基于yolov5的目标检测和模型训练(Miniconda3+PyTorch+Pycharm+实战项目——装甲板识别)
目录
一、环境配置和源码获取
1.Miniconda
2.MIniconda虚拟环境配置PyTorch
3.yolov5项目源码
4.pycharm
二、目标检测
三、模型训练
1.数据集
1.images
2.labels
2.yaml文件
3.预训练权重模型文件
4.train.py
1.本地训练
2.云端gpu训练
五、YOLOV5实战——装甲板识别
1.前言
2.制作数据集
3.新建yaml文件
3.开始训练模型
4.装甲板识别
一、环境配置和源码获取
1.Miniconda
首先使用MIniconda新建一个环境,使用Anaconda也可以,但推荐使用Miniconda,MIniconda更加轻便,只有必要的依赖项,没有冗余的库包。
MIniconda官网:Miniconda — Conda documentation
Miniconda清华镜像:Index of /anaconda/miniconda/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
推荐使用清华镜像源下载
进入清华开源镜像站后,根据自己的系统平台选择下载版本,最好选择MIniconda3下载
下载好的conda会自带一个版本的python,这里推荐选择3.6~3.8的python,这里下载的是py39

下载后打开安装程序 ,选择Next ==> I Agree ==> Next



选择好安装路径,这里是安装在E盘,Next
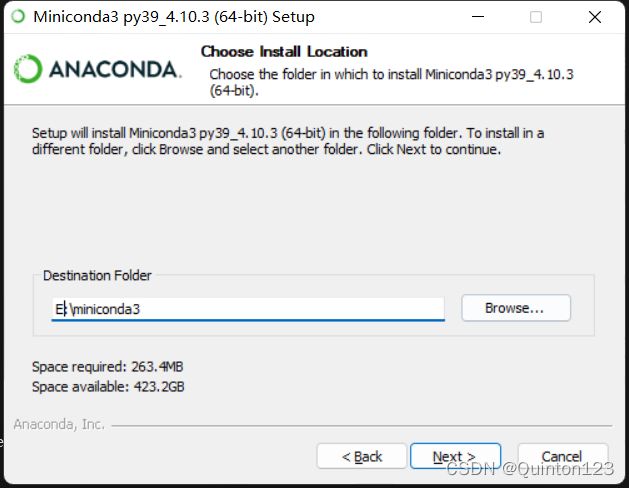
一定要记得加入环境变量, 然后选择install

安装完毕

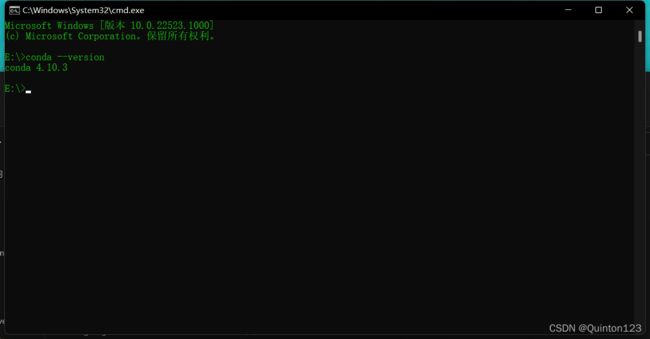
在安装conda的盘符下打开cmd
使用 conda --version 命令查看conda版本并验证conda是否安装成功
验证安装成功后,使用此命名指定python版本新建环境
yolo是创建的环境名称(名称可以自己定,不一定像我一样用yolo)
python=则是指定python版本,可以按下载Miniconda时的python版本指定
conda create -n yolo python=3.9 开始创建新的虚拟环境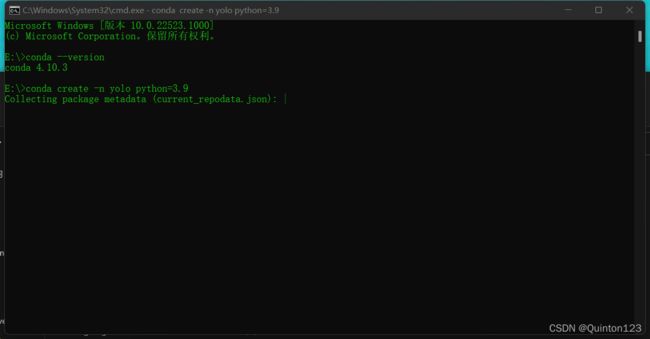
输入y,然后回车
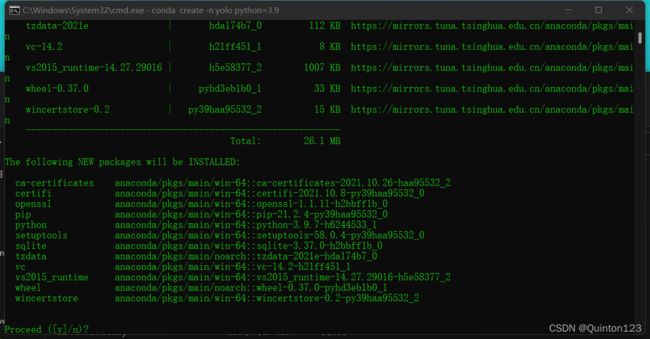
创建虚拟环境完成
激活进入虚拟环境
conda activate yolo

2.MIniconda虚拟环境配置PyTorch
PyTorch官网:PyTorch https://pytorch.org/进入官网,选择install进入下一页面
https://pytorch.org/进入官网,选择install进入下一页面

