Python豆瓣电影爬虫实战(超详解)-----我的机器人女友《阿丽塔》
写在前面
爬虫基础详见我另一篇博客:https://blog.csdn.net/weixin_43329700/article/details/86768422
我的机器人女友----《阿丽塔》中,阿丽塔凭借其天真善良,勇敢正义,敢爱敢恨的品格俘获了众多男性观影者的心,尽管电影中间 掏心脏 的那一段略微有点夸张,但竟然也让我这个 铁石心肠 的男人动情了(还贴了一张大海报到自己房间的藏书阁),于是当晚就决定之后两周一定要实现这部电影的评论爬取。距离内地首映已经过去半个月了,直到最近一次饭桌上的契机,才让拖拉的我正式开始。
故事背景:茶楼
亲戚(文学出身):看到你之前写过篇爬虫的博客,能简单讲讲用知识点和作用机理吗?
我:嗯,像用Python爬取百度贴吧或者豆瓣等这些“价值性相对没有那么高”的网站的话,可能简单的requests/urlib + beautfulsoup/正则表达式/xpath + 少许python文件操作 知识就可以了,但如果要爬取新浪微博或者今日头条(爬虫起家)等网站的话,就需要使用Selenium或数据抓包,中间人爬虫等反爬技术来实现了(这些我也不懂,随口说的)。
亲戚:你说这些我也不懂,能一句话概括一下吗?
我: 。。。我复制粘贴比较快
亲戚:原来爬虫只是复制粘贴比较快而已,那也没什么嘛
我:。。。(内心活动)

于是为了不丢Python的脸,此处省略一万字…
题外话
最近打代码闲下来的时候读了一本叫 《群体性孤独》 名字听起来有点鸡汤,但却是一本货真价实的阐述人工智能发展与人类心理学相交合的绝顶好书,也是互联网时代技术影响人际关系的反思之作。作者为TED演讲的常驻嘉宾,麻省理工学院社会学教授,人称技术领域的 [弗洛伊德] ----- 雪莉-克莱尔。 刚好又看了《阿丽塔》,不仅思索未来机器人与人的关系,鄙人文采不精,只能借助书本序言来表达:有一天,我将习惯用文字而非声音,用数据而非抚摸,来传递感情。有一天,我们将依赖技术,超过依赖彼此,这就是真正的“机器人时代”。对于这种所谓的“机器的美好和技术的美好”,我有一种有种的不确定性和恐惧。
准备工作
- pycharm2017 (
懒于升级) - Google chrome 开发者浏览器
- 500ml 水
爬虫目的
我们需要获取的内容如下,针对每条评论而言
- 用户名
- 评分(等级)
- 评价内容
- 评价时间
- 每条评论对应的点赞数(有用数)
爬虫数据的抓取只占到整个爬虫工作的 1/3 不到,真正考验技术和需要时间投入的是突破各种反爬机制和学会使用各种非常规技术手段来获取数据 ------佚名
所以这篇博客重点分享一下我个人理解的思路和走的弯路,最后会附上源码。
实战网址: https://movie.douban.com/subject/1652592/comments?status=P
为什么选择豆瓣呢?原因如下两点:
- 评论数比较多,已经过10万了,当然也可以选择猫眼,但是前辈尝试过当爬到5万条评论的时候就无法继续进行,可能是网页的时间戳设置。作为刚入门的我还是先调简单一点的来吧。(豆瓣暂时还没有发现异步加载Ajax和JS等,动态加载的概念等一下解释哈)

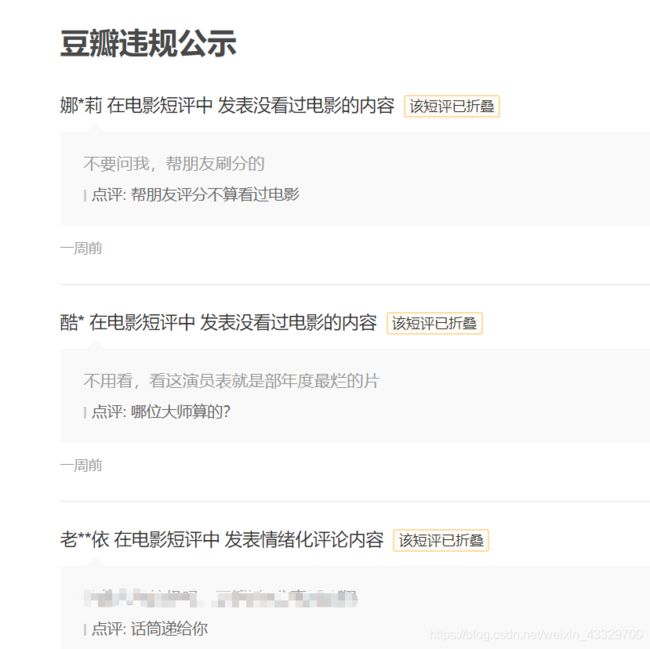
- 个人感觉豆瓣有点类似IMDB电影网,会过滤掉一些恶意灌水和无用评论如图
概念剖析—Ajax异步加载技术
所谓异步加载,就是不同步加载,这里举几个例子大家就明白了。
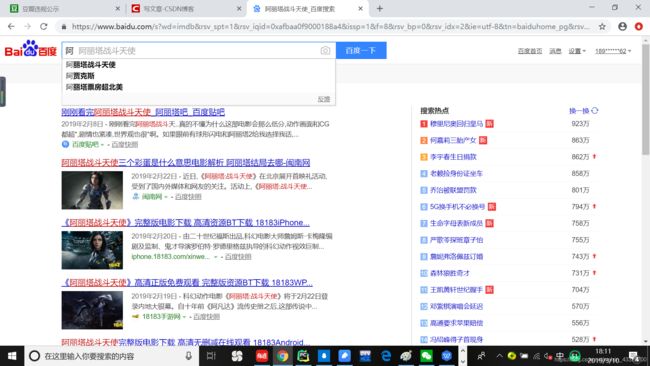
- 百度搜索:还没有按下回车就会“猴急”的弹出可能的搜索信息。才输入一个“阿”字。。
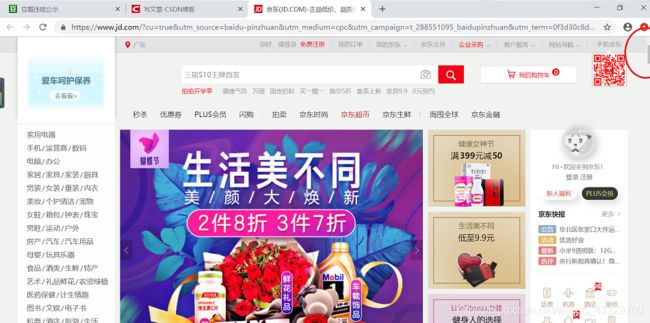
- 京东加载
我打开京东首页后等5s,如果不是异步加载的话滚动条下面的东西也应该加载完毕了。
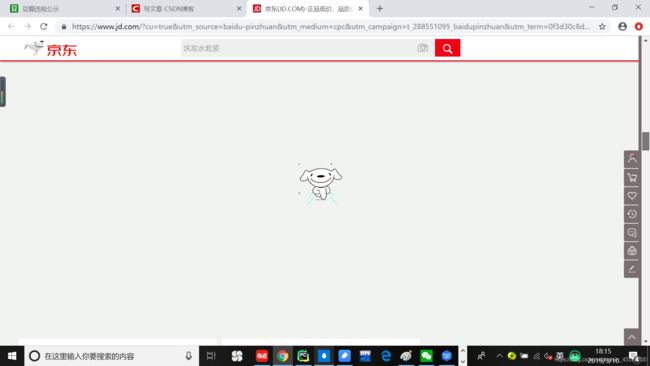
 但当我以光速拉动滚动条到中下部分的时候。。
但当我以光速拉动滚动条到中下部分的时候。。
如果上述例子还是比较难理解或者不知道异步加载有什么用的话,那么接下来这几个身边的你每天都在体验的异步加载一定会让你有更好的理解: - 知乎/朋友圈:每有一条朋友圈或知乎消息动态时,你都会看到有小小的红标提示,而不会整个知乎又刷新一次,如果没有异步加载的功劳,看知乎时每来一条消息知乎就给你自动刷新并等待,想想都烦。
- 饭店中的异步加载:冬天请一桌朋友吃饭:除非有特殊要求,否则菜大多是逐个上的,既可以通过前菜,正菜,饭后小吃水果等步骤获得最佳用餐体验,又可以避免一次上太多吃得不及时凉掉。
