Hadoop分布式集群的安装(图解)
全局统筹
- 前言
- 安装前的检查
- 开始安装虚拟机
- Linux的网络配置步骤
- 虚拟机内部设置
- 进入虚拟机
- 安装其他东西
- 克隆虚拟机
- 开始搭建分布式集群
- 集群配置
- 启动集群
- jps查看进程
- 常见问题
前言
这里的笔记仅供参考使用,你可以从买来一台新的电脑就可以开始照着安装。我目前在虚拟机里面仅仅安装jdk和Hadoop,作为我们集群最基础需要的东西,有需要学习其他的东西的小伙伴可以等待我的后续更新,和其他博主不一样的是,每个人都有不一样的地方,但目的肯定是一样的。话不多说,开干!
注:小小的提示,本实验因为涉及到网络服务的连接,建议各位在学习期间关闭你的防火墙,否则,一旦出现连接时错误时,找找你的防火墙问题。
安装前的检查
1、电脑是否虚拟化
可能有很少的一部分同学在我们打开VMware时出现过这种情况
这个问题出现的原因就是我们的电脑未进行虚拟化的开启,这时候我们打开我们的任务管理器(鼠标放到最下边的任务栏,右击就会出现,快捷键:笔记本:ctrl+shift+esc,台式电脑,ctrl+alt+.),如果出现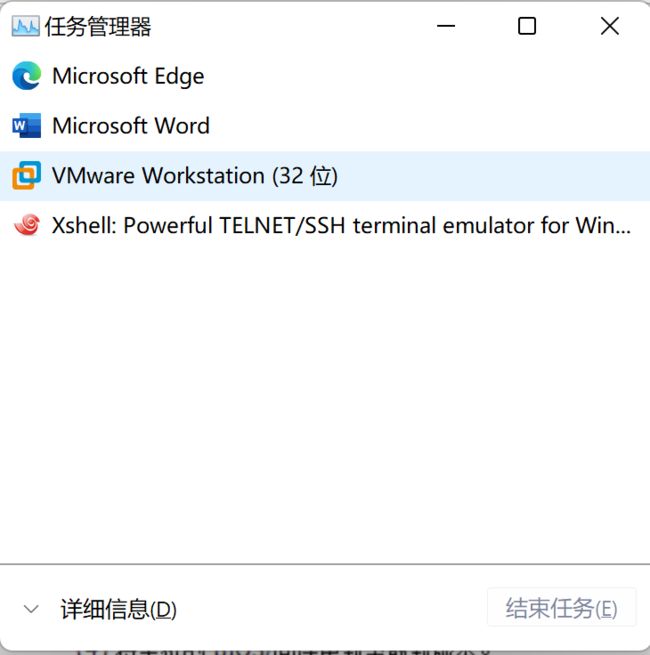
这个时候我们点开详细信息就可以了,再点击性能,如果你能看到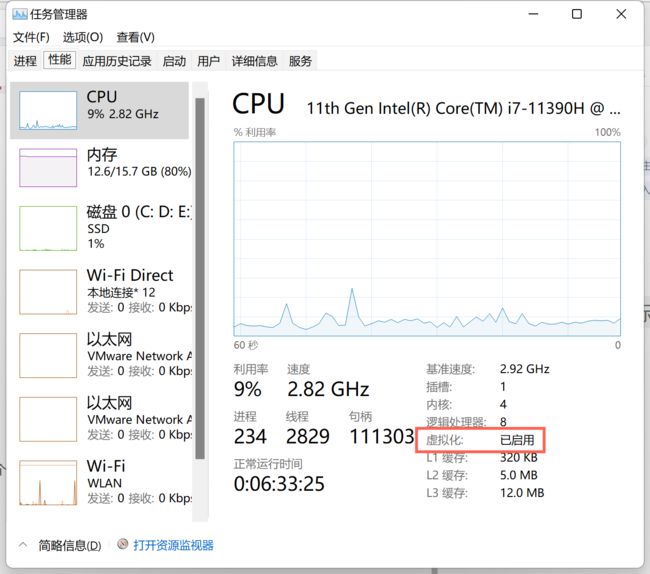
下面这个虚拟化三个字,应该时处于已禁用的状态(已启动不用管),这时候我们就需要开启虚拟化。下面这个开启虚拟化,我就不测试了,不能截图,偷偷偷个懒,没人发现吧。
开启虚拟化详情链接
2、安装VMWare
因为这里主要就是有安装包了之后,一次一次下一步基本上就可以了。
vmware安装详情链接
VMware16百度网盘下载链接:https://pan.baidu.com/s/1ZZK53T18sc72xsTU355GYg
提取码:078m
3、准备centos下载
centOS7.5.1804官网下载地址链接
这里因为超过4个G了,百度网盘都存不下了。
开始安装虚拟机
使用的配置
安装平台:VMware16
适用系统:window10,windows11(其他系统你们的博主没钱尝试了,win11都是升级后才尝试的。)
映像文件:CentOS-7.5-x86_64-DVD-1804.iso
具体安装步骤
1、新建虚拟机
2、选择自定义
3、无脑下一步
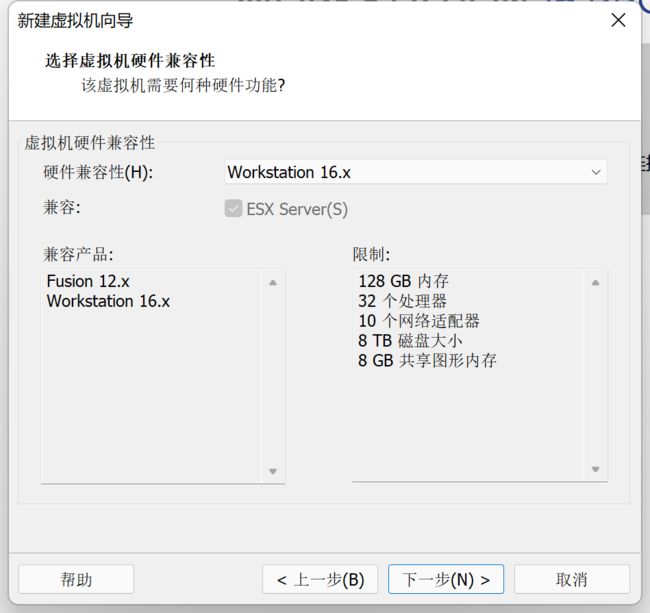
4、选择映像方式
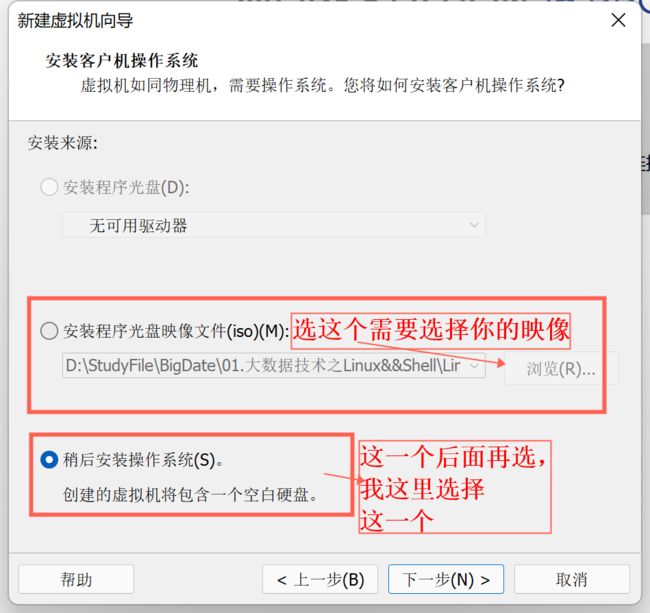
5、继续无脑下一步
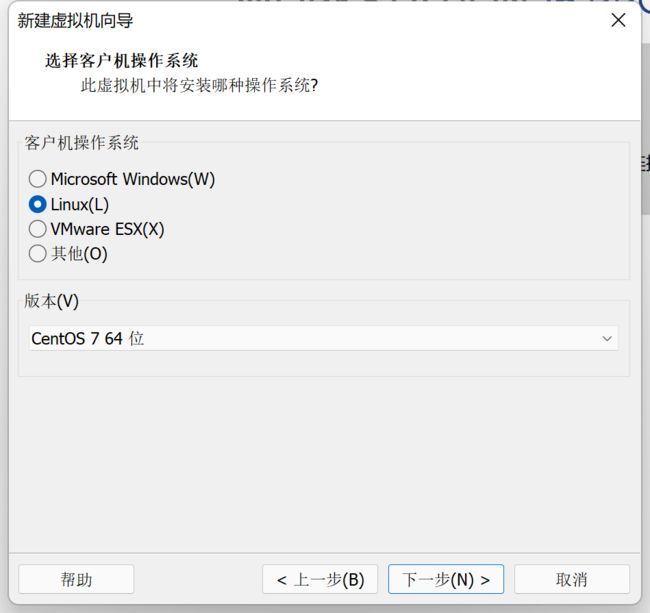