注意红框内容


PyTorch Build:按默认选择Stable
Yours OS:根据自己系统平台进行选择,我这里选择的是windows
Package:因为是安装在conda虚拟环境下,所以选择conda
Language:下载的官方源码包是python版本,所以选择python
Compute Platform:最为重要!!不要选错!!
(1)首先确定自己的电脑有没有gpu,如果没有gpu,则选择CPU;如果在有gpu的情况下选择了CPU,后续会导致无法调用gpu进行加速。
查看自己电脑是否有gpu可以参考这篇csdn博文:(44条消息) 查看自己电脑是否有GPU_simple_code-CSDN博客_怎么看电脑有没有gpu
还有一种情况,非英伟达显卡,也是选择CPU
查看是否有英伟达显卡:计算机右击–>管理–>设备管理器–>显示适配器
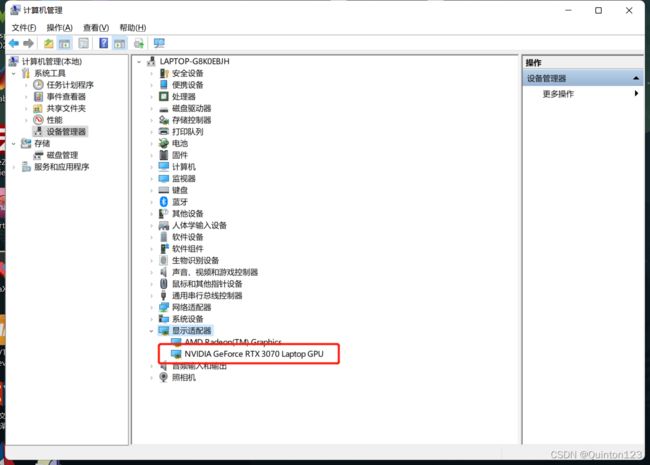
当然在这里也可以查看是否有gpu
非英伟达显卡可以参考这篇博文:(44条消息) 一、Win10+非英伟达显卡+Anaconda+Pytorch安装_zcsdn1996的博客-CSDN博客
(2)确定自己电脑有英伟达显卡后
右键桌面->NVIDIA控制面板->系统信息->组件


在这里就可以查看到CUDA版本
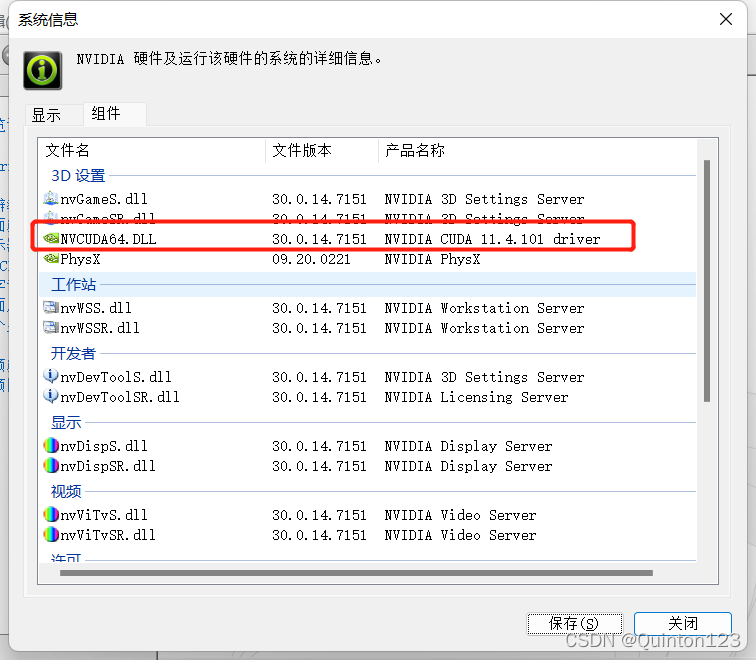
选择Compute Platform时要注意CUDA版本要低于自己电脑的CUDA驱动版本,理论上CUDA版本越高,速度越快
历史版本PyTorch框架安装:
Previous PyTorch Versions | PyTorch
这里可以找到更低版本cuda支持,pip安装注意也要在conda虚拟环境中执行
Run this Command:进入conda虚拟环境后将此命令复制,然后回车执行
在安装Miniconda的盘符下进入cmd
然后使用此命令激活进入conda虚拟环境
将安装PyTorch的命令复制粘贴,然后回车
输入y,回车
开始安装pytorch,会有一点大,稍微等一下,添加国内源会更快一些
添加国内源可以参考这篇博文:(44条消息) conda安装虚拟Python环境及添加国内源_luckyy86的博客-CSDN博客
如果中途卡住可以退出重新进入再执行一次命令

pytorch框架安装完成
3.yolov5项目源码
下载yolov5项目源码
github下载:
ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite (github.com)
百度云盘:
链接:https://pan.baidu.com/s/15Tw8p4HMn2WKbZEIwjWdOg
提取码:ac47
下载后解压,在后面的步骤中会使用pycharm打开
4.pycharm
下载pycharm
官网网址:PyCharm: the Python IDE for Professional Developers by JetBrains

下载社区版,免费的够用了,注意根据自己的系统平台选好版本
下载后安装即可
具体可以参照这篇csdn博文的步骤一:
(44条消息) PyCharm2021安装教程_学习H的博客-CSDN博客_pycharm2021安装教程
pycharm安装完成后,使用pycharm打开已经下载好的yolov5项目源码
打开项目源码后便是这样的(我的pychram主题跟随系统为暗色,如果打开为浅色主题不必在意
点击右上角的设置
左键setting后打开设置页面
Project->Python Interpreter
点击右边的设置按钮

点击Add

进入Add Python Interpreter页面
选择添加Conda Environment,点选添加已存在的环境Existing environment
然后选择我们使用Miniconda已经创建好并且安装了pytorch框架的环境

点击OK后回到这个页面
apply->ok
这样就把Conda虚拟环境加载到yolov5项目上了

回到主界面,打开detect.py
会发现有一个报错,这里报错的是
import cv2说明conda虚拟环境中没有安装opencv库
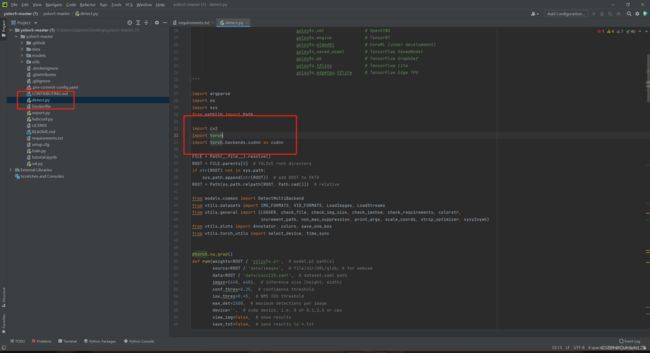
接下来在cmd中进入conda虚拟环境
推荐使用两种安装方式:
pip安装和conda安装
(1)conda安装
进入conda的官网:Search :: Anaconda.org
搜索opencv
在上方筛选器选择好系统平台