一句话 异步加载可以节省资源,通过滚动鼠标,键盘输入,喊服务员等触发机制来加载内容,从容不迫。
而解决异步加载问题也是爬虫的一个蛮重要的知识点,我还没学精,所以豆瓣刚好适合练手。
重要思路
循序渐进的“先抓大再抓小” 原则
说实话,这个原则将贯穿我们整个爬虫生涯,也有很多叫法,不过总的来说都是先抓大再抓小的思想。通俗来讲,就是层层定位,跟点外卖一个道理:比如广东省广州市天河区粤垦路王府天厨隔壁停车场-3楼的消防栓旁。由大标签到小标签,我们需要的数据们都是在我同一个楼层里面如图:
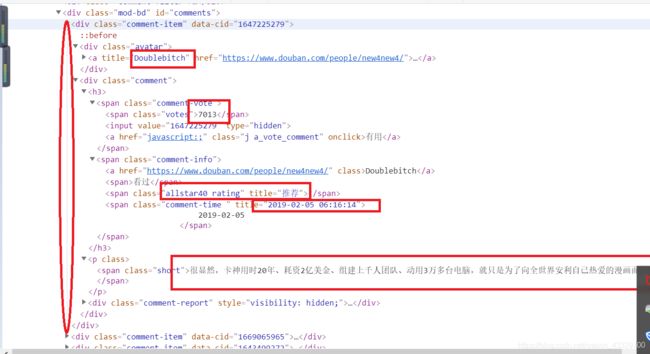
要的数据们都在标签为div,属性为comment-item里面中。
所以我们可以考虑先将整个楼层的源代码提取下来,然后再单独对每一个楼层里面的含有我们需要提取的数据的html标签进行解析(每一层楼的结构又恰好是一样的)。有些人会说为什么不直接进行提取,就是 直接小 ,直接细化到每一个标签呢?答案是这样也可以,但是会有出错的可能。解释起来比较复杂,可以自行其他大神的博客。
import requests
import lxml.html
import pandas as pd
个人感觉 lxml 库比 etree 要好用,lxml库的用法可以见我上一篇博客:
https://blog.csdn.net/weixin_43329700/article/details/86768422
url = 'https://movie.douban.com/subject/1652592/comments?start=0&limit=20&sort=new_score&status=P'
# 养成同时构造headers的习惯,有时候仅仅更换UA(User-Agent)是爬不到的,建议可以全改
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0',
'Connection': 'keep-alive','Host': 'movie.douban.com','Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
html = requests.get(url, headers=headers).content.decode()
with open('source.txt', 'w', encoding='utf-8') as f:
f.write(html)
我的headers是在这里找的
先抓大
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
print(comments_blocks) # 检查,20个对象
抓大结束
相信大家跟我一样,以前都看过不少高手写的爬虫代码,但对大神们的编写和调试代码的思路却存在不少疑惑,为什么他们就能写出这么好的代码,他们是怎么想出来的,他们要列草稿吗?感觉博客里面说得都好顺呀,轮到自己实际操作怎么就不行了,他们是怎么将学到的知识点灵活运用拼凑起来的?
在深入学习,反复演练了某位微信公众号大牛的某篇博客以后,终于有所收获,尝试推敲出他们写代码和做草稿的过程,尽管可能大神们不需要列草稿 并终于能够不看书仅借助极少量的搜索完成了这次爬虫。

翻页爬取
这次涉及翻页爬取,跟我前博客的单页爬取多页拼凑的小学生方法相比有了很大改进
建议开三个python文件
旧爬不累:适时给予良好反馈,不要写完一大段代码才去调试。
- 先试着根据先抓大再抓小的爬取一层楼的各种信息后保存到csv文件或生成表格; 循环打印出要爬取的网址(当然这里仅限有规律的网址),定义函数来实现。上述思路放第一个py文件
- 因为一般情况下每一层楼的html标签都是一样的,所以单层楼成功以后便可以尝试循环楼层爬取单页的信息,注意,这里建议还是单页。存放于第二个py文件中
- 第三个py文件:若翻页爬取时页码太多,建议先尝试爬取5页(少量页码)的数据,根据第一点的思路定义一个能够解析单个网页的函数,尝试结合第一点的函数来实现较少页数的循环爬取,因为有的网站如猫眼在翻页爬取到一定的页数的时候会出现报错,以前看过好像是网页设置,时间戳的问题。
- 前两点都尝试成功以后就可以试一下多页爬取啦,我这个实战有5000多页(真这么牛逼吗?后文揭晓),因为若前三点都成功的话,复制粘贴也就是几分钟的事情,或者直接在第三个文件那里直接将循环的终点数字改到自己想要的页码规律数
我爱学英语草稿的英文为:Draft,我这里用D1,D2,D3来表示
D1:爬取单层楼的所有信息
import requests