6、设置虚拟机名称
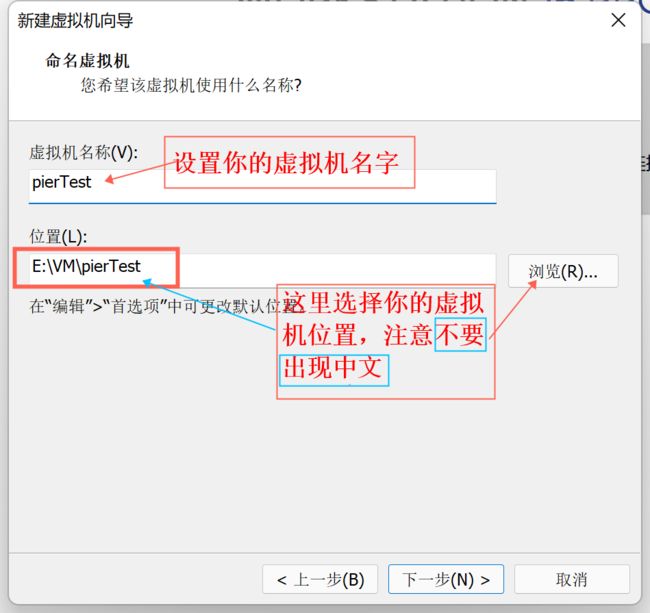
7、设置虚拟机处理器内核大小
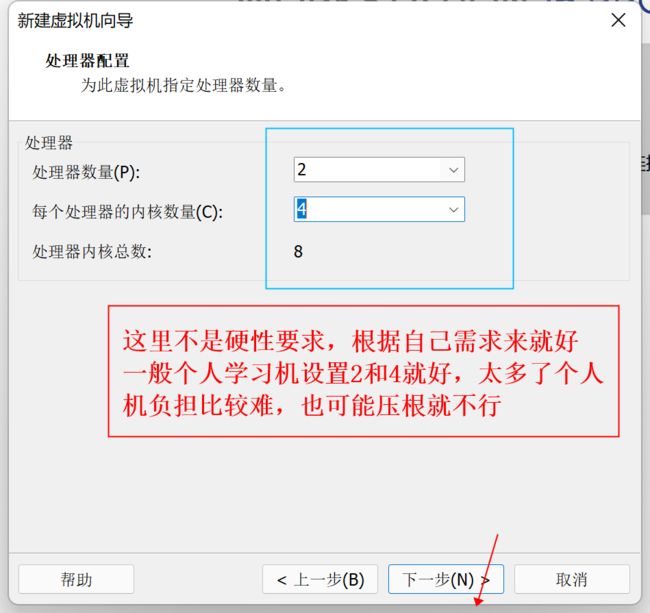
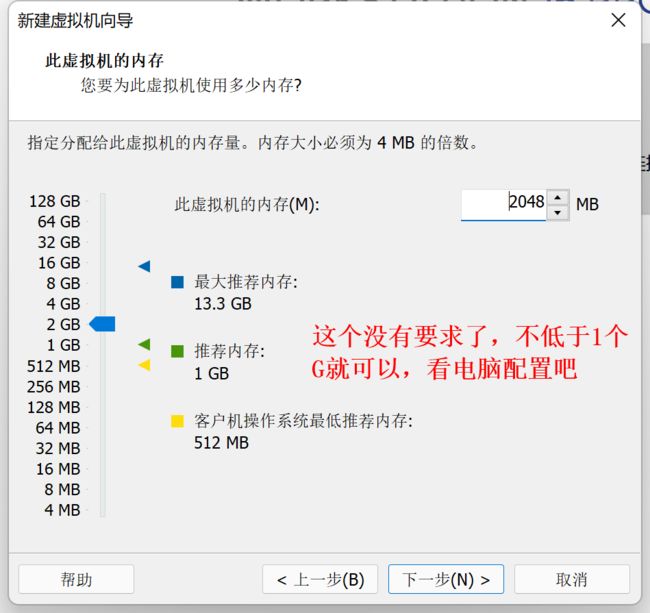
8、设置虚拟机内存大小
9、设置网络类型,学习使用NAT模式
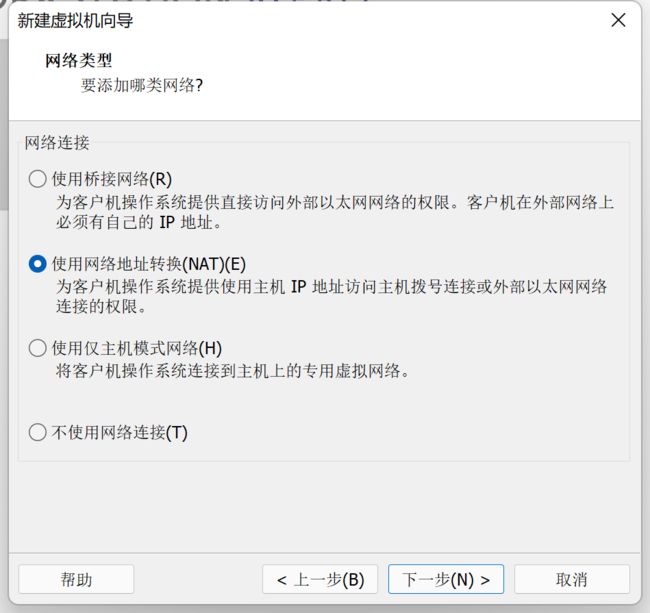
三种模式的区别
| 网络模型 | 交换机名称 |
|---|---|
| 桥接模式 | VMnet0 |
| NAT模式 | VMnet8 |
| 仅主机模式 | VMnet1 |
NAT、桥接模式(Briged模式)均可与外网进行通信,仅主机模式(Host-Only)一般只能在内网进行通信。
1、NAT(网络地址转换模式)–多用于家庭环境
安装好虚拟机后,它的默认网络模式就是NAT模式。
原理:通过宿主机的网络来访问公网。虚拟局域网内的虚拟机在对外访问时,使用的则是宿主机的IP地址,这样从外部网络来看,只能看到宿主机,完全看不到新建的虚拟局域网。
优势:虚拟系统接入互联网非常简单,只需宿主机器能访问互联网即可, 不需要进行任何手工配置。
2、Bridged(桥接模式)–多用于办公环境
类似局域网中的一台独立的主机,它可以访问内网任何一台机器,但是它要和宿主机器处于同一网段,这样虚拟系统才能和宿主机器进行通信【主机防火墙开启会导致ping不通】
设置:
(1)默认存在自动获取ip机制,只需要将虚拟机设置为Bridged(桥接模式),虚拟机会自动获取新的ip,保证ip地址与宿主机在同一个网段。
(2)如果是手工配置机制,那么为了保持虚拟机与宿主机在同一个网段,其中涉及人工配置ip,比较麻烦。
使用场景:如果想利用VMWare在局域网内新建一个虚拟服务器,为局域网用户提供网络服务,就应该选择桥接模式。
3、Host-only(主机模式) – 用得比较少
在某些特殊的网络环境中,要求将真实环境和虚拟环境隔离开,这时你就可采用host-only模式。在这种模式下宿主机上的所有虚拟机是可以相互通信的,但虚拟机和真实的网络(物理机网络)是被隔离开的。
10、连续两个下一步到达这里,选择磁盘

11、选择磁盘大小以及磁盘格式
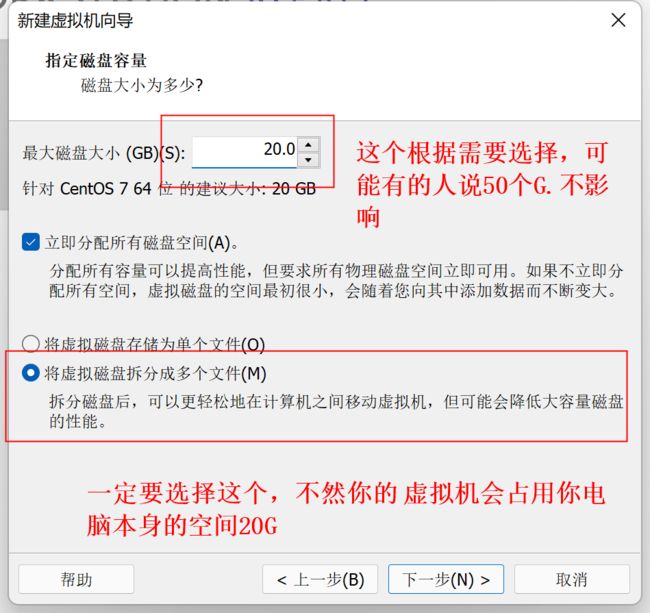
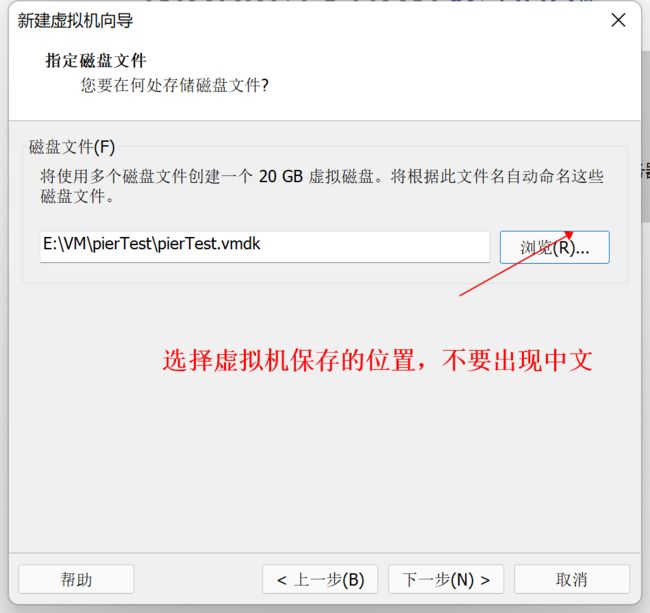
12、选择你保存的位置,不要出现中文
13、别着急点完成
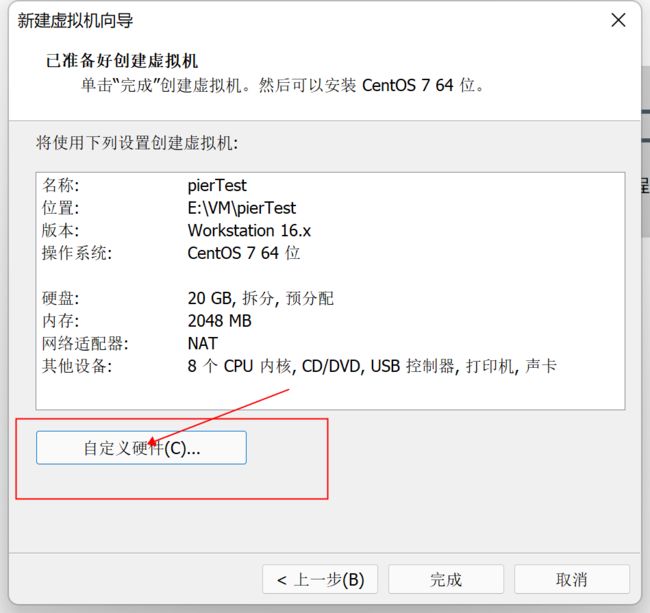
14、最后的配置
