【机器学习】Python常见用法汇总
【机器学习】Python常见用法汇总

活动地址:[CSDN21天学习挑战赛](https://marketing.csdn.net/p/bdabfb52c5d56532133df2adc1a728fd)
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:机器学习
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【机器学习】Python常见用法汇总
- 前言
-
-
- 为什么选择Python?
-
- 一、海量文件遍历
-
- (一)、数据准备
- (二)、实现“海量”文件的类型与存储空间统计
- (三)、小结
- 二、简单计算器实现
-
- (一)、定义两数字之间的计算操作
- (二)、解析输入的字符串表达式为表达式列表
- (三)、定义运算符压栈的决策函数
- (四)、实现表达式计算
- (五)、编写主程序,计算表达式结果
- 三、图像直方图统计
-
- (一)、准备一张图像
- (二)、绘制所有通道上整体的图像直方图
- (三)、分别绘制三通道的直方图
- (四)、小结
- 四、文本词频分析
-
- (一)、文本加载
- (二)、文本分词
- (三)、去停用词处理
- (四)、根据词频排序并输出
- 总结
前言
为什么选择Python?
-
Python是一种面向对象的脚本语言,使用时无需编译,因此也称作解释性语言,其结构简单,语法规则明确,关键词定义较少,非常适合初学者。
-
Python拥有丰富的内置库函数,对于处理网络、文件、GUI、数据库、文本等十分便捷,同时支持大量第三方库,比如最常用的用于科学计算的Numpy、SciPy等库,为科研工作者提供了非常简洁、高效的开发平台。
-
Python作为当下最流行的语言之一,有着易于维护、跨平台移植、可嵌入等独特优势,使其在人工智能领域备受推崇。
一、海量文件遍历
“海量”文件遍历旨在对文件夹下的大规模数据进行数据类型及占用存储空间的统计。
(一)、数据准备
- 定义解压函数:
import zipfile
def unzip_data(src_path,target_path):
# 解压原始数据集,将src_path路径下的zip包解压至target_path目录下
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
- 调用解压函数
unzip_data('data/data19638/insects.zip','data/data19638/insects')
unzip_data('data/data55217/Zebra.zip','data/data55217/Zebra')
(二)、实现“海量”文件的类型与存储空间统计
- 调用全局遍历
import os
"""
通过给定目录,统计所有的不同子文件类型及占用内存
"""
size_dict = {}
type_dict = {}
def get_size_type(path):
files = os.listdir(path)
for filename in files:
temp_path = os.path.join(path, filename)
if os.path.isdir(temp_path):
# 递归调用函数,实现深度文件名解析
get_size_type(temp_path)
elif os.path.isfile(temp_path):
# 获取文件后缀
type_name=os.path.splitext(temp_path)[1]
#无后缀名的文件
if not type_name:
type_dict.setdefault("None", 0)
type_dict["None"] += 1
size_dict.setdefault("None", 0)
size_dict["None"] += os.path.getsize(temp_path)
# 有后缀的文件
else:
type_dict.setdefault(type_name, 0)
type_dict[type_name] += 1
size_dict.setdefault(type_name, 0)
# 获取文件大小
size_dict[type_name] += os.path.getsize(temp_path)
- 调用上述函数实现,对文件进行统计:
path= "data/"
get_size_type(path)
for each_type in type_dict.keys():
print ("%5s下共有【%5s】的文件【%5d】个,占用内存【%7.2f】MB" %
(path,each_type,type_dict[each_type],\
size_dict[each_type]/(1024*1024)))
print("总文件数: 【%d】"%(sum(type_dict.values())))
print("总内存大小:【%.2f】GB"%(sum(size_dict.values())/(1024**3)))
输出如图1-1所示:

(三)、小结
至此,我们已经实现了如何动手编写一个Python小程序,统计路径下文件的类型及其占用空间的大小,这是一个非常实用的小技巧,可以帮助研究者快速实现文件的信息统计,对处理这些文件数据所需的资源进行合理规划和调配。
二、简单计算器实现
使用Python实现输入表达式计算,并返回计算结果。
主要思路如下:
- 解析计算单元,包括计算符号、计算数(负数提取)等。
- 根据优先级计算规则,对解析出的计算单元执行计算。
在计算过程中,括号具有最高优先级。因此,在表达式中搜索最后一个左括号,再搜索与之匹配的右括号,截取两个括号之间的表达式,进行先乘除后加减的运算,计算完括号内的表达式之后,将左右括号删除,计算结果当作一个新的操作数进行处理,循环上述计算过程,直至所有操作都执行完成。
(一)、定义两数字之间的计算操作
def calculate(n1, n2, operator):
'''
:param n1: float
:param n2: float
:param operator: + - * /
:return: float
'''
result = 0
if operator == "+":
result = n1 + n2
if operator == "-":
result = n1 - n2
if operator == "*":
result = n1 * n2
if operator == "/":
result = n1 / n2
return result
# 判断是否是运算符,如果是返回True
def is_operator(e):
'''
:param e: str
:return: bool
'''
opers = ['+', '-', '*', '/', '(', ')']
return True if e in opers else False
(二)、解析输入的字符串表达式为表达式列表
