Pytorch学习笔记:(一)神经网络解决回归问题
文章目录
-
- 前置知识
-
- 数据生成
- 批训练数据打包
-
- DataLoader参数解释
- 建立神经网络
-
- 正常的方法
- 快速的方法
- 损失函数
- 优化器
- 训练
- 测试
- 参考代码
- 心得
前置知识
数据生成
我们先生成最简单的二次函数。
import torch
x = torch.unsqueeze(torch.linspace(-5, 5, 100000), dim=1)
y = x.pow(2)+2*torch.rand(x.size())
test_x = torch.unsqueeze(torch.linspace(-5, 5, 1000), dim=1)
test_y = test_x.pow(2)+2*torch.rand(test_x.size())
torch.linspace:等差数列插值。在示例中,就是在-5~5之间均匀地插入100000torch.unsqueeze:维度扩充。我们生成的数据是1维的,我们需要在生成一位才能满足需要。torch.rand: [ 0 , 1 ) [0,1) [0,1)随机数均匀生成。我们给数据增加一定的混乱度。如果想要生成正态分布可以使用torch.randn
如果想要看到生成的函数图像可以借助matplotlib
参考代码如下
import matplotlib.pyplot as plt
import numpy as np
plt.scatter(test_x.data.numpy(),test_y.data.numpy(),s=2 * np.ones(test_x.size()))
plt.show()
批训练数据打包
import torch.utils.data as data
BATCH_SIZE = 100
train_dataset = data.TensorDataset(x, y)
train_loader = data.dataloader.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=1,
)
DataLoader参数解释
dataset:数据集,不解释。batch_size:每批的数据大小shuffle:是否打乱数据集num_workers:使用多进程加载的进程数,0代表不使用多进程。记得如果要多进程要放在main里面不然会报错的。
建立神经网络
正常的方法
(为什么叫正常的方法因为下面有快速的方法
import torch.nn.functional as f
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = f.relu(self.hidden(x))
x = self.predict(x)
return x
torch.nn.Module:我们建的神经网络需要继承Pytorch中原有的神经网络模块(Neural Network)。__init__(self):构造函数Linear:全连接网络。Linear(x,y)代表输入参数有x个输出参数有y个。relu:激活函数 r ( x ) = max ( 0 , x ) r(x)=\max(0,x) r(x)=max(0,x),还有其他的激活函数比如tanh,sigmoid都是比较常用的。
快速的方法
net = torch.nn.Sequential(
torch.nn.Linear(1, 20),
torch.nn.ReLU(),
torch.nn.Linear(20, 1)
)
损失函数
损失函数就是计算预测结果和实际相差多少的一个函数。
| 名称 | 适用问题 |
|---|---|
| L1Loss(L1范数损失) | 回归问题 |
| MSELoss(均方误差损失) | 回归问题 |
| CrossEntropyLoss(交叉熵损失) | 多分类问题 |
优化器
就是通过某种方法来找到让损失函数下降最快。
常用的有Adam和RMSProp。但是这两个优化器虽然效果好,但是感觉不太好理解其中的原理,所以一般老师教学的时候基本都是从SGD开始的。
在Pytorch中优化器有一个很重要的参数就是lr(Learning Rate)。这个是决定优化器的学习效率的,如果设太高可能会导致过拟合,甚至有些神经元永远没法被激活。
| 优化器名称 | 优化器解释 |
|---|---|
| SGD | 随机梯度下降算法 |
| Momentum | 带动量随机梯度下降算法 |
| RMSprop | 弹性反向传播 |
| ASGD | 随机平均梯度下降 |
| Adam | 将Momentum算法和RMSProp算法结合起来使用的一种算法(推荐) |
| RMSProp | 均方根传递(推荐) |
训练
def train(epoch):
for step, (batch_x, batch_y) in enumerate(loader):
prediction = net(batch_x)
loss = loss_function(prediction, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step%200==0 :
print('Train Epoch: {} [{:05d}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, step * len(batch_x), TRAIN_SIZE,
100 * step * len(batch_x) / TRAIN_SIZE, loss.item()))
zero_grad():梯度清零backward():误差反向传播step():更新参数
测试
def test(epoch):
prediction = net(test_x)
loss = loss_function(prediction,test_y)
print('Test Epoch: {}\tAverage: {:.4f}\n'.format(epoch,loss.item()/TEST_SIZE))
参考代码
import torch
import torch.nn.functional as f
import torch.utils.data as data
import numpy as np
import matplotlib.pyplot as plt
from torch import Tensor
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = f.relu(self.hidden(x))
x = self.predict(x)
return x
# 常量
BATCH_SIZE = 100
EPOCH = 6
TRAIN_SIZE=100000
TEST_SIZE=1000
net = Net()
x = torch.unsqueeze(torch.linspace(-5, 5, TRAIN_SIZE), dim=1)
y = x.pow(2)+2*torch.rand(x.size())
test_x = torch.unsqueeze(torch.linspace(-5, 5, TEST_SIZE), dim=1)
test_y = test_x.pow(2)+2*torch.rand(test_x.size())
def train(epoch):
for step, (batch_x, batch_y) in enumerate(loader):
prediction = net(batch_x)
loss = loss_function(prediction, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step%200==0 :
print('Train Epoch: {} [{:05d}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, step * len(batch_x), TRAIN_SIZE,
100 * step * len(batch_x) / TRAIN_SIZE, loss.item()))
def test(epoch):
prediction = net(test_x)
loss = loss_function(prediction,test_y)
print('Test Epoch: {}\tloss: {:.4f}\n'.format(epoch,loss.item()))
if __name__ == '__main__':
torch_dataset = data.TensorDataset(x, y)
loader = data.dataloader.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=1,
)
loss_function = torch.nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(EPOCH):
train(epoch)
test(epoch)
prediction = net(test_x)
loss = loss_function(prediction, test_y)
plt.clf()
plt.xlim(-5, 5)
plt.ylim(0, 30)
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), s=2 * np.ones(test_x.size()))
plt.plot(test_x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(2, 0.2, 'Loss=%.4f' % loss.item(), fontdict={'size': 15, 'color': 'black'})
plt.show()
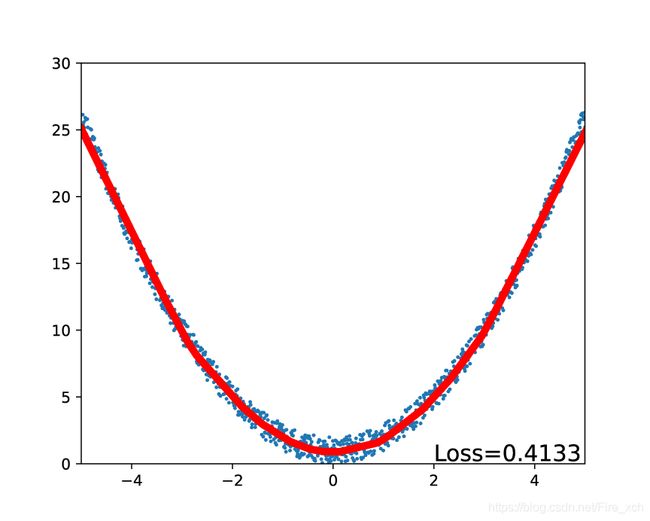
心得
我为什么要进行分批训练呢,第一个原因当然是这可以提高准确性,还有一个也十分重要的问题就是,当你一次性输入的点过多时,尤其是我这种是直接把loss全部加起来的人极有可能会产生梯度爆炸,在实验的时候就有几次就梯度爆炸了,我都不知道这是啥原因,后来问了一下老师,老师估计了一下是梯度爆了。