这里我们以后也可以在这个界面更改
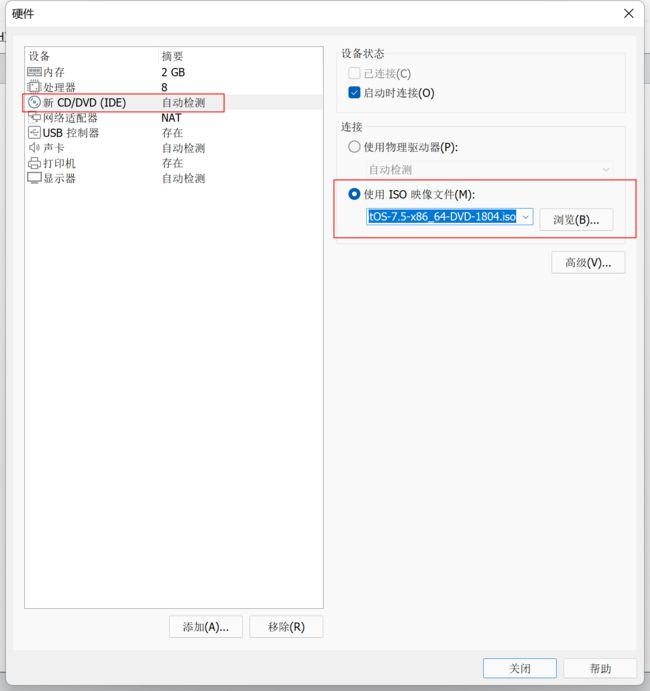
选择映像文件,前面选择这里就不用选择了

选择NAT模式
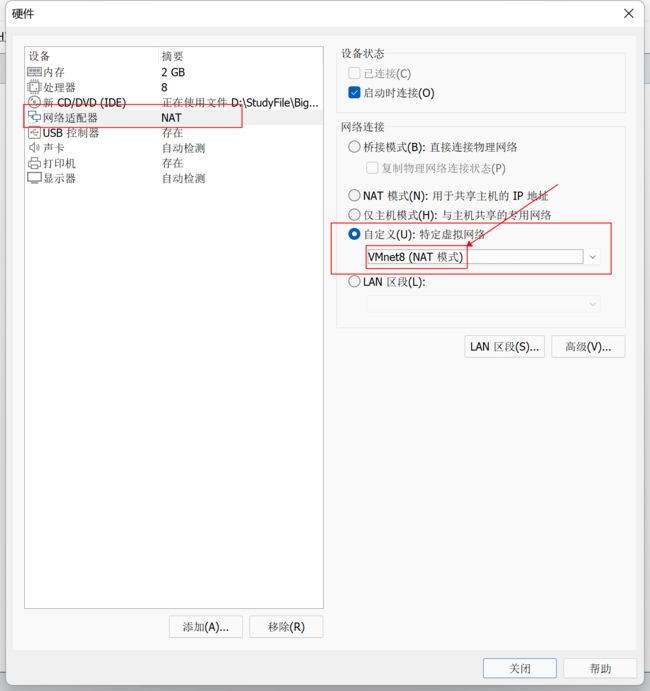
配置完毕后点击关闭完成。启动虚拟机下面这个界面请等待就可以了。
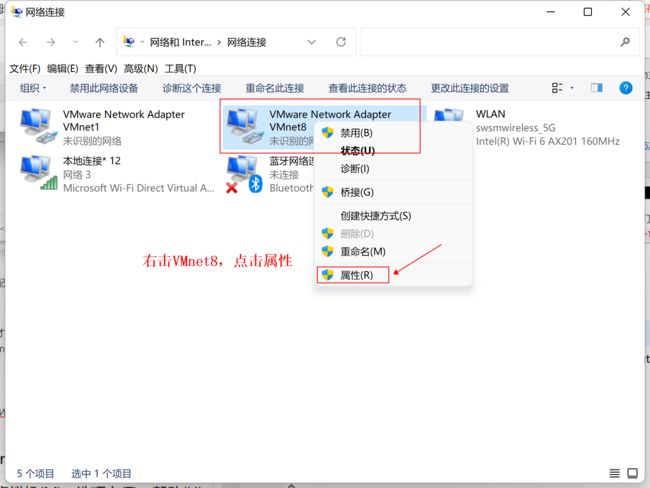
等他安装时我们可以去做一个事,打开我们的网络配置,这么查找控制面板\网络和 Internet\网络连接
Linux的网络配置步骤
对于网络的配置,我们希望IP是相对固定了,这样才能确保集群的所有服务器之间通信的正常,达到协同合作的目的,因此再配置Linux网络时要考虑到局域网和Internet网都可以适配,在这里我们选用虚拟网卡配合NAT模式的方式达到此目的。反正一句话:网要通还很稳定。
步骤如下
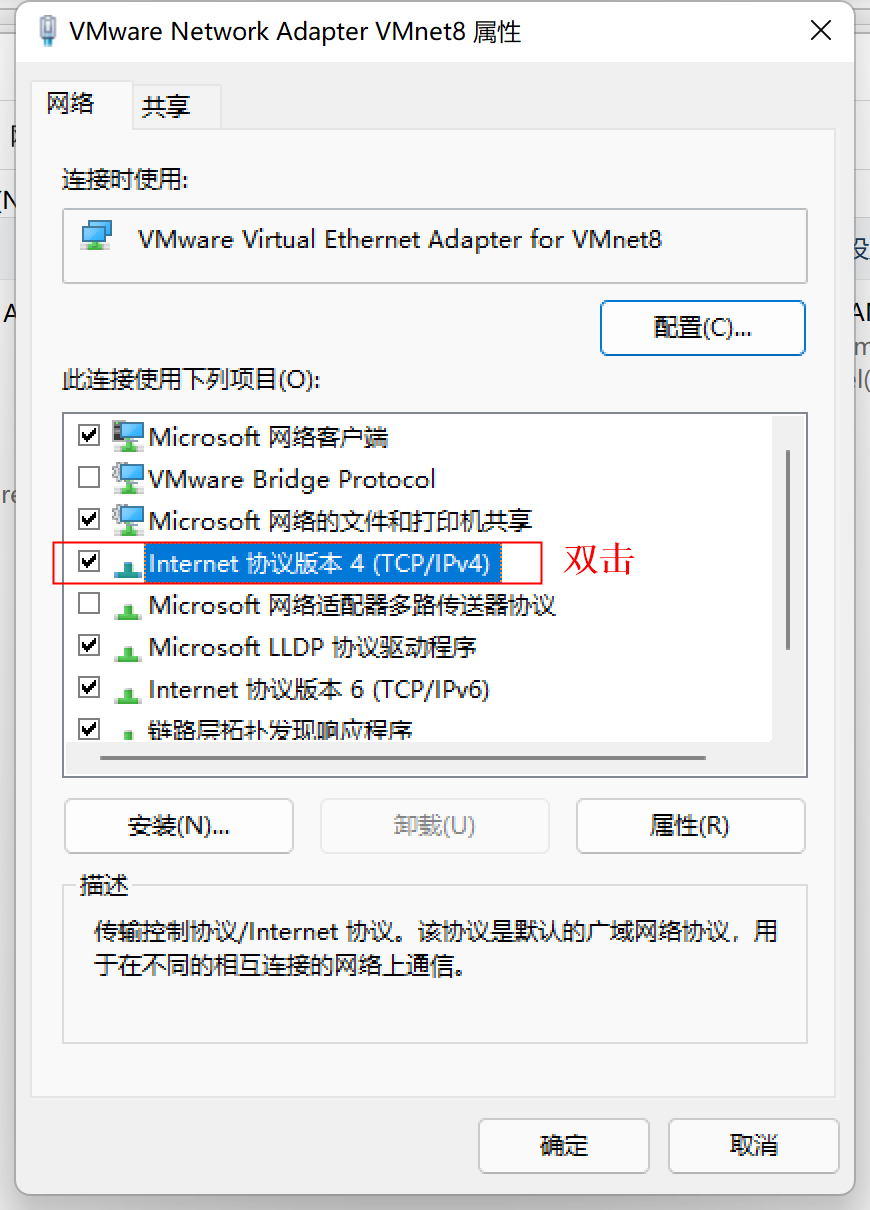
1、给当前Linux主机设置VMnet8虚拟网卡,在VMWare中选择虚拟机,在选择设置
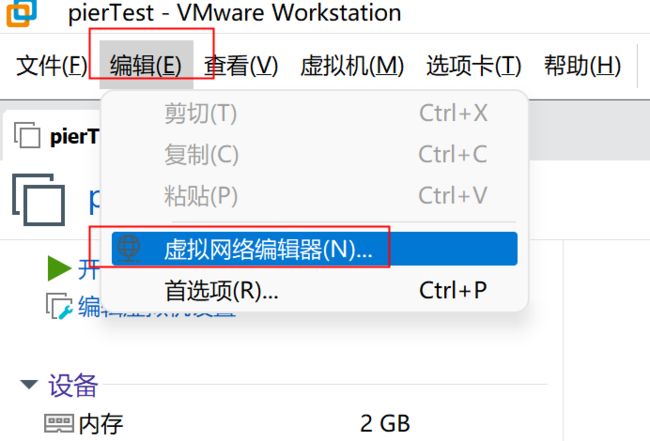
最后确定保存。
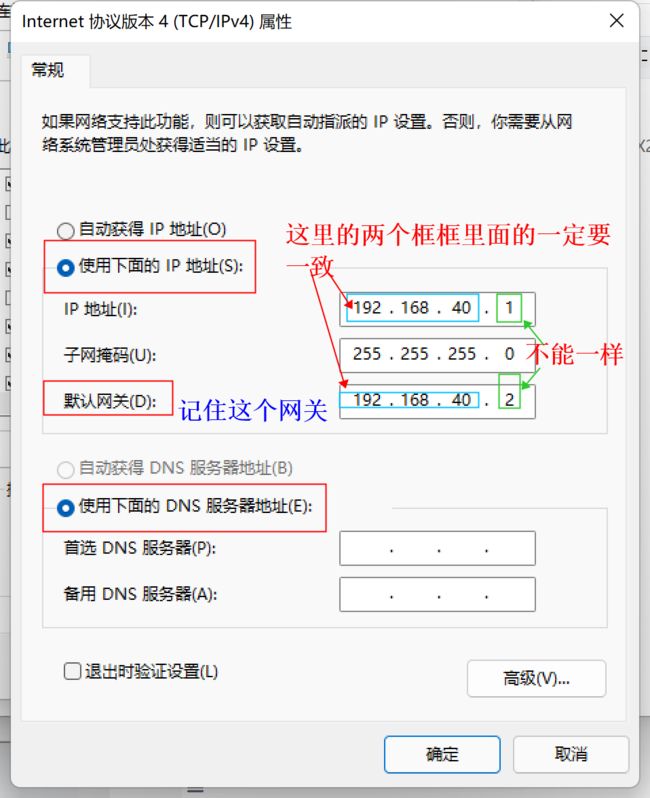
2、配置网关
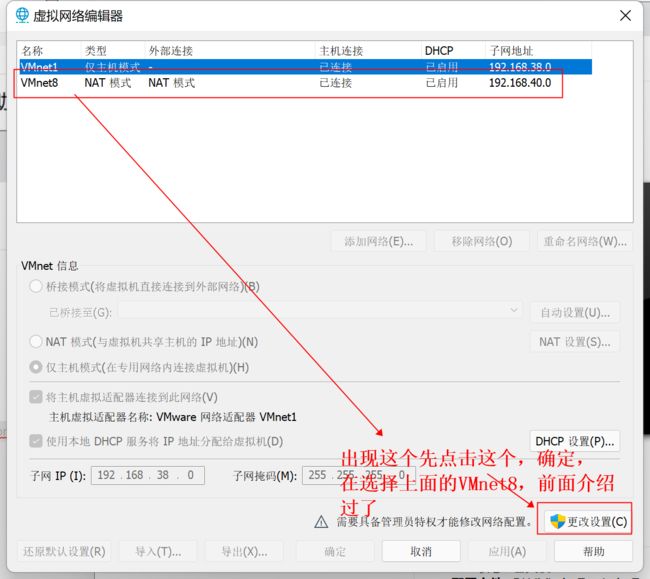
子网IP不要和之前win配置的IP地址冲突

这里的网关一定要和之前的保持一致。主要是更改框里面的东西
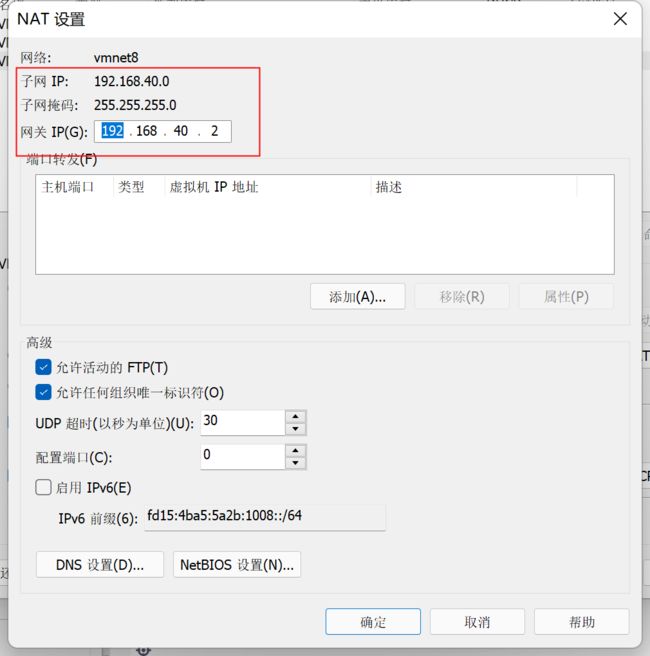
确定保存后,打开虚拟机。
虚拟机内部设置
选择安装
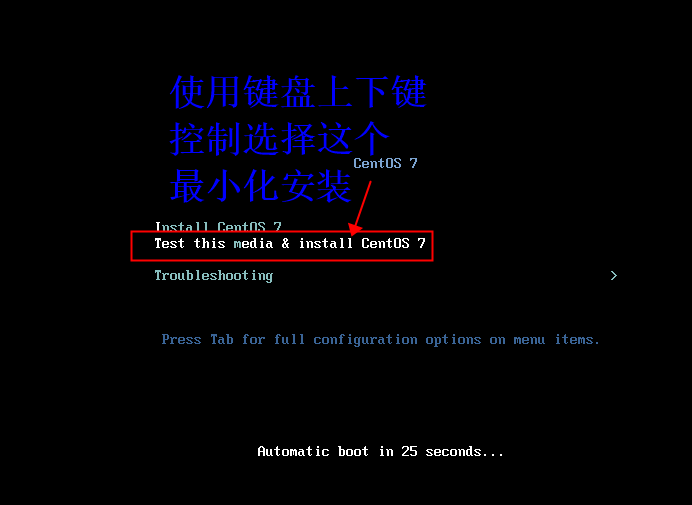
在下面搜索ch,就可以选择中文,当然你也可以选择其他的,随意,选择
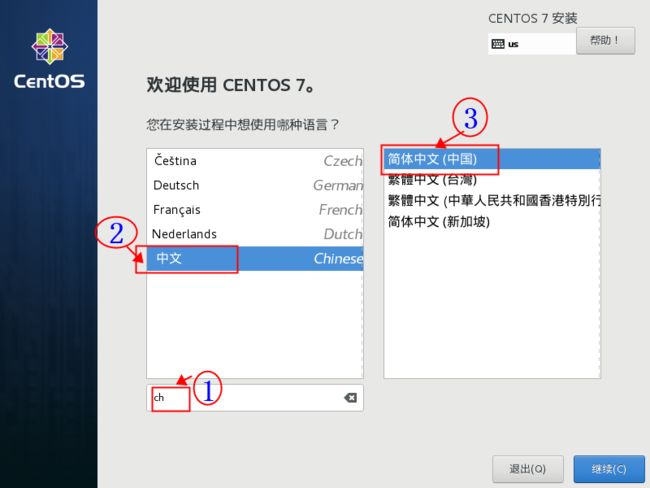
继续下一步。
选择时区和最小化安装
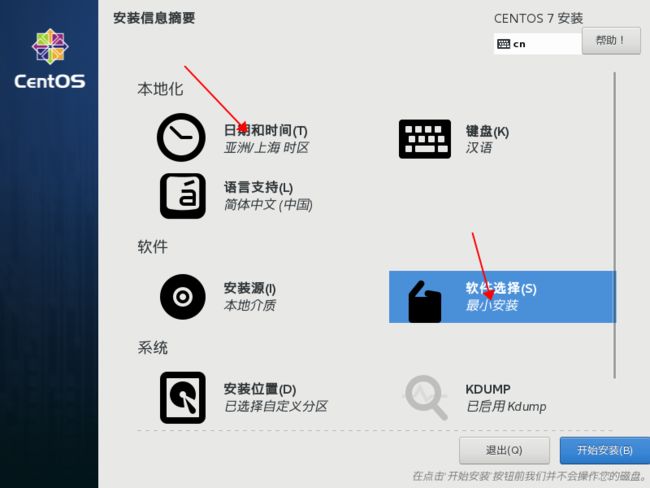
时区自己选择,最小化安装在下面
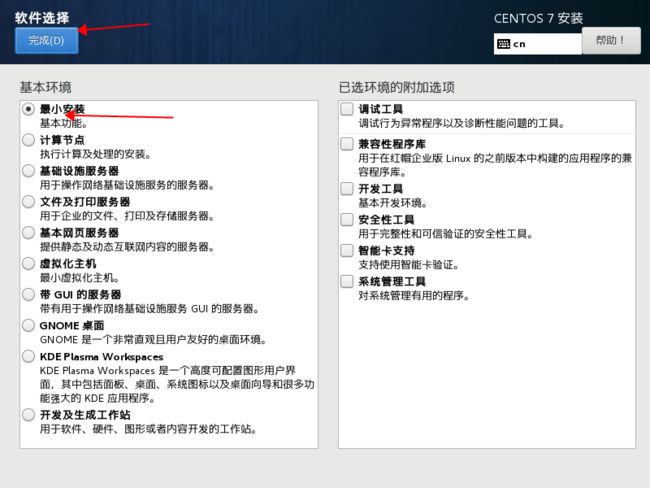
配置磁盘
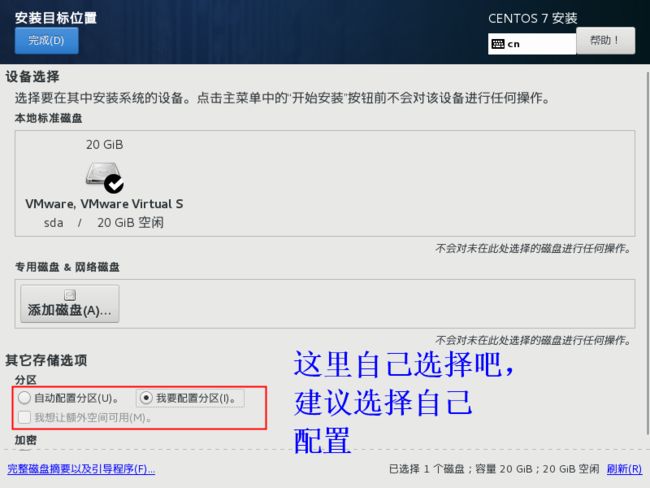
第一个分区
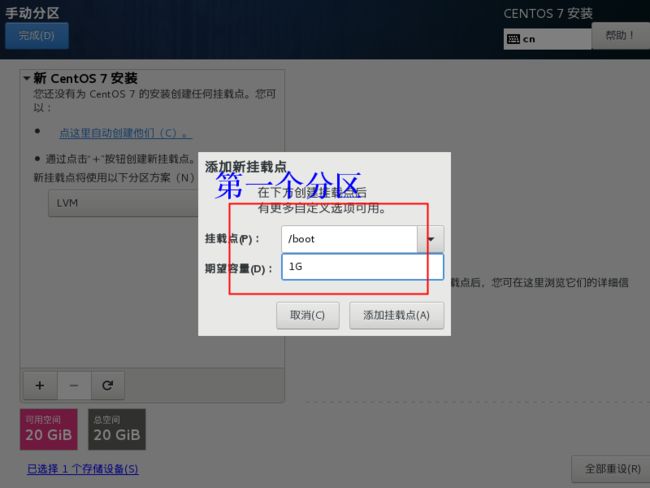
设置第一个分布格式
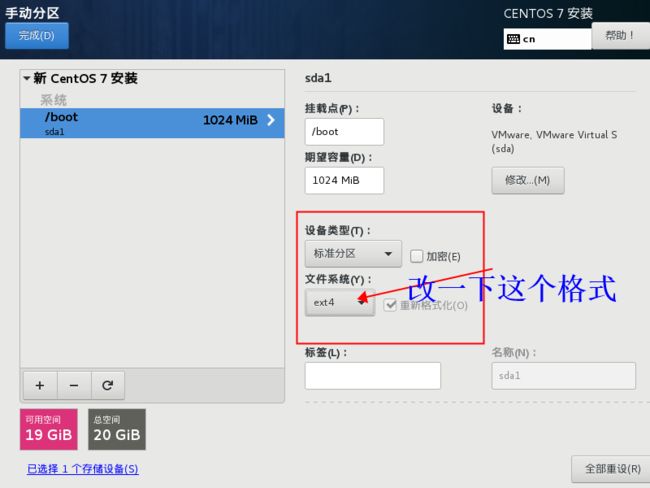
第二个分区
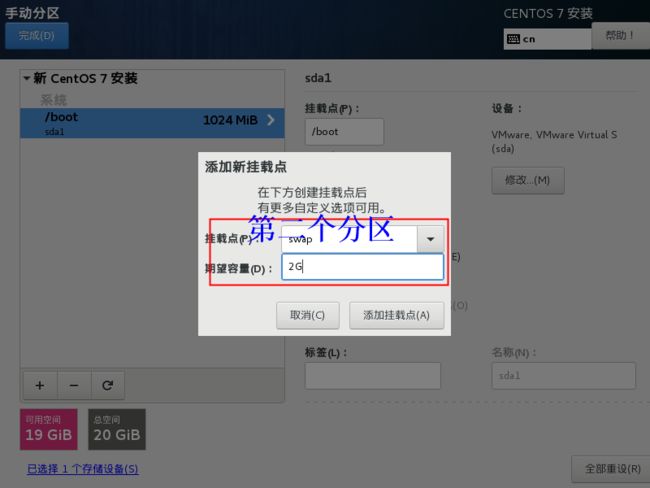
