从 VLAN 到 IPVLAN: 聊聊虚拟网络设备及其在云原生中的应用
作者:张伟(谢石)
由于这篇文章真的很长,大量的篇幅在讲述内核的实现,如果你对这部分不感兴趣,那么在建议你在看完第一部分的三个问题后,思考一下,然后直接跳转到我们对问题的回答。
提出问题
注:本文所有的代码均为 Linux 内核源代码,版本为 5.16.2
你听说过 VLAN 么?它的全称是 Virtual Local Area Network,用于在以太网中隔离不同的广播域。它诞生的时间很早,1995 年,IEEE 就发表了 802.1Q 标准 [ 1] 定义了在以太网数据帧中 VLAN 的格式,并且沿用至今。如果你知道 VLAN,那么你听说过 MACVlan 和 IPVlan 么?随着容器技术的不断兴起,IPVlan 和 MACVlan 作为 Linux 虚拟网络设备,慢慢走上前台,在 2017 年 Docker Engine 的 1.13.1 的版本 [2 ] 中,就开始引入了 IPVlan 和 MACVlan 作为容器的网络解决方案。
那么你是否也有过以下的疑问呢?
1. VLAN 和 IPVlan,MACVlan 有什么关系呢?为什么名字里都有 VLAN?
2. IPVlan 和 MACVlan 为什么会有各种模式和 flag,比如 VEPA,Private,Passthrough 等等?它们的区别在哪里?
3. IPVlan 和 MACVlan 的优势在哪里?你应该在什么情况下接触到,使用到它们呢?
我也曾有过一样的问题,今天这篇文章,我们就针对上面三个问题一探究竟。
背景知识
以下为一些背景知识,如果你对 Linux 本身很了解,可以跳过。
- 内核对网络设备的抽象
在 Linux 中,我们操作一个网络设备,不外乎使用 ip 命令或者 ifconfig 命令。对于 ip 命令的实现 iproute2 来说,它真正依赖的就是 Linux 提供的 netlink 消息机制,内核会对每一类网络设备(无论是真实的还是虚拟的)抽象出一个专门响应 netlink 消息的结构体,它们都按照 rtnl_link_ops 结构来实现,用于响应对网络设备的创建,销毁和修改。例如比较直观的 Veth 设备:
static struct rtnl_link_ops veth_link_ops = {
.kind = DRV_NAME,
.priv_size = sizeof(struct veth_priv),
.setup = veth_setup,
.validate = veth_validate,
.newlink = veth_newlink,
.dellink = veth_dellink,
.policy = veth_policy,
.maxtype = VETH_INFO_MAX,
.get_link_net = veth_get_link_net,
.get_num_tx_queues = veth_get_num_queues,
.get_num_rx_queues = veth_get_num_queues,
};
对于一个网络设备来说,Linux 的操作和硬件设备的响应本身也需要一套规范,Linux 将其抽象为 net_device_ops 这个结构体,如果你对设备驱动感兴趣,那主要就是和它打交道,依然以 Veth 设备为例:
static const struct net_device_ops veth_netdev_ops = {
.ndo_init = veth_dev_init,
.ndo_open = veth_open,
.ndo_stop = veth_close,
.ndo_start_xmit = veth_xmit,
.ndo_get_stats64 = veth_get_stats64,
.ndo_set_rx_mode = veth_set_multicast_list,
.ndo_set_mac_address = eth_mac_addr,
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = veth_poll_controller,
#endif
.ndo_get_iflink = veth_get_iflink,
.ndo_fix_features = veth_fix_features,
.ndo_set_features = veth_set_features,
.ndo_features_check = passthru_features_check,
.ndo_set_rx_headroom = veth_set_rx_headroom,
.ndo_bpf = veth_xdp,
.ndo_xdp_xmit = veth_ndo_xdp_xmit,
.ndo_get_peer_dev = veth_peer_dev,
};
从上面的定义我们可以看到几个语义很直观的方法:ndo_start_xmit 用于发送数据包,newlink 用于创建一个新的设备。
对于接收数据包,Linux 的收包动作并不是由各个进程自己去完成的,而是由 ksoftirqd 内核线程负责了从驱动接收、网络层(ip,iptables)、传输层(tcp,udp)的处理,最终放到用户进程持有的 Socket 的 recv 缓冲区中,然后由内核 inotify 用户进程处理。对于虚拟设备来说,所有的差异集中于网络层之前,在这里有一个统一的入口,即__netif_receive_skb_core。
- 801.2q 协议对 VLAN 的定义
802.1q 协议中,以太网数据帧包头中用于标记 VLAN 字段是一个 32bit 的域,结构如下:

如上所示,有 16 个 bit 用于标记 Protocol,3 个 bit 用于标记优先级,1 个 bit 用于标记格式,12 个 bit 用于存放 VLAN id,看到这里我想你可以轻易计算出,依靠 VLAN 我们能划分出多少个广播域?没错,正是 2*12,4096 个,减去保留的全 0 和全 1 ,客户划分出 4094 个可用的广播域。(在 OpenFlow 兴起之前,云计算最早期雏形中的 vpc 的实现正是依赖 VLAN 进行网络的区分,但是由于这个限制,很快就被淘汰了,这也催生了另一个你也许似曾相识的名词,VxLAN,尽管两者差别很大,但是仍有借鉴的缘故)。
