【云原生训练营】模块八 Kubernetes 生命周期管理和服务发现
生命周期管理和服务发现
- 1、深入理解Pod的生命周期
-
- 管理Pod的生命周期
- pod创建的时候,经历了哪些过程?
- initC
- Pod状态计算细节
- 如何确保Pod的高可用
- 基于Taint的Evictions
- 健康探针
- 前置后置Post-start&Pre-stop钩子
- 容器应用可能面临的进程中断
- 作业
- 2、服务发现SVC
- 3、微服务架构下的高可用挑战
-
- 负载均衡
- DNS负载均衡
- 负载均衡技术概览
- 4、Service对象
-
- Endpoint对象
- Service类型
- 5、kube-proxy
-
- kube-proxy原理
- iptables与ipvs区别
- 6、域名服务
-
- Service中的Ingress对比
1、深入理解Pod的生命周期
管理Pod的生命周期
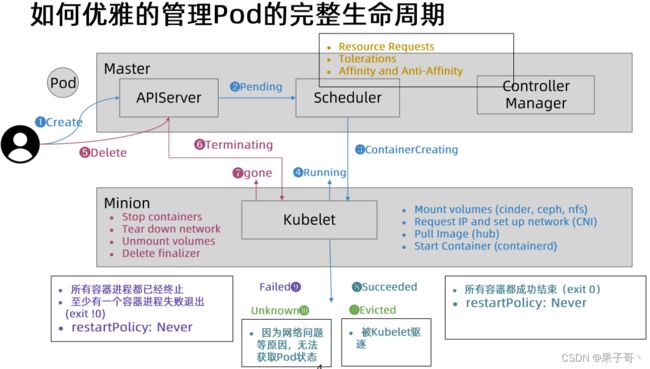
pod创建的时候,经历了哪些过程?

首先kubectl向kubeapi接口发送指令后,kubeapi会调度到Kubelet(这过程通过etcd存储),Kubelet去操作CRI,CRI完成容器的初始化,在初始化的过程中会先启动一个Pause的基础容器(负责网络以及存储卷共享),然后进行多个init C初始化,进入Main C 主容器运行,Main C退出时可执行STOP,执行完整个Pod生命周期结束。
readlines为什么不是顶头,靠左端?因为允许定义在容器运行多少秒以后再进行探测
readlines:根据命令、TCP连接、HTTP协议获取状态,判断这个服务是否已可用,如果可用再把运行状态改成Running,能暴露出去提供外网访问
Liveness:它会伴随整个Main C主容器的生命周期,当主容器里面的进程跟Liveness探测出现不一致的情况时,主容器有问题不能正常提供外网访问,然后就执行重启或删除命令。
initC
Pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的Init容器
Init容器与普通的容器非常像,除了如下两点:
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败,Kubernetes会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的restartPolicy为Never,它不会重新启动
因为Init容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
- 它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的,因此可以再Init C初始化过程中,提前创建出来,然后Main C可以不包含这些文件,又可以通过init C引用
- 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、python或dig这样的工具。
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
- Init容器使用LinuxNamespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问Secret的权限,而应用程序容器则不能。
- 它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
init C还可以用于探测mysql是否正常,如果正常则退出init容器,启动Apache。
而不会因为Apache+PHP启动稍微快一点,mysql延迟启动导致整个pod不断重启。
(针对依赖性比较强的服务而言)
Pod的状态机

Pod Phase
- Pending
- Running
- Succeeded
- Failed
- Unknown
kubectl get pod显示的状态信息是由 podstatus 的conditions和phase计算出来的 - 查看pod细节
kubectl get pod $podname -o yaml - 查看pod相关事件
kubectl describe pod

Pod状态计算细节

如何确保Pod的高可用
避免容器进程被终止避免Pod被驱逐
-
设置合理的resources.memory limits防止容器进程被OOMKill。
-
设置合理的emptydir.sizeLimit并且确保数据写入不超过emptyDir的限制,防止Pod被驱逐。
-
Pod的QoS分类

-
定义Guaranteed类型的资源需求来保护你的重要Pod.
-
认真考量Pod需要的真实需求并设置limit和resource,这有利于将集群资源利用率控制在合理范围并减少Pod被驱逐的现象。
-
尽量避免将生产Pod设置为BestEffort,但是对测试环境来讲,BestEffort Pod能确保大多数应用不会因为资源不足而处于Pending状态。
-
Burstable 适用于大多数场景。
基于Taint的Evictions

