YOLOv3 代码详解(4) —— 网络结构的搭建、loss的定义
前言:
yolo系列的论文阅读
论文阅读 || 深度学习之目标检测 重磅出击YOLOv3
论文阅读 || 深度学习之目标检测yolov2
论文阅读 || 深度学习之目标检测yolov1
该篇讲解的工程连接是:
tensorflow的yolov3:https://github.com/YunYang1994/tensorflow-yolov3
自己对该工程的解析博客:
YOLOv3 || 1. 使用自己的数据集训练yolov3
YOLOv3 || 2. dataset.py解析
YOLOv3 || 3. dataset.py的多进程改造
YOLOv3 || 4. yolov3.py 网络结构的搭建和loss的定义
YOLOv3 || 5. train.py
YOLOv3 || 6. anchorboxes的获取 kmeans.py
YOLOv3 || 7. yolov3的pb文件的测试
前面介绍了数据读取与处理部分的代码。
该篇博客介绍的是yolov3网络结构的搭建,和loss的定义。
1 代码讲解
1.1 代码概述
该脚本定义了yolov3的类,包含了神经网络的搭建和loss的定义
class YOLOV3(object): """Implement tensoflow yolov3 here""" def __init__(self, input_data, trainable): ... def __build_nework(self, input_data): """神经网络的搭建""" def decode(self, conv_output, anchors, stride): """神经网络输出层的解码""" def focal(self, target, actual, alpha=1, gamma=2): def bbox_giou(self, boxes1, boxes2): """计算giou""" def bbox_iou(self, boxes1, boxes2): """计算iou""" def loss_layer(self, conv, pred, label, bboxes, anchors, stride): """结合【网络输出的解码】和【label】,计算网络的loss""" def compute_loss(self, label_sbbox, label_mbbox, label_lbbox, true_sbbox, true_mbbox, true_lbbox): """计算3个输出模块的loss总和"""
1.2
def __init__()该部分代码主要实现yolov3的初始化,未有什么复杂的内容
import numpy as np import tensorflow as tf import core.utils as utils import core.common as common mport core.backbone as backbone from core.config import cfg class YOLOV3(object): """Implement tensoflow yolov3 here""" def __init__(self, input_data, trainable): self.trainable = trainable self.classes = utils.read_class_names(cfg.YOLO.CLASSES) self.num_class = len(self.classes) self.strides = np.array(cfg.YOLO.STRIDES) self.anchors = utils.get_anchors(cfg.YOLO.ANCHORS) self.iou_loss_thresh = cfg.YOLO.IOU_LOSS_THRESH self.upsample_method = cfg.YOLO.UPSAMPLE_METHOD try: # self.conv_lbbox:8倍下采样输出 # self.conv_mbbox:16倍下采样输出 # self.conv_sbbox:32倍下采样输出 self.conv_lbbox, self.conv_mbbox, self.conv_sbbox = self.__build_nework(input_data) except: raise NotImplementedError("Can not build up yolov3 network!") with tf.variable_scope('pred_sbbox'): # 结合输出尺寸和anchor,对神经网络的输出进行解码,得到【xywh,confidence,class】的形式 self.pred_sbbox = self.decode(self.conv_sbbox, self.anchors[0], self.strides[0]) with tf.variable_scope('pred_mbbox'): # 结合输出尺寸和anchor,对神经网络的输出进行解码,得到【xywh,confidence,class】的形式 self.pred_mbbox = self.decode(self.conv_mbbox, self.anchors[1], self.strides[1]) with tf.variable_scope('pred_lbbox'): # 结合输出尺寸和anchor,对神经网络的输出进行解码,得到【xywh,confidence,class】的形式 self.pred_lbbox = self.decode(self.conv_lbbox, self.anchors[2], self.strides[2])
1.3 yolov3的网络结构
1.3.1
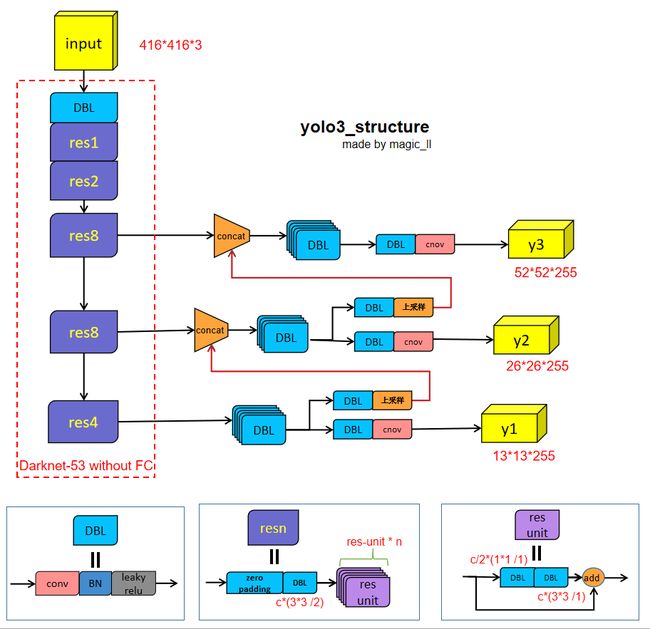
def __build_nework()在之前的博客中,有详细讲述到yolov3的网络结构等内容 重磅出击YOLOv3
def __build_nework(self, input_data): route_1, route_2, input_data = backbone.darknet53(input_data, self.trainable) input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv52') input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv53') input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv54') input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv55') input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv56') conv_lobj_branch = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, >name='conv_lobj_branch') conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(self.num_class + 5)), trainable=self.trainable, name='conv_lbbox', activate=False, bn=False) input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv57') input_data = common.upsample(input_data, name='upsample0', method=self.upsample_method) with tf.variable_scope('route_1'): input_data = tf.concat([input_data, route_2], axis=-1) input_data = common.convolutional(input_data, (1, 1, 768, 256), self.trainable, 'conv58') input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv59') input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv60') input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv61') input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv62') conv_mobj_branch = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, >name='conv_mobj_branch' ) conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(self.num_class + 5)), trainable=self.trainable, name='conv_mbbox', activate=False, bn=False) input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv63') input_data = common.upsample(input_data, name='upsample1', method=self.upsample_method) with tf.variable_scope('route_2'): input_data = tf.concat([input_data, route_1], axis=-1) input_data = common.convolutional(input_data, (1, 1, 384, 128), self.trainable, 'conv64') input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv65') input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv66') input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv67') input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv68') conv_sobj_branch = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, >name='conv_sobj_branch') conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(self.num_class + 5)), trainable=self.trainable, name='conv_sbbox', activate=False, bn=False) return conv_lbbox, conv_mbbox, conv_sbbox
1.3.1
def decode()神经网络的最后一层的输出,其中位置信息为 ( t x , t y , t h , t w ) (t_x,t_y,t_h,t_w) (tx,ty,th,tw),并不是bbox在2D图上的具体位置 ( b x , b y , b h , b w ) (b_x,b_y,b_h,b_w) (bx,by,bh,bw),所以需要转换。即该函数的功能。
在之前的yolov3讲述过,每个特征图的输出围度为 N ∗ N ∗ 3 ∗ ( 4 + 1 + 80 ) N*N*3*(4+1+80) N∗N∗3∗(4+1+80)。其中 N ∗ N N*N N∗N为输出特征图的grid数量;3为一个grid有3个anchor box;每个box有4维预测框位置 t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th,1维预测框的 c o n f i d e n c e confidence confidence,80维物体的 c l a s s e s classes classes。
- 检测框解码
获取到了网络的输出以及先验框后,解码检测框 x , y , w , h x,y,w,h x,y,w,h: b x = σ ( t x ) + c x b_x=\sigma (t_x)+c_x bx=σ(tx)+cx b y = σ ( t y ) + c y b_y=\sigma (t_y)+c_y by=σ(ty)+cy b w = p w e t w b_w=p_we^{t_w} bw=pwetw b h = p h e t n b_h=p_he^{t_n} bh=phetn其中: t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th为网络输出的部分内容; σ ( t x ) , σ ( t y ) \sigma (t_x),\sigma (t_y) σ(tx),σ(ty)是基于矩形框中心点左上角格点坐标的偏移量; p w , p h p_w,p_h pw,ph是先验框的宽高。得到的 b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh为预测框的中心和宽高。- 置信度的解码
置信度在输出的85维中占一位,由sigmoid函数计算即可,数值在[0,1]之间。- 类别解码
