什么是BST?什么是哈希表?一文带你了解并实现查找的基础知识
本文的全部代码均已上传Gitee MySearching~Star一下再走把;
文章目录
- 一、查找的基础概念
-
- 1.静态查找表:
- 2.动态查找表:
- 3.查找结构
- 二、顺序表查找
-
- 1.顺序表查找算法
- 2.顺序表查找优化
- 三、有序表查找
-
- 1.折半查找
- 2.插值查找
- 3.斐波那契查找
- 四、线性索引查找
-
- 1.稠密索引
- 2.分块索引
- 3.倒排索引
- 五、二叉排序树
-
- 1.二叉排序树的定义
- 2.二叉排序树的创建、插入和查找
-
- 2.1 二叉排序树的查找
- 2.2 二叉排序树的插入
- 2.3 二叉排序树的创建
- 3.二叉排序树的删除操作
- 4.二叉排序树的中序遍历
- 5.BST测试汇总
- 6.二叉排序树总结
- 六、平衡二叉树(AVL树)
-
- 1.AVL树的定义
- 2.AVL树的实现原理
-
- 2.1 右旋和左旋
-
- 2.1.1 左旋
- 2.1.2 右旋
- 2.2 右平衡操作
- 2.3左平衡操作
- 2.4 AVL树的插入
- 2.5 AVL树的创建
- 2.6 AVL树汇总
- 3.B树(多路查找树)
-
- 3.1 2-3树
- 3.1.1 2-3树的插入
- 3.1.2 2-3树删除的实现
- 3.2 2-3-4树
- 3.3 B树
- 3.4 B+树
- 七、散列表查找概述
-
- 1.散列表查找的定义
- 2.散列查找的步骤
- 3.散列函数的构造方法
-
- 3.1 直接定址法
- 3.2 数字分析法
- 3.3 平方取中法
- 3.4折叠法
- 3.5 除留余数法
- 3.6 随机数法
- 4.处理散列冲突的方法
-
- 4.1 开放定址法
- 4.2 再散列函数法
- 4.3 链地址法
- 4.4 公共溢出区法
- 八、散列表查找的实现
-
- 1.除留余数法+开放定址法
- 2.除留余数法+链地址法
- 3.除留余数法+公共溢出区法
- 4.散列表查找的性能分析
一、查找的基础概念
查找表是由同一类型的数据元素构成的集合。
**关键字是数据元素中某个数据项的值,又称为键值。**有时也叫关键码。
若此关键字可以唯一地标记一个记录,则称此关键字为主关键字(Primary Key)。
对于那些可以识别多个数据元素(或记录)的关键字,我们称为次关键字(secondary key)。
查找就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素。
1.静态查找表:
只做查找操作的查找表。
2.动态查找表:
在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。
3.查找结构
为了提高查找的效率,我们需要专门为查找操作设置数据结构,这种面向查找操作的数据结构称为查找结构。
从逻辑上来说,查找所基于的数据结构是集合,集合中的记录之间没有本质关系。可是如果想获得较高的查找性能,我们就不能不改变数据元素之间的关系,在存储时可以把数据集合组织成表、树等结构。
例如,对于静态表的查找来说,我们不妨应用线性数据结构来组织数据,这样可以使用顺序查找算法,如果再对主关键字排序,则可以应用折半查找等技术进行高效的查找。
如果需要动态查找,可能会复杂一些,我们可以考虑二叉排序树的查找技术或散列表结构来解决一些查找问题。
二、顺序表查找
顺序查找又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不相等,则表中没有所查的记录,查找失败。
1.顺序表查找算法
int Sequential_find(int* a, int n, int key)
{
for (int i = 0; i < n; i++)
{
if (a[i] == key)
return i;
}
return 0;
}
复杂的顺序表查找只要修改数组a和关键字key就行。
2.顺序表查找优化
上面算法的缺点是每次都要比较数组是否越界,我们可以设置一个哨兵位,解决每次都要让i和n做对比的问题
int Sequential_Search2(int* a, int n, int key)
{
int i = n;
a[0] = key;
while (a[i] != key)
{
i--;
}
return i;//返回0则说明查找失败
}
这两个算法的时间复杂度都是O(n),当n很大的时候,效率比较低下,不过我们可以把经常被查找的元素放在前面,把不常用的数据放在后面,效率就可以有大幅提高。
三、有序表查找
1.折半查找
折半查找(Binary Search)技术,又称为二分查找。它的前提是线性表中的数据记录必须满足关键字有序(通常是从小到大有序),线性表必须采用顺序存储。
它的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
int Binary_Search(int* a, int n, int key)
{
int left = 1;
int right = n;
//数组下标为0的哨兵位不用 用从1到n
while (left <= right)
{
int mid = (left + right) / 2;
if (key < a[mid])
{
right = mid - 1;
}
else if (key > a[mid])
{
left = mid + 1;
}
else
{
return mid;
}
}
return 0;//返回0表示查找失败
}
这种折半查找可以用一棵完全二叉树表示,树的结点数等于顺序表元素数n,根据完全二叉树的性质,n个结点的完全二叉树的深度k等于
k = [ l o g 2 n ] + 1 k=[log_{2}n]+1 k=[log2n]+1
所以最糟糕的情况下,我们要比较k次,这个算法的时间复杂度就是O(logn),他显然远好于顺序表查找的时间复杂度O(n)。
对于静态查找表,一次排序后不再变化,这个算法就算很好了,但是如果对动态查找表要频繁进行插入或删除操作来说,每次都要维护有序的排序,工作量很大,就不建议用这个算法了。
2.插值查找
在折半查找中,我们的mid是这样计算的:
m i d = l e f t + r i g h t 2 = l e f t + 1 2 ( r i g h t − l e f t ) mid=\frac{left+right}{2}=left+\frac{1}{2}(right-left) mid=2left+right=left+21(right−left)
关键就是这个1/2,这表明我们是公平的,不管key是多少,每次我们都是直接找到left和right的中点,这样的查找是不会去适应你的key值来计算mid是更靠近left一点还是更靠近right一点,基于这点思考,算法科学家们给出了新的求mid的公式:
m i d = l e f t + k e y − a [ l e f t ] a [ r i g h t ] − a [ l e f t ] ( r i g h t − l e f t ) mid=left+\frac{key-a[left]}{a[right]-a[left]}(right-left) mid=left+a[right]−a[left]key−a[left](right−left)
可以看到我们根据key值在自适应的调整mid值是更加靠近left还是更加靠近right,所以插值查找的算法如下:
int Insertpolation_Search(int* a, int n, int key)
{
if (key > a[n] || key < a[1])//防止越界
{
return 0;
}
int left = 1;
int right = n;
while (left <= right)
{
int mid = left + (key - a[left]) / (a[right] - a[left]) * (right - left);
if (a[mid] < key)
{
left = mid + 1;
}
else if (a[mid] > key)
{
right = mid - 1;
}
else
{
return mid;
}
}
return 0;
}
这个算法的时间复杂度也是O(loglogn),对于表长较大,关键字分布又比较均匀的查找表来说,其性能显著优于折半查找。
3.斐波那契查找
在我的理解中,斐波那契查找也是一种类折半查找,他的mid的位置如下图
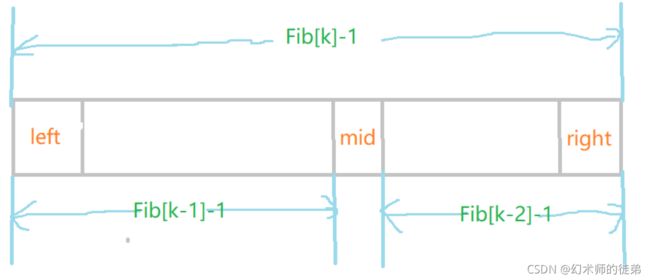
它的设计利用了斐波那契数列的性质:
