深度学习:数据预处理_案例写法汇总
目录
- 数据加载
- 案例一:猫狗分类
-
- 数据集展示:
- 数据增强
- 数据读取,加载
- 查看数据集数量及种类
- 训练数据可视化
- 案例二:交通指示牌识别-4分类
-
- 数据集展示
- 查看数据集
-
- 查看数据集大小
- 查看图片
- 数据集分割
-
- 选择的4个类别
- 新建目录
- 拷贝数据到目标文件夹
- 数据增强
- 数据加载读取
- 可视化数据增强的图片
- 案例三:肺部识别
-
- 数据增强
- 加载数据集
- 查看数据集信息
- 展示图片
数据加载
若数据集里无分类文件,全是照片,用ImageFolder()时,应在数据集文件里自己建一个文件夹,在写数据路径时应写到上一层文件夹.
如下例路径

路径应为![]()
案例一:猫狗分类
参考:https://blog.csdn.net/qq_42951560/article/details/109950786.
代码位置:E:\项目例程\猫狗分类\迁移学习\猫狗_resnet18_2 \猫狗分类_迁移学习可视化
数据集展示:
数据增强
#---数据增强----
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
数据读取,加载
当数据集已经自觉按照要分配的类型分成了不同的文件夹,一种类型的文件夹下面只存放一种类型的图片,定义数据读取时,使用 torchvision包中的ImageFolder类会比Dataset类会更方便
#----制作数据集----
image_datasets = {
x: datasets.ImageFolder(
root=os.path.join('./catsdogs', x),
transform=data_transforms[x]
) for x in ['train', 'val']
}
#----数据加载器---
dataloaders = {
x: DataLoader(
dataset=image_datasets[x],
batch_size=16,
shuffle=True,
num_workers=0
) for x in ['train', 'val']
}
查看数据集数量及种类
#------相关信息打印-----
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
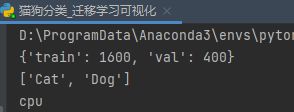
print(dataset_sizes)
print(class_names)
print(device)
结果展示:
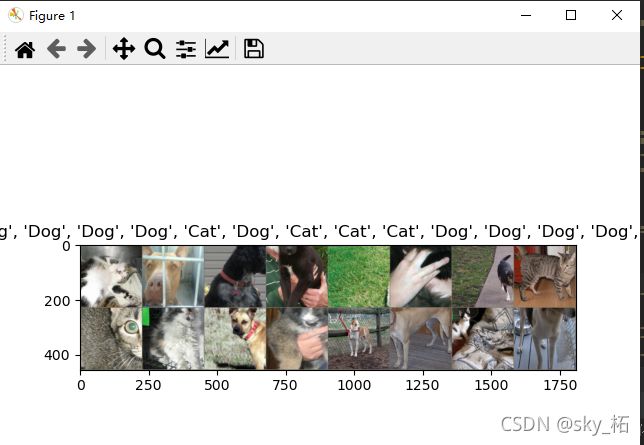
训练数据可视化
#----训练数据可视化-----
inputs, labels = next(iter(dataloaders['train']))
grid_images = torchvision.utils.make_grid(inputs)
def no_normalize(im):
im = im.permute(1, 2, 0)
im = im*torch.Tensor([0.229, 0.224, 0.225])+torch.Tensor([0.485, 0.456, 0.406])
return im
grid_images = no_normalize(grid_images)
plt.title([class_names[x] for x in labels])
plt.imshow(grid_images)
plt.show()
结果展示:
案例二:交通指示牌识别-4分类
参考:b站交通指示牌4分类迁移学习
代码位置:E:\项目例程\交通指示灯\迁移学习_交通道路识别\交通指示牌识别4分类_迁移学习
数据集展示
查看数据集
查看数据集大小
注意:使用opencv加载图片,路径应为全英文
Train_Path= r'E:\data\GTSRB\Final_Training\Images\*'
Test_Path = r'E:\data\GTSRB\Final_Test\Images\*'
# 训练集文件夹
train_folders = sorted(glob(Train_Path)) #根据路径读取文件
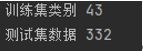
print("训练集类别",len(train_folders))
# 测试集文件
test_files = sorted(glob(Test_Path))