COCO数据集由80类,在85维占了80维。使用sigmoid代替了Yolo2中的softmax,每一维独立代表一个类别的置信度,取消了类别之间的互斥,使网络更加灵活def decode(self, conv_output, anchors, stride): """ return tensor of shape [batch_size, output_size, output_size, anchor_per_scale, 5 + num_classes] contains (x, y, w, h, score, probability) """ # 结合输出尺寸和anchor,对神经网络的输出进行解码,得到【xywh,confidence,class】的形式 conv_shape = tf.shape(conv_output) batch_size = conv_shape[0] output_size = conv_shape[1] anchor_per_scale = len(anchors) conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, anchor_per_scale, 5 + self.num_class)) conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # 论文公式中的(tx,ty) conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # 论文公式中的(tw,th) conv_raw_conf = conv_output[:, :, :, :, 4:5] conv_raw_prob = conv_output[:, :, :, :, 5: ] """ 通过output_size,得到输出特征图对应的grid-ceil的数值,即xy_grid。-----开始-----""" # 获取xy_grid ,shape=(batch,size,size,3,2) # 其中最后一维存放的是grid的位置(0.0),(1,0)...(output_size, output_size) y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size]) x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1]) xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1) xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, anchor_per_scale, 1]) xy_grid = tf.cast(xy_grid, tf.float32) # 这里里需要弄懂 tf.newais/tf.tile 的具体用法 """ 通过output_size,得到输出特征图对应的grid-ceil的数值,即xy_grid。-----结束-----""" pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * stride # 公式中的x,y的解码 pred_wh = (tf.exp(conv_raw_dwdh) * anchors) * stride # 公式中的w,h的解码 pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1) pred_conf = tf.sigmoid(conv_raw_conf) # confidence的解码 pred_prob = tf.sigmoid(conv_raw_prob) # class的解码 return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)
1.4 yolov3的 loss
1.41
def loss_layer()loss分为3部分:xywh的loss、confidence的loss、class的loss。
- 【xywh的loss】:若为正样本,计算预测框与实际框的giou。否则不计算。后面会说明iou、giou的定义。本片博客不讲iou、giou的区别和优异。
- 【class的loss】:若为正样本,计算loss损失。
- 【 confidence的loss】:正负样本的置信度损失都参与计算,忽略样本不参与。
当前代码中的样本划分
在前面博客 dataset.py 的解析中可以了解到:
该工程分别在3个输出尺度下,计算【输出尺度下的anchor_boxes数值】和【缩小的真实框】的iou。
- 当 i o u ( a n c h o r b o x , l a b e l ) iou_{(anchorbox,label)} iou(anchorbox,label)>0.3 时,将【真实box-输入尺度上的数值,置信度,分类的onehot】保存在对用anchorbox负责维度项,否则对应label位置数值为0。
- 当所有的 i o u ( a n c h o r b o x , l a b e l ) iou_{(anchorbox,label)} iou(anchorbox,label)<0.3时,选择最大iou的【真实box-输入尺度上的数值,置信度,分类的onehot】保存到相应位置。
工程中进行正负忽略样本的划分,主要体现在这一句
- i o u ( a n c h o r b o x , l a b e l ) iou_{(anchorbox,label)} iou(anchorbox,label)>0.3。 则respond_bbox=1,respond_bgd=0【正样本】
- i o u ( a n c h o r b o x , l a b e l ) iou_{(anchorbox,label)} iou(anchorbox,label)<0.3, i o u ( p r e d , l a b e l ) iou_{(pred,label)} iou(pred,label)<0.5。则respond_bbox=0,respond_bgd=1 【负样本】
- i o u ( a n c h o r b o x , l a b e l ) iou_{(anchorbox,label)} iou(anchorbox,label)<0.3, i o u ( p r e d , l a b e l ) iou_{(pred,label)} iou(pred,label)>0.5。则respond_bbox=0,respond_bgd=0 【忽略样本】
主要体现在这一句:
# 每一个grid都会有一个conf_box(即respond_box),代表这个grid负责预测目标的置信度 # respond_bdg,代表着grid预测的是背景。具体数值可以枚举得到结果 respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < self.iou_loss_thresh, tf.float32 )论文中的样本划分
以前的博客讲述过 yolov3,正负样本以及忽略样本的选择为:
当输入尺寸为320x320时,可得到 ( 8 2 + 1 6 2 + 3 2 2 ) ∗ 3 = 4032 (8^2+16^2+32^2)*3=4032 (82+162+322)∗3=4032个先验框
预测框一共分为三种情况:正样本、负样本、忽略样本
- 正样本:
定义:假设图片中有2个物体的真实框:1. 第一个真实框与4032个先验框计算IOU,最大的先验框为正样本(一个真实框只分配一个先验框)。2. 第二个真实框在4031个先验框中,得到IOU最大的先验框为正样本。 真实框的先后顺序可以忽略。如果该最大IOU小于阈值(论文中0.5),也为正样本。
标签:正样本的检测框loss的标签为ground truth box的 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)编码后的 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th)、