# SVM分类器构建
# 将算式处理成列表,解决-是负数还是减号
def formula_format(formula):
# 去掉算式中的空格
formula = re.sub(' ', '', formula)
# 以 '横杠数字' 分割, 其中正则表达式:(\-\d+\.?\d*) 括号内:
# \- 表示匹配横杠开头; \d+ 表示匹配数字1次或多次;\.?表示匹配小数点0次或1次;\d*表示匹配数字1次或多次。
formula_list = [i for i in re.split('(\-\d+\.?\d*)', formula) if i]
# 最终的算式列表
final_formula = []
for item in formula_list:
# 第一个是以横杠开头的数字(包括小数)final_formula。即第一个是负数,横杠就不是减号
if len(final_formula) == 0 and re.search('^\-\d+\.?\d*$', item):
final_formula.append(item)
continue
if len(final_formula) > 0:
# 如果final_formal最后一个元素是运算符['+', '-', '*', '/', '('], 则横杠数字不是负数
if re.search('[\+\-\*\/\(]$', final_formula[-1]):
final_formula.append(item)
continue
# 按照运算符分割开
item_split = [i for i in re.split('([\+\-\*\/\(\)])', item) if i]
final_formula += item_split
return final_formula
(三)、定义运算符压栈的决策函数
def decision(tail_op, now_op):
'''
:param tail_op: 运算符栈的最后一个运算符
:param now_op: 从算式列表取出的当前运算符
:return: 1 代表弹栈运算,0 代表弹运算符栈最后一个元素, -1 表示入栈
'''
# 定义4种运算符级别
rate1 = ['+', '-']
rate2 = ['*', '/']
rate3 = ['(']
rate4 = [')']
if tail_op in rate1:
if now_op in rate2 or now_op in rate3:
# 说明连续两个运算优先级不一样,需要入栈
return -1
else:
return 1
elif tail_op in rate2:
if now_op in rate3:
return -1
else:
return 1
elif tail_op in rate3:
if now_op in rate4:
return 0 # ( 遇上 ) 需要弹出 (,丢掉 )
else:
return -1 # 只要栈顶元素为(,当前元素不是)都应入栈。
else:
return -1
(四)、实现表达式计算
def final_calc(formula_list):
num_stack = [] # 数字栈
op_stack = [] # 运算符栈
for e in formula_list:
operator = is_operator(e)
if not operator:
# 压入数字栈
# 字符串转换为符点数
num_stack.append(float(e))
else:
# 如果是运算符
while True:
# 如果运算符栈等于0无条件入栈
if len(op_stack) == 0:
op_stack.append(e)
break
# decision 函数做决策
tag = decision(op_stack[-1], e)
if tag == -1:
# 如果是-1压入运算符栈进入下一次循环
op_stack.append(e)
break
elif tag == 0:
# 如果是0弹出运算符栈内最后一个(, 丢掉当前),进入下一次循环
op_stack.pop()
break
elif tag == 1:
# 如果是1弹出运算符栈内最后两个元素,弹出数字栈最后两位元素。
op = op_stack.pop()
num2 = num_stack.pop()
num1 = num_stack.pop()
# 执行计算
# 计算之后压入数字栈
num_stack.append(calculate(num1, num2, op))
# 处理大循环结束后 数字栈和运算符栈中可能还有元素 的情况
while len(op_stack) != 0:
op = op_stack.pop()
num2 = num_stack.pop()
num1 = num_stack.pop()
num_stack.append(calculate(num1, num2, op))
return num_stack, op_stack
(五)、编写主程序,计算表达式结果
if __name__ == '__main__':
formula = input('请输入:\n')
# formula = "1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2))"
print("算式:", formula)
formula_list = formula_format(formula)
result, _ = final_calc(formula_list)
print("计算结果:", result[0])
运行主程序,在控制台输入如图2-1所示的算式,即可得到输出的计算结果。

三、图像直方图统计
灰度直方图概括了图像的灰度级信息,简单的来说就是每个灰度级图像中的像素个数以及占有率,创建直方图无外乎两个步骤,统计直方图数据,再用绘图库绘制直方图。
统计直方图数据:
首先要稍微理解一些与函数相关的术语,方便理解其在python3库中的应用和处理
BINS: 在上面的直方图当中,如果像素值是0到255,则需要256个值来显示直 方图。但是,如果不需要知道每个像素值的像素数目,只想知道两个像素值之间的像素点数目怎么办?例如,想知道像素值在0到15之间的像素点数目,然后是16到31…240到255。可以将256个值分成16份,每份计算综合。每个分成的小组就是一个BIN(箱)。在opencv中使用histSize表示BINS。
DIMS: 数据的参数数目。当前例子当中,对收集到的数据只考虑灰度值,所以该值为1。
RANGE: 灰度值范围,通常是[0,256],也就是灰度所有的取值范围。
统计直方图同样有两种方法,使用opencv统计直方图,函数如下:
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
(一)、准备一张图像
以一张哪吒图像为例(图3-1),进行后续直方图统计,直观上,该张图像的亮度较暗,因此在此刻可以推理出,该图像的直方图灰度值分布应该偏向于灰度值较低的区域,那么是否如此呢?