健康探针

- livenessProbe(initialDelayseconds)
也可以通过startupProbe,它是在- livenessProbe之前进行的探针。 - initialDelay比较不灵活,会出现过短积累健康检查的资源,过长会导致原本有问题的没探测出来。
- startup是在容器启动的时候执行
有时候会存在特殊情况,比如服务A启动时间很慢,需要60s。这个时候如果还是用上面的探针就会进入死循环,因为上面的探针10s后就开始探测,这时候我们服务并没有起来,发现探测失败就会触发restartPolicy。这时候有的朋友可能会想到把initialDelay调成60s不就可以了?但是我们并不能保证这个服务每次起来都是60s,假如新的版本起来要70s,甚至更多的时间,我们就不好控制了。有的朋友可能还会想到把失败次数增加。这在启动的时候是可以解决我们目前的问题,但是如果这个服务挂了呢?如果failureThreshold=1则10s后就会报警通知服务挂了,如果设置了failureThreshold=5,那么就需要5*10s=50s的时间,在现在大家追求快速发现、快速定位、快速响应的时代是不被允许的。在这时候我们把startupProbe和livenessProbe结合起来使用就可以很大程度上解决我们的问题。
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 1
initialDelay:10
periodSeconds: 10
startupProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 10
initialDelay:10
periodSeconds: 10
上面的配置是只有startupProbe探测成功后再交给livenessProbe。我们startupProbe配置的是10s*10+10s,也就是说只要应用在110s内启动都是OK的,而且应用挂掉了10s就会发现问题
探针属性(可以设置探针的时间)
- initialDelaySeconds (默认是0秒,最小值是0),推迟多久才做探活
- periodSeconds(默认是10秒,最小值是1秒),探活周期
- timeoutSeconds(默认是1秒,最小值是1秒),探活多久没返回算超时
- successThreshold(默认是1秒,且出现必须设置,最小为1秒),探测多少次才认为是success[200,400)
- failureThreshold(默认是3秒,最小值是1秒),探测多少次才认为是failure
ReadinessGates(可以通过k8s外部控制器控制是否ready)

前置后置Post-start&Pre-stop钩子
Post-start和Pre-Stop

容器关闭过程:pre-stop执行完后,先发sigterm(pod会处在terminating状态),再发sigkill
postStart示例:
apiVersion: v1
kind: Pod
metadata:
name: poststart
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
pre-stop示例:
apiVersion: v1
kind: Pod
metadata:
name: prestop
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
preStop:
exec:
command: [ "/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done" ]
terminating状态60秒后会自动退出示例:
apiVersion: v1
kind: Pod
metadata:
name: no-sigterm
spec:
terminationGracePeriodSeconds: 60
containers:
- name: no-sigterm
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
terminationGracePeriodSeconds

Terminating Pod的误用
bash/sh会忽略SIGTERM信号量,因此kill -SIGTERM会永远超时,若应用使用bash/sh作为Entrypoing,则应避免过长的graceperiod,避免更多的无效等待
terminating pod的经验分享
- terminationGracePeriodSeconds默认时长30秒
- 如果不关心Pod的终止时长,那么无需采取特殊措施
如果希望快速终止应用进程,那么可采取如下方案- 在preStop script中主动退出进程,发出sigterm优雅终止信号或sigkill强制终止信号
- 在主容器进程中使用特定的初始化进程
优雅的初始化进程应该
- 正确处理系统信号量,将信号量转发给子进程
- 在主进程退出之前,需要先等待并确保所有子进程退出监控并清理孤儿子进程
容器应用可能面临的进程中断

