构建适合组织的可观测性能力,用「实战」破解“网络谜案”!
CNCF 在云原生的定义[1]中,将可观测性(Observability)明确为一项必备要素。因此,使用云原生应用架构,享受其带来的效率提升时,不得不面对的是如何构建匹配的可观测性能力。发展到今日,可观测性在开源和商业上已经有了大量的解决方案拼图,CNCF Cloud Native Landscape[2] 中相关内容更是多达上百个。本文由云杉网络总结了可观测性能力的成熟度模型,希望能为组织选择适合自身的可观测性方案提供指导。
同时欢迎您预约本期“原力释放 云原生可观测性分享会”,由云杉网络高级产品经理李倩分享《高清云网可观测之全链路追踪实战》议题,用「实战」带领大家一起破解“网络谜案”!
扫码预约直播,一起围观“破案现场”!
对云网络的诊断如何才能不依赖云服务商就能快速定位问题边界?
如何解释客户端的高时延和服务端的风平浪静?
K8s Service NAT 前后的流量如何追踪?
VXLAN、IPIP、GRE 等层层隧道封装的流量如何追踪?
穿过云上云下错综复杂的各类网关流量如何追踪?

1.0 支柱:基础的可观测性
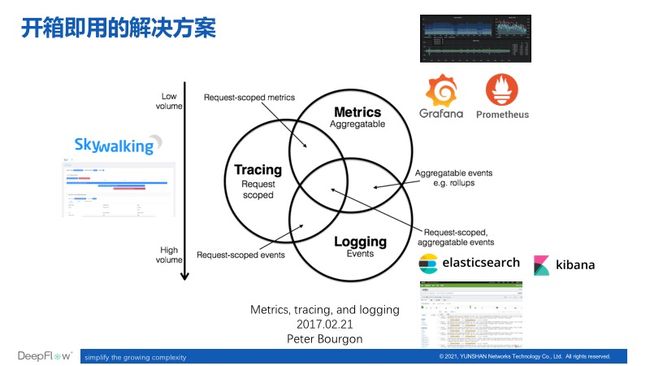
时间回到 2017 年,Peter Bourgon 一篇博文总结了可观测性的三大支柱:指标(Metrics)、追踪(Tracing)、日志(Logging)[3]。此后几年间这个观点受到了业内的广泛认可,发展为对可观测性能力的基本要求,并且每一个方面都有了众多成熟的解决方案。例如,开源组件中就有聚焦于 Metrics 的 Prometheus、Telegraf、InfluxDB、Grafana 等,聚焦于 Tracing 的 Skywalking、Jaeger、OpenTracing 等,聚焦于 Logging 的 Logstash、Elasticsearch、Loki 等。
构建三大支柱是可观测性能力建设的初级阶段,基于开源组件很容易为每个业务系统搭建一套开箱即用的可观测性设施。这个阶段面临的主要问题有两个:
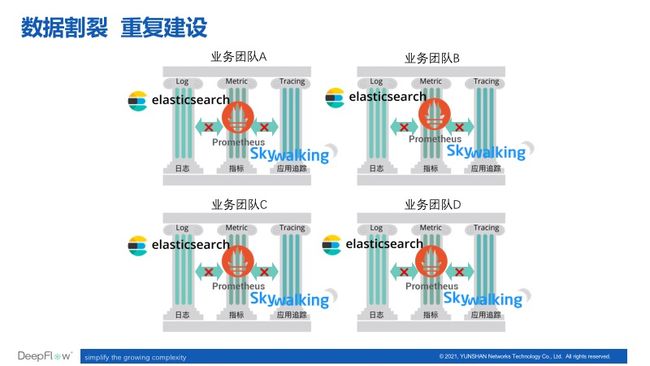
1)数据孤岛:当团队面临一个业务故障时,可能需要频繁跳转于 Metrics、Tracing、Logging 系统之间,由于这些系统上的数据并没有很好的关联打通,整个问题排查流程高度依赖人工的信息衔接,有些时候可能还需要协调负责不同系统的不同人员参与问题排查。
2)建设冗余:由于观测数据的采集依赖 StatsD 插桩、Tracing SDK 插桩、Logging SDK 插桩,处于这个阶段的可观测性能力一般以业务开发团队为核心驱动构建,业务部门只会构建服务于自身的观测设施,导致在不同业务部门之间重复构建。另一方面,开箱即用的方案往往存在扩展性问题,难以成长为面向所有业务提供的基础服务。
2.0 服务:统一的可观测性
当观测数据的打通和观测系统的优化在日常运维工作中越来越频繁时,意味着我们需要准备提升可观测性能力到下一个等级了。这个等级的可观测性以服务为核心,由基础设施团队和业务开发团队协作。基础设施团队需要打造一个面向所有业务的统一可观测性平台,提供 Metrics、Tracing、Logging 数据的采集、存储、检索基础设施,并支持将不同类型的数据进行关联以消除孤岛。业务开发团队作为消费方,利用统一 SDK 在此平台上注入观测数据。