格式
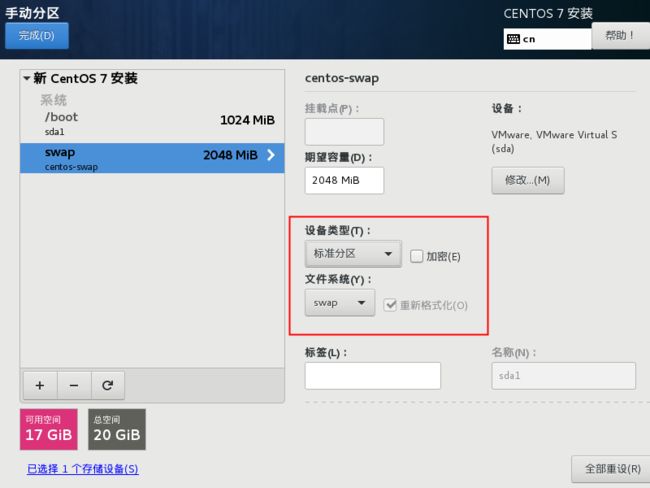
第三个分区
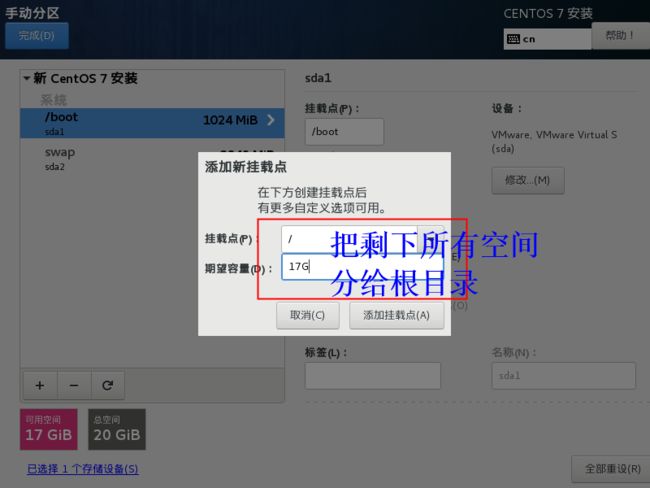
最终的分区设置
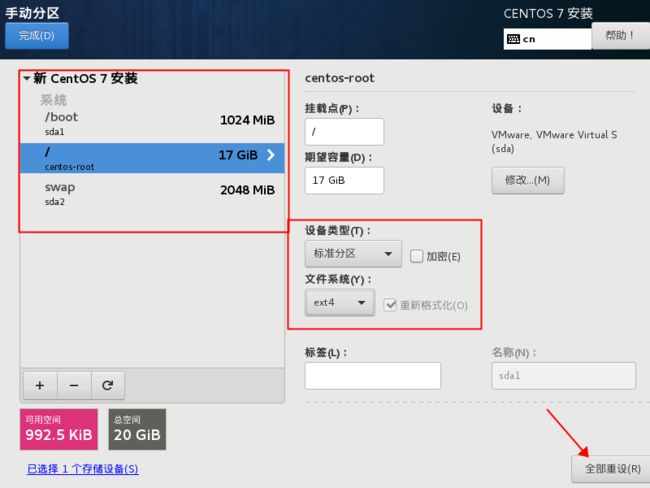
点击完成,接受更改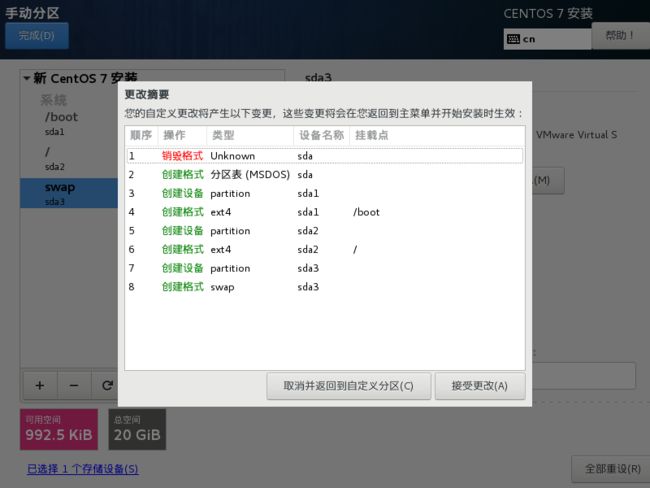
关闭KDUMP

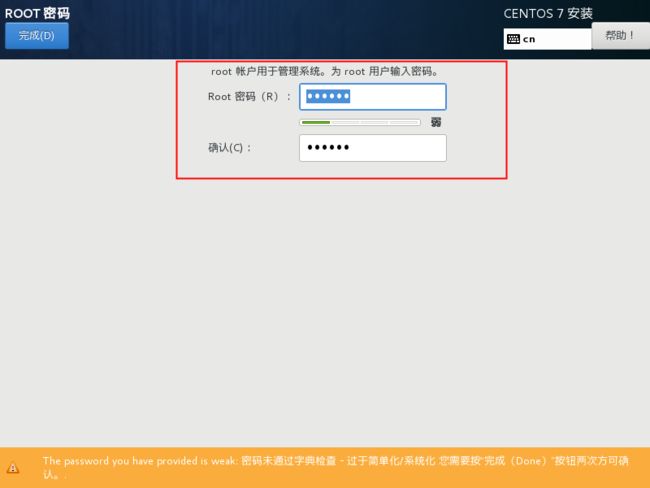
设置root密码
在上面完成后点击下一步
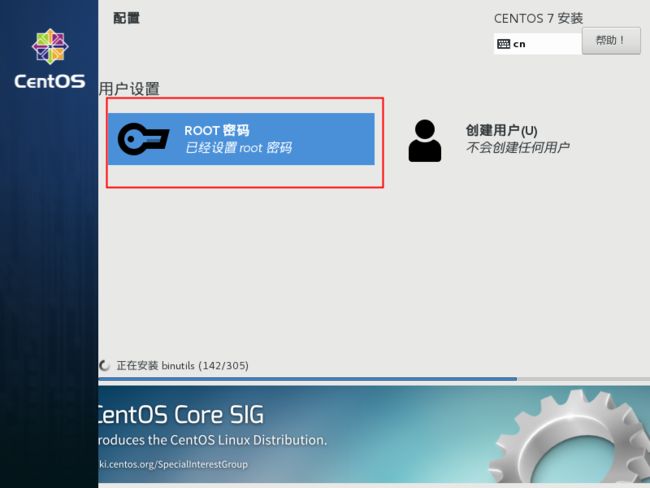
设置密码,一定要记着,更改不太方便
完成配置
这里慢慢等待别着急
等待几分钟后
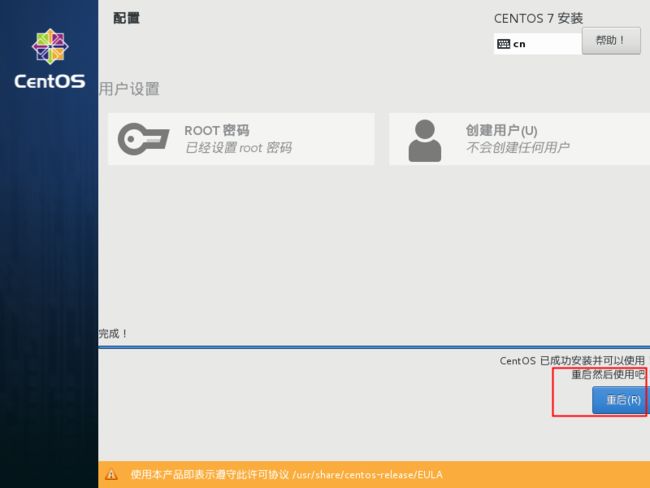
进入虚拟机
登录界面

配置网络
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33

重启网络服务
service network restart

检查ping
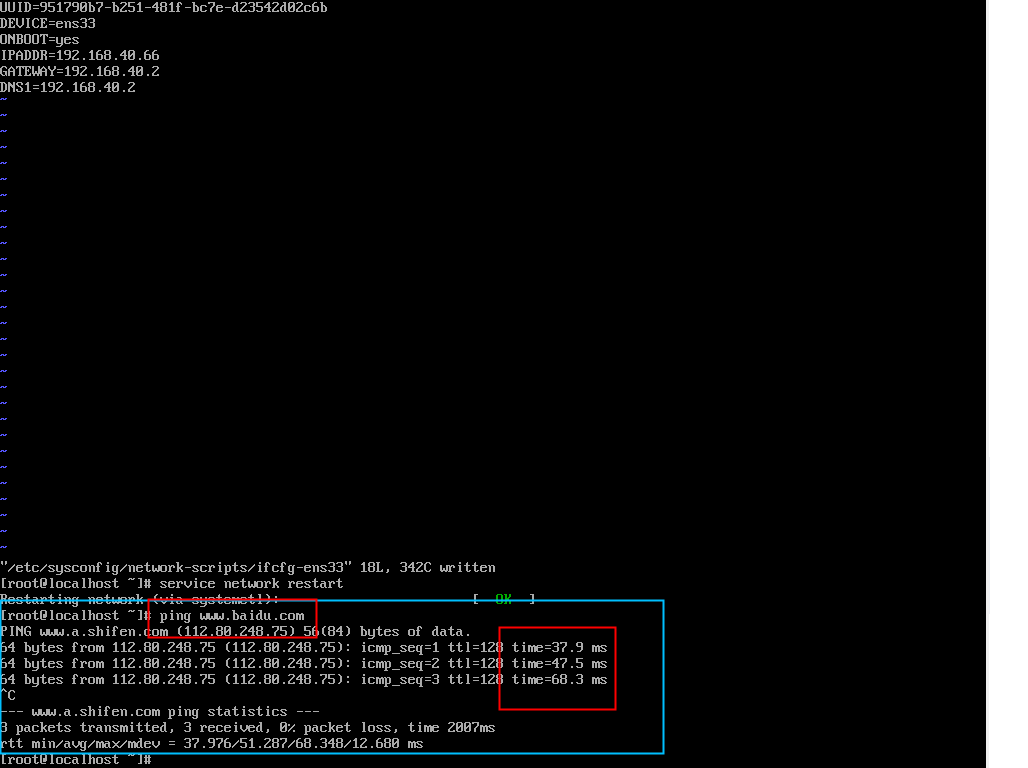
当我们做好这一步了之后,我们就可以做远程连接了,当然如果你要修改主机名,建议下一步做了之后再做远程连接。这里我们采用xshell做远程连接。这里因为版本基本上都大同小异,使用起来体验差不多,就不指定版本号了。因为有的小伙伴可能需要修改主机名,我们就把远程连接放在后面了。
xshell下载地址
修改主机名
#查看虚拟机现有名字
hostname
如果你觉得这个虚拟机的名字不好看,我们就改名
sudo vi /etc/hostname
把里面的东西删除,更改成你想要的名字,重启虚拟机就可以了。这里我们最基本的虚拟机就安装好了,但是我们因为采取的是最小化安装,我们就还需要安装一些其他的东西。
XShell远程连接
在上面的配置完成后,我们的ping能够搞定三端后(本机,你的win,外网【百度之类】),可以做远程连接了。
打开下xshell后,右击左上角的新建
连接
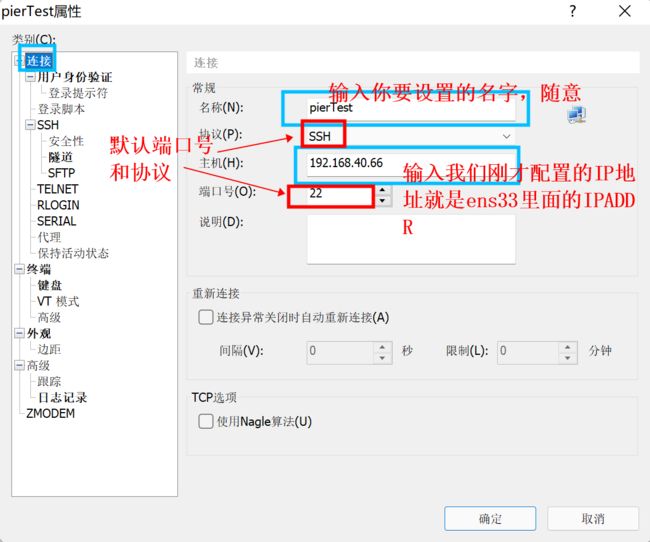
然后就可以点击确定,或者在用户身份验证哪里输入你的用户名和密码,不输入,每次都需要输入的。也可以在外观哪里选择其他的页面设置。
安装其他东西
下载相应工具组件
[root@localhost ~]# yum install -y epel-release
[root@localhost ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