作业
编写K8s部署脚本将httpserver部署到k8s集群,以下思考的维度:
- 优雅启动
- 优雅终止
- 资源需求和QoS保证
- 探活
- 日常运维需求,日志等级
- 配置和代码分离
优雅启动
deploy 中的 livenessProbe 提供优雅启动功能,只有当 8080 端口的 http get 请求 url 127.0.0.1/healthz 返回 200 时,pod 才会被 k8s 设置成 ready 状态,然后才会接收外部流量
livenessProbe:
httpGet:
### this probe will fail with 404 error code
### only httpcode between 200-400 is retreated as success
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
探活
deploy 中配置的 readinessProbe 用于探活,一旦 /healthz 这个接口请求不通,或者返回非 200~400 的状态码,则 k8s 就会将这个pod调度为非 ready 状态,流量就不会请求到这个 pod 上了
# 探活
readinessProbe:
httpGet:
### this probe will fail with 404 error code
### only httpcode between 200-400 is retreated as success
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 2
资源需求和 QoS 保证
- k8s 的 QoS 保证:
- pod中所有容器都必须统一设置limits,并且设置参数都一致,如果有一个容器要设置requests,那么所有容器都要设置,并设置参数同limits一致,那么这个pod的QoS就是Guaranteed级别
- Burstable: pod中只要有一个容器的requests和limits的设置不相同,该pod的QoS即为Burstable
- Best-Effort:如果对于全部的resources来说requests与limits均未设置,该pod的QoS即为Best-Effort
- 3种QoS优先级从有低到高(从左向右):Best-Effort pods -> Burstable pods -> Guaranteed pods
- httpserver 这个容器设置了一样的 requests 和 limit 且只有这一个容器,所以是最高 QoS 保证,即 Guaranteed
日常运维需求,日志等级
-
日常日志查看,其中 httpserver-565798b9f9-4rghf 是 pod 的名称,由于 httpserver 将日志打印到控制台中所以可以直接通过 logs 命令查看
kubectl logs -f httpserver-565798b9f9-4rghf
但是在pod出现异常退出时,日志也就销毁了,这种方法就无法查看到日志了 -
常用的日志解决方案是采用 ELK 方案,搭建 ElasticSearch 集群,采用 filebeat(最初是 logstash,由于内存消耗比较大,所以现在一般用 filebeat 替代)采集日志存储至 ES 中,最后通过 Kibana 查询和展示。
-
filebeat 可以采用 sidecar 的方式挂载到业务容器中,也可通过 DeamonSet 的方式启动之后进行收集。
配置和代码分离
通过 ConfigMap 配置 httpserver 的配置
envFrom:
- configMapRef:
name: httpserver-env-cm
volumeMounts:
- name: config-volume
mountPath: /etc/httpserver/httpserver.properties
ConfigMap + viper 实现 httpserver 热加载配置
viperInstance.WatchConfig()
viperInstance.OnConfigChange(func(e fsnotify.Event) {
fmt.Println("Detect config change: %s \n", e.String())
log.Warn("Config file updated.")
viperLoadConf(viperInstance) // 加载配置的方法
})
当 ConfigMap 发生变化时,会被 viperInstance.WatchConfig() 监控到,然后会调用 OnConfigChange 函数中的匿名函数,重新加载配置
Deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpserver
namespace: mxs
labels:
app: httpserver
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
# maxSurge: 最大激增数, 指更新过程中, 最多可以比replicas预先设定值多出的pod数量, 可以为固定值或百分比(默认25%), 更新过程中最多会有replicas + maxSurge个pod
maxSurge: 2
# maxUnavailable: 最大无效数, 指更新过程中, 最多有几个pod处于无法服务状态, 当maxSurge不为0时, 此栏位也不可为0, 整个更新过程中, 会有maxUnavailable个pod处于Terminating状态
maxUnavailable: 1
# minReadySeconds: 容器内应用的启动时间, pod变为run状态, 会在minReadySeconds后继续更新下一个pod. 如果不设置该属性, pod会在run成功后, 立即更新下一个pod.
minReadySeconds: 15
selector:
matchLabels:
app: httpserver
template:
metadata:
labels:
app: httpserver
spec:
containers:
- name: httpserver
image: tjudream/httpserver:v5
command: [/httpserver]
envFrom:
- configMapRef:
name: httpserver-env-cm
volumeMounts:
- name: config-volume
mountPath: /etc/httpserver/
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
# 优雅启动
livenessProbe:
httpGet:
### this probe will fail with 404 error code
### only httpcode between 200-400 is retreated as success
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
# 探活
readinessProbe:
httpGet:
### this probe will fail with 404 error code
### only httpcode between 200-400 is retreated as success
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 2
volumes:
- name: config-volume
configMap:
# Provide the name of the ConfigMap containing the files you want
# to add to the container
name: httpserver-conf-cm
2、服务发现SVC
在kurbernetes中,pod是应用程序的载体,可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问
为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问Sevice的入口地址就能访问到后面的pod服务。