F i b [ k ] = F i b [ k − 1 ] + F i b [ k − 2 ] Fib[k]=Fib[k-1]+Fib[k-2] Fib[k]=Fib[k−1]+Fib[k−2]
&esmp;但是有时候我们的数组长度不是一个斐波那契数-1,所以我们要把他补全到这样的长度。
//斐波那契查找
int Fib[MAXSIZE];
void fillFib(void);
int Fibonacci_Search(int* a, int n, int key);
extern int Fib[MAXSIZE];
void fillFib(void)
{
Fib[0] = 0;
Fib[1] = 1;
int i = 2;
while (i <= MAXSIZE)
{
Fib[i] = Fib[i - 1] + Fib[i - 2];
i++;
}
}
int Fibonacci_Search(int* a, int n, int key)
{
int left = 1;
int right = n;
int k = 0;
int mid;
while (n > Fib[k] - 1)
{
k++;
}//得到大于等于当前n的斐波那契数列值-1的下标k
for (int i = n; i < Fib[k] - 1; i++)
{
a[i] = a[n];
}
while (left <= right)
{
mid = left + Fib[k] - 1;
if (key < a[mid])
{
//在左边的区域找
right = mid - 1;
k = k - 1;
}
else if (key > a[mid])
{
//在右边的区域找
left = mid + 1;
k = k - 2;
}
else
{
if (mid <= n)
//如果mid还在n范围内 返回mid就行
{
return mid;
}
else
{
//如果mid出了n的范围找到了,由于后面的元素都和n位置的元素相等,其实就是在n位置找到了
//返回n
return n;
}
}
}
return 0;
}
斐波那契查找的时间复杂度也是O(logn),如果我们始终都在右半区查找,那么斐波那契查找的效率显然是高于折半查找的,如果我们始终但左半区查找,那它的效率就比折半查找差很多了。还有一点,斐波那契查找计算mid用的是
m i d = l e f t + F i b [ k ] − 1 ; mid = left + Fib[k] - 1; mid=left+Fib[k]−1;
是纯加法运算,而折半查找和插值查找都是用了乘法和除法,在数据规模很大的情况下,这样效率可能更高一些。
三种查找的本质区别是分隔点选择不同,各有优劣,实际开发中应该根据数据的特点再做选择。
四、线性索引查找
对于数据数量很大的情况下,把数据集整个按照关键字进行排序所需要的时间成本是很高的(因为单个数据项的大小会很大),所以我们可以单独把关键字拿出来,加上一个指向它所对应元素的指针,对这个东西进行操作。
索引就是把一个关键字和与它对应的记录相关联的过程(这个过程可以用指针实现),每个关键字和指向它对应记录的指针叫做一个索引项。
把索引项按照不同的数据结构来储存,可以分为线性索引,树形索引和多级索引。我们这里只介绍线性索引。
所谓线性就是将索引项集合组织成线性结构,也称为索引表。
1.稠密索引
稠密索引是在线性索引中,将数据集中的每个记录对应一个索引项,如下图所示
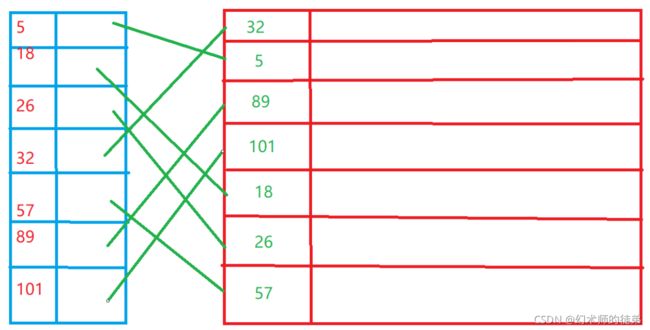
**对于稠密索引这个索引表来说,索引项一定是按照关键码有序排列的。**这意味着我们可以用折半查找、插值查找、斐波那契查找对索引表进行查找,效率相对较高。
但它每个索引项对应一个记录也给它带来了缺点,如果数据规模很大,比如上亿,那也就意味着索引表也得有同样数据集长度规模,对于内存有限的计算机来说,可能就需要去反复访问磁盘,查找性能反而下降了。
//稠密索引
typedef struct {
int data;
int key;
}LINode,LTNodes[MAXSIZE];
typedef struct {
LINode* pointer;
int key;
}Indexelement,ListIndex[MAXSIZE];
void GetListIndex(LTNodes ltnodes, ListIndex listindex, int n);
void ListIndexSort(ListIndex listindex, int n);
void GetListIndex(LTNodes ltnodes, ListIndex listindex, int n)
{
for (int i = 0; i < n; i++)
{
listindex[i].key = ltnodes[i].key;
listindex[i].pointer = &(ltnodes[i]);
}
}
void ListIndexSort(ListIndex listindex, int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (listindex[j].key > listindex[j + 1].key)
{
Indexelement e = listindex[j];
listindex[j] = listindex[j + 1];
listindex[j + 1] = e;
}
}
}
}
2.分块索引
借鉴了图书馆存储数据的方法,就是把数据记录分块存储,然后用一个分块索引表存储每个块中最大的关键字,存储块长,存储指向块中首元素的指针,分块索引表有序以便查找。
我们的这些块要满足以下性质:
- 块内无序
- 块间有序,例如要求第二块所有记录的关键字均要大于第一块中所有记录的关键字,这样才有搜索效率。
//分块索引
typedef struct {
keyType maxkey;
int length;
LINode* pointer;
}BlockIndexelement, BlockIndex[MAXSIZE];
我们来讨论一下分块索引查找的平均查找长度。设n个记录的数据集被平均分成m块,每个块中有t条记录,那么显然
n = m ∗ t m = n t n=m*t\\ m=\frac{n}{t} n=m∗tm=tn
根据最好与最差等概率的原则,在索引表中查找的平均距离是
L b = m + 1 2 L_{b}=\frac{m+1}{2} Lb=2m+1
在块中查找的平均距离是
L w = t + 1 2 L_{w}=\frac{t+1}{2} Lw=2t+1
所以平均查找长度为
L = L b + L w = m + t 2 + 1 = 1 2 ( n t + t ) + 1 > = n 1 2 + 1 当 且 仅 当 t = n 1 2 时 取 等 号 L=L_{b}+L_{w}=\frac{m+t}{2}+1=\frac{1}{2}(\frac{n}{t}+t)+1>=n^{\frac{1}{2}}+1 \\当且仅当t=n^{\frac{1}{2}}时取等号 L=Lb+Lw=2m+t+1=21(tn+t)+1>=n21+1当且仅当t=n21时取等号
可见分块索引的时间复杂度比顺序查找要好了很多,但是与折半查找的效率比还是差了很多,不过分块索引兼顾了对细分块不需要有序的情况,大大提升了整体查找的速度,所以普遍用于数据库表查找等技术的应用中。
3.倒排索引
最简单,最基础的搜索技术——倒排索引。
比如以下两篇文章:
- Books and friends should be few but good.
- A good book is a good friend.
我们可以制作一张单词表
| 英文单词 | 文章编号 |
|---|---|
| a | 2 |
| and | 1 |
| be | 1 |
| book | 1,2 |
| but | 1 |
| few | 1 |
| friend | 1,2 |
| good | 1,2 |
| is | 2 |
| should | 1 |
有了这样一张单词表,我们要搜索文章就非常方便了。如果你要在搜索框中填写“book”关键字,我们就会在这个单词表中有序查找book,找到后将它对应的文章编号1和2的文章地址(通常在搜索引擎中就是网页和标题的链接)返回,并告诉你查到两条记录,用时0.0001秒。由于表是有序的,查找效率很高,返回的又只是文章的编号,所以整体速度非常快。
这张单词表就是倒排索引的索引表,索引项的通用结构是:
- 次关键码:例如上面的“英文单词”。
- 记录号表:例如上面的“文章编号”。
其中记录号表存储具有相同次关键字的所有记录的记录号(可以是指向记录的指针或者是该记录的主关键字)。这样的索引方法就是倒排索引(inverted index)。