VLAN 原本和 bridge 一样是一个交换机上的概念,不过 Linux 将它们都进行了软件的实现,Linux 在每个以太网数据帧中使用一个 16bit 的 vlan_proto 字段和 16bit 的 vlan_tci 字段实现 802.1q 协议,同时对于每一个 VLAN,都会虚拟出一个子设备来处理去除 VLAN 之后的报文,没错 VLAN 也有属于自己的子设备,即 VLAN sub-interface,不同的 VLAN 子设备通过一个主设备进行物理上的报文收发,这个概念是否又有点熟悉?没错,这正是 ENI-Trunking 的原理。
深入 VLAN/MACVlan/IPVlan 的内核实现
补充了背景知识后,我们就先从 VLAN 子设备开始,看看 Linux 内核究竟是怎么做的,这里所有的内核代码都以时下较新的 5.16.2 版本为例。
VLAN 子设备
- 设备创建
VLAN 子设备起初并没有被当作一类单独的虚拟设备来处理,毕竟出现的时间很早,代码分布比较乱,不过核心逻辑位于/net/8021q/路径下。从背景中我们可以了解到,netlink 机制中实现了网卡设备创建的入口,对于 VLAN 子设备,它们的 netlink 消息实现的结构体是 vlan_link_ops,而负责创建 VLAN 子设备的是 vlan_newlink 方法,内核初始化代码流程如下:

- 首先创建一个 Linux 通用的 net_device 结构体保存设备的配置信息,进入 vlan_newlink 之后,会进行 vlan_check_real_dev 检查传入的 VLAN id 是否是可用的,这其中会调用到 vlan_find_dev 方法,这个方法用于针对一个主设备查找到符合条件的子设备,后面还会用到,我们截取一部分代码观察一下:
static int vlan_newlink(struct net *src_net, struct net_device *dev,
struct nlattr *tb[], struct nlattr *data[],
struct netlink_ext_ack *extack)
{
struct vlan_dev_priv *vlan = vlan_dev_priv(dev);
struct net_device *real_dev;
unsigned int max_mtu;
__be16 proto;
int err;
/*这里省略掉了用于参数校验的部分*/
// 这里会设置vlan子设备的vlan信息,也就是背景知识中vlan相关的protocol,vlanid,优先级和flag信息的默认值
vlan->vlan_proto = proto;
vlan->vlan_id = nla_get_u16(data[IFLA_VLAN_ID]);
vlan->real_dev = real_dev;
dev->priv_flags |= (real_dev->priv_flags & IFF_XMIT_DST_RELEASE);
vlan->flags = VLAN_FLAG_REORDER_HDR;
err = vlan_check_real_dev(real_dev, vlan->vlan_proto, vlan->vlan_id,
extack);
if (err < 0)
return err;
/*这里会进行mtu的设置*/
err = vlan_changelink(dev, tb, data, extack);
if (!err)
err = register_vlan_dev(dev, extack);
if (err)
vlan_dev_uninit(dev);
return err;
}
-
接下来是通过 vlan_changelink 方法对设备的属性进行设置,如果你有特殊的配置,则会覆盖默认值。
-
最后进入 register_vlan_dev 方法,这个方法就是把前面已经完成好的信息装填到 net_device 结构体,并按照 Linux 的设备管理统一接口注册到内核中。
- 接收报文
从创建过程来看, VLAN 子设备与一般设备的区别就在于它能够被主设备和 VLAN id 通过 vlan_find_dev 的方式找到,这一点很重要。
接下来我们来看报文的接收过程,根据背景知识,物理设备接收到报文后,在进入协议栈处理之前,常规的入口是 __netif_receive_skb_core,我们就从这个入口开始逐渐分析,内核操作流程如下:

根据上方的示意图,我们截取部分__netif_receive_skb_core 进行分析:
-
首先在数据包处理流程开始的时候,会进行 skb_vlan_untag 操作,对于 VLAN 数据包来说,数据包 Protocol 字段一直是 VLAN 的 ETH_P_8021Q ,skb_vlan_untag 就是将 VLAN 信息从数据包的 vlan_tci 字段中提取后,调用 vlan_set_encap_proto 将 Protocol 更新为正常的网络层协议,这时 VLAN 已经一部分转变为正常数据包了。
-
拥有 VLAN tag 的数据包会在 skb_vlan_tag_present 中进入 vlan_do_recieve 的处理流程,vlan_do_receive 的处理过程的核心就是通过 vlan_find_dev 找到子设备,将数据包中的 dev 设置为子设备,然后将 Priority 等与 VLAN 相关的信息进行清理,到了这里,VLAN 数据包已经转变为一个发往 VLAN 子设备的普通数据包了。
-
在 vlan_do_receive 完成后,会进入 another_round,重新按照正常数据包的流程执行一次__netif_receive_skb_core,按照正常包的处理逻辑进入,进入了 rx_handler 的处理,就像一个正常的数据包一样,在子设备上通过与主设备相同的 rx_handler 进入到网络层。
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
rx_handler_func_t *rx_handler;
struct sk_buff *skb = *pskb;
struct net_device *orig_dev;
another_round:
skb->skb_iif = skb->dev->ifindex;