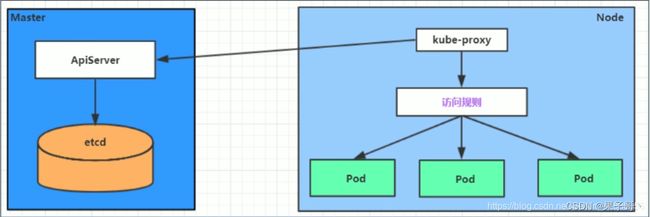
Service在很多情况下只是一个概念,真正起作用的其实是 kube-proxy 服务进程,每个Node节点上都运行着一个 kube-proxy 服务进程。
当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种service的变动,然后它会将最新的service信息转换成对应的访问规则(iptables规则或ipvs规则)。
服务发布
需要把服务发布至集群内部或者外部,服务的不同类型
-
ClusterlP(Headless):默认值,它是Kubernetes系统自动分配的虚拟IP,缺点是只能在集群内部访问
-
NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务
-
LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持

-
ExternalName:把集群外部的服务引入集群内部,直接使用。此类Service用来引用一个已经存在的域名,CoreDNS会为该Service创建一个CName记录指向目标域名。
-
Headless:无头服务,是用户在Spec显示指定ClusterIP为None的Service,对于这类Service,API Server不会为其分配ClusterIP。CoreDNS为此类Service创建多条A记录,并且目标为每个就绪的PodIP。 另外,每个Pod会拥有一个FQDN格式为
$podname.$svcname.$namespace.svc.$clusterdomain的A记录指向PodIP


证书管理和七层负载均衡的需求
需要gRPC负载均衡如何做?
DNS需求
与上下游服务的关系
服务发布的挑战
kube-dns
- DNS TTL问题
Service
- ClusterlP只能对内
- kube-proxy支持的iptables/ipvs规模有限
- IPVS的性能和生产化问题
- kube-proxy的drift问题
- 频繁的Pod变动(spec change,failover,crashloop)导致LB频繁变更
- 对外发布的Service需要与企业ELB即成
- 不支持gRPC
- 不支持自定义DNS和高级路由功能
Ingress
- Spec的成熟度?
3、微服务架构下的高可用挑战
服务发现
- 微服务架构是由一系列职责单一的细粒度服务构成的分布式网状结构,服务之间通过轻量机制进行通信,这时候必然引入一个服务注册发现问题,也就是说服务提供方要注册通告服务地址,服务的调用方要能发现目标服务。
- 同时服务提供方一般以集群方式提供服务,也就引入了负载均衡和健康检查问题。
集中式LB服务发现
- 在服务消费者和服务提供者之间有一个独立的LB。
- LB上有所有服务的地址映射表,通常由运维配置注册。
- 当服务消费方调用某个目标服务时,它向LB发起请求,由LB以某种策略(比如Round-Robin)
做负载均衡后将请求转发到目标服务。 - LB一般具备健康检查能力,能自动摘除不健康的服务实例。
- 服务消费方通过DNS发现LB,运维人员为服务配置一个DNS域名,这个域名指向LB。

- 集中式LB的主要问题是单点问题,所有服务调用流量都经过LB,当服务数量和调用量大的时候,LB容易成为瓶颈,且一旦LB发生故障对整个系统的影响是灾难性的。
- LB在服务消费方和服务提供方之间增加了一跳(hop),有一定性能开销。
进程内LB服务发现
- 进程内LB方案将LB的功能以库的形式集成到服务消费方进程里头,该方案也被称为客户端负载方案。
- 服务注册表(Service Registry)配合支持服务自注册和自发现,服务提供方启动时,首先将服务地址注册到服务注册表(同时定期报心跳到服务注册表以表明服务的存活状态)。
- 服务消费方要访问某个服务时,它通过内置的LB组件向服务注册表查询(同时缓存并定期刷新)目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求。
- 这一方案对服务注册表的可用性(Availability)要求很高,一般采用能满足高可用分布式一致的组件(例如ZooKeeper,Consul,etcd等)来实现。