五、二叉排序树
假设查找的数据集是普通的顺序存储,那么插入操作就是将记录放在表的末端,给表记录数加1即可,删除操作可以是删除后,后面的记录前移;也可以是要删除的元素和最后一个元素互换,表数据记录减1,反正整个数据集也没有什么顺序,这样的效率也不错。但是由于无序造成查找的效率很低。
如果我们是关键字有序的线性表,查找可以用折半、插值、斐波那契查找,效率很高,但是我们每次插入和删除都要重新维护数据的有序,效率也会受到影响。
下面我们要讲的二叉排序树就是一种插入和删除效率不错,又可以比较高效的实现查找算法的结构。
1.二叉排序树的定义
二叉排序树(Bit Sort Tree),又称为二叉查找树。它要么是一棵空树,要么是具有下列性质的二叉树:
- 若它的左子树不为空,则左子树上的所有结点都小于它的根结点的值。
- 若它的右子树不为空,则右子树上的所有结点都大于它的根节点的值。
- 它的左、右子树也都是二叉排序树。
显然,对二叉排序树做中序遍历可以得到一个从小到大的有序排列。
2.二叉排序树的创建、插入和查找
2.1 二叉排序树的查找
由于二叉排序树的创建要用到二叉排序树的查找,所以我们先来讲讲二叉排序树的查找。
我们采用链式存储的形式,给出二叉树结点的数据结构:
typedef struct BiTNode {
int data;
struct BiTNode* leftchild;
struct BiTNode* rightchild;
}BiTNode, * BiTree;
设计查找函数的思路是这样的,使用递归的思路,如果当前查找结点的值小于关键字的值,那么就进入当前节点的右子树进行查找,否则进入当前节点的左子树进行查找,如果找到了结点,那么令p返回当前节点的地址;如果查找失败(就是查到底了 NULL),我们就令p返回当前节点的前一个节点的位置,由于我们要修改p这个指针的值,所以我们需要二级指针也就是BiTree* p。
bool SearchBST(BiTree T, int key, BiTree prev, BiTree* p);
//T表示当前正在查找的BST的根节点
// key表示需要查找的关键字
// prev表示当前结点的双亲节点
//p表示返回值 如果查找失败 则返回当前失败位置NULL的双亲节点
//如果查找成功 则返回当前节点
bool SearchBST(BiTree T, int key, BiTree prev, BiTree* p)
{
if (T == NULL)
//如果T是NULL 有两种情况 一种树为空 那么prev一定等于NULL 返回从查找失败
//还有可能是查找到叶子结点了也没找到 这是prev会等于当前节点的双亲结点
//两种情况都可以解引用p,改为prev返回
{
*p = prev;
return false;
}
else if (T->data == key)
{
*p = T;
return true;
}
else if (T->data < key)
{
return SearchBST(T->rightchild, key, T, p);
}
else
{
return SearchBST(T->leftchild, key, T, p);
}
}
2.2 二叉排序树的插入
插入的设计逻辑是我们已经有了一颗二叉排序树,我们要把这个关键字插入到合适的位置可以这样,首先,进行一个二叉树查找,如果此关键字在现在的BST中已经有了,那么就不插入了;否则会有一个指针指向一个查找失败位置的前一个结点,观察我们的查找函数,这个结点其实就是我们插入结点的双亲结点,然后我们比较一下key和这个节点的数据值决定是要插入左边还是右边就行了。
bool InsertBST(BiTree* T, int key)
{
BiTree p;
if (SearchBST(*T, key, NULL, &p) == false)
//如果查找失败 才有插入的必要
{
BiTree s = (BiTree)malloc(sizeof(BiTNode));
if (s == NULL)
{
printf("malloc fault\n");
exit(-1);
}
s->data = key;
s->leftchild = s->rightchild = NULL;
if (p == NULL)
//p等于NULL说明当前树中没有结点 我们要插入首个结点
{
*T = s;
}
else if (p->data < key)
{
p->rightchild = s;
}
else
{
p->leftchild = s;
}
return true;
}
return false;
}
2.3 二叉排序树的创建
有了二叉树的插入,其创建的实现思路就很简单了,因为我们的插入函数是可以应对二叉树为空的情况的,所以只需要一个数组arr存储要创建的二叉树的结点的元素,然后利用一个for循环依次插入就行。
void createBST(BiTree* T, int arr[MAXSIZE], int n)
{
for (int i = 0; i < n; i++)
{
InsertBST(T, arr[i]);
}
}
3.二叉排序树的删除操作
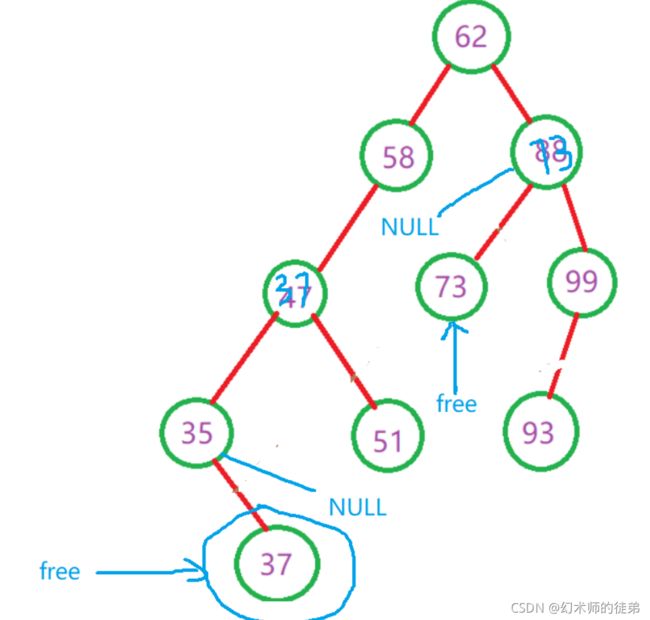
俗话说,请神容易送神难。前面介绍的二叉排序树的查找、插入、创建操作说实话都没有那么困难,但是排序二叉树的结点的删除是由一定困难的。因为我们不能删除了这个结点后使得得到的树不符合排序二叉树的性质,我们分三种情况来考虑:
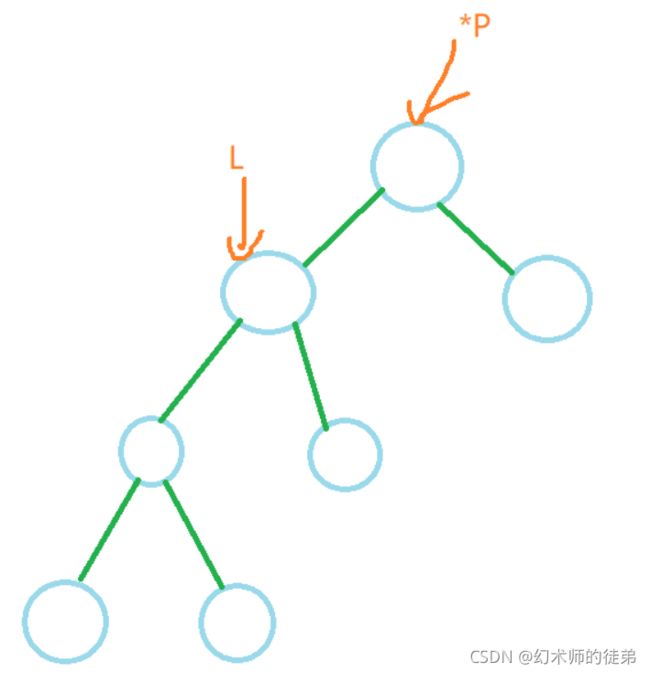
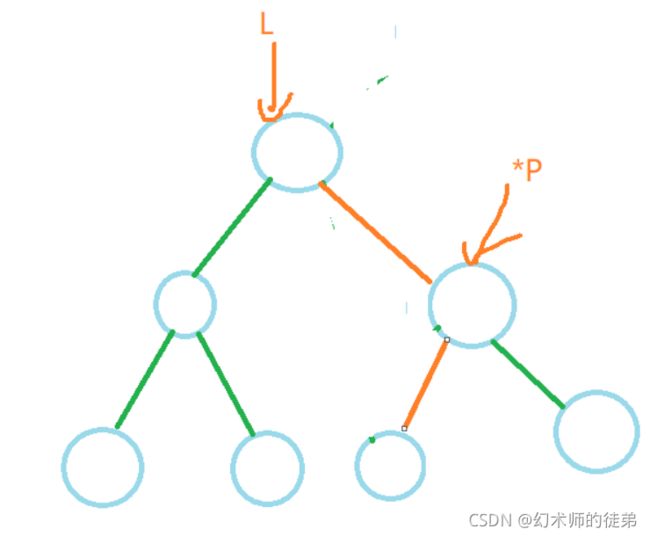
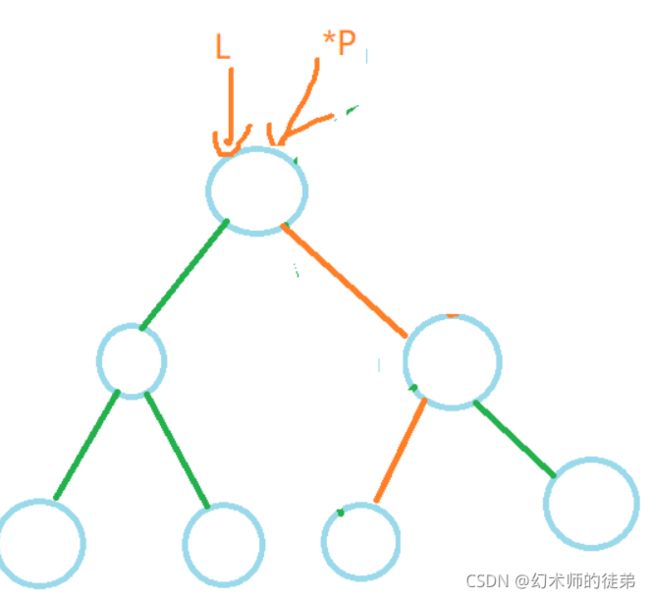
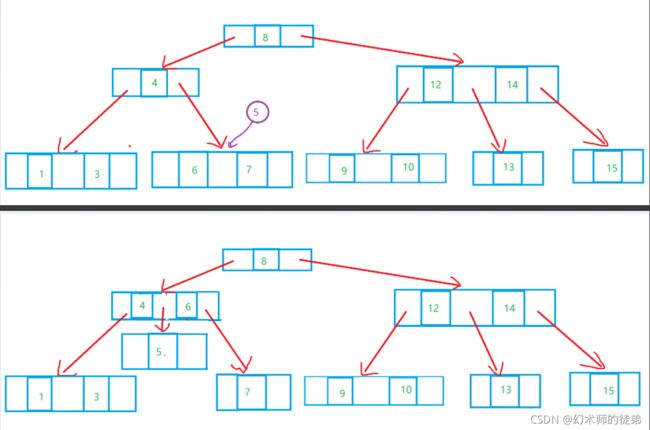
- 如果要删除的结点是叶子结点,那太好了,直接删除就行了,其他结点并不会收到影响,如图:

- 对于要删除的结点如果只有左子树或者只有右子树的情况,我们可以把这个结点替换成它的左子树(或右子树)的根节点,然后free这个结点,如图:

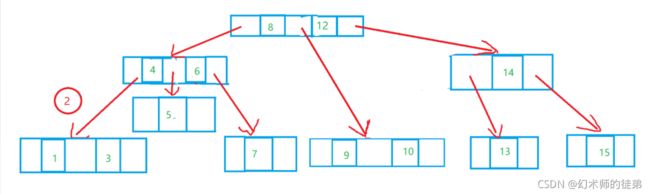
- 如果要删除的结点同时有左子树和右子树,怎么办呢?我们的想法是找到这个结点左子树中最大的元素,然后以这个元素的值替代原来的结点的值,然后把左子树中最大元素的节点的双亲结点的的右子树接成这个最大元素结点的左子树,然后free这个最大元素结点,我们用s指针找到那个节点,用q指针找到s指针的双亲结点,此时有两种情况,如果q指针没动过,那么要把s的左子树接到q的左子树上;否则要把s的左子树接到q的右子树上,两种情况在图中都有展示。
bool DeleteBST(BiTree* T, int key)
{
if (*T == NULL)
{
return false;//如果没找到这个结点就删除失败了
}
else
{
if (key == (*T)->data)
{
return Delete(T);
}
else if (key < (*T)->data)
{
//传的是T的左子树或者右子树的指针的指针,会修改T的左孩子或者右孩子指针。
return DeleteBST(&((*T)->leftchild), key);
}
else
{
return DeleteBST(&((*T)->rightchild), key);
}
}
}
bool Delete(BiTree* p)
{
BiTree q, s;
//一、只有左子树的情况 叶子结点同样也走这一步
if ((*p)->rightchild == NULL)
{
q = *p; *p = (*p)->leftchild; free(q);
}
//二、只有右子树的情况
else if ((*p)->leftchild == NULL)
{
q = *p; *p = (*p)->rightchild; free(q);
}
//左右子树都有的情况
else
{
q = *p; s = (*p)->leftchild;
while (s->rightchild)
{
q = s; s = s->rightchild;
}
//s走到p的左子树中最大的元素 q是它的双亲结点
(*p)->data = s->data;
//如果q动了,说明我们应该让q的右子树接s的左子树
if (q != *p)
{
q->rightchild = s->leftchild;
}
//如果q没动,那么q还在待删除节点 要让他的左子树接s的左子树
else
{
q->leftchild = s->leftchild;
}
free(s);