/* 这是尝试对数据帧报文本身做一次vlan的解封装,也就从将背景中的vlan相关的两个字段填充*/
if (eth_type_vlan(skb->protocol)) {
skb = skb_vlan_untag(skb);
if (unlikely(!skb))
goto out;
}
/* 这里就是你所熟知的tcpdump的抓包点了,pt_prev记录了上一个处理报文的handler,如你所见,一份skb可能被很多地方处理,包括pcap */
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
/* 这里在存在vlan tag的情况下,如果有pt_prev已经存在,则做一次deliver_skb,这样其他handler处理的时候就会复制一份,原始报文就不会被修改 */
if (skb_vlan_tag_present(skb)) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
/* 这里是核心的部分,我们看到经过vlan_do_receive处理之后,会变成正常包文再来一遍 */
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
}
/* 这里是正常报文应该到达的地方,pt_prev表示已经找到了正常的handler,然后调用rx_handler进入上层处理 */
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
break;
case RX_HANDLER_PASS:
break;
}
}
if (unlikely(skb_vlan_tag_present(skb)) && !netdev_uses_dsa(skb->dev)) {
check_vlan_id:
if (skb_vlan_tag_get_id(skb)) {
/* 这里是对vlan id并没有正确被摘除的处理,通常是因为vlan id不合法或者不存在在本地
}
}
- 数据发送
VLAN 子设备的数据发送的入口是 vlan_dev_hard_start_xmit,相比于收包流程,其实发送的流程简单很多,内核在发送时的流程如下:

在硬件发送时,VLAN 子设备会进入 vlan_dev_hard_start_xmit 方法,这个方法实现了 ndo_start_xmit 接口,它通过__vlan_hwaccel_put_tag 方法填充 VLAN 相关的以太网信息到报文中,然后修改了报文的设备为主设备,调用主设备的 dev_queue_xmit 方法重新进入主设备的发送队列进行发送,我们截取关键的一部分来分析:
static netdev_tx_t vlan_dev_hard_start_xmit(struct sk_buff *skb,
struct net_device *dev)
{
/* 这里就是上文提到的vlan_tci的填充,这些信息都归属于子设备本身 */
if (veth->h_vlan_proto != vlan->vlan_proto ||
vlan->flags & VLAN_FLAG_REORDER_HDR) {
u16 vlan_tci;
vlan_tci = vlan->vlan_id;
vlan_tci |= vlan_dev_get_egress_qos_mask(dev, skb->priority);
__vlan_hwaccel_put_tag(skb, vlan->vlan_proto, vlan_tci);
}
/* 这里直接将设备从子设备改为了主设备,非常直接 */
skb->dev = vlan->real_dev;
len = skb->len;
if (unlikely(netpoll_tx_running(dev)))
return vlan_netpoll_send_skb(vlan, skb);
/* 这里就可以直接调用主设备进行报文发送了 */
ret = dev_queue_xmit(skb);
...
return ret;
}
MACVlan 设备
看完 VLAN 子设备之后,马上对 MACVlan 进行分析,MACVlan 与 VLAN 子设备不一样的是,它已经不再是以太网本身的能力了,而是一种有自己驱动的虚拟网设备,这一点首先就体现在驱动代码的独立,MACVlan 相关的代码基本都位于/drivers/net/macvlan.c 中。
MACVlan 设备有有五种 mode,其中除了 source 模式外,其余四种都出现比较早,定义如下:
enum macvlan_mode {
MACVLAN_MODE_PRIVATE = 1, /* don't talk to other macvlans */
MACVLAN_MODE_VEPA = 2, /* talk to other ports through ext bridge */
MACVLAN_MODE_BRIDGE = 4, /* talk to bridge ports directly */
MACVLAN_MODE_PASSTHRU = 8,/* take over the underlying device */
MACVLAN_MODE_SOURCE = 16,/* use source MAC address list to assign */
};
这里先记住这些模式的行为,关于其中的原因是我们后面要回答的问题。
- 设备创建
对于 MACVlan 设备来说,它的 netlink 响应结构体是 macvlan_link_ops,我们可以找到创建设备的响应方法为macvlan_newlink,从入口开始,创建一个 MACVlan 设备的整体流程如下:
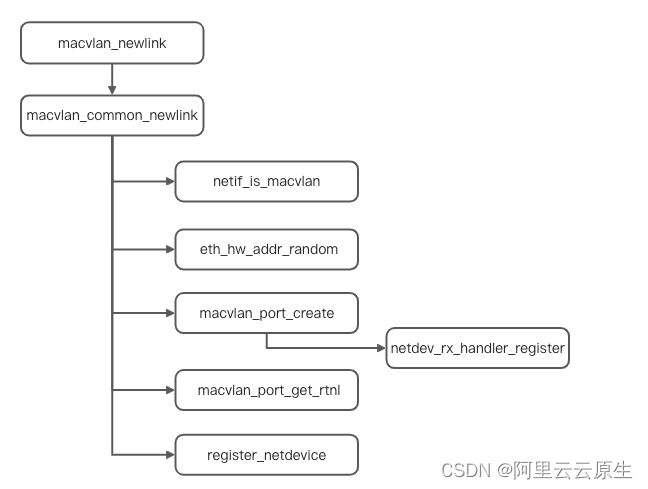
-
macvlan_newlink 会调用 macvlan_common_newlink 进行实际的子设备创建操作,macvlan_common_newlink 首先会进行一个合法性的校验,这其中需要注意的就是 netif_is_MACVlan 检查,如果把一个 MACVlan 子设备作为主设备来创建的话,那么会自动采用这个子设备的主设备作为新建网卡的主设备。
-
接下来会通过 eth_hw_addr_random 给 MACVlan 设备创建一个随机的 mac 地址,没错,MACVlan 子设备的 mac 地址是随机的,这一点很重要,后面会提到。