import lxml.html
# 尝试爬取第一页,第二页时改动url即可
url = 'https://movie.douban.com/subject/1652592/comments?start=0&limit=20&sort=new_score&status=P'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0',
'Connection': 'keep-alive','Host': 'movie.douban.com','Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
html = requests.get(url, headers=headers).content.decode() # 这里不用用cookies反倒可以
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
print(comments_blocks) # 检查,20个对象
# 爬取单层楼(以第一层为例),所以从content中抽出第一个对象
first_block = selector.xpath('//div[@class="comment-item"]')[0]
print(first_block) # 检查,一个对象
# 以下均为第一层楼的各种信息
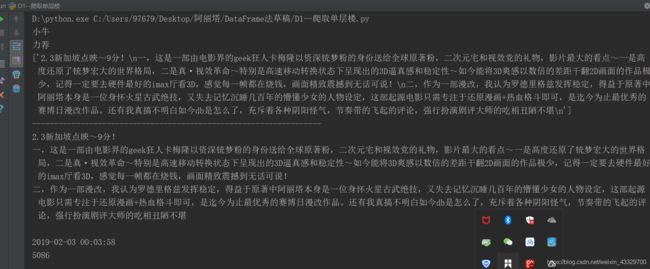
# 用户名
username = first_block.xpath('div[1]/a[1]/@title')[0]
print(username) # ok
# 星级,发现爬不出来,因为是在span标签中的属性中的某一部分。。只好尝试爬取属性title的值来表示星级
# 博客配图
stars = first_block.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
print(stars) # ok
# 评论内容,打印两种形式的给大家对比看一下,我的第一篇博客关于xpath的个人理解已经分享得比较详细了,
# 暂时不理解xpath可以点击连接跳转哈
content_list = first_block.xpath('div[2]/p/span/text()')
content_string = first_block.xpath('div[2]/p/span')[0].text
print(content_list)
print('-'*66) # 分割线的好习惯
print(content_string)
# 评论时间
time = first_block.xpath('div[2]/h3/span[2]/span[3]/@title')[0]
print(time) # ok
# 每条评论对应的有用数
useful_num = first_block.xpath('div[2]/h3/span[1]/span')[0].text
print(useful_num)
结果
D2:循环爬取单页(20层楼)
import requests
import lxml.html
import pandas as pd
url = 'https://movie.douban.com/subject/1652592/comments?start=0&limit=20&sort=new_score&status=P'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0',
'Connection': 'keep-alive','Host': 'movie.douban.com','Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
html = requests.get(url, headers=headers).content.decode() # 这里不用用cookies反倒可以
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
#print(comments_blocks) # 检查,20个对象
# 循环爬取整页的每一个楼层的所需要的信息
# 创建存储爬得信息的容器,个人偏爱DataFrame
result = pd.DataFrame()
for each in comments_blocks:
# 用户名
username = each.xpath('div[1]/a[1]/@title')[0]