类别loss的标签为类别数的one-hot形式。置信度loss的标签为1。- 忽略样本
正样本除外,与任意一个真实框的IOU大于阈值的预测框,为忽略样本,不产生任何loss。- 负样本
正样本除外,与真实框的IOU小于阈值的预测框,为负样本。只产生置信度loss,标签为0。
下面为工程中loss的的具体实现,备注的较为详细
def loss_layer(self, conv, pred, label, bboxes, anchors, stride): # 下面的部分字符代表的意义,需要参考论文label解释图 # conv: 网络最后一层卷积的输出 shape=(batch,outSize, outSize, 3*(4+1+n))。其中的框的位置信息为(tx,ty,tw,th) # pred: 将conv进行解码的结果。shape=(batch,outSize, outSize, 3, (4+1+n))。其中的框的位置信息为(bx,by,bw,bh) # label_sbbox:神经网络的标签 # true_sbboxd:神经网络标签中的位置信息 conv_shape = tf.shape(conv) batch_size = conv_shape[0] output_size = conv_shape[1] input_size = stride * output_size conv = tf.reshape(conv, (batch_size, output_size, output_size, self.anchor_per_scale, 5 + self.num_class)) conv_raw_conf = conv[:, :, :, :, 4:5] # 最后一层直接输出的置信度 conv_raw_prob = conv[:, :, :, :, 5:] # 最后一层直接输出的分类 pred_xywh = pred[:, :, :, :, 0:4] # 解码后的位置信息 pred_conf = pred[:, :, :, :, 4:5] # 解码后的置信度 label_xywh = label[:, :, :, :, 0:4] # 标签的位置信息 respond_bbox = label[:, :, :, :, 4:5] # label 的置信度 label_prob = label[:, :, :, :, 5:] # label的分类信息 # 计算giou_loss----------------------------------------------------------------------- #计算解码后的框与真实label的giou(两者尺寸大小在输入尺寸上的) giou = tf.expand_dims(self.bbox_giou(pred_xywh, label_xywh), axis=-1) input_size = tf.cast(input_size, tf.float32) bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2) # respond_bbox如果为0,giou则不参与计算 giou_loss = respond_bbox * bbox_loss_scale * (1- giou) # 计算conf_loss----------------------------------------------------------------------- # 计算解码后的框(一个grid有3个预测框)和真实框(最大有效为150个框)的iou。这里注意广播的使用 # pred_xywh.shape=(batch, out_size, out_size, 3, 4) # bboxes.shape = (batch, 150, 4) # iou.shape = (batch, out_size, out_size, 3, 150) # 3个预测框分别与150维的真实框进行的iou # max_iou.shape = (batch, out_size, out_size, 3, 1) iou = self.bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :]) max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1) # 每一个grid都会有一个conf_box(即respond_box),代表这个grid负责预测目标的置信度 # respond_bdg,代表着grid预测的是背景。具体数值可以枚举得到结果 respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < self.iou_loss_thresh, tf.float32 ) conf_focal = self.focal(respond_bbox, pred_conf) conf_loss = conf_focal * ( respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf) + respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf) ) # 计算prob_loss----------------------------------------------------------------------- prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob) giou_loss = tf.reduce_mean(tf.reduce_sum(giou_loss, axis=[1,2,3,4])) conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1,2,3,4])) prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1,2,3,4])) return giou_loss, conf_loss, prob_loss
1.41
def bbox_iou()iou的定义是两个框的交并比。
所以代码实现的思路:计算bbox1和bbox2的面积、计算交集、计算并集、计算ioudef bbox_iou(self, boxes1, boxes2): # boxes1、boxes2的形式为【xywh】。 # 计算boxes1、boxes2的面积 boxes1_area = boxes1[..., 2] * boxes1[..., 3] boxes2_area = boxes2[..., 2] * boxes2[..., 3] # 将boxes从【xywh】的形式转换到【左上角右下角】的形式 boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5, boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1) boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5, boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1) # 计算boxes1和boxes2的交集的左上角left_up、交集的右下角right_down left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2]) right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:]) inter_section = tf.maximum(right_down - left_up, 0.0) # 计算交集的边长 inter_area = inter_section[..., 0] * inter_section[..., 1] # 计算交集的面积 union_area = boxes1_area + boxes2_area - inter_area # 计算boxes1和boxes2的并集 iou = 1.0 * inter_area / union_area # 计算iou return iou