-
在有了 mac 地址之后,开始在主设备上初始化 MACVlan 逻辑,这里会有个检查,如果主设备从未创建过 MACVlan 设备,则会通过 macvlan_port_create 来支持 MACVlan 的初始化,而这个初始化最为核心的就是,调用 netdev_rx_handler_register 进行了 MACVlan 的 rx_handler 方法 macvlan_handle_frame 去取代了设备原来注册的 rx_handler 的动作。
-
在初始化完成后,获得一个 port,也就是子设备,然后对子设备的信息进行了设置。
-
最后通过 register_netdevice 完成了设备的创建动作。我们截取部分核心逻辑进行分析:
int macvlan_common_newlink(struct net *src_net, struct net_device *dev,
struct nlattr *tb[], struct nlattr *data[],
struct netlink_ext_ack *extack)
{
...
/* 这里检查了主设备是否是macvlan设备,如果是则直接使用他的主设备 */
if (netif_is_macvlan(lowerdev))
lowerdev = macvlan_dev_real_dev(lowerdev);
/* 这里生成了随机的mac地址 */
if (!tb[IFLA_ADDRESS])
eth_hw_addr_random(dev);
/* 这里进行了初始化操作,也就是替换了rx_handler */
if (!netif_is_macvlan_port(lowerdev)) {
err = macvlan_port_create(lowerdev);
if (err < 0)
return err;
create = true;
}
port = macvlan_port_get_rtnl(lowerdev);
/* 接下来一大段都是省略的关于模式的设置 */
vlan->lowerdev = lowerdev;
vlan->dev = dev;
vlan->port = port;
vlan->set_features = MACVLAN_FEATURES;
vlan->mode = MACVLAN_MODE_VEPA;
/* 最后注册了设备 */
err = register_netdevice(dev);
if (err < 0)
goto destroy_macvlan_port;
}
- 接收报文
MACVlan 设备的报文接收依然是从__netif_receive_skb_core 入口开始,具体的代码流程如下:

-
当__netif_receive_skb_core 在主设备接收后,会进入 MACVlan 驱动注册的 macvlan_handle_frame 方法,这个方法首先会处理多播的报文,然后处理单播的报文。
-
对于多播报文,经过 is_multicast_ether_addr 后,首先通过 macvlan_hash_lookup,通过子设备上的相关信息查找到子设备,则根据网卡的 mode 进行处理,如果是 private 或者 passthrou,找到子设备并单独通过 macvlan_broadcast_one 送给它;如果是 bridge 或者没有 VEPA,则所有的子设备都会通过 macvlan_broadcast_enqueue 收到广播报文。
-
对于单播的报文,首先会将 source 模式和 passthru 模式进行处理,直接触发上层的操作,对于其他模式,根据源 mac 进行 macvlan_hash_lookup 操作,如果找到了 VLAN 信息,则将报文的 dev 设置为找到的子设备。
-
最后对报文进行 pkt_type 的设置,将其通过 RX_HANDLER_ANOTHER 的返回,再进行一次__netif_receive_skb_core 的操作,这次操作中,走到 macvlan_hash_lookup 时,由于已经是子设备,所以会返回 RX_HANDLER_PASS 从而进入上层的处理。
-
对于 MACVlan 的数据接收过程,最为关键的就是主设备接收到报文后选择子设备的逻辑,这部分代码如下:
static struct macvlan_dev *macvlan_hash_lookup(const struct macvlan_port *port,
const unsigned char *addr)
{
struct macvlan_dev *vlan;
u32 idx = macvlan_eth_hash(addr);
hlist_for_each_entry_rcu(vlan, &port->vlan_hash[idx], hlist,
lockdep_rtnl_is_held()) {
/* 这部分逻辑就是macvlan查找子设备的核心,比较mac地址 */
if (ether_addr_equal_64bits(vlan->dev->dev_addr, addr))
return vlan;
}
return NULL;
}
- 发送报文
MACVlan 的发送报文过程也是从子设备接收到 ndo_start_xmit 回调函数开始,它的入口是 macvlan_start_xmit,整体的内核代码流程如下:

-
当数据包进入 macvlan_start_xmit 后,主要执行数据包发送操作的是 macvlan_queue_xmit 方法。
-
macvlan_queue_xmit 首先处理 bridge 模式,我们从 mode 的定义可知,只有 bridge 模式下才可能在主设备内部出现不同子设备的直接通信,所有这里处理了这种特殊的情况,把多播报文和目的地为其他子设备的单播报文直接发给子设备。
-
对于其他报文,则会通过 dev_queue_xmit_accel 进行发送,dev_queue_xmit_accel 会直接调用主设备的 netdev_start_xmit 方法,从而实现报文真正的发送。
static int macvlan_queue_xmit(struct sk_buff *skb, struct net_device *dev)
{
...