点击py-opencv,进入到这个页面
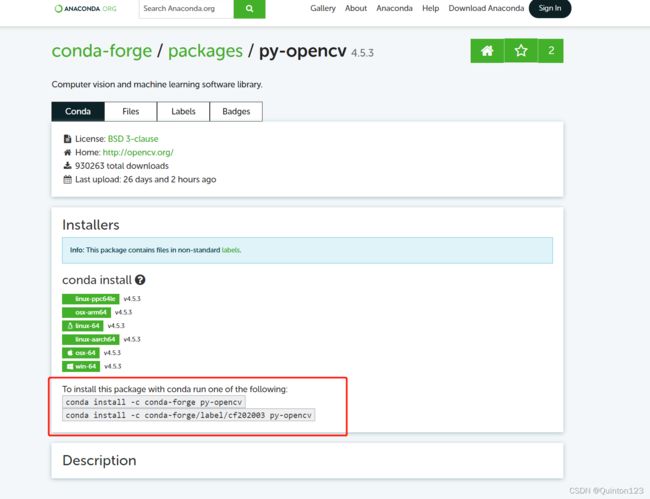
可以看到下发的两条conda安装命令
conda install -c conda-forge py-opencv
conda install -c conda-forge/label/cf202003 py-opencv任选一条命令复制到cmd,回车
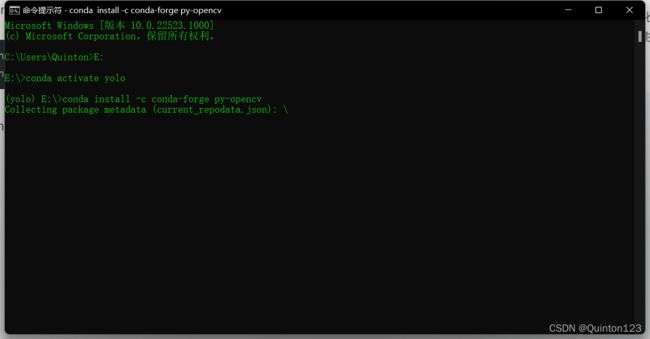
如果出现这行WARNING,不用在意,这里只是提醒更新conda
输入y,回车

opencv库安装中

安装完毕
(2)pip安装
进入这个网址:Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
ctrl+F搜索opencv,定位到opencv,根据自己的系统版本选择好对应的下载命令

在cmd打开conda中对应的虚拟环境
输入pip install,然后将对应的下载命令复制粘贴在后面,回车
例如:
pip install opencv_python‑4.5.5‑pp38‑pypy38_pp73‑win_amd64.whl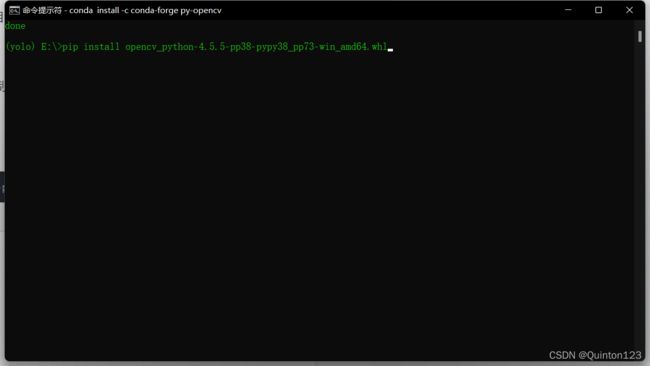
后面的操作和conda安装类似
opencv库安装成功后,回到pycharm,打开detect.py
会发现没有报错了

最为重要的pytorch和opencv已经安装完成,pycharm在一般情况下还会提醒安装一些未安装的其它依赖项,点击install requirments

默认勾选全部,点击install
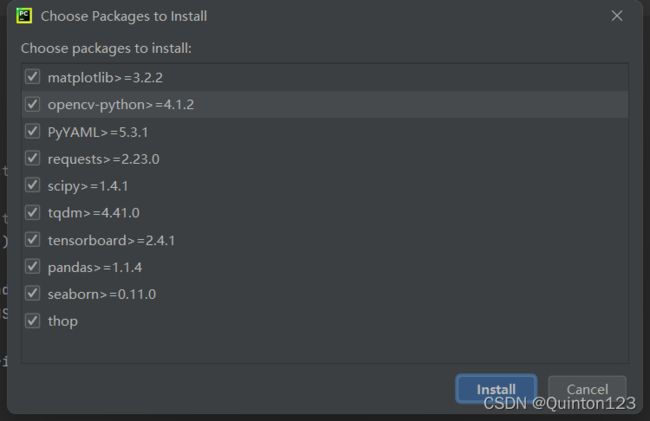
这样就会开始安装未安装的依赖项,耐心等待安装完成