永久关闭防火墙
-
临时关闭防火墙
- 查看防火墙状态
systemctl status firewalld - 临时关闭防火墙
systemctl stop firewalld
- 查看防火墙状态
-
开机启动时关闭防火墙
- 查看防火墙开机启动状态
systemctl enable firewalld.service - 设置开机时关闭防火墙
systemctl disable firewalld.service
- 查看防火墙开机启动状态
还可以创建一个用户pier,并设置密码
#添加用户
[root@localhost ~]# useradd pier
#设置用户密码
[root@localhost ~]# passwd pier
更改用户 pier 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符 #这里的提示不用管,自己随意
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
给用户增加root权限
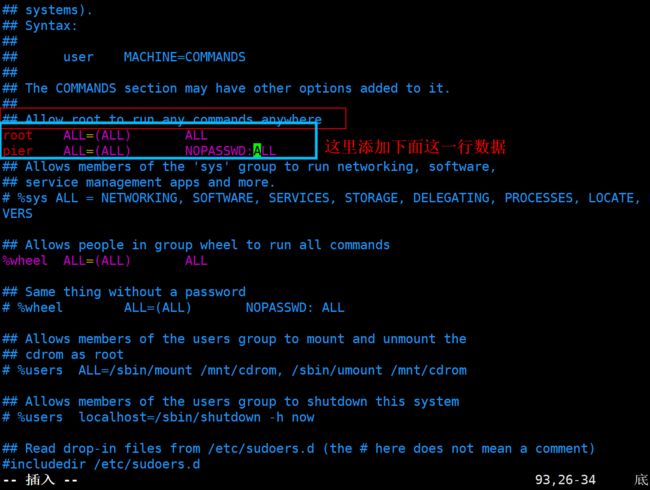
[root@localhost ~]# vim /etc/sudoers
添加下面这一行语句,位置不影响,主要是方便复制。
pier ALL=(ALL) NOPASSWD:ALL
/opt下创建文件夹
[root@localhost ~]# mkdir /opt/sofeware /opt/module
修改文件权限以及所属用户组
[root@localhost opt]# chown pier:pier /opt/module /opt/sofeware/
[root@localhost opt]# ll
总用量 8
drwxr-xr-x. 2 pier pier 4096 1月 7 00:39 module
drwxr-xr-x. 2 pier pier 4096 1月 7 00:39 sofeware
,至此我们做好了我们最重要的一步,做了一台救命机,这台机器我们不做其他的东西,只是为了我们以后多台服务器使用时方便克隆。不安装jdk以及其他包的原因是,救命的,肯定越纯粹越好,后期大不了就复杂一点,不至于每一台都要这么安装了呀。
克隆虚拟机
克隆虚拟机是需要先关闭这一台虚拟机的关机命令:shutdown -h now,这里我们克隆三台虚拟机,分别为改名为Hadoop105,Hadoop106,Hadoop107,对应的IP地址分别为192.168.40.105、192.168.40.106、192.168.40.107。