# 星级
stars = each.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
# 评论内容
content = each.xpath('div[2]/p/span')[0].text
# 评论时间
time = each.xpath('div[2]/h3/span[2]/span[3]/@title')[0]
# 每条评论对应的有用数
useful_num = each.xpath('div[2]/h3/span[1]/span')[0].text
data = {
'用户名': [username],
'星级': [stars],
'评论内容': [content],
'评论时间': [time],
'有用数': [useful_num]
}
cache = pd.DataFrame(data)
result = pd.concat([result, cache])
result.to_csv('first_page.csv')
D3:循环爬取几页
找寻网址规律: 既然是循环爬取,那就得循环翻页,我们先来观察一下网址随页码变化的规律
首页:

第二第三页
![]()
![]()
start参数公差为20,正好是每页评论的数量
于是定义一个能够循环网址的函数,里面涉及的格式化和具体思路可以参照这篇快速创建文件夹提高文书效率的博客哈
https://blog.csdn.net/weixin_43329700/article/details/88247524
init_url = 'https://movie.douban.com/subject/1652592/comments?start={}&limit=20&sort=new_score&status=P'
# 先试一下50页,也就是1万条评论
def format_url(init_url):
urls = []
for i in range(0,1000,20):
urls.append(init_url.format(i))
return urls# ok
# 循环爬取部分页数的时候,不禁会发现每一页的操作都要两个步骤:获取网页源代码和解析网页,
# 即获取每一页所需要的数据并存储到DataFrame当中
# 每一页的操作都相同,那就自然能够想起来应该需要函数来代替重复的工作
# 循环爬取整页的每一个楼层的所需要的信息
# 创建存储爬得信息的容器,个人偏爱DataFrame
# 定义能够解析单个页面的函数
def parse_page(url, headers):
result = pd.DataFrame()
html = requests.get(url, headers=headers).content.decode() # 这里不用用cookies反倒可以
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
for each in comments_blocks:
# 用户名
username = each.xpath('div[1]/a[1]/@title')[0]
# 星级
stars = each.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
# 评论内容
content = each.xpath('div[2]/p/span')[0].text
# 评论时间
time = each.xpath('div[2]/h3/span[2]/span[3]/@title')
# 每条评论对应的有用数
useful_num = each.xpath('div[2]/h3/span[1]/span')[0].text
data = {
'用户名': [username],
'星级': [stars],
'评论内容': [content],
'评论时间': [time],
'有用数': [useful_num]
}
cache = pd.DataFrame(data)
result = pd.concat([result, cache])
return result
要想将上述定义好的两个函数很好的连接在一起,可以放到一个主函数中
def main():
final_result = pd.DataFrame()
init_url = 'https://movie.douban.com/subject/1652592/comments?start={}&limit=20&sort=new_score&status=P'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0',