- 进程内LB是一种分布式模式,LB和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。该方案以客户库(Client Library)的方式集成到服务调用方进程里头,如果企业内有多种不同的语言栈,就要配合开发多种不同的客户端,有一定的研发和维护成本。
- 一旦客户端跟随服务调用方发布到生产环境中,后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
独立LB进程服务发现
- 针对进程内LB模式的不足而提出的一种折中方案,原理和第二种方案基本类似。
- 不同之处是,将LB和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立LB进程做服务发现和负载均衡。
- LB独立进程可以进一步与服务消费方进行解耦,以独立集群的形式提供高可用的负载均衡服务。
- 这种模式可以称之为真正的“软负载(Soft Load Balancing)"。

- 独立LB进程也是一种分布式方案,没有单点问题,一个LB进程挂了只影响该主机上的服务调用方。
- 服务调用方和LB之间是进程间调用,性能好。
- 简化了服务调用方,不需要为不同语言开发客户库,LB的升级不需要服务调用方改代码。
- 不足是部署较复杂,环节多,出错调试排查问题不方便。
负载均衡

-
系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。
- 纵向扩展,是从单机的角度通过增加硬件处理能力,比如CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题;
- 横向扩展,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力,这就是典型的集群和负载均衡架构。
-
负载均衡的作用(解决的问题):
- 解决并发压力,提高应用处理性能,增加吞吐量,加强网络处理能力;
- 提供故障转移,实现高可用;
- 通过添加或减少服务器数量,提供网站伸缩性,扩展性;
- 安全防护,负载均衡设备上做一些过滤,黑白名单等处理。
DNS负载均衡
早期以前,在DNS服务器,配置多个A记录,这些A记录对应的服务器构成集群
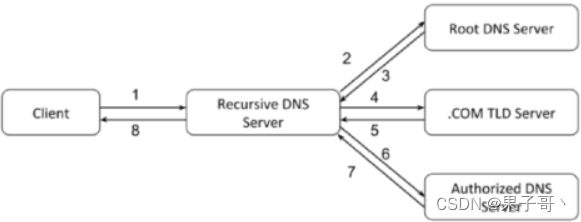

负载均衡技术概览
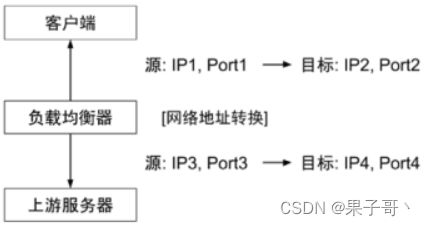
网络地址转换
网络地址转换(Network Address Translation,NAT)通常通过修改数据包的源地址(Source NAT)或目标地址(Destination NAT)来控制数据包的转发行为。
链路层负载均衡
- 在通信协议的数据链路层修改MAC地址进行负载均衡。
- 数据分发时,不修改IP地址,指修改目标MAC地址,配置真实物理服务器集群所有机器虚拟IP和负载均衡服务器IP地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
- 实际处理服务器IP和数据请求目的IP一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。

隧道技术
负载均衡中常用的隧道技术是IPover IP,其原理是保持原始数据包IP头不变,在IP头外层增加额外的IP包头后转发给上游服务器。
上游服务器接收IP数据包,解开外层IP包头后,剩下的是原始数据包。
同样的,原始数据包中的目标IP地址要配置在上游服务器中,上游服务器处理完数据请求以后,响应包通过网关直接返回给客户端。
4、Service对象
Service Selector
- K8s允许将Pod对象通过标签(Label)进行标记,并通过Service Selector定义基于Pod标签的过滤规则,以便选择服务的上游应用实例
Ports:
- Ports属性中定义了服务的端口、协议目标端口等信息
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: kube-system
spec:
ports:
- name: nginx
port: 80
protocol: TCP
targetPort: 80 (宿主机端口)
selector:
app: nginx
Endpoint对象
(Endpoint理解为中间表,描述的Service和Pod之间的地址映射关系,与Service同名。ep会把pod的IP填充到subset属性里)
- 当Service的selector不为空时,Kubernetes Endpoint Controller会侦听服务创建事件,创建与Service同名的Endpoint对象
- selector能够选取的所有PodlP都会被配置到addresses属性中
- 如果此时selecto所对应的fiter查询不到对应的Pod,则addresses列表为空
- 默认配置下,如果此时对应的Pod为not ready状态,则对应的PodiP只会出现在subsets的notReadyAddresses属性中,这意味着对应的Pod还没准备好提供服务,不能作为流量转发的目标。
- 如果设置了PublishNotReadyAdddress为true,则无论Pod是否就绪都会被加入readyAddress list
- ep信息