再提示一下,更改主机名命令为sudo vi /etc/hostname,修改IP地址的命令为sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
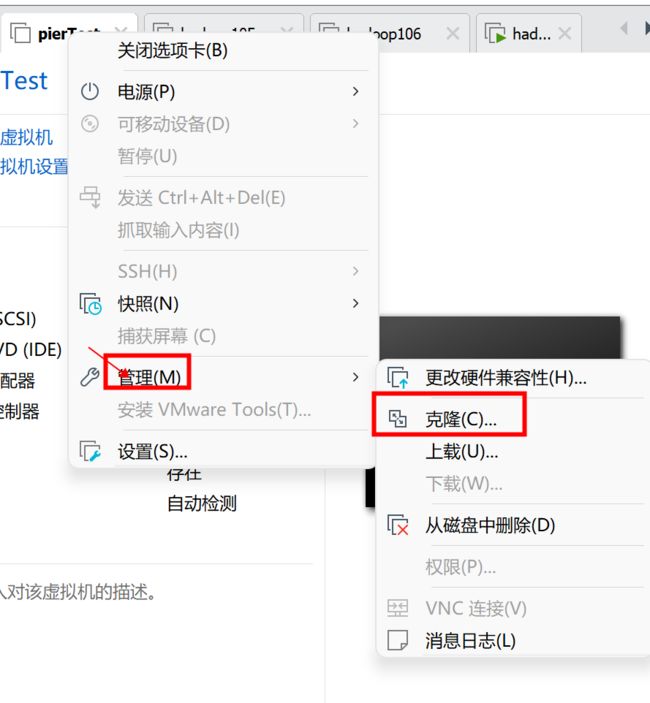
前面两步直接下一步即可,在下面这里一定要点创建完整克隆。
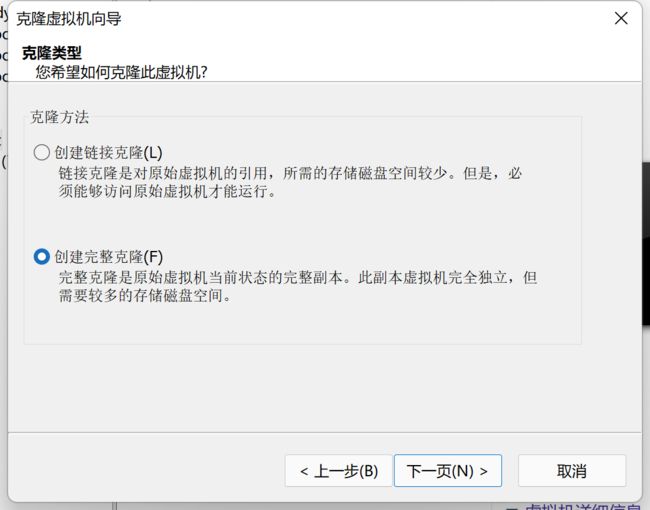
继续下一步即可。完成后,记得克隆三台虚拟机。并完成改名和ip地址的修改。做好远程连接。
开始搭建分布式集群
已经创建好了三台虚拟机。
安装jdk和Hadoop可以参考这篇文章jdk和Hadoop的安装
我们可以在其中一台机器上面安装jdk和Hadoop的安装,之后我们不是做好网络服务的配置了 嘛,我们可以分发给其他主机即可。
可以先将虚拟机切换到pier用户su pier,输入设置的pier密码就可以了
scp分发文件
#基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
例:
[pier@hadoop105 ~]# scp -r /opt/module/jdk1.8.0_212/pier@hadoop106:/opt/module/
rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av p d i r / pdir/ pdir/fname u s e r @ h a d o o p user@hadoop user@hadoophost: p d i r / pdir/ pdir/fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
- 选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
(2)案例实操
- 把hadoop105机器上的/opt/software目录同步到hadoop106服务器的/opt/software目录下
[pier@hadoop105 ~]# rsync -av /opt/software/* pier@hadoop106:/opt/software
当我们一个一个文件发的太累了怎们办呢?自己写一个脚本吧,嘻嘻,我觉得可。说干就干
[pier@hadoop105 opt]$ cd /home/pier
[pier@hadoop105 ~]$ mkdir bin
[pier@hadoop105 ~]$ cd bin
[pier@hadoop105 bin]$ vim my
my_xsync.sh 编辑文件
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop106 hadoop107