1.42
def box_giou()giou的定义是【 iou-[小凸集内不属于两个框的区域] / [最小凸集] 】。
所以代码实现的思路:计算bbox1和bbox2的面积、计算交集、计算并集、计算最小凸集,计算gioudef bbox_giou(self, boxes1, boxes2): # boxes1.shape= (batch, outSize, outSize, 3, 4) # 将boxes1和boxes2,从(x,y,w,h)的形式转化到左上角右下角的形式 boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5, boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1) boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5, boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1) # 确保左上角的坐标小于右下角的坐标 boxes1 = tf.concat([tf.minimum(boxes1[..., :2], boxes1[..., 2:]), tf.maximum(boxes1[..., :2], boxes1[..., 2:])], axis=-1) boxes2 = tf.concat([tf.minimum(boxes2[..., :2], boxes2[..., 2:]), tf.maximum(boxes2[..., :2], boxes2[..., 2:])], axis=-1) # 计算boxes1和boxes2的面积 boxes1_area = (boxes1[..., 2] - boxes1[..., 0]) * (boxes1[..., 3] - boxes1[..., 1]) boxes2_area = (boxes2[..., 2] - boxes2[..., 0]) * (boxes2[..., 3] - boxes2[..., 1]) # 计算boxes1和boxes2的交集框的左上角和右下角坐标 left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2]) right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:]) inter_section = tf.maximum(right_down - left_up, 0.0) # 计算交集框的边长 inter_area = inter_section[..., 0] * inter_section[..., 1] #计算交集框的面积 union_area = boxes1_area + boxes2_area - inter_area # 计算并集的面积 iou = inter_area / union_area # 计算iou # 计算boxes1和boxes2的最小凸集框的左上角和右下角坐标 enclose_left_up = tf.minimum(boxes1[..., :2], boxes2[..., :2]) enclose_right_down = tf.maximum(boxes1[..., 2:], boxes2[..., 2:]) enclose = tf.maximum(enclose_right_down - enclose_left_up, 0.0) # 计算最小凸集的边长 enclose_area = enclose[..., 0] * enclose[..., 1] # 计算最小凸集的面积 rate = 1.0 * (enclose_area - union_area) / enclose_area # 【最小凸集内不属于两个框的区域】与【最小凸集】的比值 giou = iou - rate # 计算giou return giou
1.42
def compute_loss()该函数,就是将3个输出模块的loss相加。
def compute_loss(self, label_sbbox, label_mbbox, label_lbbox, true_sbbox, true_mbbox, true_lbbox): with tf.name_scope('smaller_box_loss'): # self.conv_sbbox:神经网络的输出 # self.pred_sbbox:神经网络的输出的解码 # label_sbbox:神经网络的标签 # true_sbboxd:神经网络标签中的位置信息 loss_sbbox = self.loss_layer(self.conv_sbbox, self.pred_sbbox, label_sbbox, true_sbbox, anchors = self.anchors[0], stride = self.strides[0]) with tf.name_scope('medium_box_loss'): loss_mbbox = self.loss_layer(self.conv_mbbox, self.pred_mbbox, label_mbbox, true_mbbox, anchors = self.anchors[1], stride = self.strides[1]) with tf.name_scope('bigger_box_loss'): loss_lbbox = self.loss_layer(self.conv_lbbox, self.pred_lbbox, label_lbbox, true_lbbox, anchors = self.anchors[2], stride = self.strides[2]) with tf.name_scope('giou_loss'): giou_loss = loss_sbbox[0] + loss_mbbox[0] + loss_lbbox[0] with tf.name_scope('conf_loss'): conf_loss = loss_sbbox[1] + loss_mbbox[1] + loss_lbbox[1] with tf.name_scope('prob_loss'): prob_loss = loss_sbbox[2] + loss_mbbox[2] + loss_lbbox[2] return giou_loss, conf_loss, prob_loss