首先我们面临的问题是采集时如何关联不同类型的数据,OpenTelemetry[4] 通过标准化数据的采集和传输期望解决此问题。遵循 OpenTelemetry 规范,我们可以看到 Metrics 可通过 Exemplars 关联至 Trace,Trace 通过 TraceID、SpanID 关联至 Log,Log 通过 Instance Name、Service Name 关联至 Metrics。OpenTelemetry 社区已经完成了 Tracing 规范的 1.0 版本,并计划在 2021 年完成 Metrics 规范、2022 年完成 Logging 规范。这是一个高速发展中的项目,但得到了业界大量的关注和认可,也能看出可观测苦数据孤岛久矣!
其次,我们还面临着不同类型数据的存储问题,遗憾的是这方面 OpenTelemetry 并未涉及。Metrics 和 Trace/Log 数据有着较大的区别,通常采用 TSDB(如 InfluxDB)存储 Metrics 数据,Search Engine(如 Elasticsearch)存储 Trace/Log 数据。为了提供一项统一的可观测平台服务,系统需要具备水平扩展能力,但 TSDB 由于高基问题通常难以用于存储精细至每个微服务、API 的指标数据,而 Search Engine 由于全文索引问题通常会带来高昂的资源开销。解决这两个问题一般考虑选择基于稀疏索引的实时数仓,例如 ClickHouse 等,并通过对象存储机制实现冷热数据分离。
除此之外,观测系统成为统一服务的更大挑战还在于,它需要比业务系统有更强的水平扩展能力。例如,在混合云、边缘云等复杂环境中,观测系统应该能扩展至多个 Region/AZ 以及边缘机房,使得可全链路监控复杂业务。
解决了数据的采集和存储问题后,基础设施团队可将观测系统作为一项统一服务向业务开发团队开放,但这个阶段的可观测性依然有两个问题未能解决:
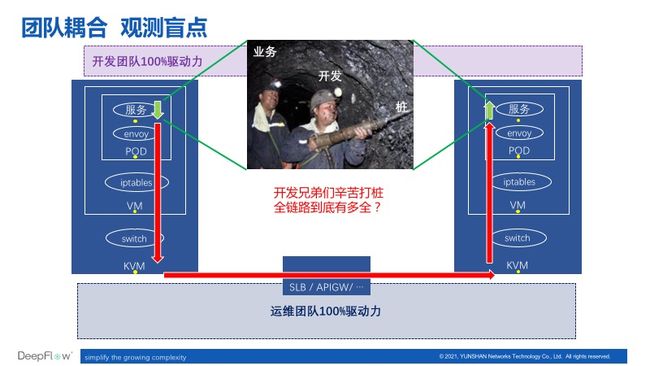
1)团队耦合:观测能力作为一项服务(Service),必须由业务开发团队主动调用(Call),但业务保障的 KPI 由运维团队承担,并不直接落在开发团队上。在云原生架构应用的高速迭代背景下,是否每一次业务上线都能做到对观测服务的 100% 调用?即使开发团队能严守规则,整个事情的主动权也并没有落在运维团队手上。另外站在开发团队的视角,业务代码中不得不插入各式各样的由运维团队强制要求的 SDK 调用。
2)观测盲点:应用架构中涉及到的所有软件服务并不是每一行代码都由开发团队编写,因此侵入式的代码打桩手段势必会遇到观测盲点。例如两个微服务通信路径上的 API 网关、iptables/ipvs、宿主机 vSwitch、SLB、Redis 缓存服务、MQ 消息队列服务等,都无法通过插码的方式植入式获取观测收据。
3.0 原力:内生的可观测性