(二)、绘制所有通道上整体的图像直方图
图像数据分为R、G、B三个通道,同一位置的三个通道灰度值构成一个该像素点的最终着色形式。该步骤将三个通道中的所有灰度值拉平后进行统计,例如,一张彩色图片的大小为200×200,那么其拉平后的灰度值个数为3×200×200=120000,在所有通道上整体的图像直方统计正是对这120000个灰度值在各个bins内出现的1频次的刻画。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('data/data131/test.jpeg',1)
img_np = np.array(img)
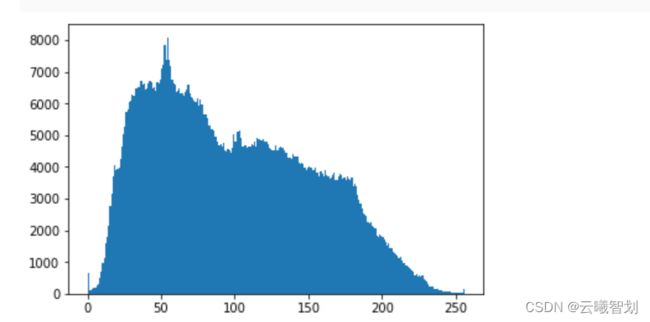
plt.hist(img.reshape([-1]),256,[0,256]);
plt.show()
上述代码中,plt.hist()函数用来绘制直方图,将x轴[0,256)的区间划分为256个bins,因此,每个不同的灰度值均会落在不同的bins中,绘制结果如图3-2所示,图中灰度值的分布稍微偏左,说明了该图片的整体色调较暗。
(三)、分别绘制三通道的直方图
上述直方图无法区分在不同通道上的图统计特性,现在使用一种新的方法分别展示不同通道上,灰度值的分布特征。OpenCV库提供了专门的用于图像像素值统计的函数:
cv2.calcHist([images], [channels], mask, histSize, ranges[, hist[,
accumulate ]])
.
imaes:输入的图像 channels:选择图像的通道
mask:掩膜,是一个大小和image一样的np数组,其中把需要处理的部分指定为1,不需要处理的部分指定为0,一般设置为None,表示处理整幅图像
histSize:使用多少个bin(柱子),一般为256 ranges:像素值的范围,一般为[0,255]表示0~255
import cv2
# import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('data/nezha.jpeg',0)
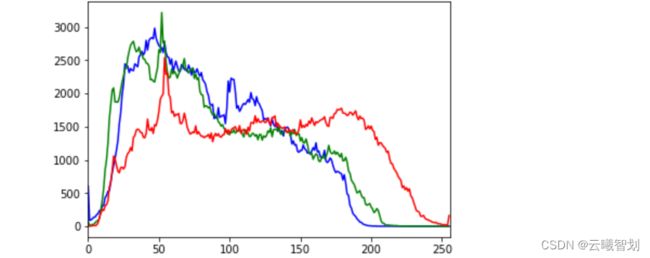
histr = cv2.calcHist([img],[0],None,[256],[0,256]) #hist是一个shape为(256,1)的数组,表示0-255每个像素值对应的像素个数,下标即为相应的像素值
plt.plot(histr,color = 'b')
plt.xlim([0,256])
plt.show()
绘制的三通道直方图结果如图3-3所示,从原始图片中可以看出,三原色中红色的部分在整张图片中是比较鲜明的,而图3-3中红色部分的x轴右侧要高于其它亮色,解释了整体的图片风格基调。
(四)、小结
上述调用了两种第三方库方法进行灰度值的统计,当然也可以动手实现一个统计函数,实现上述直方图展示,此处不再赘述。
四、文本词频分析
文本与图片具有本质上的差别:图片本质上是数字化的,其每个像素点都由三原色的组合灰度值构成,而文本属于自然语言,其表现形式无法被计算机直接识别,因此,在自然语言处理技术发展的早期,解决文本表示问题是一项极具挑战的任务。
与图像灰度值的直方图展示相类似,早期的研究者也对文本进行词频统计,将文本中各词出现的频率作为特征,然后进行后续一系列分析与处理。然而,各语言文本在表现形式上也具有很大的差异,比如英文文本由单词个体构成,空格为天然的单词分隔符,因此统计十分便利,然而中文不具备这种天然的分割形式,若要进行词频统计,需要对文本进行预处理,即分词。
下面逐一介绍进行中文文本词频统计的步骤。
(一)、文本加载
首先将需要分析的文本从文件中读出,本文以一篇散文为例进行后面的分析:
with open('test.txt', 'r', encoding='UTF-8') as novelFile:
novel = novelFile.read()
(二)、文本分词
目前,Python支持多种第三方分词工具,最常用的有jieba分词、SnowNLP、THULAC、NLPIR等,本书以jieba分词为例进行演示,更多分词工具读者可以自行实验尝试。