一般会发现这两个安装失败,opencv在前面的步骤已经安装过了,thop对yolov5源码运行没有太大影响,不必在意
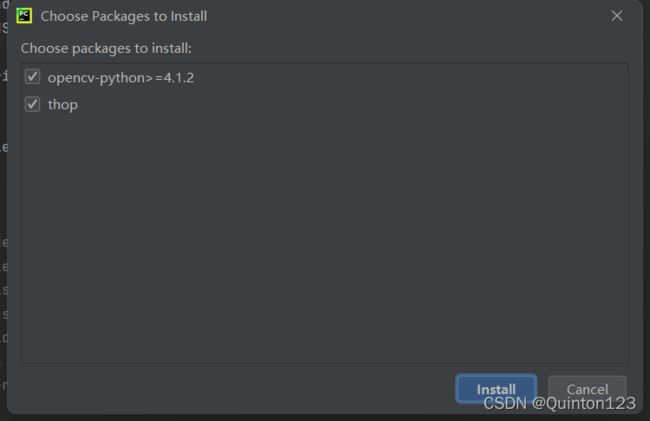
至此,环境配置已经全部完成
运行detect.py
红框1可以查看是否启用了gpu加速
红框2可以查看结果图片存储的位置
出现这样的结果说明环境搭建成功
在runs文件夹中可以找到运行yolov5的结果图
二、目标检测
目标检测用到的是yolov5项目中的detect.py
在前面部署环境时已经尝试运行过detect.py验证是否部署成功
打开detect.py
往下翻,直到第267行
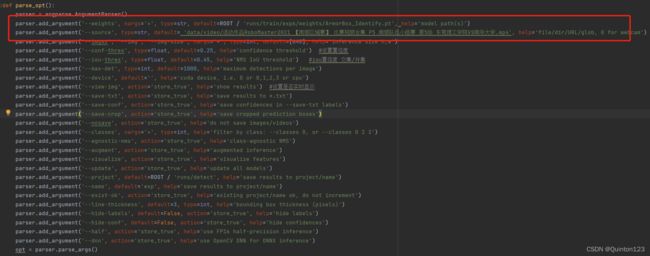
这里便是一些重要参数的设定
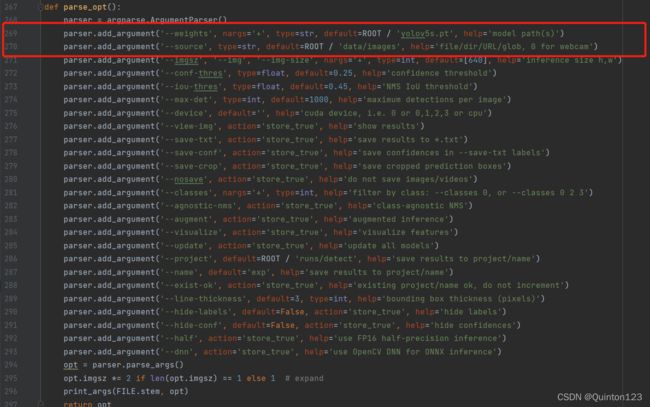
重点关注第269行以及第270行
269行:
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')更改的default后面的文件名(最好带有路径),设定目标检测的模型文件
同级文件夹下可以不带有路径,低一级文件夹需要带有上一级文件夹路径,绝对路径一般都可以使用
在pycharm中寻找到目标文件,右击->Copy Path/Reference...->Path From Content Root
这里所复制到的路径一般直接可用(图片中随便找了一个文件作为示范)
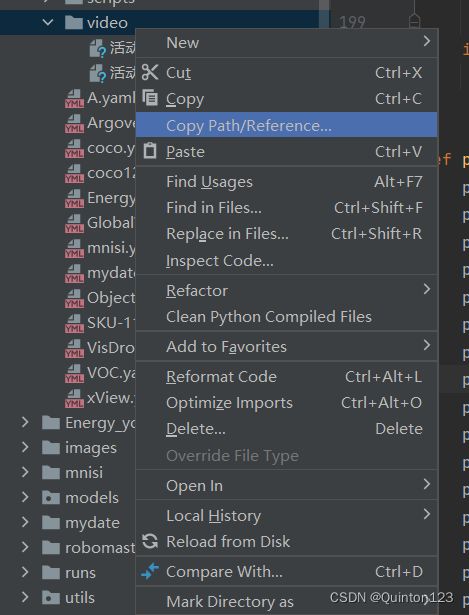

例如:
在yolov5项目中新建一个文件夹weights存储自己训练的模型文件,然后将此模型文件用于目标检测
可以把269行更改为
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'weights/yolov5s.pt', help='model path(s)')yolov5项目文件中会默认自带一个yolov5s.pt权重模型文件,同时这也是在模型训练中使用到的预训练模型文件
可以选择不手动下载,因为调用时也是会自动下载

但推荐下载好了保存起来,提高运行效率
其它yolo预训练模型文件的下载:
github:Releases · ultralytics/yolov5 (github.com)
往下翻找到Assets,点击下载就可以了,因为使用pytorch框架,所以下载时要选择后缀名为pt的文件
下载后建议在yolov5文件夹下新建一个weights文件夹,用于储存下载好的pt文件,便于后面调用

github下载过慢,已上传百度云盘
百度云盘:
链接:https://pan.baidu.com/s/1Xb_mdUWZSKjxr5R3iTMhoQ
提取码:cmtn
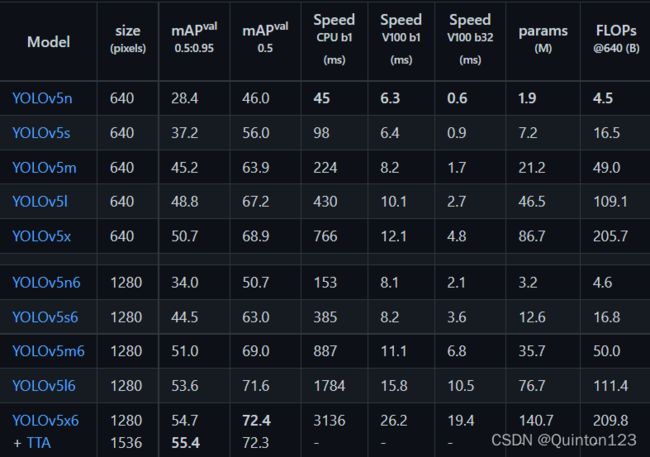
由此表可知各权重模型文件的区别,排序为n、s、m、l、x,速度越慢,准确率越高
270行:
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')更改的default后面的文件名(最好带有路径),设定进行目标检测的图片或者视频
同级文件夹下可以不带有路径,低一级文件夹需要带有上一级文件夹路径,绝对路径一般都可以使用
例如:
在yolov5项目中新建一个文件夹videos存储自己的视频文件,然后对此视频文件进行目标检测
可以把270行更改为
parser.add_argument('--source', type=str, default=ROOT / 'videos/myvideo1.mp4', help='file/dir/URL/glob, 0 for webcam')更改好这两行的参数,就可以使用自己训练的模型对图片或者视频进行目标检测
官方给的yolov5模型文件是基于coco数据集训练的模型
coco数据集的介绍可以参考这篇博文:(45条消息) Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略_一个处女座的程序猿-CSDN博客_coco数据集
可以找一个街道的视频作为例子 ,使用Annie工具在b站等视频网站下载好街道相关的视频
Annie工具的安装和使用可以参考这篇博文:(45条消息) Github 上 annie 下载神器的安装及使用教程_景墨轩-CSDN博客_annie github
下载好视频后,将视频放在合适的文件夹里
在第269行和第270行更改好使用的模型文件以及视频文件
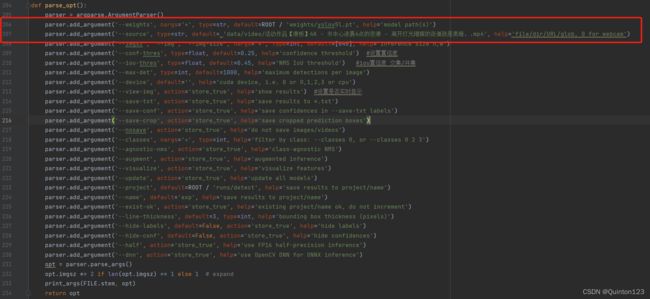
运行detect.py
正在对视频进行目标检测

