每天一篇论文 373/1000 PSEUDO-LIDAR++:ACCURATE DEPTH FOR 3D OBJECT DETECTION IN AUTONOMOUS DRIVING
论文阅读汇总list
PSEUDO-LIDAR++:ACCURATE DEPTH FOR 3D OBJECT DETECTION IN AUTONOMOUS DRIVING
Code
Pseudo-LiDAR from Visual Depth Estimation:Bridging the Gap in 3D Object Detection for Autonomous Driving
本文了一种新的图形传(GCD)播算法,它集成了两种数据模式,并使用两个稀疏矩阵求解器来传播稀疏但精确的深度估计。得到的系统是准激光雷达++ (SDN + GDC),其性能几乎与64波束激光雷达系统相当,价格为7.5万美元,但只需要4波束和两个商用摄像机,总成本不到1000美元。
摘要
汽车、行人等物体的三维检测在自动驾驶中起着不可或缺的作用。现有的方法主要依赖于昂贵的激光雷达传感器来获取精确的深度信息。虽然最近伪激光雷达已经被作为一个有希望的替代,以更低的成本,完全基于立体图像,仍然有一个显着的性能差距。本文通过对立体深度估计的改进,对伪激光雷达框架进行了实质性的改进。具体地说,我们调整了立体网络结构和损失函数,使之更符合精确地估计遥远目标的深度——这是目前伪激光雷达的主要弱点。进一步,我们探索了利用更便宜但非常稀疏的激光雷达传感器的想法,仅为三维检测提供不足的信息,去提高·我们的深度估计。我们提出了一种深度传播算法,在初始深度估计的指导下,将这些精确的测量数据分散到整个深度图中。我们在KITTI对象检测基准上表明,我们的组合方法在深度估计和基于体视的3D对象检测方面取得了显著的改进——比以前的最先进的远程对象检测精度提高了40%。
方法
pseudo-LIDAR
该框架应用了一种与以前基于图像的3D对象检测器截然不同的方法。而不是直接检测额的3 d边界框的一个场景,pseudo-LiDAR始于基于图像深度估计,预测的深度Z (u, v)每个图像像素(u, v)。由此产生的深度图然后Z是back-projected成一个三维点云:一个像素(u, v)将转化为3 d (x, y, Z):

式中 ( c U , c V ) (c_U,c_V) (cU,cV),为相机中心, ( f U , f V ) (f_U,f_V) (fU,fV)为水平和垂直焦距。
Stereo disparity estimation
视差估计算法采用一对来自 I l 和 I r I_l和I_r Il和Ir输入的左右图像,这些图像是从一对带有水平偏移量(即b.在不失一般性的前提下,我们假设算法将左图像 I l I_l Il作为参考,输出一个视差图D,记录每个像素(u, v)的水平视差,理想情况下, I l ( u , v ) I_l(u,v) Il(u,v)和 I r ( u , v + D ( u , v ) ) I_r(u,v+D(u,v)) Ir(u,v+D(u,v))将绘制出相同的3D位置。因此,我们可以通过以下变换得到深度映射Z:
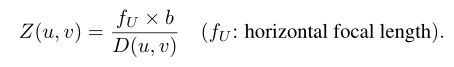
双目深度网络(SDN)
本文的深度估计算法与激光雷达和其他双目算法对比:

双目深度估计主要核心就是3D convolutions ,本文建立了一个新的深度层:

作者的双目估计还是主要依赖月PSMNet,详细了解可以查看该文章。
深度校正
我们提出了一种基于图形的深度校正(GDC)算法,它有效地结合了具有渲染对象形状的密集立体深度和稀疏精确的激光雷达测量。从概念上讲,我们希望修正后的深度图具有以下属性:全局性,与激光雷达点相关联的地标像素应该具有准确的深度;在局部,由邻近的3D点捕获,从输入深度图反向投影的物体形状(参看公式1)应该被保留。图5(底部)演示了该算法

其中这里面的深度关联主要是让稀疏的激光点云能够指导其周围深度值的更新,必须对邻居的邻居进行校正,并且少数n个点的深度在整个图中传播。我们可以用另一个二次优化直接求解最终的z0::

实验


GDC实验效果