}
return true;
}
4.二叉排序树的中序遍历
为了查看我们的创建删除插入操作是否成功,我们可以再创建一个中序遍历函数。
void InOrderBST(BiTree T)
{
if (T == NULL)
return;
InOrderBST(T->leftchild);
printf("%d ", T->data);
InOrderBST(T->rightchild);
}
5.BST测试汇总
//二叉排序树
typedef struct BiTNode {
int data;
struct BiTNode* leftchild;
struct BiTNode* rightchild;
}BiTNode, * BiTree;
bool SearchBST(BiTree T, int key, BiTree prev, BiTree* p);
//T表示当前正在查找的BST的根节点
// key表示需要查找的关键字
// prev表示当前结点的双亲节点
//p表示返回值 如果查找失败 则返回当前失败位置NULL的双亲节点
//如果查找成功 则返回当前节点
bool InsertBST(BiTree* T, int key);
void createBST(BiTree* T, int arr[MAXSIZE], int n);
bool DeleteBST(BiTree* T, int key);
bool Delete(BiTree* p);
void InOrderBST(BiTree T);
bool SearchBST(BiTree T, int key, BiTree prev, BiTree* p)
{
if (T == NULL)
{
*p = prev;
return false;
}
else if (T->data == key)
{
*p = T;
return true;
}
else if (T->data < key)
{
return SearchBST(T->rightchild, key, T, p);
}
else
{
return SearchBST(T->leftchild, key, T, p);
}
}
bool InsertBST(BiTree* T, int key)
{
BiTree p;
if (SearchBST(*T, key, NULL, &p) == false)
{
BiTree s = (BiTree)malloc(sizeof(BiTNode));
if (s == NULL)
{
printf("malloc fault\n");
exit(-1);
}
s->data = key;
s->leftchild = s->rightchild = NULL;
if (p == NULL)
{
*T = s;
}
else if (p->data < key)
{
p->rightchild = s;
}
else
{
p->leftchild = s;
}
return true;
}
return false;
}
void createBST(BiTree* T, int arr[MAXSIZE], int n)
{
for (int i = 0; i < n; i++)
{
InsertBST(T, arr[i]);
}
}
bool DeleteBST(BiTree* T, int key)
{
if (*T == NULL)
{
return false;//如果没找到这个结点就删除失败了
}
else
{
if (key == (*T)->data)
{
return Delete(T);
}
else if (key < (*T)->data)
{
//传的是T的左子树或者右子树的指针的指针,会修改T的左孩子或者右孩子指针。
return DeleteBST(&((*T)->leftchild), key);
}
else
{
return DeleteBST(&((*T)->rightchild), key);
}
}
}
bool Delete(BiTree* p)
{
BiTree q, s;
//一、只有左子树的情况 叶子结点同样也走这一步
if ((*p)->rightchild == NULL)
{
q = *p; *p = (*p)->leftchild; free(q);
}
//二、只有右子树的情况
else if ((*p)->leftchild == NULL)
{
q = *p; *p = (*p)->rightchild; free(q);
}
//左右子树都有的情况
else
{
q = *p; s = (*p)->leftchild;
while (s->rightchild)
{
q = s; s = s->rightchild;
}
//s走到p的左子树中最大的元素 q是它的双亲结点
(*p)->data = s->data;
//如果q动了,说明我们应该让q的右子树接s的左子树
if (q != *p)
{
q->rightchild = s->leftchild;
}
//如果q没动,那么q还在待删除节点 要让他的左子树接s的左子树
else
{
q->leftchild = s->leftchild;
}
free(s);
}
return true;
}
void InOrderBST(BiTree T)
{
if (T == NULL)
return;
InOrderBST(T->leftchild);
printf("%d ", T->data);
InOrderBST(T->rightchild);
}
#include "MySearch.h"
void test1()
{
BiTree T = NULL;
int arr[] = { 62,88,58,47,35,73,51,99,37,93 };
createBST(&T, arr, 10);
InOrderBST(T);
DeleteBST(&T, 58);
printf("\n");
InOrderBST(T);
}
int main()
{
test1();
return 0;
}
6.二叉排序树总结
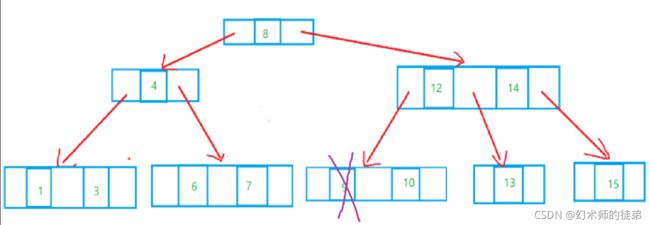
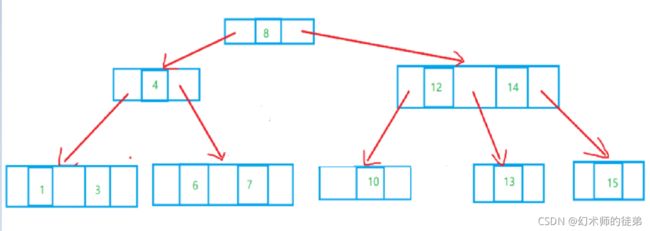
对于插入和删除操作,保持了链式存储不用移动元素的优点,只需找到合适的位置修改指针的值即可,但是对于二叉树的查找,就是要从根节点走到目标结点的路径,极端情况下,最少为1次,也就是根节点就是要找的节点,最多也不会超过树的深度,也就是说,二叉排序树的查找性能取决于二叉排序树的形状,可问题及就是二叉排序树的形状是不确定的。
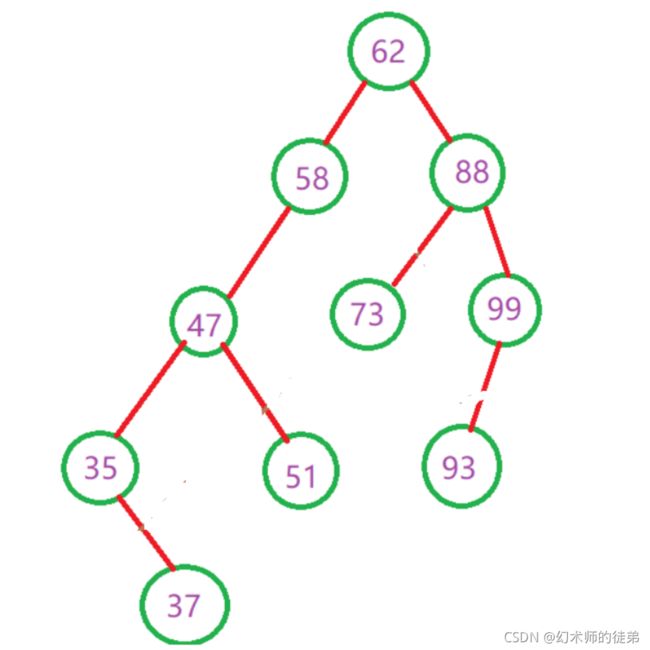
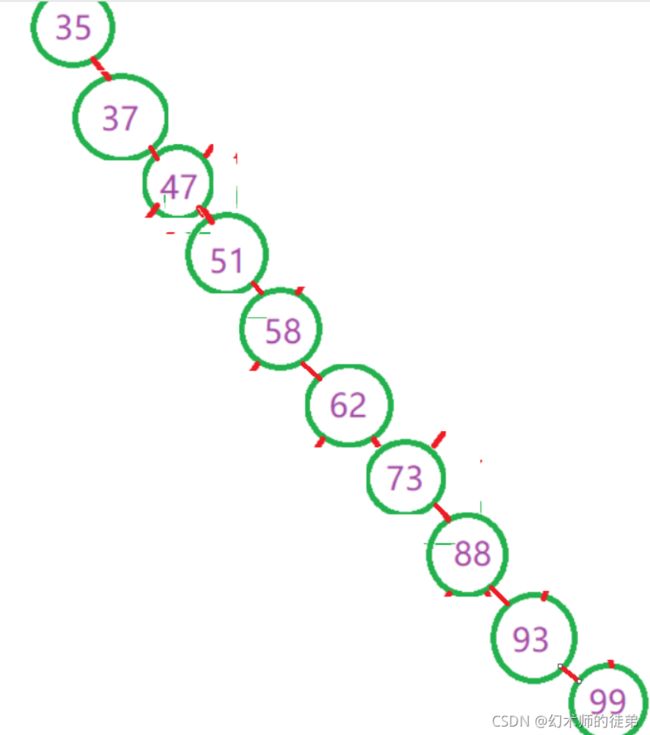
可以看到,同样元素构成的二叉排序树,第一个图查找的最多比较5次,而第二个图的最多比较次数是10。
因此我们希望二叉排序树的左右能够“平衡”一点,即深度与完全二叉树相同,深度为O(log2N),那么查找的时间复杂度是O(logN),近似于折半查找。
六、平衡二叉树(AVL树)
1.AVL树的定义
平衡二叉树是一种二叉排序树,其中每一个结点的左子树和右子树的高度差至多等于1.
我们将二叉树上节点的左子树高度减去右子树高度的值称为平衡因子BF,那么平衡二叉树的平衡因子只能是-1,0和1。
当我们要插入结点的时候,距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树,我们称为最小不平衡子树。
2.AVL树的实现原理
AVL树的实现原理说来简单,就是在构建二叉排序树的过程中,每当插入一个结点的时候,先检查是否因为插入而破坏了树的平衡性,若是,则找出最小不平衡子树,对其进行相应的旋转,使其成为新的平衡子树。
首先,我们要介绍两种旋转操作,进而引出左平衡和右平衡操作。
2.1 右旋和左旋
2.1.1 左旋
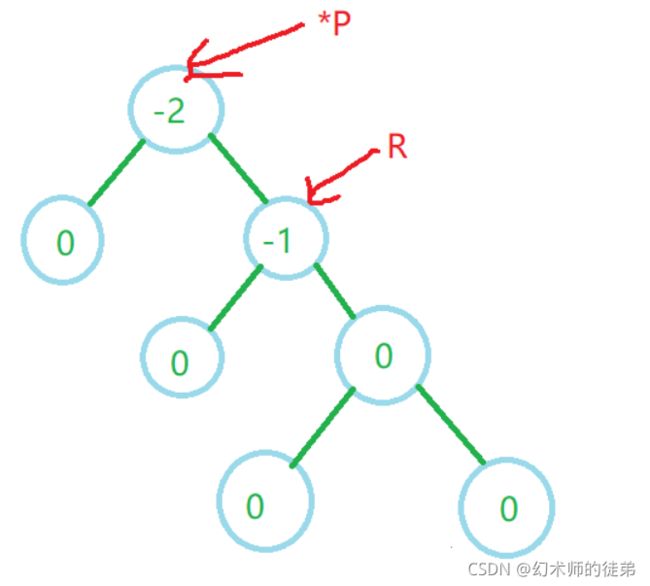
左旋的思路是用R记录根节点*P的右孩子,然后让右孩子的左子树做根节点的右子树,用新的*P做R的左子树,最后让*P等于R以指向旋转后的子树的根节点。

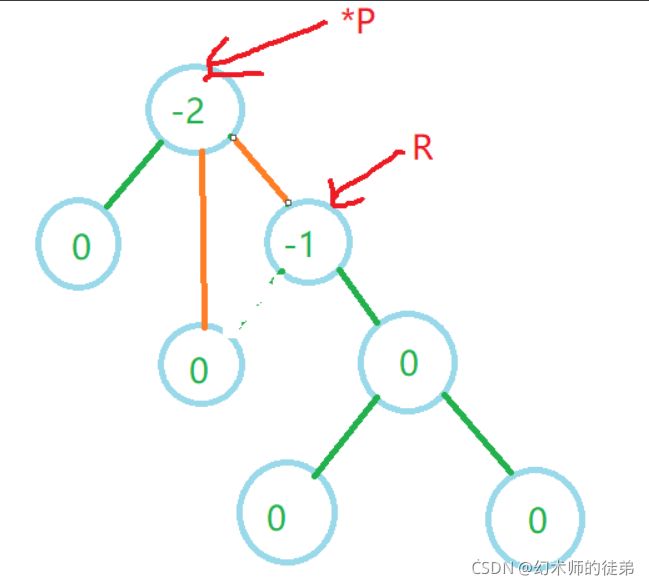
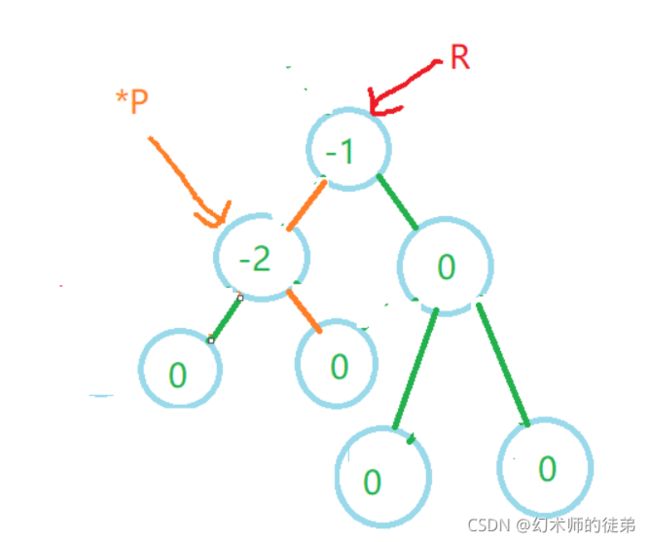

左旋的实现代码如下:
void L_Rotate(AVLTree* P)
{
AVLNode* R = (*P)->rchild;
(*P)->lchild = R->rchild;