print("测试集数据",len(test_files))
输出:
查看图片
# 函数:根据路径,加载图片
def load_image(img_path, resize=True):
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2BGRA) # 根据路径读取图片,并进行灰度转换
if resize:
img = cv2.resize(img, (64, 64)) # 改变图片尺寸大小
return img
# 函数:显示图片
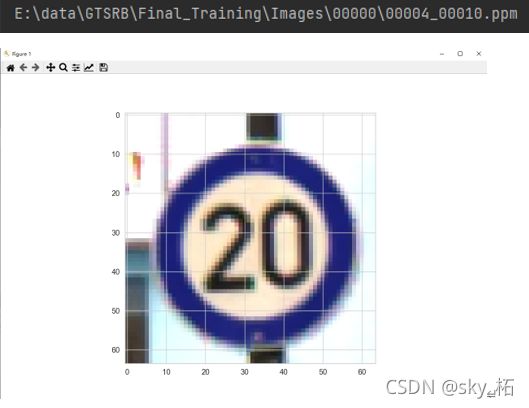
def show_img(img_path):
img = load_image(img_path) # 调用函数
plt.imshow(img) # 显示
plt.show()
plt.axis('off') # 关闭坐标轴
# 依次从43个文件夹中, 从每个文件夹中随机获取一张图片的路径
sample_images = [np.random.choice(glob(f'{file_name}/*ppm')) for file_name in train_folders]
print(sample_images[0] )# 第一张图片的路径
# 显示第一张图片
show_img(sample_images[0])
print("第一张图片显示完毕")
输出:
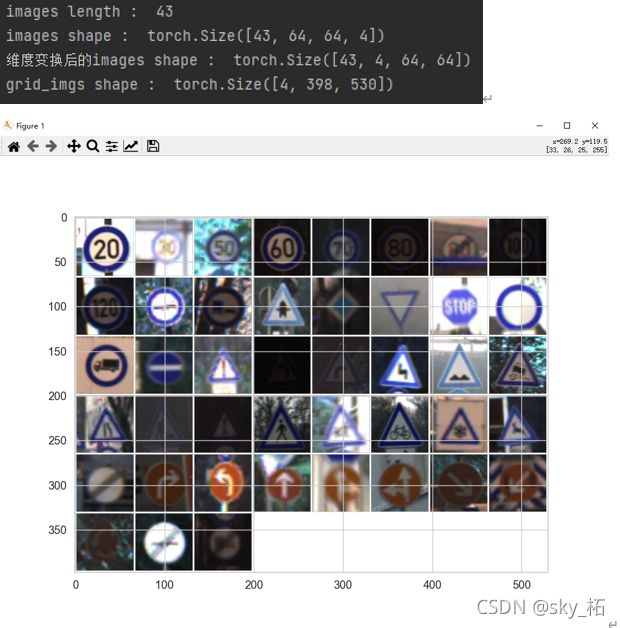
# 函数:显示一批图片(一个网格所包含的图片)
def show_imgs_grid(img_paths):
"""
img_paths : 很多图片的路径
"""
images = [load_image(path) for path in img_paths] # 根据路径,读取一批图片
print("images length : ", len(images))
images = torch.as_tensor(images) # list类型转换为tensor类型 as_tensor 类型转换范围更广
print("images shape : ", images.shape)
images = images.permute(0, 3, 1, 2) # 维度换位 表示位置,索引下标 0:43张图片 3:3通道位置 1:宽度 2:高度
print("维度变换后的images shape : ", images.shape)
grid_imgs = torchvision.utils.make_grid(images, nrow=8) # 将若干幅图像拼成一幅图像
plt.figure(figsize=(24, 12)) # 画布大小
print("grid_imgs shape : ", grid_imgs.shape)
plt.imshow(grid_imgs.permute(1, 2, 0)) # 维度交换
plt.show()
plt.axis('off') # 关闭坐标轴
# 显示这批图片
show_imgs_grid(sample_images)
print('显示这一批图片')
输出:
数据集分割
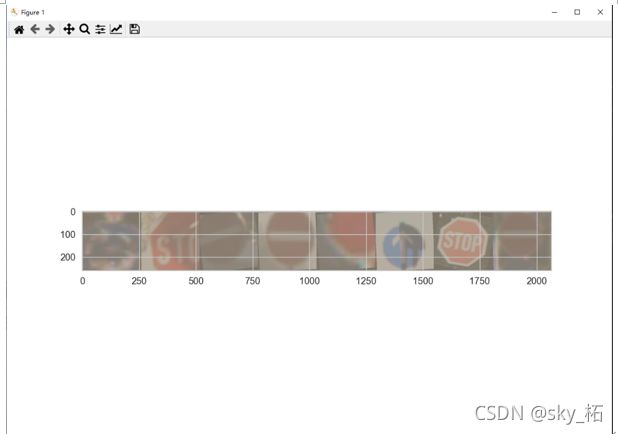
原本数据集有43个类别,现取出4个类别进行分类训练。
选择的4个类别
# ---选择4个类别分类,类别名称
class_names = ['STOP', '禁止通行', '直行', '环岛行驶']
# 类别对应的文件夹序号: 00014, 00017, 00035, 00040
class_indices = [14, 17, 35, 40]
新建目录
# 新建目录,将原始的train数据集分割成:train, val, test, 比例是70%, 20%, 10%
DATA_DIR = Path('New_Data_4_classes')
DATASETS = ['train', 'val', 'test']
for dt in DATASETS:
for cls in class_names:
(DATA_DIR/dt/cls).mkdir(parents=True, exist_ok=True) # exist_ok为True,则在目标目录已存在的情况下不会触发FileExistsError异常
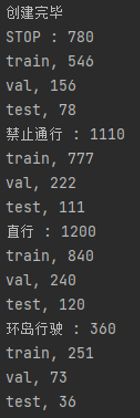
print("创建完毕")
拷贝数据到目标文件夹