'Connection': 'keep-alive', 'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
urls = format_url(init_url)
for url in urls:
res = parse_page(url, headers=headers)
final_result = pd.concat([final_result, res])
time.sleep(5.2)
return final_result
if __name__ == '__main__':
final_result = main()
final_result.to_csv('50 pages.csv')
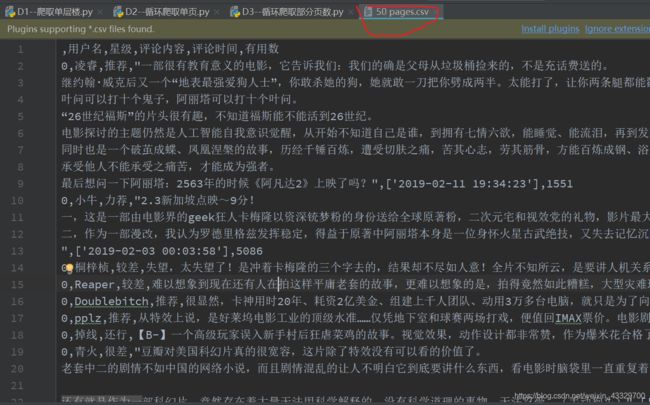
大刀阔斧
既然50页都成功了,那就直接试一下最大页数爬取

import requests
import lxml.html
import pandas as pd
import time
def format_url(init_url):
urls = []
for i in range(0,104000,20): # 唯一改动处
urls.append(init_url.format(i))
return urls
def parse_page(url, headers):
result = pd.DataFrame()
html = requests.get(url, headers=headers).content.decode()
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
for each in comments_blocks:
# 用户名
username = each.xpath('div[1]/a[1]/@title')[0]
# 星级
stars = each.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
# 评论内容
content = each.xpath('div[2]/p/span')[0].text
# 评论时间
time = each.xpath('div[2]/h3/span[2]/span[3]/@title')
# 每条评论对应的有用数
useful_num = each.xpath('div[2]/h3/span[1]/span')[0].text
data = {
'用户名': [username],
'星级': [stars],
'评论内容': [content],
'评论时间': [time],
'有用数': [useful_num]
}
cache = pd.DataFrame(data)
result = pd.concat([result, cache])
return result
# 要想将上述定义好的两个函数很好的连接在一起,可以放到一个主函数中
def main():
final_result = pd.DataFrame()
init_url = 'https://movie.douban.com/subject/1652592/comments?start={}&limit=20&sort=new_score&status=P'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0',
'Connection': 'keep-alive', 'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
urls = format_url(init_url)
for url in urls:
res = parse_page(url, headers=headers)
final_result = pd.concat([final_result, res])
time.sleep(5.2)
return final_result
if __name__ == '__main__':
final_result = main()
final_result.to_csv('100000_comments.csv')
经过“漫长的”等待,结果如图
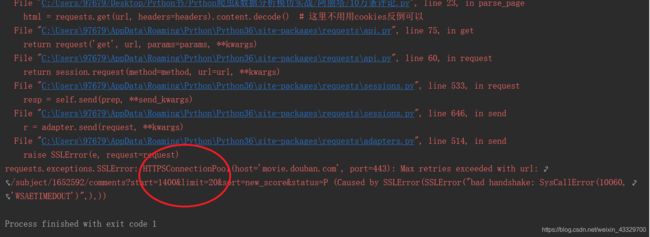
翻译一下:
超过最大重试与url,大意为start参数到1400就已经不行了?