EndpointSlice对象
- 当某个Service对应的backend Pod较多时,Endpoint对象就会因保存的地址信息过多而变得异常庞大
- Pod状态的变更会引起Endpoint的变更,Endpoint的变更会被推送至所有节点,从而导致持续占用大量网络带宽
- EndpointSlice对象,用于对Pod较多的Endpoint进行切片,切片大小可以自定义
不定义Selector的Service
-
用户创建了Service但不定义Selector(场景:用于指定外部虚拟机)
- Endpoint Controller不会为该Service自动创建Endpoint
- 用户可以手动创建Endpoint对象,并设置任意Ip地址到Address属性
- 访问该服务的请求会被转发至目标地址
-
通过该类型服务,可以为集群外的一组Endpoint创建服务
Service、Endpoint和Pod的对应关系

Service类型
headless-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-headless
spec:
ClusterIP: None
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
externalName.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: tencent.com
Service Topology
- 一个网络调用的延迟受客户端和服务器所处位置的影响,两者是否在同一节点、同一机架、同一可用区、同一数据中心,都会影响参与数据传输的设备数量
- 在分布式系统中,为保证系统的高可用,往往需要控制应用的错误域(Failure Domain),比如通过反亲和性配置,将一个应用的多个副本部署在不同机架,甚至不同的数据中心
- Kubernetes提供通用标签来标记节点所处的物理位置,如:
topology.kubernetes.io/zone:us-west2-a
failure-domain.beta.kubernetes.io/region:us-west
failure-domain.tess.io/network-device:us-west05-ra053
failure-domain.tess.io/rack:us_ west02_02-314_19_12
kubernetes.io/hostname:node-1

5、kube-proxy
kube-proxy原理
Service在很多情况下只是一个概念,真正起作用的其实是 kube-proxy 服务进程,每个Node节点上都运行着一个 kube-proxy 服务进程。
当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种service的变动,然后它会将最新的service信息转换成对应的访问规则(iptables规则或ipvs规则)。
每台机器上都运行一个kube-proxy服务,它监听API server中service和endpoint的变化情况,并通过iptables等来为服务配置负载均衡(仅支持TCP和UDP)。
kube-proxy可以直接运行在物理机上,也可以以static pod或者Daemonset的方式运行。
kube-proxy当前支持以下几种实现
- userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过iptables转发到这个端口,然后在其内部负载均衡到实际的Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。
- iptables:目前推荐的方案,完全以iptables规则的方式来实现service负载均衡。该方式最主要的问题是在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题
- ipvs:为解决iptables模式的性能问题,V1.8新增了ipvs模式,采用增量式更新,并可以保证service更新期间连接保持不断开
- winuserspace:同userspace,但仅工作在windows上
Linux内核处理数据包

Netfilter和iptables

iptables

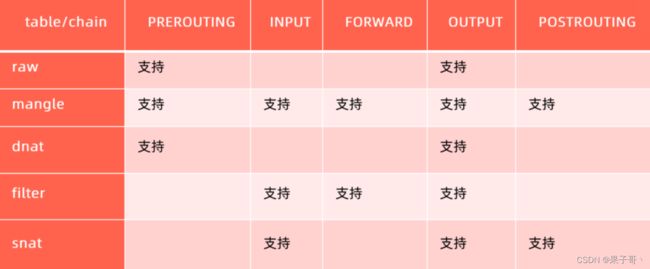
kube-proxy工作原理

iptables规则



iptables与ipvs区别
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是ipvs采用的hash表,iptables采用一条条的规则列表。iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
每个节点的kube-proxy负责监听API server中service和endpoint的变化情况。将变化信息写入本地userspace、iptables、ipvs来实现service负载均衡,使用NAT将vip流量转至endpoint中。由于userspace模式因为可靠性和性能(频繁切换内核/用户空间)早已经淘汰,所有的客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能很差。
ipvs和iptables都是基于netfilter的,两者差别如下:
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
切换操作
1、开启内核操作
cat >>/etc/sysct.conf <-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
EOF sysctl-p
2、开启ipvs支持
yum-y install ipvsadm ipset
#临时生效
modprobe-ip_vs
modprobe-ip_vs_rr
modprobe--ip_vs_wrr
modprobe--ip_vs_sh
modprobe-nf_conntrack_ipv4
#永久生效
cat>/etc/sysconfig/modules/pvs.modules <--ip_vs
modprobe--ip_vs_rr
modprobe--ip_vs_wrr
modprobe-ip_vs_sh
modprobe-nf_conntrack_ipv4
EOF
3、配置kube-proxy
vim /usr/lib/systemd/system/kube-proxy.service
在ExecStart后面加上:
# 添加下⾯两⾏
--proxy-mode=ipvs \
--masquerade-all=true
4、重启kube-proxy
systemctl daemon-reload
systemctl restart kube-proxy
systemctl status kube-proxy
6、域名服务
- Kubernetes Service通过虚拟IP地址或者节点端口为用户应用提供访问入口
- 然而这些IP地址和端口是动态分配的,如果用户重建一个服务,其分配的clusterlP和nodePort,以及LoadBalancerlP都是会变化的,我们无法把一个可变的入口发布出去供他人访问
- Kubernetes提供了内置的域名服务,用户定义的服务会自动获得域名,而无论服务重建多少次,只要服务名不改变,其对应的域名就不会改变
CoreDNS
CoreDNS包含一个内存态DNS,以及与其他controller类似的控制器。
CoreDNS的实现原理是,控制器监听Service和Endpoint的变化并配置DNS,客户端Pod在进行域名解析时,从CoreDNS中查询服务对应的地址记录(service_name.namespace_name.svc.cluster_name(默认是cluster.local),把FQDN指向svc的cluster_ip,把映射的A记录存到CoreDNS里)。

k8s中的域名解析
- Kubernetes Pod有一个与DNS策略相关的属性DNSPolicy,默认值是ClusterFirst
- Pod启动后的/etc/resolv.conf会被改写,所有的地址解析优先发送至CoreDNS
$cat/etc/resolv.conf
search ns1.svc.cluster.local svc.cluster.local cluster.local #(默认加在svc-name的后面)
nameserver 192.168.0.10 #(这个DNS的IP地址为kube-dns的Cluster-IP)
options ndots:4
- 当Pod启动时,同一Namespace的所有Service都会以环境变量的形式设置到容器内影响?

不同类型服务的DNS记录

Service中的Ingress对比

Ingress
- Ingress是一层代理
- 负责根据hostname和path将流量转发到不同的服务上,使得一个负载均衡器用于多个后台应用
- k8s ingress spec是转发规则的集合
Ingress Controller
- 确保实际状态(Actual)与期望状态(Desired)一致的Control Loop
- Ingress Controller确保
- 负载均衡配置
- 边缘路由配置
- DNS配置
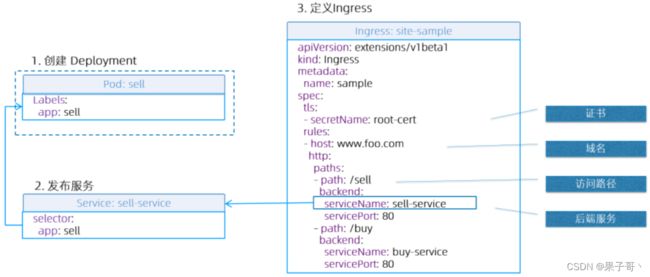
service本身就是一个四层的负载策略,针对外部服务类型:nodeport或loadbalance
deployment与svc
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-dm
spec:
replicas: 2
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1
imagePullPolicy: IfNotPresent # 如果有就不下载
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector: # 匹配,当name=nginx的时
name: nginx
ingress
[root@k8s-master01 ~]# vim ingress1.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-test
spec:
rules:
- host: www1.atguigu.com
http:
paths:
- path: /
backend:
serviceName: nginx-svc # 链接的是上面svc的名字
servicePort: 80
另外一个例子:https://github.com/cncamp/101/tree/master/module8/ingress
其中的Generate key-cert需要进行cat tls.crt | base64 -w 0,然后再放进去