# 从原始数据集拷贝图片到目标文件夹--------
for i, cls_index in enumerate(class_indices):
image_paths = np.array(glob(f'{train_folders[int(cls_index)]}/*.ppm')) # 标签对应的所有图片路径
class_name = class_names[i] # 标签和名称对应
print(f'{class_name} : {len(image_paths)}')
np.random.shuffle(image_paths) # 打乱图片路径
# 数据集切分,train : 70%, val : 20%, test : 10%
# 本质上是索引切分
ds_split = np.split(
image_paths,
indices_or_sections=[int(0.7 * len(image_paths)), int(0.9 * len(image_paths))]
) #0-69 张图片 90对应89序号切一刀
# 拼接
dataset = zip(DATASETS, ds_split)
for dt, img_pathes in dataset:
print(f'{dt}, {len(img_pathes)}')
for path in img_pathes:
# 拷贝图片
shutil.copy(path, f'{DATA_DIR}/{dt}/{class_name}/')
输出:
数据增强
# 数据增强
mean_nums = [0.485, 0.456, 0.406]
std_nums = [0.229, 0.224, 0.225]
transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256), # 随机裁剪
transforms.RandomRotation(degrees=15), # 随机旋转
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为tensor
]),
'val': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
]),
'test': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
])
}
数据加载读取
统计train, val, test 数据集大小
# 定义数据加载器(ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名)
Image_datasets = {
d : ImageFolder(f'{DATA_DIR}/{d}', transform[d]) for d in DATASETS
}
print("数据加载完毕")
# 批数据读取
data_loaders = {
d : DataLoader(Image_datasets[d], batch_size=16, shuffle=True, pin_memory=True)
for d in DATASETS
}
print("数据读取完毕")
# 统计train, val, test 数据集大小
dataset_size = {d : len(Image_datasets[d]) for d in DATASETS}
print("统计train, val, test 数据集大小",dataset_size)
# 查看train的类别
class_names = Image_datasets['train'].classes
print("查看train的类别",class_names)

可视化数据增强的图片
# -------可视化显示数据增强后的图片(!!!注意:中文字符显示)-----
from matplotlib.font_manager import FontProperties
def imshow(inp, title=None):
my_font = FontProperties(fname='SimHei.ttf', size=12)
inp = inp.numpy().transpose((1,2,0)) # 转置
mean = np.array([mean_nums])
std = np.array([std_nums])
inp = std * inp + mean # 还原
inp = np.clip(inp, 0, 1) # 限制像素值在0~1之间
plt.imshow(inp)