试一下把1400直接输进网址
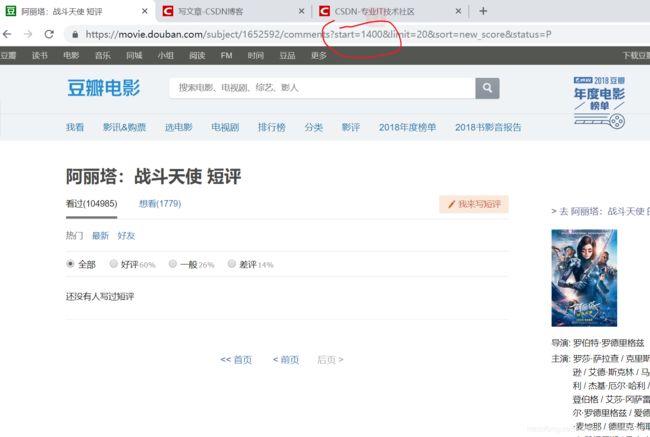
???按道理不是应该至少有 100000/20= 5000页的吗

于是我试着把start的参数改成小于1400的,二分法直接取一半,700
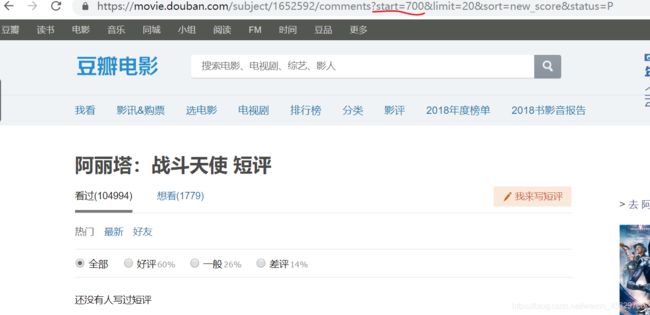
还不行?500试一下
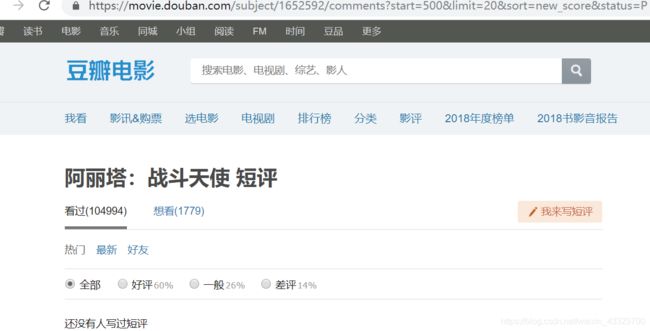
突然发现starts参数为500的时候就是我第一次尝试翻页爬取的时候range函数里面设置的最大值,于是果断点击前一页
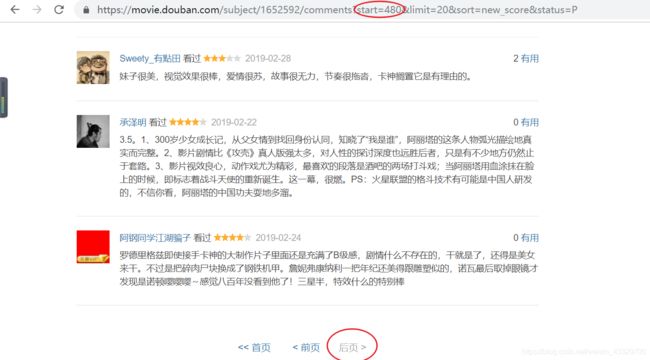
原来480已经是最后一页了,说好的100000评论5000多页呢?后来询问在豆瓣评论过电影的朋友才发现原来一开始的 看过 显示的十万三千多人,人数并不代表评论数。听到这个消息时差点哭出声:

唉,只好安慰自己,理解思路并体会到爬虫的乐趣就行,
于是打开文件夹看看爬取的成果
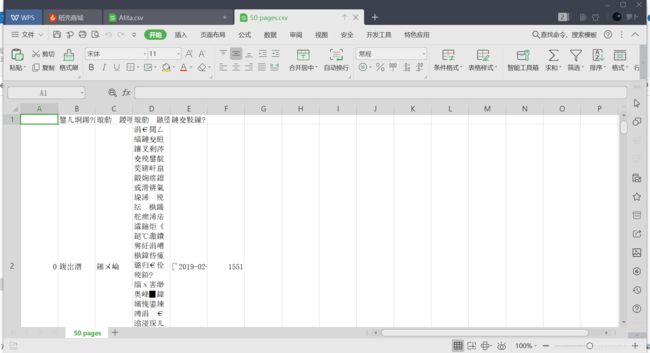
不仅乱码格式也不对,真的是双重打击

知道是编码格式不对,但是pandas库中的to_csv()没有办法显示增加编码格式
https://blog.csdn.net/fwj_ntu/article/details/78563962
这篇是万能的csv文件打开乱码解决办法
也可改成用csv库的方法,csv库的方法我在这篇博客也有介绍:
https://blog.csdn.net/weixin_43329700/article/details/86768422
于是循环爬取单页的草稿就变成
result_list = [] 改动点
for each in comments_blocks:
# 用户名
username = each.xpath('div[1]/a[1]/@title')[0]
# 星级
stars = each.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
# 评论内容
content = each.xpath('div[2]/p/span')[0].text
# 评论时间
time = each.xpath('div[2]/h3/span[2]/span[3]/@title')[0]