R->lchild = (*P);
(*P) = R;
}
2.1.2 右旋
右旋的思路和左旋类似,直接上图和代码:
void R_Rotate(AVLTree* P)
{
AVLNode* L = (*P)->lchild;
(*P)->rchild = L->lchild;
L->rchild = (*P);
(*P) = L;
}
2.2 右平衡操作
当最小不平衡子树的根节点的平衡因子是小于0的时候,说明新加上的节点是在最小不平衡子树的右子树上,说明**右子树高,需要右平衡操作。**这里有两种情况::
我们记指向最小不平衡子树的根节点为(*T)的指针,指向其右子树的根节点的指针为R,指向其右节点左子树的指针为rl。
- 检查最小不平衡子树的右子树的根节点(记为*R),如果其bf也小于0,说明形态类似下图,只需要进行一次左旋操作;
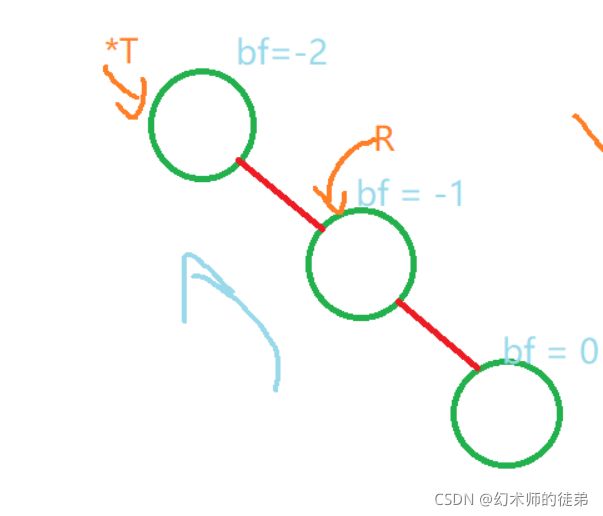
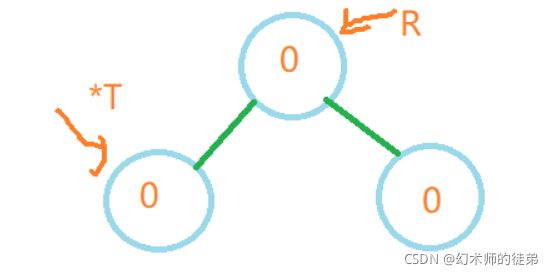
我们调整平衡后也要对应的调整结点的平衡因子值,但是由于旋转的过程会让我们的指针指向的结点发生变化,不如我们先调整bf的值然后再旋转,观察上面两幅图,只需这样调整
(*T)->bf = R->bf = 0;
- 检查R的bf值,如果R的bf值大于0,说明新增的结点挂在*T的右子树R的左子树rl上,其形态大概如下图,这种情况下需要对R进行一次右旋操作,然后对*T进行一次左旋操作,如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传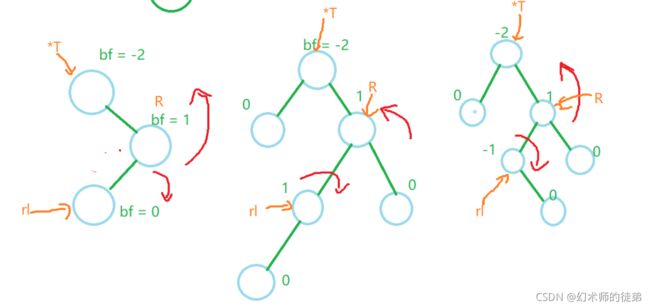
同样仿照之前的思路,我们在旋转之前也要对应调整没个结点的bf值,对比下图:
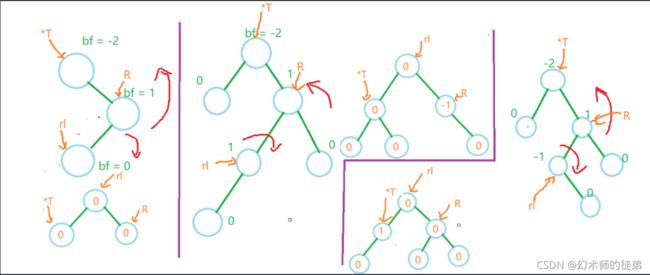
发现可以分为三种情况
switch (rl->bf)
{
case 0: (*T)->bf = R->bf = 0;
case 1: (*T)->bf = 1; R->bf = -1; rl->bf = 0;
case -1: (*T)->bf = 1; rl->bf = 0; R->bf = 0;
}
所以右平衡操作的函数就得到了:
void RightBalance(AVLTree* T)
{
AVLTree R, rl;
R = (*T)->rchild;
switch (R->bf)
{
case RH:
(*T)->bf = R->bf = EH;
L_Rotate(T);
break;
case LH:
rl = R->lchild;
switch (rl->bf)
{
case EH:
(*T)->bf = R->bf = EH;
break;
case LH:
(*T)->bf = EH;
R->bf = RH;
break;
case RH:
(*T)->bf = LH;
R->bf = EH;
break;
}
rl->bf = EH;
R_Rotate(&(*T)->rchild);
L_Rotate(T);
break;
}
}
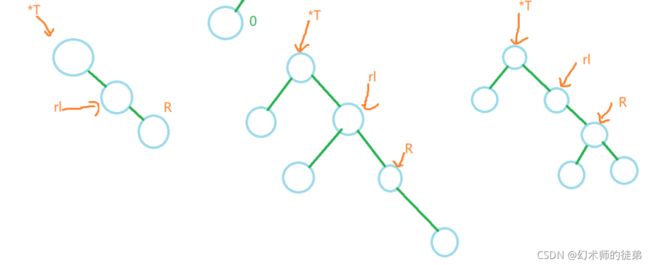
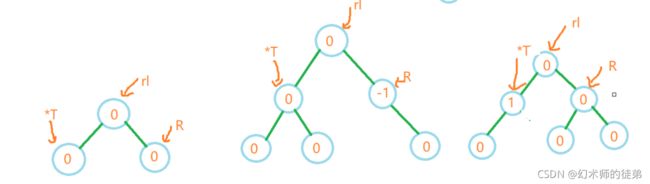
2.3左平衡操作
如果出现了最小不平衡子树的根节点的bf大于1,那么就说明最小不平衡子树的左子树比右子树高,需要进行左平衡操作,可以同样按上面的情况来分,这里一次性给出所有情况:
我们用*T表示指向最小不平衡子树的根节点的指针,L表示指向它左子树根节点的指针,lr表示指向它左子树的右子树的根节点的指针。

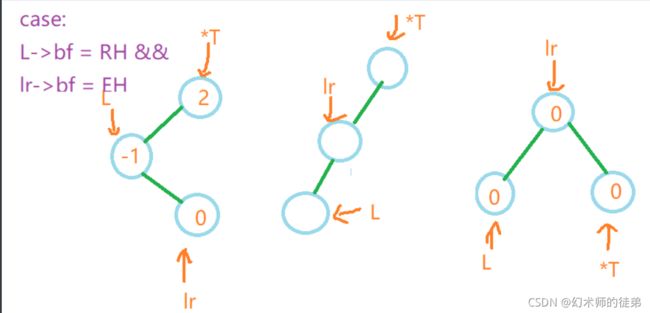


void LeftBalance(AVLTree* T)
{
AVLTree L, lr;
L = (*T)->lchild;
switch (L->bf)
{
case LH:
(*T)->bf = EH;
L->bf = EH;
break;
case RH:
lr = L->rchild;
switch (lr->bf)
{
case EH:
(*T)->bf = EH;
L->bf = EH;
break;
case LH:
(*T)->bf = RH;
L->bf = EH;
break;
case RH:
(*T)->bf = EH;
L->bf = LH;
break;
}
lr->bf = EH;
L_Rotate(&((*T)->lchild));
R_Rotate(T);
break;
}
}
2.4 AVL树的插入
bool InsertAVL(AVLTree* T, int e, bool* taller)
{
if (*T == NULL)
{
*T = (AVLTree)malloc(sizeof(AVLNode));
(*T)->data = e;
(*T)->lchild = (*T)->rchild = NULL;
(*T)->bf = EH;
*taller = true;
//taller的值表示经过插入树是否变高了
}
else
{
if (e == (*T)->data)
{
*taller = false;
return false;
}
if (e < (*T)->data)
{
//如果插入失败(即找到了相同的结点),InsertAVL会在上面返回false,
//然后就就返回false表示插入失败
if (InsertAVL(&(*T)->lchild, e, taller) == false)
return false;
//走到这里说明新结点插入在其左子树了
if (*taller == true)
{
switch ((*T)->bf)
//检查T的平衡度
{
//本来就左边高 那需要调整一下 由于调整所以树并没有长高
case LH:
LeftBalance(T);
*taller = false;
break;
//本来一样高 插入完了就了变成左边高了 并且长高了
case EH:
(*T)->bf = LH;
*taller = true;
break;
//本来右边高 插入完了以后变成一样高了
case RH:
(*T)->bf = EH;
*taller = false;
break;
}
}
}
else
{
if (InsertAVL(&(*T)->rchild, e, taller) == false)
return false;
if (*taller == true)
{
//走到这里说明在右子树插入了
switch ((*T)->bf)
{
//如果本来左边高 那么插入完以后变成一样高了,并且树没有长高
case LH:
(*T)->bf = EH;
*taller = false;
break;
//如果本来一样高,插入完了变成右边高了,并且树长高了
case EH:
(*T)->bf = RH;
*taller = true;
break;
//如果本来右边高 就需要调整一下了 由于调整 树也没有长高
case RH:
RightBalance(T);
*taller = false;
break;
}
}
}
}
return true;
}
2.5 AVL树的创建
void createAVLTree(AVLTree* T, int a[MAXSIZE], int n)
{
bool taller;
for (int i = 0; i < n; i++)
{
InsertAVL(T, a[i], &taller);
}
}
2.6 AVL树汇总
//AVL树
typedef struct AVLNode {
int data;
int bf;
struct AVLNode* lchild;
struct AVLNode* rchild;
}AVLNode, * AVLTree;
void L_Rotate(AVLTree* P);
void R_Rotate(AVLTree* P);
#define RH -1
#define EH 0
#define LH 1
void RightBalance(AVLTree* T);
void LeftBalance(AVLTree* T);
bool InsertAVL(AVLTree* T, int e, bool* taller);
void createAVLTree(AVLTree* T, int a[MAXSIZE], int n);
void InOrderTraverse(AVLTree T);
void L_Rotate(AVLTree* P)
{
AVLNode* R = (*P)->rchild;
(*P)->rchild = R->lchild;