plt.show()
if title is not None:
plt.title(title, fontproperties=my_font)
plt.axis('off')
# 获取一批数据 batchsize=8一批数据
inputs, labels = next(iter(data_loaders['train']))
out = torchvision.utils.make_grid(inputs) #拼在一起显示
imshow(out, title=[class_names[x] for x in labels]) #lable索引,下标
print("可视化数据增强结果完毕")
案例三:肺部识别
参考教程:B站肺部识别案例详解
代码位置:E:\项目例程\肺部识别\肺部识别_迁移学习_优化
数据增强
# 分为为train, val, test定义transform
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=300, scale=(0.8, 1.1)), # 功能:随机长宽比裁剪原始图片, 表示随机crop出来的图片会在的0.08倍至1.1倍之间
transforms.RandomRotation(degrees=10), # 功能:根据degrees随机旋转一定角度, 则表示在(-10,+10)度之间随机旋转
transforms.ColorJitter(0.4, 0.4, 0.4), # 功能:修改亮度、对比度和饱和度
transforms.RandomHorizontalFlip(), # 功能:水平翻转
transforms.CenterCrop(size=256), # 功能:根据给定的size从中心裁剪,size - 若为sequence,则为(h,w),若为int,则(size,size)
transforms.ToTensor(), # numpy --> tensor
# 功能:对数据按通道进行标准化(RGB),即先减均值,再除以标准差
transforms.Normalize([0.485, 0.456, 0.406], # mean
[0.229, 0.224, 0.225]) # std
]),
'val': transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], # mean
[0.229, 0.224, 0.225]) # std
]),
'test': transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], # mean
[0.229, 0.224, 0.225]) # std
])
}
加载数据集
#-----加载数据集----------
# 数据集所在目录路径
data_dir = './chest_xray/'
# train路径
train_dir = data_dir + 'train/'
# val路径
val_dir = data_dir + 'val/'
# test路径
test_dir = data_dir + 'test/'
# 从文件中读取数据
datasets = {
'train' : datasets.ImageFolder(train_dir, transform=image_transforms['train']), # 读取train中的数据集,并transform
'val' : datasets.ImageFolder(val_dir, transform=image_transforms['val']), # 读取val中的数据集,并transform
'test' : datasets.ImageFolder(test_dir, transform=image_transforms['test']) # 读取test中的数据集,并transform
}
# 定义BATCH_SIZE
BATCH_SIZE = 32 # 每批读取128张图片
# DataLoader : 创建iterator, 按批读取数据
dataloaders = {
'train' : DataLoader(datasets['train'], batch_size=BATCH_SIZE, shuffle=True), # 训练集
'val' : DataLoader(datasets['val'], batch_size=BATCH_SIZE, shuffle=True), # 验证集