/* 这里首先是bridge模式下的逻辑,需要考虑不通子设备间的通信 */
if (vlan->mode == MACVLAN_MODE_BRIDGE) {
const struct ethhdr *eth = skb_eth_hdr(skb);
/* send to other bridge ports directly */
if (is_multicast_ether_addr(eth->h_dest)) {
skb_reset_mac_header(skb);
macvlan_broadcast(skb, port, dev, MACVLAN_MODE_BRIDGE);
goto xmit_world;
}
/* 这里对发往同一个主设备的其他子设备进行处理,直接进行转发 */
dest = macvlan_hash_lookup(port, eth->h_dest);
if (dest && dest->mode == MACVLAN_MODE_BRIDGE) {
/* send to lowerdev first for its network taps */
dev_forward_skb(vlan->lowerdev, skb);
return NET_XMIT_SUCCESS;
}
}
xmit_world:
skb->dev = vlan->lowerdev;
/* 这里已经将报文的设备设置为主设备,然后通过主设备进行发送 */
return dev_queue_xmit_accel(skb,
netdev_get_sb_channel(dev) ? dev : NULL);
}
IPVlan 设备
IPVlan 子设备相比于 MACVlan 和 VLAN 子设备来说,模型就更加复杂了,不同于 MACVlan,IPVlan 将与子设备间互通行为通过 flag 来定义,同时又提供了三种 mode,定义如下:
/* 最初只有l2和l3,后面linux有了l3mdev,于是就出现了l3s,他们主要的区别还是在rx */
enum ipvlan_mode {
IPVLAN_MODE_L2 = 0,
IPVLAN_MODE_L3,
IPVLAN_MODE_L3S,
IPVLAN_MODE_MAX
};
/* 这里其实还有个bridge,因为默认就是bridge,所有省略了,他们的语义和macvlan一样 */
#define IPVLAN_F_PRIVATE 0x01
#define IPVLAN_F_VEPA 0x02
- 设备创建
有了之前两种子设备的分析,在 IPVlan 的分析上,我们也可以按照这个思路继续进行分析,IPVlan 设备的 netlink 消息处理结构体是 ipvlan_link_ops,而创建设备的入口方法是 ipvlan_link_new,创建 IPVlan 子设备的流程如下:

-
进入 ipvlan_link_new,进行合法性判断,与 MACVlan 类似,如果以一个 IPVlan 设备作为主设备进行新增,就会自动将 IPVlan 设备的主设备作为新设备的主设备。
-
通过 eth_hw_addr_set 设置 IPVlan 设备的 mac 地址为主设备的 mac 地址,这是 IPVlan 与 MACVlan 最明显的特征区分。
-
进入统一网卡注册的 register_netdevice 流程,在这个流程里,如果当前没有 IPVlan 子设备存在,则会和 MACVlan 一样,进入到 ipvlan_init 的初始化过程,它会在主设备上创建 ipvl_port,并且用 IPVlan 的 rx_handler 去取代主设备原有的 rx_handler,同时也会启动一个专门的内核 worker 去处理多播报文,也就是说,对于 IPVlan,所有的多播报文其实都是统一处理的。
-
接下来继续处理当前这个新增的子设备,通过 ipvlan_set_port_mode 将当前子设备保存到主设备的信息中,同时针对 l3s 的子设备,会将它的 l3mdev 处理方法注册到 nf_hook 中,没错,这是和上面设备最大的区别,l3s 的主设备和子设备交换数据包实际上是在网络层完成的。
对于 IPVlan 网络设备,我们截取 ipvlan_port_create 一部分代码进行分析:
static int ipvlan_port_create(struct net_device *dev)
{
/* 从这里可以看到,port是主设备对子设备管理的核心 */
struct ipvl_port *port;
int err, idx;
/* 子设备的各种属性,都在port中体现,也可以看到默认的mode是l3 */
write_pnet(&port->pnet, dev_net(dev));
port->dev = dev;
port->mode = IPVLAN_MODE_L3;
/* 这里可以看到,对于ipvlan,多播的报文都是单独处理的 */
skb_queue_head_init(&port->backlog);
INIT_WORK(&port->wq, ipvlan_process_multicast);
/* 这里就是常规操作了,其实他是靠着这里来让主设备的收包可以顺利配合ipvlan的动作 */
err = netdev_rx_handler_register(dev, ipvlan_handle_frame, port);
if (err)
goto err;
}
- 接收报文
IPVlan 子设备的三种 mode 分别有不同的收包处理流程,在内核的流程如下:

-
与 MACVlan 类似,首先会经过__netif_receive_skb_core 进入到创建时注册的 ipvlan_handle_frame 的处理流程,此时数据包依然是主设备所拥有。
-
对于 mode l2 模式的报文处理,只处理多播的报文,将报文放进前面创建子设备时初始化的多播处理的队列;对于单播报文,会直接交给 ipvlan_handle_mode_l3 进行处理!