stopwords = [line.strip() for line in open('stop.txt', 'r', encoding='UTF-8').readlines()]
novelList = list(jieba.lcut(novel))
novelDict = {}
(三)、去停用词处理
在自然语言钟,存在很多无意义的词,比如标点符号、“的”、“之”等,这类词出现频率高,但具有很有限的语义作用,称作停用词。为了避免这类词对统计结果造成的干扰,通常在分词之后,需要将其剔除,只保留重要的词语用作进一步分析,下面一段代码演示了在计算每个词出现的频次的过程钟,若该词在停用词列表中时,做不计入处理。
# 统计出词频字典
for word in novelList:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
novelDict[word] = novelDict.get(word, 0) + 1
(四)、根据词频排序并输出
import jieba # jieba中文分词库
with open('test.txt', 'r', encoding='UTF-8') as novelFile:
novel = novelFile.read()
# print(novel)
stopwords = [line.strip() for line in open('stop.txt', 'r', encoding='UTF-8').readlines()]
novelList = list(jieba.lcut(novel))
novelDict = {}
# 统计出词频字典
for word in novelList:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
novelDict[word] = novelDict.get(word, 0) + 1
# 对词频进行排序
novelListSorted = list(novelDict.items())
novelListSorted.sort(key=lambda e: e[1], reverse=True)
# 打印前10词频
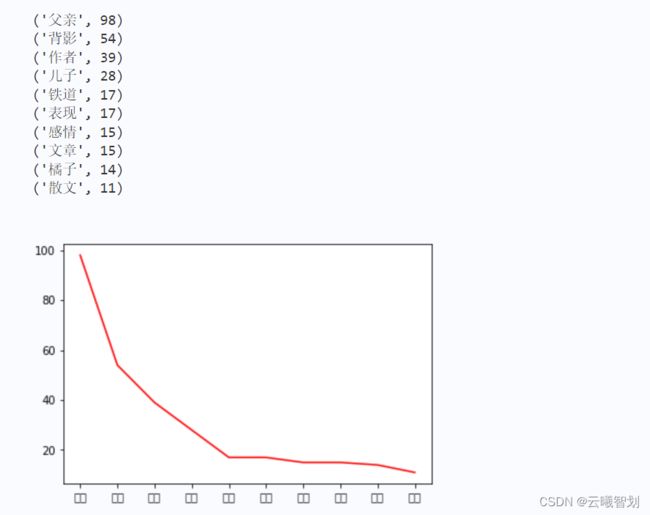
topWordNum = 0
for topWordTup in novelListSorted[:10]:
print(topWordTup)
from matplotlib import pyplot as plt
x = [c for c,v in novelListSorted]
y = [v for c,v in novelListSorted]
plt.plot(x[:10],y[:10],color='r')
plt.show()
输出结果如图4-1所示:
from wordcloud import WordCloud,ImageColorGenerator
import jieba
import matplotlib.pyplot as plt
from imageio import imread
#读入背景图片
bg_pic = imread('图1.png')
#生成词云图片
wordcloud = WordCloud(mask=bg_pic,background_color='white',\
scale=1.5,font_path=r'msyh.ttc').generate(' '.join(novelDict.keys()))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#保存图片
wordcloud.to_file('父亲.jpg')

总结
本系列文章内容为根据清华社初版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞浆开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