# 每条评论对应的有用数
useful_num = each.xpath('div[2]/h3/span[1]/span')[0].text
改动点
result = {
'用户名': [username],
'星级': [stars],
'评论内容': [content],
'评论时间': [time],
'有用数': [useful_num]
}
result_list.append(result) 改动点
改动点
with open('Alita.csv', 'w', encoding='utf-8') as f:
fieldnames = ['用户名', '星级', '评论内容', '评论时间', '有用数']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # 告诉Python为这个csv文件创造三个列空间
writer.writerows(result_list)
战战兢兢地点开用csv模块的创建的这个csv文件,结果还是出现了乱码,不过格式规整多了。
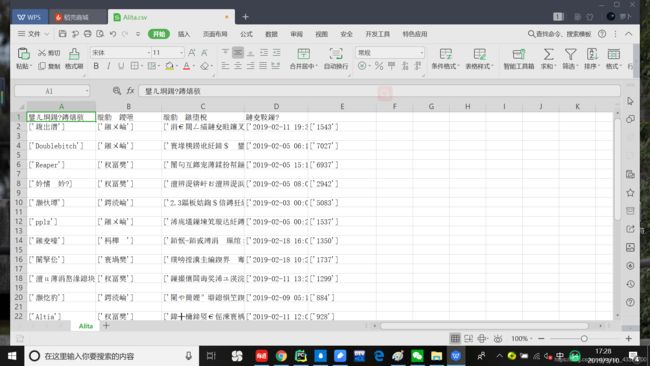
尝试把编码格式改为 ‘gb18030’ 后,终于成功
with open('Alita.csv', 'w', encoding='gb18030') as f:
fieldnames = ['用户名', '星级', '评论内容', '评论时间', '有用数']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # 告诉Python为这个csv文件创造三个列空间
writer.writerows(result_list)
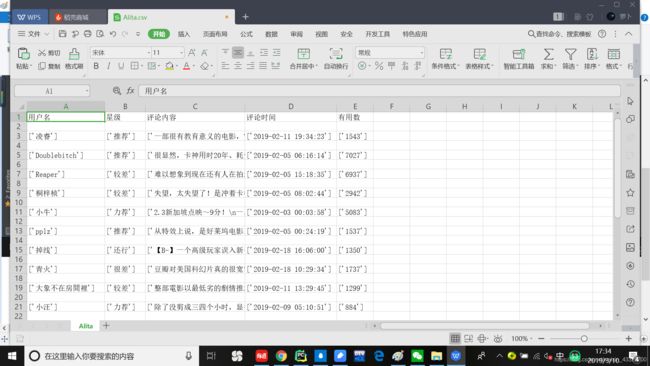
这里不少同学可能会疑惑,怎么会突然想到改成 ‘gb18030’ 呢?
原因有两个:
6. 以前积累过的编码格式错误的笔记,可以改几个尝试一下,改成
这个的成功率是我试过最高的。或者参考这篇博文:https://blog.csdn.net/qiqiaiairen/article/details/51535262
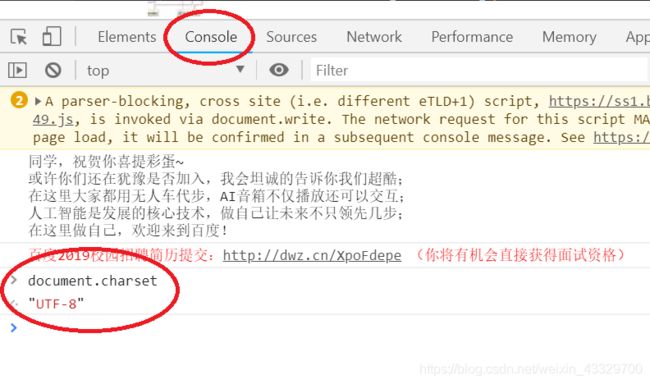
7. 用csv模块,且在windows中创建的文件,使用了UTF-8打开文件的话,有一定几率会出现乱码。还有一种便是通过Chrome浏览器查找当前页面的编码格式,个人觉得这个还是蛮有用的,出奇不意会帮得上忙。操作输入如下图:
8. 