-
对于 mode l3 或者单播的 mode l2 报文,进入 ipvlan_handle_mode_l3 处理流程,首先通过 ipvlan_get_L3_hdr 获取到网络层的头信息,然后根据 ip 地址去查找到对应的子设备,最后调用 ipvlan_rcv_frame,将报文的 dev 设置为 IPVlan 子设备并返回 RX_HANDLER_ANOTHER,进行下一次收包。
-
对于 mode l3s,在 ipvlan_handle_frame 中会直接返回 RX_HANDLER_PASS,也就是说,mode l3s 的报文会在主设备就进入到网络层的处理阶段,对于 mode l3s 来说,预先注册的 nf_hook 会在 NF_INET_LOCAL_IN 时触发,执行 ipvlan_l3_rcv 操作,通过 addr 找到子设备,更换报文的网络层目的地址,然后直接进入 ip_local_deliver 进行网络层余下的操作。
- 发送报文
IPVlan 的报文发送,尽管在实现上相对复杂,但是究其根本,还是各个子设备在想办法用主设备来做到发送报文的工作,IPVlan 子设备进行数据包发送时,首先进入 ipvlan_start_xmit,其核心的发送操作在 ipvlan_queue_xmit,内核代码流程如下:
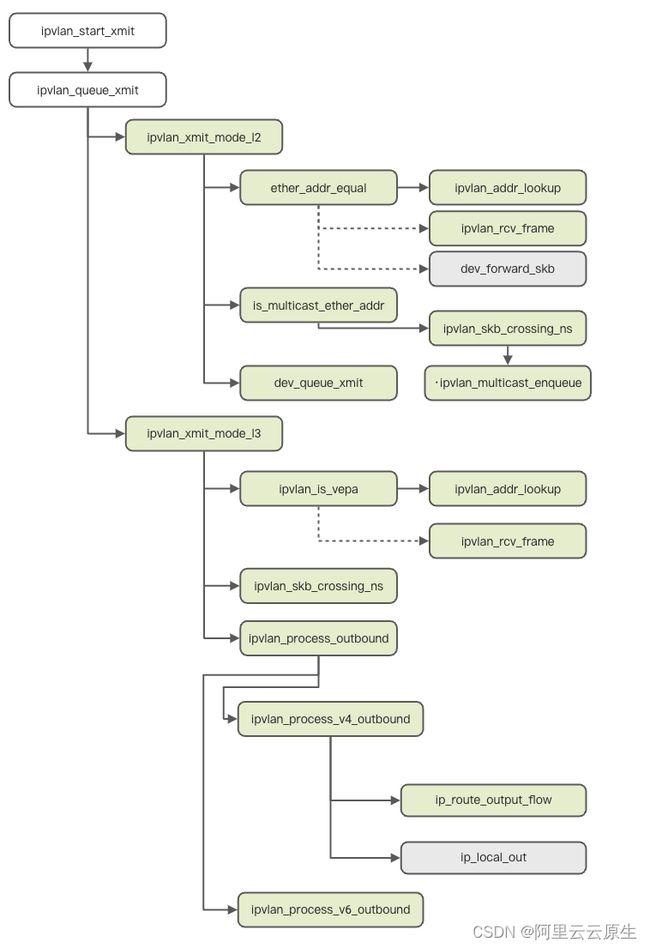
-
ipvlan_queue_xmit 根据子设备的模式选择不同的发送方法,mode l2 通过 ipvlan_xmit_mode_l2 发送,mode l3 和 mode l3s 进行 ipvlan_xmit_mode_l3 发送。
-
对于 ipvlan_xmit_mode_l2,首先判断是否是本地地址或者 VEPA 模式,如果不是 VEPA 模式的本地报文,则首先通过 ipvlan_addr_lookup 查到到是否是相同主设备下的 IPVlan 子设备,如果是,则通过 ipvlan_rcv_frame 让其他子设备进行收包处理;如果不是,则通过 dev_forward_skb 让主设备进行处理。
-
接下来 ipvlan_xmit_mode_l2 会对多播报文进行处理,在处理之前,通过 ipvlan_skb_crossing_ns 清理掉数据包的 netns 相关的信息,包括 priority 等,最后将数据包放到 ipvlan_multicast_enqueue,触发上述的多播处理流程。
-
对于非本地的数据包,通过主设备的 dev_queue_xmit 进行发送。
-
ipvlan_xmit_mode_l3 的处理首先也是对 VEPA 进行判断,对与非 VEPA 模式的数据包,通过ipvlan_addr_lookup 查找是否是其他子设备,如果是则调用 ipvlan_rcv_frame 触发其他设备进行收包处理。
-
对于非 VEPA 模式的数据包,首先进行 ipvlan_skb_crossing_ns 的处理,然后进行 ipvlan_process_outbound的操作,此时根据数据包的网络层协议,选择 ipvlan_process_v4_outbound 或者 ipvlan_process_v6_outbound 进行处理。
-
以 ipvlan_process_v6_outbound 为例,首先会通过 ip_route_output_flow 进行路由的查找,然后直接通过网络层的 ip_local_out,在主设备的网络层继续进行发包操作。
解决问题
经历上面的分析和一番体会思考,我想至少第一个问题已经可以很轻易的回答出来了:
VLAN 与 MACVlan/IPVlan 的关系
VLAN 和 IPVlan,MACVlan 有什么关系呢?为什么名字里都有 VLAN?
既然 MACVlan 和 IPVlan 选择叫这个名字,那说明在某些方面还是有相似之处的。我们整体分析下来发现,VLAN 子设备和 MACVlan,IPVlan 的核心逻辑很相似:
-
主设备负责物理上的收发包。
-
主设备将子设备管理为多个 port,然后根据一定的规则找到 port,比如 VLAN 信息,mac 地址以及 ip 地址(macvlan_hash_lookup,vlan_find_dev,ipvlan_addr_lookup)。
-
主设备收包后,都需要经过在__netif_receive_skb_core 中走一段“回头路”.
-
子设备发包最终都是直接通过修改报文的 dev,然后让主设备去操作。
所以不难推论,MACVlan/IPVlan 的内在逻辑其实很大程度上参考了 Linux 的 VLAN 的实现。Linux 最早加入 MACVlan 是在 2007 年 6 月 18 日发布的 2.6.63 版本 [ 3] ,对他的描述是:
The new “MACVlan” driver allows the system administrator to create virtual interfaces mapped to and from specific MAC addresses.
而到了 2014 年 12 月 7 日 发布的 3.19 版本 [ 4] 中,第一次引入了 IPVlan,他的描述是:
The new “IPVlan” driver enable the creation of virtual network devices for container interconnection. It is designed to work well with network namespaces. IPVlan is much like the existing MACVlan driver, but it does its multiplexing at a higher level in the stack.
至于 VLAN,出现的远比 Linux 2.4 版本还要早,很多设备的第一版驱动就已经支持了 VLAN,不过,Linux 对于 VLAN 的 hwaccel 实现,是 2004 年的 2.6.10 [ 5] ,当时更新的一大批特性中,出现了这一条:
I was poking about in the National Semi 83820 driver, and I happened to notice that the chip supports VLAN tag add/strip assist in hardware, but the driver wasn’t making use of it. This patch adds in the driver support to use the VLAN tag add/remove hardware, and enables the drivers use of the kernel VLAN hwaccel interface.
也就是说,当 Linux 开始把 VLAN 当作一个 interface 处理后,才有了后面的 MACVlan 和 IPVlan 两个 virtual interface,Linux 为了实现对于 VLAN 数据包的处理流程的加速,把不同的 VLAN 虚拟成了设备,而后期 MACVlan 和 IPVlan 在这种思路之下,让虚拟设备有了更大的用武之地。
这样看来,它们的关系更像是一种致敬。
关于 VEPA/passthrough/bridge/private
IPVlan 和 MACVlan 为什么会有各种模式和 flag,比如 VEPA,private,passthrough 等等?它们的区别在哪里?
其实在内核的分析中,我们已经大致了解了这几种模式的表现,假如主设备是一个钉钉群,所有的群友都可以向外发消息,那么其实几种模式就非常直观:
- private 模式,群友们相互之间都是禁言的,既不能在群内,也不能在群外。
- bridge 模式,群友们可以在群内愉快发言。
- VEPA 模式,群友们在群内禁言了,但是你们在群外直接私聊,相当于年会抢红包时期的集体禁言。
- passthrough 模式,这时候你就是群主了,除了你没人能发言。
那么为什么会有这几种模式呢?我们从内核的表现来看,无论是 port,还是 bridge,其实都是网络的概念,也就是说,从一开始,Linux 就在努力将自己表现成一个合格的网络设备,对于主设备,Linux 努力将它做成一个交换机,对于子设备,那就是一个个网线背后的设备,这样看起来就很合理了。
实际上正是这样,无论是 VEPA 还是 private,它们最初都是网络概念。其实不止是 Linux,我们见到很多致力于把自己伪装成物理网络的项目,都沿袭了这些行为模式,比如 OpenvSwitch [ 6] 。
MACVlan 与 IPVlan 的应用
IPVlan 和 MACVlan 的优势在哪里?你应该在什么情况下接触到,使用到它们呢?