R->lchild = (*P);
(*P) = R;
}
void R_Rotate(AVLTree* P)
{
AVLNode* L = (*P)->lchild;
(*P)->lchild = L->rchild;
L->rchild = (*P);
(*P) = L;
}
void RightBalance(AVLTree* T)
{
AVLTree R, rl;
R = (*T)->rchild;
switch (R->bf)
{
case RH:
(*T)->bf = R->bf = EH;
L_Rotate(T);
break;
case LH:
rl = R->lchild;
switch (rl->bf)
{
case EH:
(*T)->bf = R->bf = EH;
break;
case LH:
(*T)->bf = EH;
R->bf = RH;
break;
case RH:
(*T)->bf = LH;
R->bf = EH;
break;
}
rl->bf = EH;
R_Rotate(&(*T)->rchild);
L_Rotate(T);
break;
}
}
void LeftBalance(AVLTree* T)
{
AVLTree L, lr;
L = (*T)->lchild;
switch (L->bf)
{
case LH:
(*T)->bf = EH;
L->bf = EH;
break;
case RH:
lr = L->rchild;
switch (lr->bf)
{
case EH:
(*T)->bf = EH;
L->bf = EH;
break;
case LH:
(*T)->bf = RH;
L->bf = EH;
break;
case RH:
(*T)->bf = EH;
L->bf = LH;
break;
}
lr->bf = EH;
L_Rotate(&((*T)->lchild));
R_Rotate(T);
break;
}
}
bool InsertAVL(AVLTree* T, int e, bool* taller)
{
if (*T == NULL)
{
*T = (AVLTree)malloc(sizeof(AVLNode));
(*T)->data = e;
(*T)->lchild = (*T)->rchild = NULL;
(*T)->bf = EH;
*taller = true;
//taller的值表示经过插入树是否变高了
}
else
{
if (e == (*T)->data)
{
*taller = false;
return false;
}
if (e < (*T)->data)
{
//如果插入失败(即找到了相同的结点),InsertAVL会在上面返回false,
//然后就就返回false表示插入失败
if (InsertAVL(&(*T)->lchild, e, taller) == false)
return false;
//走到这里说明新结点插入在其左子树了
if (*taller == true)
{
switch ((*T)->bf)
//检查T的平衡度
{
//本来就左边高 那需要调整一下 由于调整所以树并没有长高
case LH:
LeftBalance(T);
*taller = false;
break;
//本来一样高 插入完了就了变成左边高了 并且长高了
case EH:
(*T)->bf = LH;
*taller = true;
break;
//本来右边高 插入完了以后变成一样高了
case RH:
(*T)->bf = EH;
*taller = false;
break;
}
}
}
else
{
if (InsertAVL(&(*T)->rchild, e, taller) == false)
return false;
if (*taller == true)
{
switch ((*T)->bf)
{
case LH:
(*T)->bf = EH;
*taller = false;
break;
case EH:
(*T)->bf = RH;
*taller = true;
break;
case RH:
RightBalance(T);
*taller = false;
break;
}
}
}
}
return true;
}
void createAVLTree(AVLTree* T, int a[MAXSIZE], int n)
{
bool taller;
for (int i = 0; i < n; i++)
{
InsertAVL(T, a[i], &taller);
}
}
void InOrderTraverse(AVLTree T)
{
if (T == NULL)
{
return;
}
InOrderTraverse(T->lchild);
printf("%d ", T->data);
InOrderTraverse(T->rchild);
}
void test2()
{
AVLTree T = NULL;
int a[] = { 1,2,3,4,5,6,7,8,9,10 };
createAVLTree(&T, a, sizeof(a) / sizeof(a[0]));
InOrderTraverse(T);
}
int main()
{
test2();
return 0;
}
3.B树(多路查找树)
如果把开会比作内存中的数据存储的话,那么写下来和时常阅读它就是内存数据对外存磁盘上的存取操作了。
当我们要操作的数据集非常大,大到内存已经没办法处理了,如数据库中的上千万条记录的数据、硬盘中的上万个文件等。在这种情况下,对数据的处理需要不断的从硬盘等存储设备中调入或调出内存界面。
一旦涉及这样的外部存储设备,关于时间复杂度的计算就会发生变化,访问该集合元素的时间已经不仅仅是寻找该元素所需要比较次数的函数,我们必须考虑对硬盘等外部设备的访问次数。
试想一下,为了要在一个拥有几十万个文件的磁盘中查找一个文本文件,访问该集合元素的时间已经不仅仅是寻找该元素所需比较次数的函数,我们必须考虑对硬盘等外部存储设备的访问时间以及将会对该设备做出多少次单独访问。
为了打破一个结点只存储一个元素的限制,使得元素特别多的时候不会造成树的度很大和树的高度很大导致内存存取外存的次数过多,引入多路查找树的概念。
多路查找树,其每一个结点的孩子数可以超过两个,且每一个结点都可以存储多个元素。由于它是查找树,所有元素之间存在某种特定的排序关系。
我们讲解它的4种特殊形式:2-3树、2-3-4树、B树和B+树。
3.1 2-3树
一个2-3树是这样一个棵多路查找树:其中的每一个结点都具有两个孩子(称其为2结点)或三个孩子(称其为3结点),它满足以下性质:
- 一个2结点包含一个元素和两个孩子(或没有孩子),其左子树包含的元素小于该元素,右子树包含的元素大于该元素。
- 一个3结点包含一小一大两个元素和三个孩子(或没有孩子),左子树包含小于较小元素的元素,右子树包含大于较大元素的元素,中间子树包含介于量元素之间的元素。
- 2-3树的所有叶子都在同一层次上,下图就是一个有效的2-3树:
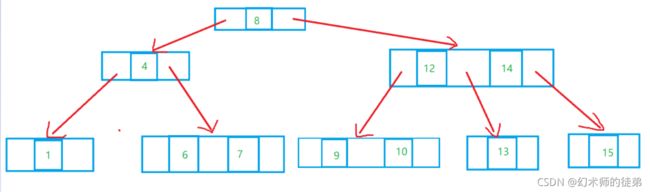
事实上,2-3树复杂的地方就在于新结点的插入和已有结点的删除。毕竟每个结点可能是2结点也可能是3结点,要保证所有叶子都在同一层次,是需要进行一番复杂的操作的。
3.1.1 2-3树的插入
对于2-3树的插入来说,与二叉排序树一样,插入操作一定是发生在叶子结点上。但是与二叉排序树不同的是,2-3树插入一个元素的过程有可能对该树的其余结构产生连锁反应。
2-3树的插入可以分为一下三种情况:
-
对于空树,插入一个2结点即可,这很容易理解。
-
插入结点到一个2结点的叶子结点上,很简单,只要让这个2结点变成3结点就可以了,注意比较一下大小以确定放置他们的顺序。
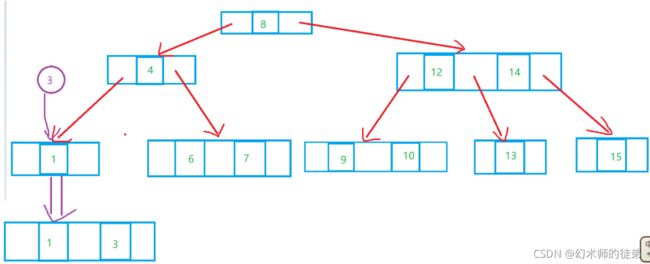
-
往3结点中插入一个新元素。由于3结点本身已经是2-3树的结点最大容量,因此我们需要将其拆分,且将树中两元素或插入元素的三者中选择其一向上移动一层,因此产生了复杂的情况。
- 如果它的双亲结点是2结点,那就选择适当元素将它的双亲结点升级成3结点。
- 如果它的双亲结点是3结点,首先看它双亲的双亲,如果双亲的双亲是2结点,就把2结点升级为3结点然后调整一下。

如果插入结点的双亲结点是3结点,双亲结点的双亲结点还是3结点(一直到根节点都是3结点)那么要把结点拆碎重组。如下图

通过这个例子,让我们发现,如果2-3树插入的传播效应导致了根节点的拆分,则树的高度就会增加。
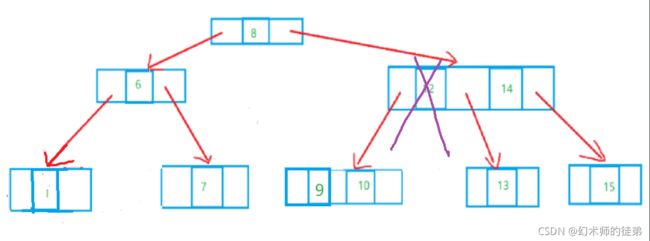