'test' : DataLoader(datasets['test'], batch_size=BATCH_SIZE, shuffle=True) # 测试集
}
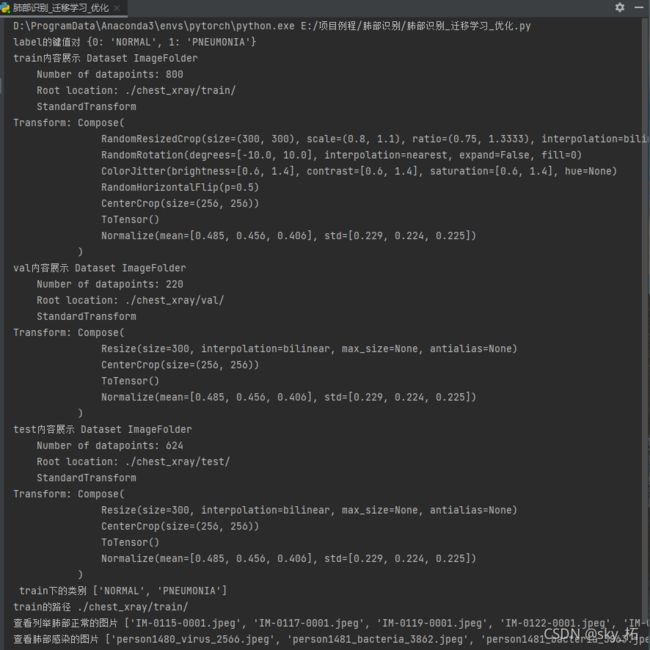
查看数据集信息
# 创建label的键值对
LABEL = dict((v, k) for k, v in datasets['train'].class_to_idx.items())
print('label的键值对',LABEL)
# 数据集简介
print('train内容展示',dataloaders['train'].dataset)
print('val内容展示',dataloaders['val'].dataset)
print('test内容展示',dataloaders['test'].dataset)
# train下的类别
print(' train下的类别',dataloaders['train'].dataset.classes)
# train的路径
print('train的路径',dataloaders['train'].dataset.root)
# 查看列举肺部正常的图片
files_normal = os.listdir(os.path.join(str(dataloaders['train'].dataset.root), 'NORMAL'))
print('查看列举肺部正常的图片',files_normal)
# 肺部感染的图片
files_pneumonia = os.listdir(os.path.join(str(dataloaders['train'].dataset.root), 'PNEUMONIA'))
print('查看肺部感染的图片',files_pneumonia)
输出结果:
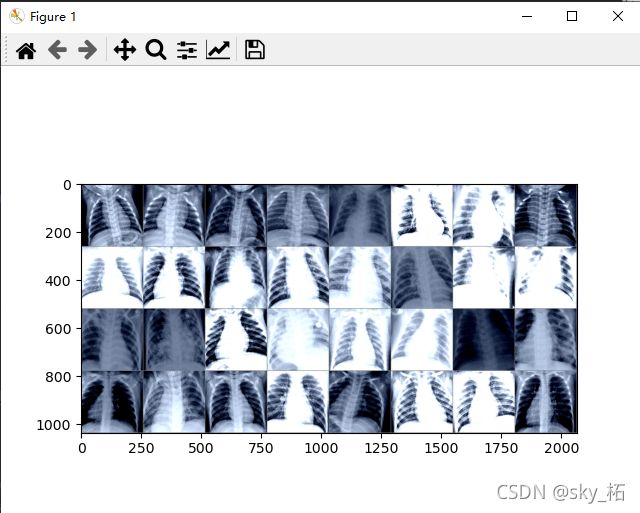
展示图片
展示一批图片
#-----可视化------
# 导入SummaryWriter
from torch.utils.tensorboard import SummaryWriter
# SummaryWriter() 向事件文件写入事件和概要
# 定义日志路径
log_path = 'logdir/'
# 定义函数:获取tensorboard writer
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S") # 时间格式
writer = SummaryWriter(log_path + timestr) # 写入日志
return writer
writer = tb_writer()
#----- 第1种方法:显示部分图片集------
images, labels = next(iter(dataloaders['train'])) # 获取到一批数据
print("获取数据完毕")
# 定义图片显示方法
def imshow(img):
img = img / 2 + 0.5 # 逆正则化
np_img = img.numpy() # tensor --> numpy
plt.imshow(np.transpose(np_img, (1, 2, 0))) # 改变通道顺序
plt.show()
grid = utils.make_grid(images) # make_grid的作用是将若干幅图像拼成一幅图像
imshow(grid) # 展示图片
print("展示一批图片完毕")
输出结果:
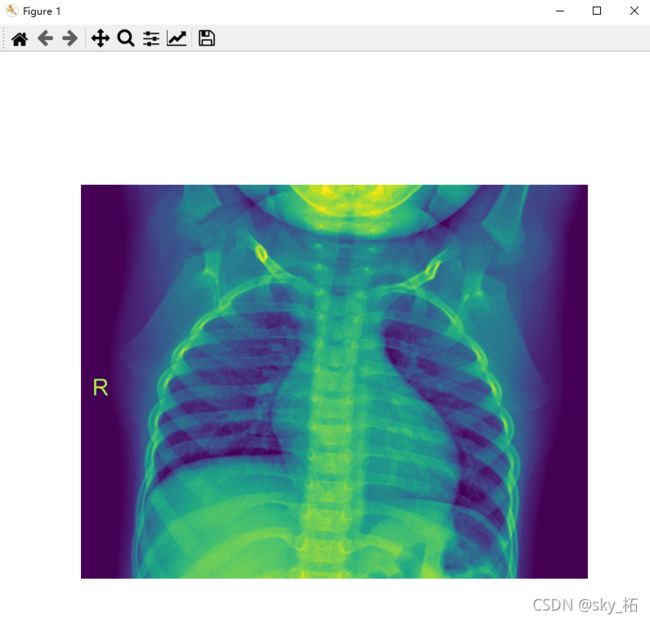
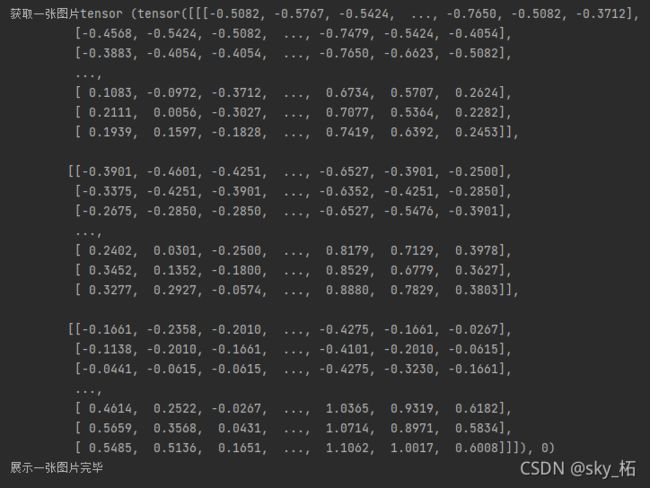
展示一张图片
# 获取一张图片tensor
print('获取一张图片tensor',dataloaders['train'].dataset[4]) # 返回:tensor, label
# 第3种方法:显示一张图片
def show_image(img):
plt.figure(figsize=(8, 8)) # 显示大小
plt.imshow(img) # 显示图片
plt.axis('off') # 关闭坐标轴
plt.show()
# 读取图片
one_img = Image.open(dataloaders['train'].dataset.root + 'NORMAL/IM-0239-0001.jpeg')
print('展示一张图片完毕')
# 调用函数
show_image(one_img)
输出结果: