SQL自学进阶知识点
SQL自学进阶知识点及小练习
limit 去除前5条数据后的五条数据,第一个5代表前5条数据,第二个五,代表查询结果后面的五条数据
SELECT * FROM movies
order by title limit 5,5;
如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可
SELECT title FROM movies
where Director='John Lasseter'
order by Length_minutes desc
limit 2,1;
列出所有在Chicago西部的城市,从西到东排序(包括所有字段)
–请输入sql
SELECT * FROM north_american_cities
where Longitude<(select Longitude from north_american_cities
where city= 'Chicago')
order by Latitude desc;
数据库范式是数据表设计的规范,在范式规范下,数据库里每个表存储的重复数据降到最少(这有助于数据的一致性维护),同时在数据库范式下,表和表之间不再有很强的数据耦合,可以独立的增长 (ie. 比如汽车引擎的增长和汽车的增长是完全独立的). 范式带来了很多好处,但随着数据表的分离,意味着我们要查询多个数据属性时,需要更复杂的SQL语句,也就是本节开始介绍的多表连接技术。这样SQL的性能也会面临更多的挑战,特别是当大数据量的表很多的情况下.
如果一个实体(比如Dog)的属性数据被分散到多个数据表中,我们就需要学习如何通过
JOIN连表技术来整合这些数据并找到我们想要查询的数据项
四种连接方式
INNER JOIN可以简写做JOIN. 两者是相同的意思,但我们还是会继续写作INNER JOIN以便和后面的LEFT JOIN,RIGHT JOIN等相比较. full jion (kettle里面用过)
外连接
和INNER JOIN 语法几乎是一样的. 我们看看这三个连接方法的工作原理:
在表A 连接 B, LEFT JOIN保留A的所有行,不管有没有能匹配上B 反过来 RIGHT JOIN则保留所有B里的行。最后FULL JOIN 不管有没有匹配上,同时保留A和B里的所有行若
问题一:下面这两个的执行结果为什么会不同。
源数据 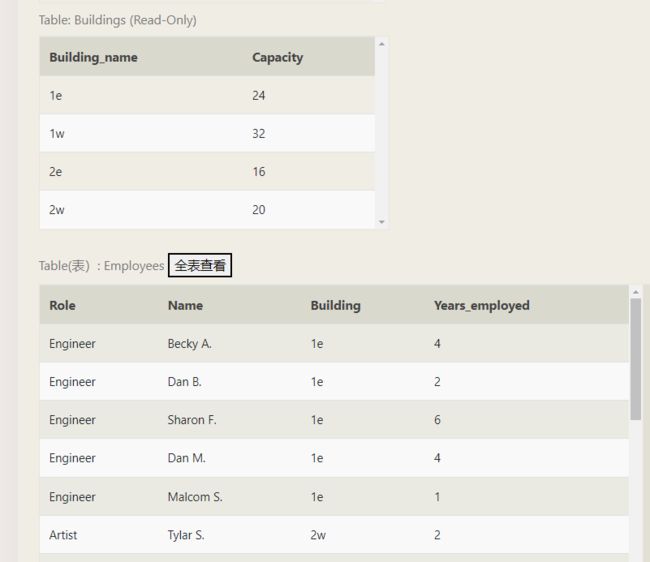
1、直接使用left join 并去除空数据。
select * from (SELECT building,Capacity FROM
employees e left join Buildings B
on e.Building=B.Building_name group by Building) where building is not null;

SELECT building,Capacity FROM
employees e left join Buildings B
on e.Building=B.Building_name and building is not null group by Building

2、利用子查询判断数据是否为要求数据
SELECT * FROM Buildings
WHERE Building_name IN (
SELECT DISTINCT Building FROM Employees
WHERE Building IS NOT NULL
)
在查询中使用表达式
列出所有的电影ID,名字和销售总额(以百万美元为单位计算)
SELECT id,title,(Domestic_sales+International_sales)/1000000 销售总额 FROM movies m left join Boxoffice B on m.id=B.Movie_id;
列出所有的电影ID,名字和市场指数(Rating的10倍为市场指数)
ELECT id,title,rating*10 市场总数 FROM movies m left join Boxoffice B on m.id=B.Movie_id;
列出所有偶数年份的电影,需要电影ID,名字和年份
SELECT id,title,Year FROM (select * from movies where year%2=0) m left join Boxoffice B on m.id=B.Movie_id;
在查询中进行统计I
常见的统计函数
| Function | Description |
|---|---|
| COUNT(*), COUNT(column) | 计数!COUNT(*) 统计数据行数,COUNT(column) 统计column非NULL的行数. |
| MIN(column) | 找column最小的一行. |
| MAX(column) | 找column最大的一行. |
| **AVG(**column) | 对column所有行取平均值. |
| SUM(column) | 对column所有行求和. |
查询执行顺序
FROM和JOINs
FROM或JOIN会第一个执行,确定一个整体的数据范围. 如果要JOIN不同表,可能会生成一个临时Table来用于 下面的过程。总之第一步可以简单理解为确定一个数据源表(含临时表)
WHERE我们确定了数据来源
WHERE语句就将在这个数据源中按要求进行数据筛选,并丢弃不符合要求的数据行,所有的筛选col属性 只能来自FROM圈定的表. AS别名还不能在这个阶段使用,因为可能别名是一个还没执行的表达式
GROUP BY如果你用了
GROUP BY分组,那GROUP BY将对之前的数据进行分组,统计等,并将是结果集缩小为分组数.这意味着 其他的数据在分组后丢弃.
HAVING如果你用了
GROUP BY分组,HAVING会在分组完成后对结果集再次筛选。AS别名也不能在这个阶段使用.
SELECT确定结果之后,
SELECT用来对结果col简单筛选或计算,决定输出什么数据.
DISTINCT如果数据行有重复
DISTINCT将负责排重.
ORDER BY在结果集确定的情况下,
ORDER BY对结果做排序。因为SELECT中的表达式已经执行完了。此时可以用AS别名.
LIMIT/OFFSET最后
LIMIT和OFFSET从排序的结果中截取部分数据.
统计一下每个导演的销售总额(列出导演名字和销售总额)
常规写法
SELECT Director,sum(Domestic_sales+International_sales) 销售总额 FROM movies
left join Boxoffice
on movies.id=Boxoffice.movie_id group by Director;
使用with 写法,可能会有人觉得多此一举,我不觉得,因为说实话在这之前,我不是很理解with的用处这也是一个尝试。用with as ,其实跟直接用子查询效率上没有什么区别;而用临时表与永久表相似,数据是真是跑入到数据库里面去的,相当于第二次直接关联的是一个小表,查询效率大大提高。值得注意的是,在数据优化的过程中,其实使用with as 可以增加代码的可读性,方便更改。
with t1 as (SELECT id,Director FROM movies),
t2 as (select movie_id,Domestic_sales,International_sales from Boxoffice)
SELECT Director,sum(Domestic_sales+International_sales) 销售总额 FROM t1
left join t2
on t1.id=t2.movie_id group by Director;
按导演分组计算销售总额,求出平均销售额冠军(统计结果过滤掉只有单部电影的导演,列出导演名,总销量,电影数量,平均销量) ✓
select * from (SELECT Director
,sum(Domestic_sales+International_sales) sum_
,count()
,avg(Domestic_sales+International_sales) avg_
FROM movies m left join Boxoffice B
on B.movie_id=m.id group by Director having count()>1) order by avg_ desc limit 1
with写法
with t1 as (SELECT id,Director FROM movies),
t2 as (select movie_id,Domestic_sales,International_sales from Boxoffice),
t3 as (SELECT Director
,sum(Domestic_sales+International_sales) 销售总额
,count() 数量
,avg(Domestic_sales+International_sales) avg_sale
FROM t1
left join t2
on t1.id=t2.movie_id
group by Director having count()>1)
select director,销售总额,数量,max(avg_sale) from t3;
找出每部电影和单部电影销售冠军之间的销售差,列出电影名,销售额差额
-- 先将两个表读取进来
with t1 as (SELECT id,title FROM movies),
t2 as (select movie_id,Domestic_sales,International_sales from Boxoffice),
-- 再找出单部电影的电影冠军
t3 as(select max(Domestic_sales+International_sales) max_sales
from t1 left join t2
on t1.id=t2.movie_id)
select title
,(t3.max_sales-t2.Domestic_sales-t2.International_sales) diff_sales
from t1 left join t2
on t1.id=t2.movie_id,t3
最后附上这个sql的自学练习网站,里面的部分简单的题我就没有写了,就写了部分的难道适中,或者部份简单的题大家可以自行学习哟。
自学SQL网(教程 视频 练习全套) (xuesql.cn)
里面的题大多还是比较简单的,假如有的小伙伴觉得太过于简单的话,可以选择去力扣或者牛客或者自建数据进行测试和玩一玩,毕竟学大数据这一块的东西,以后不管从事哪方面,都免不了使用sql语句。别说hive不用,hive的语句是不是类sql(感觉基本上就是sql语句)。