… / 文章刷阅读量 / 音频 视频 播放量
可以刷课 可以刷网课 自动 还能自动批量注册账号
模拟点击 >>> 游戏辅助 >>> 修改游戏内存(单机) …
普通B站视频可以爬 番剧是需要会员的
爬虫都是通过开发者工具进行抓包分析 查询数据来源 ( 静态页面 / 动态页面 ajax异步加载)
1. 确定目标需求 (弹幕数据 那个视频弹幕)
确定了
2. 找数据 (数据的来源分析)
简简单单 找到了
3. 对于数据来源的url地址 发送请求 (请求方式 / 请求头)
请求方式: get / post
请求头:
https://api.bilibili.com/x/v1/dm/list.so?oid=376200196
(通过开发者工具去看一下数据的具体来源,是否是来自有这个网站)
4. 获取数据
文本数据 response.text 获取网页源代码
json字典数据 response.json() 通常一般情况是 动态网页 ajax异步加载 用的比较多
二进制数据 response.content 保存图片 音频 视频 或者 特定格式文件
5. 解析数据
正则表达式 .*? 解决一切 遇事不决 .*? 通配符 可以匹配任意字符
6. 保存数据
python除了做爬虫数据采集,还可以做什么?
兴趣学习 还是 通过python技术赚钱 (就业找工作 / 外包)
-
网站开发(就业/外包) >>> 我们课程是教授的全栈开发 薪资 13K-15K
比如: python开发网站: Youtobe / 豆瓣 / 知乎(以前版本) / Facebook / 美团 ;
我可以做到这样么?
0基础 初学者 从零开始学习,上线 通过 域名 服务器 数据交互,4个左右的时间 就可以独立开发这个项目 类似知乎的网站;
如果你做去外包(团队): python开发就业 大多数也是进入外包公司 一个 10-20K左右; -
爬虫开发(脚本)(就业/外包) 可见即可爬
虽然爬虫什么都可以爬,但是获取用户的个人隐私(信息 电话 身份 贩卖 )、国家信息、商业机密(未公开数据,或侵犯版权)、色情等违法信息用来盈利,就基本上人无了!
很多兄弟问我,可以帮我淘宝用户数据吗? 我都是告诉他们,这个我还想多活几年,这玩意涉及隐私,个人信息,你可以自己学了悄悄爬,爬完记得删了,用来实践问题不大,但是别用来盈利!!!
之前有个兄弟爬取微博上面军事武器航母图片买给国外, 然后就进去了!所以奉劝大家,切记切记,别乱来! -
数据分析(就业/外包)
-
自动化(脚本)
-
游戏开发/辅助(脚本)
-
人工智能(研究生以上学历 要求很高)
等等方向还有很多,我就不一 一述说了,那些方向对于一般人来说作用不大。
我们开始正题吧
爬虫部分:
发送请求 第三方模块 需要pip install requests
import requests
import re # 内置模块
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=376200196'
请求头的作用就是伪装
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
模拟浏览器对服务器发送请求, 服务器接收到请求之后,确定你没问题 然后会给你返回 response响应体数据
函数传参
response = requests.get(url=url, headers=headers)
<> 对象 对象意味着你可以调用里面的方法或者属性
200 状态码 请求成功
获取数据 文本数据
自动识别编码
response.encoding = response.apparent_encoding
html_data = re.findall('(.*?) ', response.text)
content_str = ‘\n’.join(html_data)
- 要列表转成字符串 ‘’.join()
- for 遍历
- 保存数据 保存字符串
for content in html_data:
# mode 保存方式 w 写入会覆盖 a 追加写入
with open('弹幕1.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
# print(content_str)
爬取结果
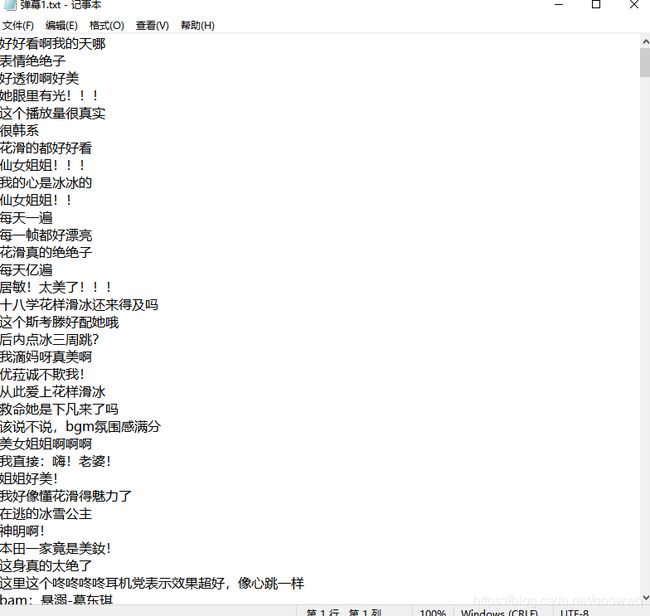
然后我们再来实现制作词云图部分
首先要安装这两个模块
import jieba
import wordcloud
一个相对路径 一个绝对路径,保存好的txt文本名字要注意看一下,不对的话,记得改一下保持一致。
f = open('弹幕.txt', mode='r', encoding='utf-8')
text = f.read()
txt_list = jieba.lcut(text)
# print(txt_list)
列表整合成一个字符串
string = ' '.join(txt_list)
print(string)
print('---'*50)
print(str(txt_list))
词云图设置
wc = wordcloud.WordCloud(
width=1000, # 图片的宽
height=700, # 图片的高
background_color='white', # 图片背景颜色
font_path='msyh.ttc', # 词云字体
# mask=py, # 所使用的词云图片
scale=15,
# stopwords={words}, # 停用词
# contour_width=5,
# contour_color='red' # 轮廓颜色
)
给词云输入文字
wc.generate(string)
词云图保存图片地址
wc.to_file('output1.png')
词云图的过程中有点慢,大家不要心急

这是最后的结果

没有加停用词,所以一些无用的词比较多
stopwords={'了', '啊'}
把这个部分的代码加入要屏蔽的词就OK了!比如我现在把 了 跟 啊 这两个字屏蔽了。
我们再来看下

不知名网友:666666 牛批 老哥我要学!!!

想学的话,这个是有教程的,和代码我已经打包了,直接在这个群可以找管理员免费领取 点我加群领取
小编创作不易,复制文章请带上原文链接!!!