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
保存退出wq
修改文件执行权限
[pier@hadoop105 bin]$ chmod +x my_xsync.sh
将脚本复制到/bin中,以便全局调用
[pier@hadoop105 bin]$ sudo cp my_xsync.sh/bin/
测试脚本
[pier@hadoop105 bin]$ my_xsync.sh /home/pier/bin
[pier@hadoop105 bin]$ sudo my_xsync.sh /bin/xsync
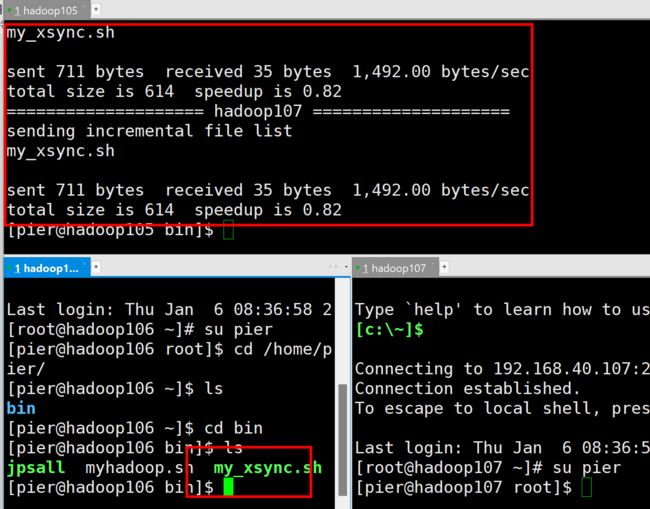
这里就使用下面这条命令把Hadoop和jdk分发过去吧
[pier@hadoop105 bin]$ my_xsync.sh /opt/module/*
[pier@hadoop105 bin]$ my_xsync.sh /etc/profile.d/my_env.sh
,那我们来一起测试一下吧。可以偷个懒使用这个工具哟,超好用。
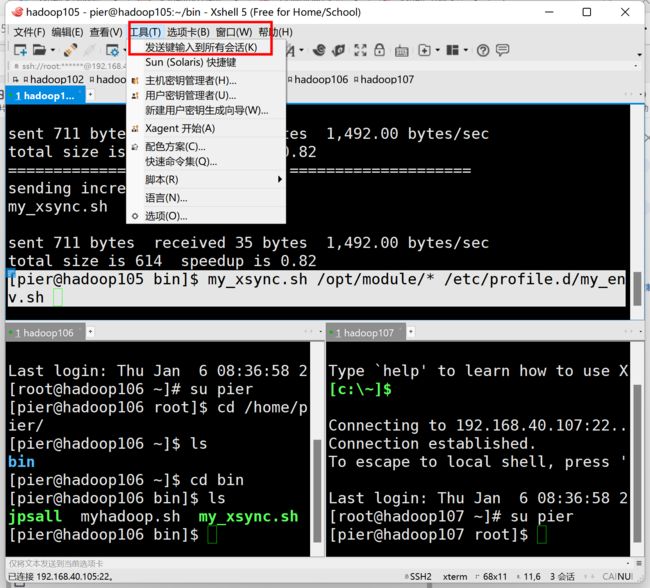
检查环境命令
[pier@hadoop105 bin]$ java -version
[pier@hadoop105 bin]$ hadoop version
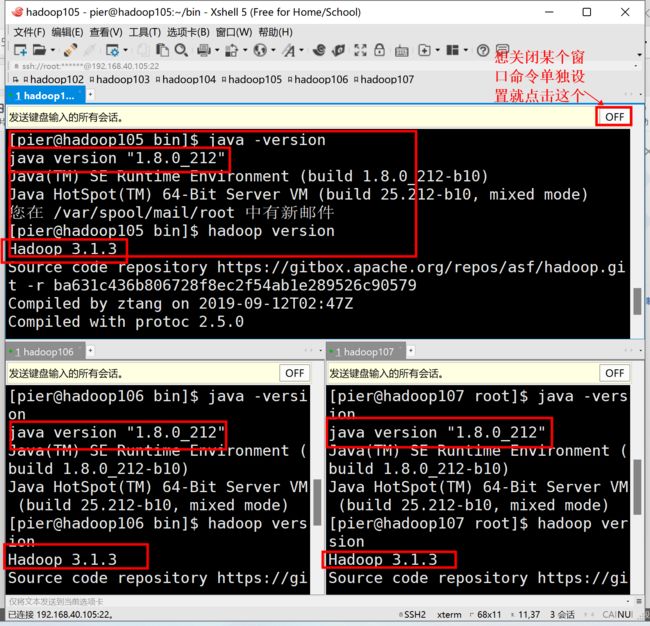
ssh免密登录
不知道你们分发文件时是不是有个和我不一样的地方,哈哈哈我不用输密码,你们需要输入密码呢,接下来我们就来一起设置一下免密登录。全部设置哟,先看一下免密登录原理:
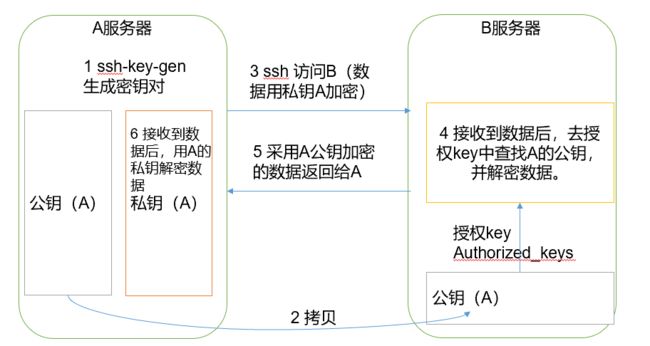
生成公钥和私钥
[pier@hadoop105 bin]$ ssh-keygen -t rsa
输入上面这个命令后三个回车搞定。
将公钥拷贝到要免密登录的目标机器上
[pier@hadoop105 bin]$ ssh-copy-id hadoop105
[pier@hadoop105 bin]$ ssh-copy-id hadoop106
[pier@hadoop105 bin]$ ssh-copy-id hadoop107
使用时需要输入目标机器的密码,你输入就行,首次使用或许还要选择yes或者no你选择yes即可。
| 目录 | 功能 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
集群配置
哇,写了这么久终于到集群配置了,开始开始!!!