当开发与运维的团队的耦合问题开始制约组织发展,当基础服务的观测盲点问题开始制约业务 SLO 进一步提升时,意味着我们需要再一次提升可观测性能力等级了。
既然每一个云原生应用都需要可观测性能力,那么我们能否让基础设施内生地提供这样的能力,它就像原力(The Force)一样,无处不在。因此,方向明朗了:如果业务代码中不插入任何一行观测代码,我们能获得多少可观测能力?这个阶段的主要挑战来自于数据的采集和存储。
如何实现基础设施内生的应用观测数据采集能力?一种 Green Field 的思路是通过服务网格实现。我们可以看到,无论是纯正的服务网格如 Istio,还是更激进的应用运行时如 Dapr,都从设计之初就考虑了可观测性能力。假如微服务之间的访问路径都经过服务网格,那么可以从基础设施层面解决观测数据的采集问题。这里的主要挑战来自于对应用架构的改变——应用需全部迁移到服务网格架构。但即使依靠服务网格,也依然会存在中间件、数据库、缓存、消息队列等系统上的观测盲点。或许等到服务网格像 TCP 一样——变成网络协议栈的一层时,我们能通过这种方法实现内生的可观测性。
另一种 Brown Field 的解决思路是借助 BPF 零侵入、无处不在的观测能力。BPF 是一项内生于 Linux Kernel 中的观测技术,经典 BPF(cBPF)主要聚焦于网络流量的过滤获取,但在 Kernel 4.X 版本中已经得到了巨大的增强(eBPF)。利用 eBPF,无需修改业务代码、无需重启业务进程,可端到端地观测每一个 TCP/UDP(kprobe)、HTTP2/HTTPS(uprobe)函数调用;利用 cBPF,从网络流量中提取每一次服务访问的 Metrics、Tracing、Logging 观测数据,可全链路地观测服务间通信在流经虚拟机网卡、宿主机网卡、SLB 等中间设备时的性能数据。随着 Linux Kernel 4.X 越来越广泛的应用,我们看到云监控泰斗 Datadog 最近刚刚发布了基于 eBPF 的 Universal Service Monitoring(USM)零侵入监控能力[5],国内阿里云 ARMS 团队也在最近发布了基于 eBPF 的零侵入监控产品 Kubernetes 监控[6],开源社区方面 Skywalking v9 也开始关注 eBPF[7]。但请注意仅仅依靠 eBPF 会存在依赖 4.X Linux 内核的问题,导致有可能退化为一种 Green Field 方案。原力需要无处不在,网络流量早已无处不在!

数据存储的挑战实际上和全链路监控相关。从应用代码出发的可观测性往往仅考虑业务和应用层面的问题,网络、基础设施成为盲点。在中间路径上(API 网关、iptables/ipvs、宿主机 vSwitch、SLB、Redis 缓存服务、MQ 消息队列服务)采集到的观测数据如何能与应用和业务层面的观测数据打通,需要我们构建一个面向微服务的知识图谱。通过与云平台 API、K8s apiserver 以及服务注册中心同步资源和服务信息,为每个微服务构建区域 / 可用区、VPC/ 子网、云服务器 / 宿主机、容器集群 / 节点 / 工作负载、服务名 / 方法名等多维度知识图谱信息,作为数据标签附加于观测数据之上,从而打通全链路上各个层面的 Metrics、Tracing、Logging 数据。
当你到达第 3 级时,可观测性已经成为了云基础设施上内生的能力,像原力一样,它蕴含在已运行的每个应用系统、以及未来会新增的每个应用系统中,是一项与生俱来的基本能力,这项能力无需依赖于在业务代码中的“调用”来触发,它就在那里。
云杉网络 DeepFlow 在可观测性 3.0 等你。May the force be with you!

引用链接
[1]
云原生的定义: https://github.com/cncf/toc/blob/main/DEFINITION.md
[2]CNCF Cloud Native Landscape: https://landscape.cncf.io/images/landscape.pdf
[3]指标(Metrics)、追踪(Tracing)、日志(Logging): https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
[4]OpenTelemetry: https://opentelemetry.io/docs/reference/specification/overview/
[5]基于 eBPF 的 Universal Service Monitoring(USM)零侵入监控能力: https://www.datadoghq.com/blog/universal-service-monitoring-datadog/
[6]基于 eBPF 的零侵入监控产品 Kubernetes 监控: https://help.aliyun.com/document_detail/260777.html
[7]Skywalking v9 也开始关注 eBPF: https://github.com/apache/skywalking/discussions/8241

![]()
你可能还喜欢
点击下方图片即可阅读
大妈都能看懂的 GitOps 入门指南
2022-07-04

Cilium Masquerading 故障排查记录
2022-07-01

KubeSphere 3.3.0 发布:全面拥抱 GitOps
2022-06-29

Docker 火了:主机外可直接访问映射到 127.0.0.1 的服务
2022-06-25


云原生是一种信仰
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?