好,大功告成,附上完整的代码
import requests
import lxml.html
import re
import pandas as pd
import time
# 定义一个能够遍历规律网址的函数
def format_url(init_url):
urls = []
for i in range(0,1000,20):
urls.append(init_url.format(i))
return urls
# 定义能够解析单个页面的函数
def parse_page(url, headers):
result = pd.DataFrame()
html = requests.get(url, headers=headers).content.decode()
selector = lxml.html.fromstring(html)
# 先抓大再抓小的抓大:每条评论的整个楼层
comments_blocks = selector.xpath('//div[@class="comment-item"]')
for each in comments_blocks:
# 用户名
username = each.xpath('div[1]/a[1]/@title')[0]
# 星级
stars = each.xpath('div[2]/h3/span[2]/span[2]/@title')[0]
# 评论内容
content = each.xpath('div[2]/p/span')[0].text
# 评论时间
time = each.xpath('div[2]/h3/span[2]/span[3]/@title')
# 这里加上[0]的话可能会报错
# 每条评论对应的有用数
useful_num = each.xpath('div[2]/h3/span[1]/span')[0].text
data = {
'用户名': [username],
'星级': [stars],
'评论内容': [content],
'评论时间': [time],
'有用数': [useful_num]
}
cache = pd.DataFrame(data)
result = pd.concat([result, cache])
return result
# 要想将上述定义好的两个函数很好的连接在一起,可以放到一个主函数中
def main():
final_result = pd.DataFrame()
init_url = 'https://movie.douban.com/subject/1652592/comments?start={}&limit=20&sort=new_score&status=P'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0',
'Connection': 'keep-alive', 'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/subject/1652592/comments?status=F',
'Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
urls = format_url(init_url)
for url in urls:
res = parse_page(url, headers=headers)
final_result = pd.concat([final_result, res])
time.sleep(5.2)
return final_result
if __name__ == '__main__':
final_result = main()
final_result.to_csv('Pages.csv')
想要集体替换掉被提取内容的某些字符串的话可以考虑用excel,pandas库等这里就不一一赘述了。总的来说这次爬虫练习只能给到自己70分。

结果分析
因为已经有不少文章是关于爬虫豆瓣,ILDB,猫眼电影等的分析了,还有精美的图片,所以这里就不展示了。
这里有一个新奇的情感分析库可以推荐一下:

根据你描述的中文给出你的情感指数,精确的小数位数有点可怕。
写在后面
鄙人原本对整天对着电脑的工作和学习比较厌恶,对英语比较有兴趣,接触Python的原因也是比较奇葩:就因为Python这个名字好听,仅此而已没有别的什么说python潮流简单易上手。而爬虫也让我对计算机行业的感情由轻微厌恶 ------> 喜欢。虽然现在还很菜,但是兴趣和态度起来了,接下来就可以用心学习钻研了。所以多多学习还是有好处的,没准能带来学这样东西以外的收获。(英语转Python这个跨度也令我身边不少朋友称奇哈哈)
一本好书:Netflix公司(对就是那个美国流媒体巨头、世界最大的收费视频网站网飞,快破产的时候“随便”弄了部剧叫 纸牌屋),与 Facebook,亚马逊,Google并成为 “硅谷四剑客”。 其人力资源总监写的 《奈飞文化手册》 一书中深刻解密了 Netflix成功的原因以及对技术时代下公司经营的一些思考(程序员或者工程师们都才华横溢,却往往因为沟通或者合作的问题无法发挥出1+1>2的作用)。其中最令我深刻的一句话便是 “我们公司的工程师们及管理层都对数据有着狂热的感情,但我始终觉得数据只能辅助人们做决策,,人们会对自己整理的数据持有偏见。人们总是倾向于人为自己的数据优于他人的数据,所以市场部用一批数据,销售部用一批数据,小心看起来很好实际上没用的数据,做决定最终需要的还是判断力已全局视野” 这启发我应该在提升数据获取能力的同时也要专注于提高分析能力,不应该为了做出漂亮的图表而打代码,应该去往更深层次,更贴近问题本质与客户需求方面来考虑(词穷…)
作为资深影迷的我,以前在去电影院看电影前总是会查找多方渠道的评价与电影分析,冷静分析性价比之类的才去,导致真的错过太多的好电影(对于自己来说的好电影),所以以后看中了哪部片子,简单想一下如果是真的想去看 就不墨迹直接去。