正所谓无规矩不成方圆,我们先来规划规划,说一些注意事项
集群规划
- 注意:NameNode和SecondaryNameNode不要安装在同一台服务器
- 注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop105 | hadoop106 | hadoop107 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
注:下面这些配置文件,可以选择性更改,我这里更改主要是因为你的个人电脑应该负荷不起它的默认配置。
默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/ core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/ hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/ yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/ mapred-default.xml |
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
核心配置文件
配置core-site.xml
[pier@hadoop105 ~]$ cd $HADOOP_HOME/etc/hadoop
[pier@hadoop105 hadoop]$ vim core-site.xml
文件内容如下:
"1.0" encoding="UTF-8"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- 指定NameNode的地址 -->
fs.defaultFS</name>
hdfs://hadoop102:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
hadoop.tmp.dir</name>
/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
hadoop.http.staticuser.user</name>
atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
hadoop.proxyuser.atguigu.hosts</name>
*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
hadoop.proxyuser.atguigu.groups</name>
*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
hadoop.proxyuser.atguigu.groups</name>
*</value>
</property>
</configuration>
HDFS配置文件
配置hdfs-site.xml
[pier@hadoop105 hadoop]$ vim hdfs-site.xml
文件内容如下:
"1.0" encoding="UTF-8"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- nn web端访问地址-->
dfs.namenode.http-address</name>
hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
dfs.namenode.secondary.http-address</name>
hadoop104:9868</value>
</property>
</configuration>
YARN配置文件
配置yarn-site.xml
[pier@hadoop105 hadoop]$ vim yarn-site.xml
文件内容如下:
"1.0" encoding="UTF-8"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- 指定MR走shuffle -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
yarn.resourcemanager.hostname</name>
hadoop103</value>
</property>
<!-- 环境变量的继承 -->
yarn.nodemanager.env-whitelist</name> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 这下面的内容可以选择性添加 -->
<!-- yarn容器允许分配的最大最小内存 -->
yarn.scheduler.minimum-allocation-mb</name>
512</value>
</property>
yarn.scheduler.maximum-allocation-mb</name>
4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
yarn.nodemanager.resource.memory-mb</name>
4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
yarn.nodemanager.pmem-check-enabled</name>
false</value>
</property>
yarn.nodemanager.vmem-check-enabled</name>
false</value>
</property>
</configuration>
MapReduce配置文件
配置mapred-site.xml
[pier@hadoop105 hadoop]$ vim mapred-site.xml
文件内容如下:
"1.0" encoding="UTF-8"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- 指定MapReduce程序运行在Yarn上 -->
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>
在集群上分发配置好的Hadoop配置文件
[pier@hadoop105 hadoop]$ my_xsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/
去106和107上查看文件分发情况
[pier@hadoop106 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[pier@hadoop107 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
配置works
[pier@hadoop105 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
添加下面内容
hadoop105
hadoop106
hadoop107
分发works文件
[pier@hadoop105 bin]$ my_xsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/workers
启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
- 格式化集群
[pier@hadoop105 hadoop]$ hdfs namenode -format
- 启动HDFS(hadoop105上)
[pier@hadoop105 hadoop-3.1.3]$ cd /opt/module/hadoop-3.1.3/
[pier@hadoop105 hadoop-3.1.3]$ sbin/start-dfs.sh
- 启动yarn(hadoop106)
[pier@hadoop106 hadoop-3.1.3]$ sbin/start-yarn.sh
- Web端查看HDFS的NameNode
- 浏览器中输入:http://hadoop102:9870
- 查看HDFS上存储的数据信息
- Web端查看YARN的ResourceManager
- 浏览器中输入:http://hadoop103:8088
- 查看YARN上运行的Job信息
jps查看进程
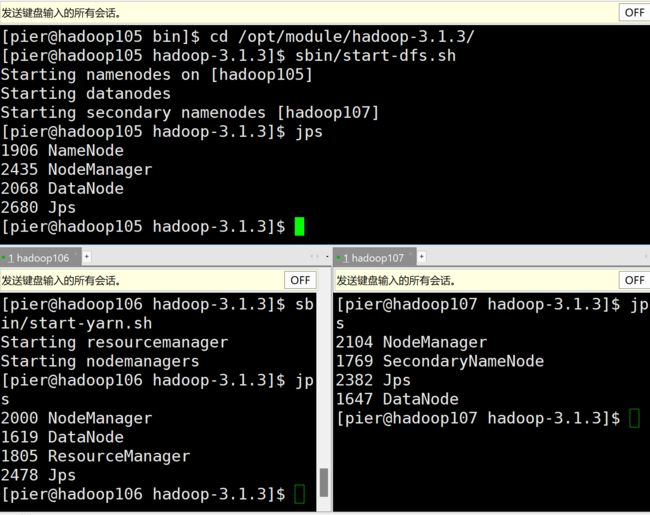
到这里我们的分布式集群搭建完毕了,当然我们后续还会在里面安装zookeeper等其他工具包,后续再说。
常见问题
1、 ping三端ping不通
解决方式:
- 查看自己的外网是否连通
- 检查
/etc/sysconfig/network-scripts/ifcfg-ens33是否配置正确 - 是否生效环境变量,source无效,试试重启虚拟机。
2、jdk安装完毕后,Hadoop version失败。
解决方式:
- 这里出现的可能性不大,但是假如出现了,你可以尝试先将Hadoop和jdk删除,并卸载系统自带openjdk
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps,再重启过后重新安装jdk和Hadoop。
3、jps出现有问题
解决方式:
- 这是一种很常见的的问题,常见的问题有,你的虚拟机配置文件有问题,自我进行排除查找。
- 第二种就是你重启服务器过后结点启动失败,这时候我们需要
$HADOOP_HOME/sbin/stop-all.sh把所有节点关闭,再把$HADOOP_HOME下面的data和logs文件删掉,重新进行格式化,再启动节点。
4、 出现下面这种情况
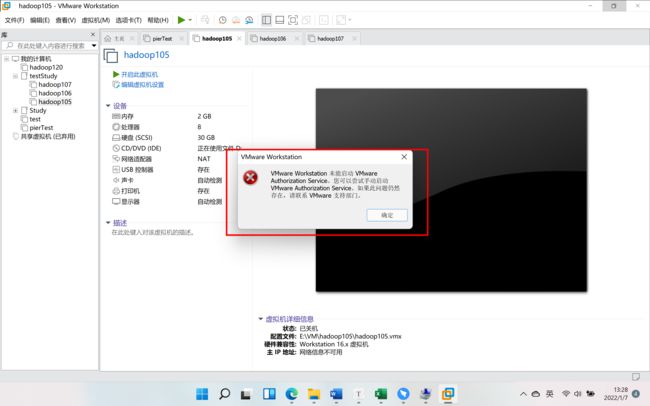
解决方式:
按住win+x选择计算机管理
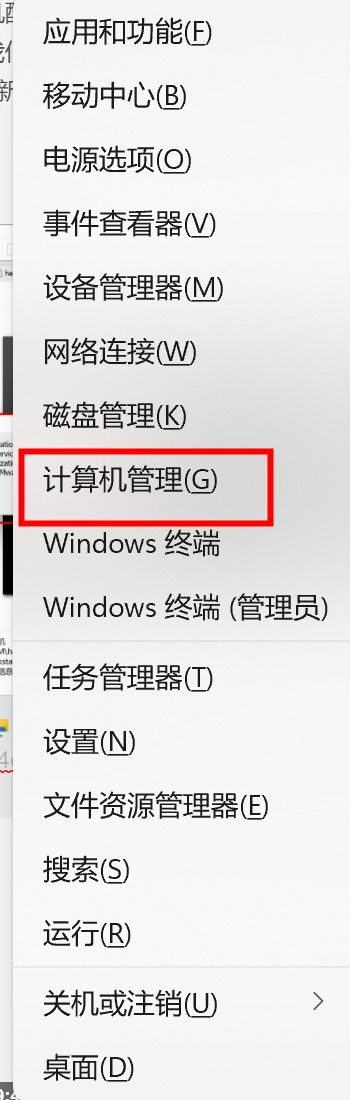
选择服务
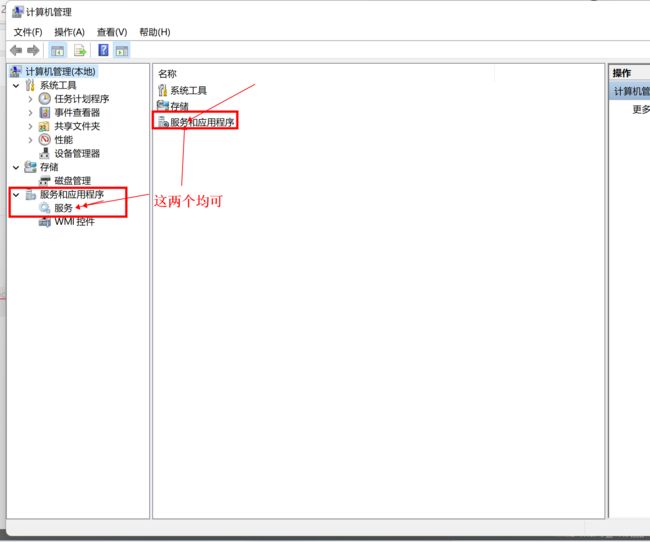
找到VMware开头的服务全部启动
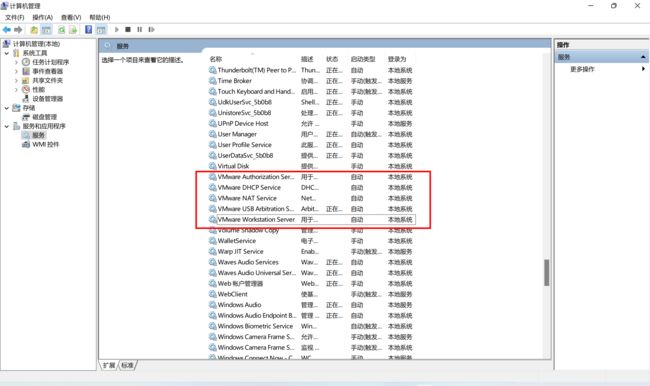
之后退出关闭,再重启一下VMware就可以了。
这一章的图片太多了,大家搭建完了,给大家来个小奖励吧

如果大家又遇到什么其他问题,可以评论区告诉我,或者私信我哟,我看到了也可以添加进入我的博客哈哈。