3.1.2 2-3树删除的实现
- 所删除的元素位于一个3结点的叶子结点上,这非常简单,只需要在该结点处删除该元素即可,如下图:
-
所删除的元素位于一个2结点形态的叶子结点上,要分4种情况处理。
- 此结点的双亲也是2结点,且拥有一个3结点的孩子,只需要删除后做一个左旋操作,如下图:
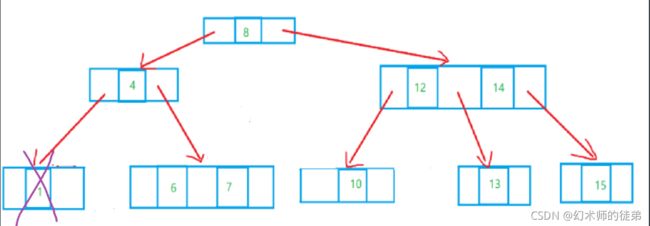

- 此结点的双亲也是2结点,且拥有一个3结点的孩子,只需要删除后做一个左旋操作,如下图:
-
此节点的双亲结点是2结点,它的右兄弟也是2结点,如下图所示,此时就要对整棵树进行变形,先试图“借”个结点让它的右兄弟变成3结点,然后旋转。

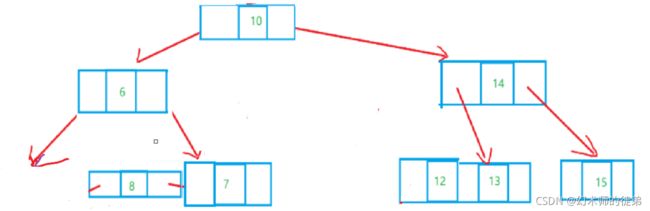
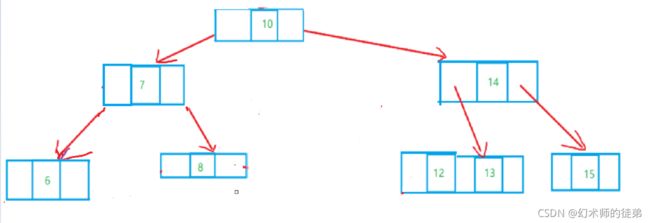
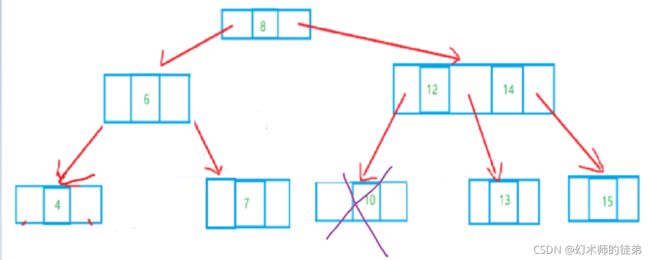
- 此节点的双亲是一个3结点,只需要拆分双亲再重组即可,如下图:
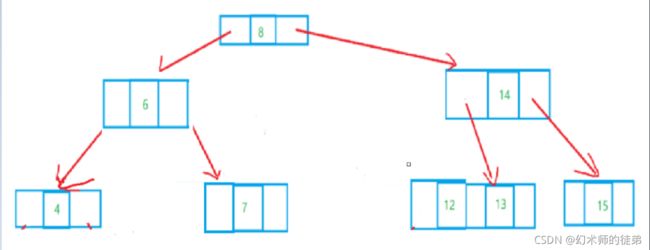
- 如果当前的树是一个满二叉树的情况,此时删除任何一个叶子都会使整棵树不能满足2-3树的定义,这种情况下就要减少层数,如下图:
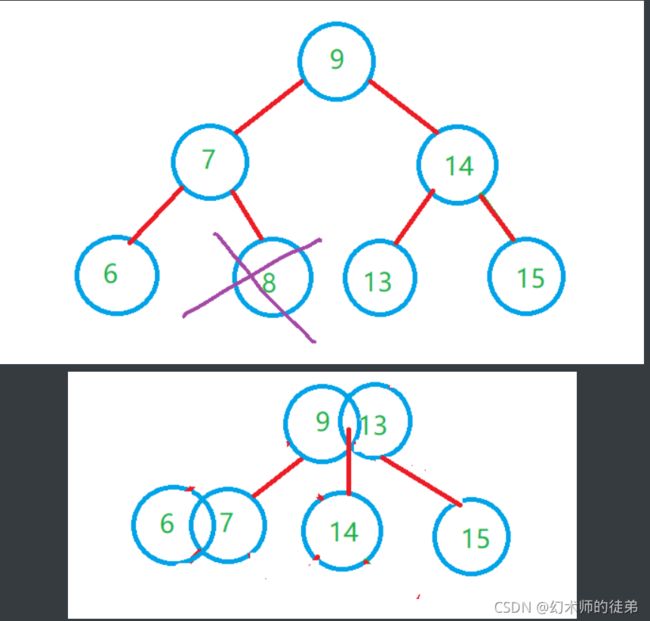
- 所删除的元素位于非叶子的分支结点。此时我们通常是将树按中序遍历后得到此元素的前驱或后继元素,考虑让他们来补位即可。
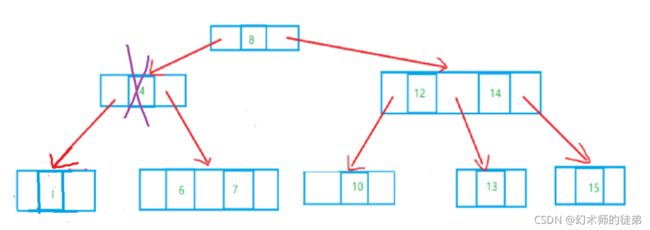
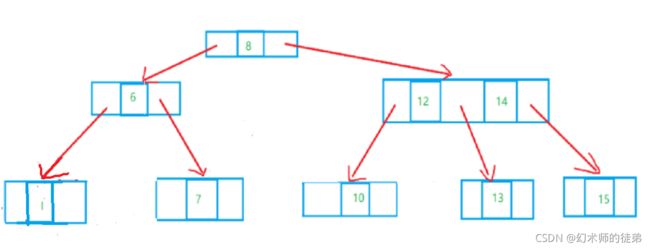
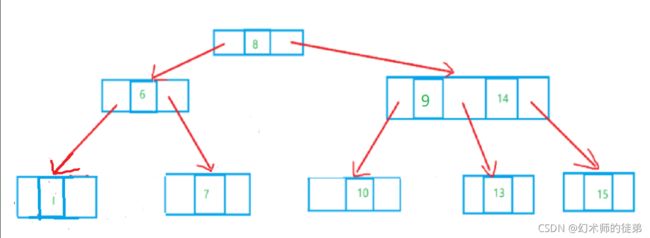
3.2 2-3-4树
它就是2-3树的概念拓展,包含了4结点的使用,一个4结点包含小中大3个元素和4个孩子(或没有孩子)。
某个4结点如果有孩子的话,左子树包含小于最小元素的元素,第二子树包含大于最小元素小于第二元素的元素,第三子树包含大于第二元素小于第三元素的元素,第四子树包含大于第三元素的元素。
3.3 B树
其实,我们前面一直都在讲B树,只不过B树是还有些特殊限制的,B树的定义如下
B树是一种平衡的多路查找树,结点最大的孩子数目称为B树的阶,一个m阶B树具有以下性质:
-
如果根结点不是叶结点,则其至少有两棵子树。
-
每一个非根的分支结点都有k-1个元素和k个孩子,其中
[ m / 2 ] + 1 ≤ k ≤ m [m/2]+1\leq k \leq m [m/2]+1≤k≤m
(个人理解这个公式是为了限制树解结点个数尽可能的少),每一个叶子结点n都有k-1个元素,其中
[ m / 2 ] + 1 ≤ k ≤ m [m/2]+1\leq k \leq m [m/2]+1≤k≤m -
所有叶子结点位于同一层次。
-
所有分支结点包含下列信息数据
n , A 0 , K 1 , A 1 , K 2 , A 2 , . . . , K n , A n n,A_{0},K_{1},A_{1},K_{2},A_{2},...,K_{n},A_{n} n,A0,K1,A1,K2,A2,...,Kn,An
其中:Ki(i=1,2,…,n)为关键字,且
K i < K i + 1 ( i = 1 , 2 , . . . , n − 1 ) K_{i}
Ai为指向子树根结点的指针,且指针Ai-1所指子树中的关键字均小于Ki(i=1,2,…,n),An所指子树中所有结点的关键字均大于Kn,
n ( [ m / 2 ] ≤ n ≤ m − 1 ) 为 关 键 字 的 个 数 且 n + 1 为 子 树 的 个 数 n([m/2]\leq n\leq m-1)为关键字的个数且n+1为子树的个数 n([m/2]≤n≤m−1)为关键字的个数且n+1为子树的个数
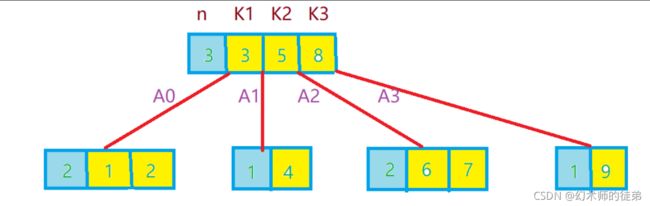
一个典型的B树应用,要处理的硬盘数据量很大,没法一次性全部装入内存。因此我们可以对B树进行调整,使得B树的阶数(或结点的元素)与硬盘存储的页面大小相匹配。比如说一棵B树的阶数是1001(即一个1结点包含1000个关键字),高度为2,它可以存储超过10亿个关键字,我们只要让根节点持久的保留在内存中,那么在这课树上,寻找某一个关键字至多需要两次硬盘的读取即可。
通过这种方式,在有限内存的情况下,每一次磁盘的访问我们都可以获得最大数量的数据。由于B树每结点可以具有比二叉树多得多的元素,所以与二叉树操作不同,它们减少了必须访问结点和数据块的数量,从而提高了性能。可以说,B树的数据结构就是为内外存的数据交互准备的。
那么对于n个关键字的m阶B树,最坏情况是要查找几次呢?
第一层至少有1个结点,第二层至少有2个结点,由于除根结点外每个分支结点至少有[m/2]棵子树,则第三层至少有2*()[m/2]+1)个结点。。。这样第k+1层至少有2*([m/2]+1)^(k-1)个结点,
假设经过k个结点后到了叶子结点,也就到了第k+1层,其实相当于查找不成功的结点为n+1,因此
n + 1 ≤ 2 ∗ ( [ m / 2 ] + 1 ) k − 1 k ≤ l o g m 2 + 1 ( n + 1 2 ) + 1 n+1\leq2*([m/2]+1)^{k-1}\\ k\leq log_{\frac{m}{2}+1}(\frac{n+1}{2})+1 n+1≤2∗([m/2]+1)k−1k≤log2m+1(2n+1)+1
也就是说,在含有n个关键字的B树上查找时,从根节点到关键字的路径上涉及的节点数不超过
l o g m 2 + 1 ( n + 1 2 ) + 1 log_{\frac{m}{2}+1}(\frac{n+1}{2})+1 log2m+1(2n+1)+1
出于这个特性,Mysql数据库里面的索引是基于哈希表或者B+树的。
3.4 B+树
尽管B树已经有了诸多好处,但它还是有缺陷的。对于树结构来说,我们可以通过中序遍历来顺序查找树中的元素,这一切都是在内存中进行的。
可是在B树里头,中序遍历往返于每个结点之间也就意味着我们必须得在硬盘的页面之间进行多次访问,如下图所示
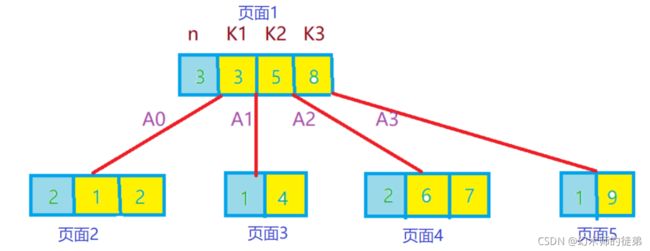
假设每个结点都属于硬盘的不同界面,我们为了中序遍历所有元素,顺序为页面1->页面2->页面1->页面3->页面1->页面4->页面1->页面5,我们每次经过结点遍历的时候,都会对结点中的元素进行一次遍历,这就非常糟糕,因为这样我们重复访问了页面1中的元素,有没有可能让遍历的时候每个元素只访问一次呢?
解决这个问题的方法是改进B树的结构。
在B树中,每一个元素都在该树中只出现一次,有可能出现在叶子结点上,也有可能出现在分支节点上;
在B+树中,出现在分支结点中的元素会被当做它们在该分支结点位置的中序前继者(叶子结点)中再次出现,另外,每一个叶子结点都会储存指向后一个叶子结点的指针。
下图就是一个B+树的实例。
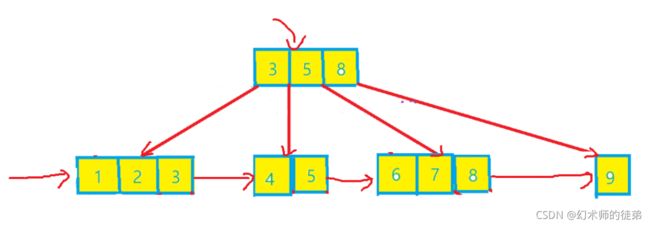
B+树与B树的差异如下:
- 有n棵子树的结点中包含有n个关键字,而不是n-1个。
- 所有的叶子结点包含全部关键字的信息,以及指向这些关键字记录的指针,叶子结点本身依关键字大小自小而大顺序链接。
- 所有的分支结点可以看成索引,结点中仅含有其子树中的最大(或最小)关键字。
如果我们要做随机查找,就先从根节点出发,其余与与B树的查找过程的相似,只不过在B+树中,就算我们在分支结点查找到了待查找的关键字,它并不是真实的查找到了,它只是用来索引的,不能提供实际访问的记录,还是需要到达包含此关键字的终端结点。
如果要从最小关键字进行一个从小到大的顺序查找,我们可以从最左侧的叶子结点出发,不经过分支结点,而是沿着指向下一叶子结点的指针就可以遍历所有关键字。
B+树特别适合带有范围的查找,比如要查找我们学校18~22岁的学生人数,我们可以从根节点出发找到第一个18岁的学生,然后再在叶子结点按顺序查找到符合范围的所有记录。
B+树的插入,删除过程与B树类似,只不过插入和删除的元素都是在叶子结点上进行。
七、散列表查找概述
我们之前的查找都是基于先根据关键字key找到i的下标,再通过顺序存储的存储位置计算方法:
L O C ( a i ) = L O C ( a l ) + ( i − 1 ) ∗ c LOC(a_{i})=LOC(a_{l})+(i-1)*c LOC(ai)=LOC(al)+(i−1)∗c
也就是通过第一个元素的内存存储位置加上i-l1个单元位置,得到最后的内存地址。
可是这真的是必要的吗?我们能否直接通过关键字key找到要查找的记录的内存地址呢?