运行结束后,目标检测的结果视频或者图片会存储在runs->detect->exp
每运行一次得出一个结果,exp就会增加一个,并自动编号

打开视频就能看到目标检测的结果
那么如何显示这样的实时推理呢?
感谢b站up主Wet_Sand的视频~(撒花)
这就用到了第276行的代码
276行:
parser.add_argument('--view-img', action='store_true', help='show results')左键点击右上角的detect
点击Edit Configuratiopns...
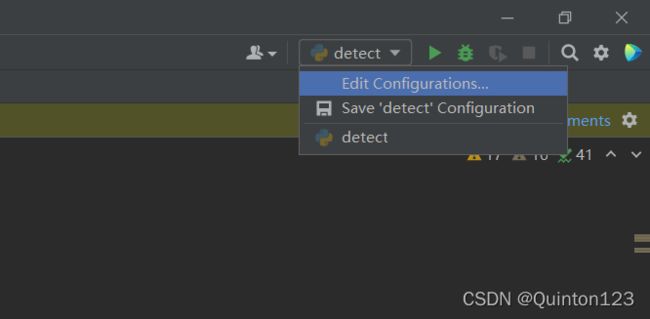
进入到Run/Debug Configuration
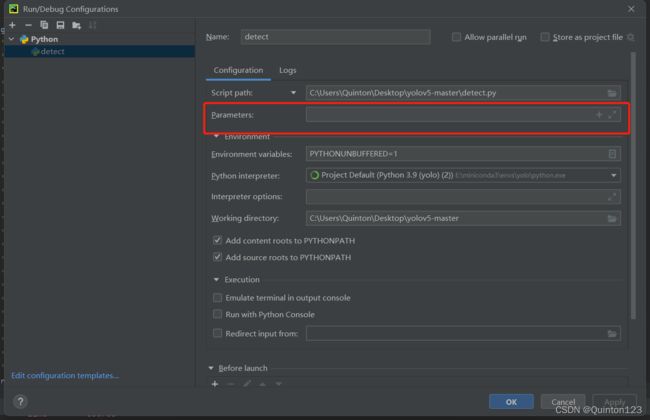
将
--view-img
输入到parameters中

Apply->OK
再次运行就可以显示实时推理啦
三、模型训练
1.数据集
后面步骤例子使用的是coco128,无需自己准备,可以先跳过第一点,实战部分再看第一点
训练模型最重要的是准备用以训练模型的数据集
数据集一般包括图片集images和标注集labels
图片集和标记集中也会有训练集train和测试集test
这里我将数据集命名为mydate
当然也可以下载开源的满足要求的数据集使用

1.images
制作images的图片尽量含有需要进行目标检测的物体
图片可以来源于网上开源、视频截图、或者是自己拍摄等等
如果是通过视频获取图片
可以使用opencv库将视频的每一帧导出
这里提供c++的参考代码
#include
#include
#include
using namespace cv;
using namespace std;
int main()
{
Mat frame;
VideoCapture capture("../data/0105.avi");
namedWindow("target",CV_WINDOW_NORMAL);
char img[200];
int i=0;
while(1)
{
capture>>frame;
if(frame.empty())
break;
imshow("target",frame);
char key=waitKey(20);
if(key == 'q')
{
break;
}
sprintf(img,"%s%.6d%s","../data/images/",++i,".jpg");
imwrite(img,frame);
}
frame.release();
return 0;
} 获取到图片后
将图片放在images下的train
并且对图片的文件名进行有序编号和格式统一化(重要)
在pycharm中打开的效果

可以使用ReNamer工具对图片进行批量重命名
ReNamer的下载:
网址:ReNamer « Products « den4b.com
百度云盘:
链接:https://pan.baidu.com/s/1dGRJiWZxZ5TqTN7USxITbw
提取码:ir2a
具体使用可以参考这篇博文:
(44条消息) 非常实用方便快捷的批量重命名软件——ReNamer Lite_小武的博客-CSDN博客
文件格式的更改可以使用格式工厂
关于格式工厂可以参考这篇博文:(44条消息) 格式工厂——难得一见的强大免费格式转换工具_boyinthesun的博客-CSDN博客_格式工厂在线转换
2.labels
数据集的另一重要组成部分标注集labels
在拥有图像集后需要对图像进行标注
最基础的数据标注是图片框。比如检测目标是一辆车,报幕员需要在一张图片上标注所有的车,并且图片框必须完全覆盖车的外矩形。如果框架不准确,机器可能会“学坏”。
数据标注是什么可以参考这篇博文:什么是数据标注?_进阶女学霸-CSDN博客_数据标注
数据标注完成后需要把标注文件放在mydate->labels->train中
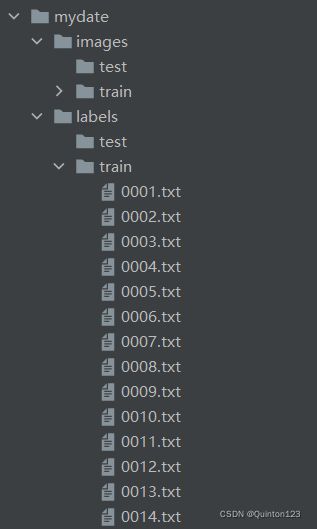
进行图像数据标注需要使用图像标注工具
图像标注工具汇总参考这篇博文:(44条消息) 深度学习图像标注工具汇总_zhangxu-CSDN博客_图像标注工具
这里主要推荐两款图像标注工具
MakeSense 和 labellmg
MakeSense:
MakeSense是网页端的图像标注工具:Make Sense
上手难度极低
具体使用可以参考这篇博文:
(44条消息) make-sense | 图像标注工具_To_ChaRiver的博客-CSDN博客
labellmg:
labellmg是本地安装使用的图像标注工具
GitHub下载链接:tzutalin/labelImg: ️ LabelImg is a graphical image annotation tool and label object bounding boxes in images (github.com)
百度云盘:链接:https://pan.baidu.com/s/1qaDSiLYPTUfEtxKQloDCxA 提取码:n34s
下载后进行解压
进入到这个路径 labelImg-master\data\predefined_classes.txt

将predefined_classes.txt删除
防止添加了奇怪的标注类别
在 labelImg-master下打开cmd
上边栏输入cmd,然后回车

进入conda虚拟环境

首先安装labelImg所需要的运行依赖
执行此条命令安装pyqt=5
conda install pyqt=5
安装完毕,提醒更新conda,无需理会
接下来执行这行命令
conda install -c anaconda lxml
输入y,回车
安装完毕
执行最后一条命令
pyrcc5 -o libs/resources.py resources.qrc
依赖安装完毕,执行下面这行命令打开labelImg执行后成功启动labelImg
python labelimg.py
执行后成功启动labelImg
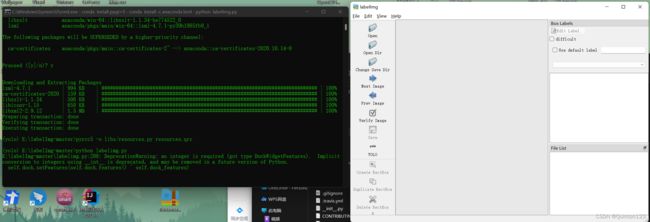
如果找到labelImg中的labelImg.py文件
选择用Python打开
比较容易崩溃或者直接启动失败
因为labelImg的依赖文件安装在conda虚拟环境中,所以最好使用cmd进入到conda虚拟环境后使用命令行打开


Open Dir打开已经制作好的图像集
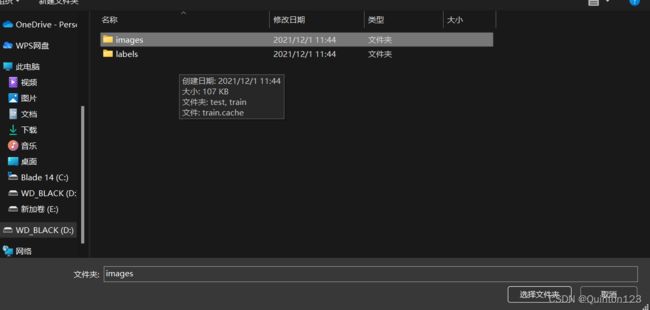
选择好保存标注文件的文件夹labels->train

使用快捷键进行标注
w:创建一个矩形
a:上一张图片
d:下一张图片

标注完成后可以在labels—>train中找到标注文件
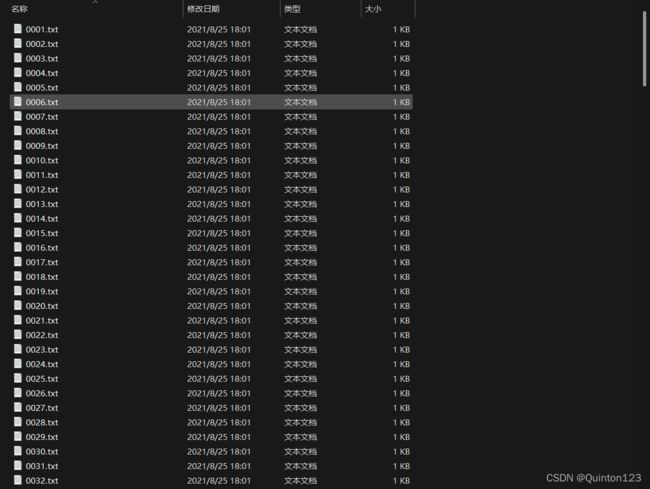
标注文件依靠文件名与图像集中的图片一一对应,所以文件名的有序非常重要,方便查错
至此,数据集制作完毕
2.yaml文件
yaml文件是进行模型训练的依据
里面包含了数据集、验证集、测试集、类别和类别名称的信息
以项目源码中带有的coco128.yaml作为例子
可以在date->scripts中找到
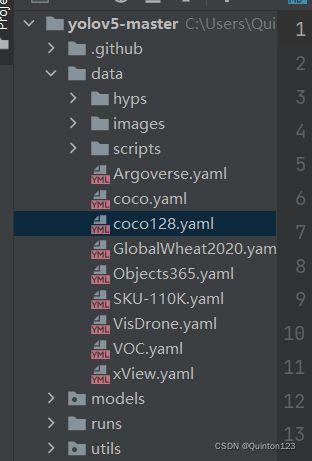
文件打开是这样的
实战中具体用到的是红框中的参数变量
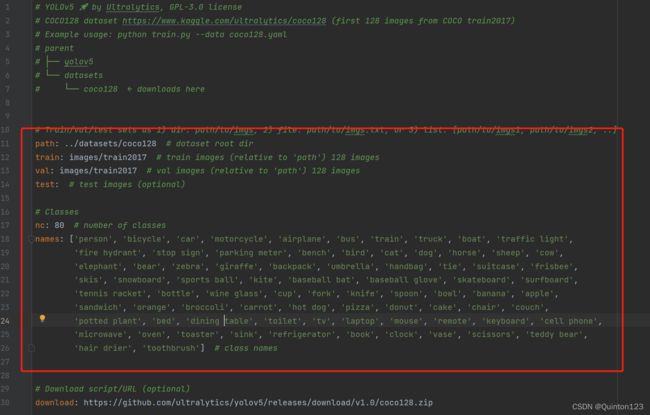
附上注释进行具体说明
# YOLOv5 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017)
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here
#======================================以上内容是对coco128使用的一些说明,不必理会============================================
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # 设定coco128的路径,实战使用中不需要path
train: images/train2017 # 数据集中的训练集路径
val: images/train2017 # 验证集路径,可以与训练集路径相同
test: # 测试集路径,实战中可以不设定
# Classes
nc: 80 # 设定的类别个数
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # 类别名称
# Download script/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip # 如果没有coco128,会通过此行代码下载注意类别名称会显示在使用该模型进行目标检测的结果上
左边为是目标检测到的类别名称,右边是概率
实战项目中的yaml文件会删除掉冗余代码,在后面的实战部分再详细说明
3.预训练权重模型文件
进行模型训练需要选择一个官方权重模型文件
关于官方权重模型文件的内容在本篇博文的目标检测部分可以找到
最后自己训练出的模型属性会倾向于选择的预训练模型
4.train.py
1.本地训练
本地训练如果电脑没有gpu加速的话速度会很慢,目标检测同理
本博文只涉及到基本使用,关于多个gpu的调用、超参的设定等内容需要通过其它博文获取
推荐这篇博文:(45条消息) YOLOv5代码详解(train.py部分)_Liaojiajia-Blog-CSDN博客_yolov5代码详解
模型训练使用到yolov5项目源码中的train.py
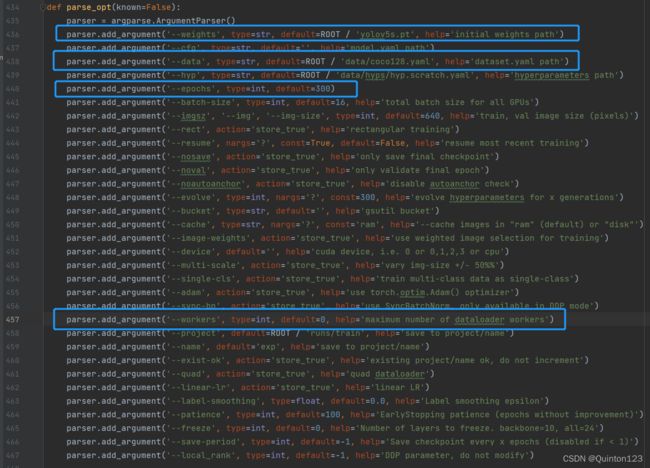
蓝框是其中最基本的四行代码
436行:
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')第436行用于设定用于进行模型训练的预训练模型
同样也是更改default后面的文件名,最好加上路径,使用绝对路径最佳
最后自己训练出的模型属性会倾向于选择的预训练模型
438行:
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')第438行用于设定用于进行模型训练的yaml文件
yaml文件是模型训练的重要依据,通过yaml文件确定数据集的位置以及类别
440行:
parser.add_argument('--epochs', type=int, default=300)在机器学习中
epochs被定义为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。简单说,epochs指的就是训练过程中数据将被“轮”多少次,就这样。
此行代码用于设定epochs次数
epoch 数量增加,神经网络中的权重的更新次数也会增加,曲线从欠拟合变得过拟合。
epochs次数对于不同的数据集,答案是不一样的,数据的多样性会影响合适的 epoch 的数量,这里可以使用默认的300
457行:
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')我的代码中已经把default后面的数字改为0
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')此行代码是用于多线程
如果不为零可能会报错

如果更改为零后仍然报一样的错误
可以参考这篇博文解决:(45条消息) yolov5训练时报错 OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading “D:\Anaconda\envs\..._沉醉于风中的博客-CSDN博客
将457行更改完毕解决可能的报错后,运行train.py
coco128.yaml文件中有下载coco128数据集的语句
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip # 如果没有coco128,会通过此行代码下载如果不存在coco128数据集,会先进行下载

顺利开始模型训练,进行300轮次epochs
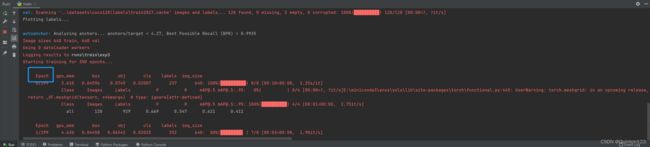
模型训练完成,pt文件存储在runs->trains->
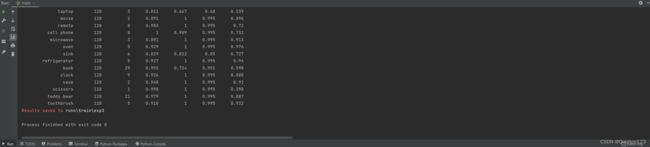
这里的best.pt就是成功训练出的模型文件