其实到这里,才开始说到本篇文章的初衷。我们从第二个问题发现,IPVlan 和 MACVlan 都是在做一件事:虚拟网络。我们为什么要虚拟网络呢?这个问题有很多答案,但是和云计算的价值一样,虚拟网络作为云计算的一项基础技术,它们最终都是为了资源利用效率的提升。
MACVlan 和 IPVlan 就是服务了这个最终目的,土豪们一台物理机跑一个 helloworld 的时代依然过去,从虚拟化到容器化,时代对网络密度提出了越来越高的要求,伴随着容器技术的诞生,首先是 veth 走上舞台,但是密度够了,还要性能的高效,MACVlan 和 IPVlan 通过子设备提升密度并保证高效的方式应运而生(当然还有我们的 ENI-Trunking)。
说到这里,就要为大家推荐一下阿里云容器服务 ACK 给大家带来的高性能、高密度的网络新方案——IPVlan 方案 [ 7] !
ACK 基于 Terway 插件,实现了基于 IPVlan 的 K8s 网络解决方案。Terway 网络插件是 ACK 自研的网络插件,将原生的弹性网卡分配给 Pod 实现 Pod 网络,支持基于 Kubernetes 标准的网络策略(Network Policy)来定义容器间的访问策略,并兼容 Calico 的网络策略。
在 Terway 网络插件中,每个 Pod 都拥有自己网络栈和IP地址。同一台 ECS 内的 Pod 之间通信,直接通过机器内部的转发,跨 ECS 的 Pod 通信、报文通过 VPC 的弹性网卡直接转发。由于不需要使用 VxLAN 等的隧道技术封装报文,因此 Terway 模式网络具有较高的通信性能。Terway 的网络模式如下图所示:
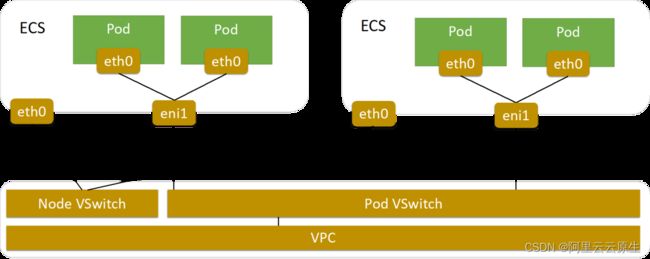
客户在使用 ACK 创建集群时,如果选择 Terway 网络插件,可以配置其使用 Terway IPvlan 模式。Terway IPvlan 模式采用 IPvlan 虚拟化和 eBPF 内核技术实现高性能的 Pod 和 Service 网络。
不同于默认的 Terway 的网络模式,IPvlan 模式主要在 Pod 网络、Service、网络策略(NetworkPolicy)做了性能的优化:
-
Pod 的网络直接通过 ENI 网卡的 IPvlan L2 的子接口实现,大大简化了网络在宿主机上的转发流程,让 Pod 的网络性能几乎与宿主机的性能无异,延迟相对传统模式降低 30%。
-
Service 的网络采用 eBPF 替换原有的 kube-proxy 模式,不需要经过宿主机上的 iptables 或者 IPVS 转发,在大规模集群中性能几乎无降低,扩展性更优。在大量新建连接和端口复用场景请求延迟比 IPVS 和 iptables 模式的大幅降低。
-
Pod 的网络策略(NetworkPolicy)也采用 eBPF 替换掉原有的 iptables 的实现,不需要在宿主机上产生大量的 iptables 规则,让网络策略对网络性能的影响降到最低。
所以,利用 IPVlan 为每个业务 pod 分配 IPVlan 网卡,既保证了网络的密度,也使传统网络的 Veth 方案实现巨大的性能提升(详见参考链接 7)。同时,Terway IPvlan 模式提供了高性能的 Service 解决方案,基于 eBPF 技术,我们规避了诟病已久的 Conntrack 性能问题。
相信无论是什么场景的业务,ACK with IPVlan 都是一个更为出色的选择。
最后感谢你能阅读到这里,在这个问题背后,其实隐藏了一个问题,你知道为什么我们选择 IPVlan,而没有选择 MACVlan 么?如果你对虚拟网络技术有了解,那么结合上述的内容,你应该很快就有答案了,也欢迎你在评论区留言。
参考链接:
*[1] *《关于 IEEE 802.1Q》
https://zh.wikipedia.org/wiki/IEEE_802.1Q
[2] 《Docker Engine release notes》
https://docs.docker.com/engine/release-notes/prior-releases/
[3] 《Merged for MACVlan 2.6.23》
https://lwn.net/Articles/241915/
[4] 《MACVlan 3.19 Merge window part 2》
https://lwn.net/Articles/626150/
[5] 《VLan 2.6.10-rc2 long-format changelog》
https://lwn.net/Articles/111033/
[6] 《[ovs-dev] VEPA support in OVS》
https://mail.openvswitch.org/pipermail/ovs-dev/2013-December/277994.html
[7] 《阿里云 Kubernetes 集群使用 IPVlan 加速 Pod 网络》
https://developer.aliyun.com/article/743689
点击此处,了解基于阿里云 ACK Terway 的 IPvlan。