在detect.py中将default后的模型文件更改
就可以使用自己训练的模型进行目标检测
例如:
此行代码位于detect.py
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp3/weights/best.pt', help='model path(s)')2.云端gpu训练
如果无法使用gpu加速,可以考虑使用云端gpu训练
可以使用谷歌的colab
首先需要科学上网
colab下yolov5的数据集训练可以参考这篇博文:
(45条消息) Yolov5模型训练——colab下yolov5的数据集训练_Shcheo的博客-CSDN博客
国内的云端gpu可以使用恒源云
不过需要付费使用,但费用并不是很贵
恒源云官网:恒源云_GPUSHARE-恒源智享云
可以使用pycharm远程连接到云服务器,然后让代码在云服务上跑
具体参考这篇博文:(45条消息) 深度学习训练 | PyCharm远程连接免费云GPU服务器教程_AI酱油君的博客-CSDN博客_pycharm免费gpu
pycharm远程连接服务器需要professional版本
获取professional版本可以参考这篇博文:(45条消息) Pycharm 免费激活专业版(图文详解)_Baimoc-CSDN博客_pycharm专业版激活教程
如果申请不到教育邮箱,csdn上还有其它方法获取professional版本,可以自己查找
五、YOLOV5实战——装甲板识别
1.前言
robomaster比赛中可以使用yolov5进行装甲板识别
本博文就以装甲板识别作为实战开发项目
这里提供已经标注好的装甲板数据集以及训练好的模型文件
提供装甲板数据集是为了减少想要快速掌握yolov5过程中所付出的重复性时间成本,学会使用后还是推荐按前述的方法制作自己的数据集
当然也可以使用我的数据集中的图像集自己标注
装甲板数据集下载:
链接:https://pan.baidu.com/s/1IEqyn7zGiHZVLp8krhvWcg
提取码:8qi8
同时提供一个RM的视觉开源数据站:Yuki Drive (52pika.cn)
提供已经训练好的模型文件是为了可以让自己训练出的模型有一个比较,我训练时yaml文件中的类别名称没有编辑好,使用了数字,所以写了一个txt文件对数字含义进行了说明
模型文件下载:
链接:https://pan.baidu.com/s/1jxWpE7hQ2BdlmgTn90oeVA
提取码:a1qf
2.制作数据集
在yolov5-master下建立这样的层级文件夹
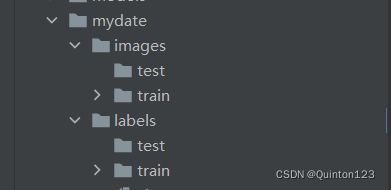
按前述的模型训练部分的制作好数据集
3.新建yaml文件
可以在yolov5-master下新建一个文件夹myyamls,用来储存自己新建的yaml文件
将项目源码自带的coco128.yaml复制进myyamls文件夹

去掉一些冗余的部分,并做出一些修改就可以得到所需要的yaml文件

可以将蓝框中的代码删除
然后将“train:”和“val:”后的路径改为自己数据集的路径
nc就是类别数,按数据集和计划目标实现效果设定
names就是类别的名称,数量要与自己设定的类别数相符,比如设定了12个类别,那么就要有12个类别名
最后得到这样的一个yaml文件
(这里是按照前面给出的数据集命名的类别,其中有两个未发现是因为数据集的标注错误导致的)
train: mydate/images/train # train images (relative to 'path') 128 images
val: mydate/images/train # val images (relative to 'path') 128 images
# Classes
nc: 14 # number of classes
names: ['蓝方哨兵装甲板 blue0','蓝方英雄装甲板 blue1','蓝方工程装甲板 blue2','3 未发现','蓝方四号步兵装甲板 blue4',
'蓝方五号步兵装甲板 blue5','蓝方基地及前哨站装甲板 blue6','红方哨兵装甲板 red0',
'红方英雄装甲板 red1','红方工程装甲板 red2','10 未发现',
'红方四号步兵装甲板 red4 ','红方五号步兵装甲板 red5','红方基地及前哨站装甲板 red6']
# class names最后别忘了给yaml文件重命名

3.开始训练模型
打开train.py
更改好预训练模型文件以及yaml文件
这里的预训练模型文件建议使用yolov5l.pt,兼顾速度和准确率

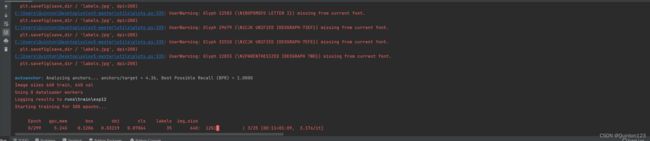
运行train.py
成功开始训练
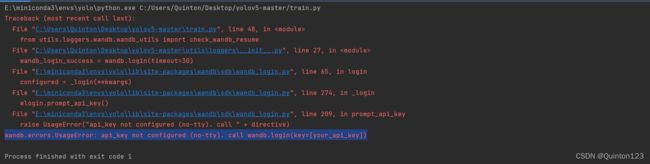
可能出现的报错:
如果出现这样的报错wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api_key])
可以参考这篇博文:(45条消息) wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api_key])_AI浩-CSDN博客
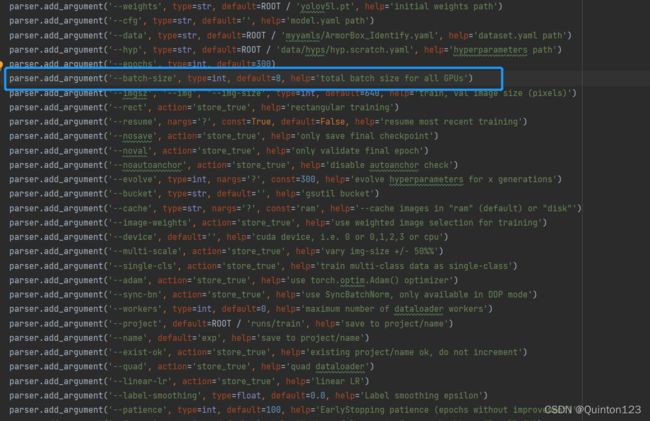
如果出现CUDA out of memory

可以减小batch-size,但是训练速度会下降很多
其它报错可以参考这篇博文解决:(45条消息) yolov5初次使用的踩坑记录_Jancoyan-CSDN博客
4.装甲板识别
打开detect.py
将模型文件更改为自己训练好的
视频文件可以使用annie工具在b站获取
(这里使用了我原来已经训练好的模型文件)
运行

最终效果如下
完结撒花~(累洗我了……orz)
感谢本文引用文章的作者,十分感谢~