1.散列表查找的定义
存 储 位 置 = f ( 关 键 字 ) 存储位置=f(关键字) 存储位置=f(关键字)
**散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。**查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找就集合中存在这个记录,则必定在f(key)的位置上。
**我们把这种对应关系称为散列函数,又称哈希(Hash)函数,采用散列技术将记录存储在一块连续的存储空间上,这块连续的存储空间称为散列表或哈希表。**关键字对应的记录的存储位置称为散列位置。
2.散列查找的步骤
整个散列过程分为两步:
- 在存储时,通过散列函数计算散列地址,并按次散列地址存储该记录。
- 当查找记录时,通过关键字通过同样的散列函数计算记录的散列地址,按散列地址访问该记录。
散列技术与线性表、树、图等结构不同,数据元素之间并不直接存在某种逻辑关系,只与关键字有关联,因此散列主要是面向查找的存储结构。
**散列技术最适合的求解问题是查找与给定值相等的记录。**对于查找来说,简化了比较过程,效率大大提高。
比如那种相同的关键字能对应出来很多记录的情况就不适合用散列技术,比如性别男。
散列表也不适合范围查找和获取表中记录的排序,因为数据记录之间已经失去的逻辑关系。
设计一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题,**另一个问题是冲突问题。**即碰到两个关键字key1,key2,
k e y 1 ≠ k e y 2 但 是 却 有 f ( k e y 1 ) = f ( k e y 2 ) key_{1}\ne key_{2}但是却有f(key_{1})=f(key_{2}) key1=key2但是却有f(key1)=f(key2)
这种现象我们称为冲突,并且把key1和key2称为这个散列函数的同义词。
3.散列函数的构造方法
什么是好的散列函数呢?
-
计算简单
如果有一个算法可以保证所有的关键字都不会产生冲突,但是这个算法需要很复杂的计算,会耗费很多时间,这对频繁的查找来说,就会大大降低查找的效率。因此散列函数的计算时间不应该超过其他查找技术与关键字的比较时间。
-
散列地址分布均匀
为了解决散列冲突问题,最好的办法就是尽量让散列地址均匀的分布在存储空间中,这样可以保证存储空间的有效利用,并减少为处理冲突带来的时间。
3.1 直接定址法
取关键字的某个线性函数值作为散列地址:
f ( k e y ) = a ∗ k e y + b f(key)=a*key+b f(key)=a∗key+b
优点:简单、均匀、无冲突。
问题:需要事先知道关键字的分布情况,适合查找表较小且连续的情况。由于这种限制,现实中并不常用。
3.2 数字分析法
像学号之类的东西,它们都是那种前面好多位都相同,只有后面几位不相同的情况,这种情况我们可以就抽取后面那几位作为散列地址。如果这样的抽取工作还是有冲突的问题,可以对抽取出来的数字在进行反转、右环位移、左环位移、甚至前两数与后两数叠加等方法,总的目的就是为了提供一个散列函数,能够合理地将关键字分配到散列表的各位置。
这里我们提到了一个关键词——抽取。抽取方法是使用关键字的一部分来计算散列的存储位置的方法,这在散列函数中是常常用到的方法。
数字分析法适合处理关键字位数比较多的情况,如果事前知道关键字的分布且关键字的若干位分布比较均匀,就可以考虑这个方法。
3.3 平方取中法
这个方法简单,假设关键字是1234,那么他的平方就是1522756,再取中间的三位就是227,用作散列地址。比如关键字4321,它的平方就是18671041,抽取中间的三位数就是671,也可以是710,用作散列地址。平方取中法适合不知道关键字的分布,而位数又不是很多的情况。
3.4折叠法
折叠法就是将关键字从左到右分割成等长的几部分(注意最后一部分分位不够的时候可以短些),然后将这几部分叠加求和,并按照散列表长,取后几位作为散列地址。
有时可能这还不能够保证分布均匀,不妨从一端向另一端来回折叠后对齐相加。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
3.5 除留余数法
这是最常用的构造散列函数的方法,对于散列表长为m的散列函数公式为:
f ( k e y ) = k e y % p ( p ≤ m ) f(key)=key\%p(p\leq m) f(key)=key%p(p≤m)
事实上,这个方法不仅可以对关键字直接取模,也可以先折叠、平方折中后再取模。
很显然,本方法的关键在于选择合适的p,p如果选择的不好,就可能会产生同义词。
例如下表,p取去12
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 12 | 25 | 38 | 15 | 16 | 29 | 78 | 67 | 56 | 21 | 22 |
| 下标 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 12 | 24 | 36 | 48 | 60 | 72 | 84 | 96 | 108 | 120 | 132 |
发现对于第二个表中的关键字,p取12也太糟糕了。
如果我们选p=11,那么
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 12 | 24 | 36 | 48 | 60 | 72 | 84 | 96 | 108 | 120 | 132 |
此时就好的多了。
根据前辈的经验,若散列表长为m,通常p为小于等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
3.6 随机数法
f ( k e y ) = r a n d o m ( k e y ) f(key)=random(key) f(key)=random(key)
当关键字的长度不相等的时候,采用这个方法比较合适。
4.处理散列冲突的方法
4.1 开放定址法
所谓开放定址法就是一旦发生了冲突,就去寻找下一个空的散列空间,只要散列表足够大,空的散列地址总能找到,并将记录存入。
i f ( f ( k e y 待 插 入 ) = = f ( k e y i ) ) 则 f i ( k e y 待 插 入 ) = ( f ( k e y 待 插 入 ) + d i ) % m , i = 1 , 2 , 3 , . . . , m − 1 i 一 直 取 到 不 冲 突 为 止 。 if(f(key_{待插入})==f(key_{i}))\\ 则f_{i}(key_{待插入})=(f(key_{待插入})+d_{i})\%m,i=1,2,3,...,m-1\\ i一直取到不冲突为止。 if(f(key待插入)==f(keyi))则fi(key待插入)=(f(key待插入)+di)%m,i=1,2,3,...,m−1i一直取到不冲突为止。
例如,当关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34}时,表长为12,我们取散列函数为
f ( k e y ) = k e y % 12 f(key)=key\%12 f(key)=key%12
计算前5个时都没有发生冲突问题,直接存入
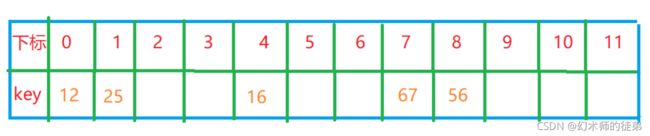
计算key=37时,发现f(37)==1,与25冲突,所以f(37)=(f(37)+1)%12=2,不冲突,所以把37存入下标为2的位置。

接下来22,29,15,47都没有冲突,正常存入

接下来到了key=48,f(48)=0,与12所在的0位置,没事f(48)=(0+1)%12=1 还冲突 没事 f(48)=(1+1)%12=2…直到f(5+1)%12=6时终于又空位了,赶紧存上。

我们把这种解决冲突的开放定址法称为线性探测法。
通过这个例子看出,在解决冲突问题的时候,也会碰到如48和37这种本来都不是同义词却需要争夺同一个地址的问题,我们称这种现象叫做堆积。显然,堆积的出现会大大影响效率,并且当key=34的时候,f(key)=10,与22冲突,按我们的算法他只会往后寻找空闲位置,明明9就有一个空闲位置,尽管可以不断地求余数最终找到9这个位置,但是效率也太差了吧,由此我们引出了改进的二次探测法。
f i ( k e y ) = ( f ( k e y ) + d i ) % m d i = 1 2 , − 1 2 , 2 2 , − 2 2 , . . . , q 2 , − q 2 , q ≤ m / 2 f_{i}(key)=(f(key)+d_{i})\%m\\ d_{i}=1^{2},-1^{2},2^{2},-2^{2},...,q^{2},-q^{2},q\leq m/2 fi(key)=(f(key)+di)%mdi=12,−12,22,−22,...,q2,−q2,q≤m/2
增加平方运算的目的是为了不让关键字都聚集在某一块区域,减少堆积的问题。
还有一种冲突的解决犯法是对位移量di采用随机函数计算得到,称为随机探测法。
这里的随机数是伪随机数,如果我们设置的随机种子相同,则不断调用随机函数可以生成不重复的数列,我们在查找的过程中,用同样的随机种子,得到的数列是一样的,相同的di自然可以访问到相同的散列地址。
f i ( k e y ) = ( f ( k e y ) + d i ) % m f_{i}(key)=(f(key)+d_{i})\%m fi(key)=(f(key)+di)%m
4.2 再散列函数法
对于散列表来说,我们可以事先准备多个散列函数。
f i ( k e y ) = R H i ( k e y ) , i = 1 , 2 , . . . , k f_{i}(key)=RH_{i}(key),i=1,2,...,k fi(key)=RHi(key),i=1,2,...,k
RHi就是不同的散列函数,可以把前面说的什么除留余数、折叠、平方取中等全部用上。每当散列地址冲突时,就换一个散列函数计算,相信总有一个可以把冲突问题解决掉。这种方法能够使得关键字不聚集,当然,相应地也增加了计算的时间。
4.3 链地址法
链地址法的思想是用一个单链表存储冲突的关键字,如对于关键字集合{12,67,56,16,25,37,22,29,15,47,48,34},我们以12位除数,根据链地址法可以得到以下图:

缺点是查找时需要遍历单链表,性能会有所损耗。
4.4 公共溢出区法
思想是这样的:你不是冲突吗?好,冲突的都跟我走,我给你们建立一个公共的溢出区来存放。
就前面的例子来说,我们有三个关键字{37,48,34}与前面的关键字位置冲突,那么就把它们存储到溢出表中,如下图:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 基本表 | 12 | 25 | ^ | 15 | 16 | 29 | ^ | 67 | 57 | ^ | 22 | 47 |
| 溢出表 | 37 | 48 | 34 |
在查找过程中,先根据基本表的相应位置进行查找,即f(key)先看看在不在m以内,如果不在的话就在溢出表中顺序查找。
如果对于基本表而言,有冲突的数据很少的情况下,公共溢出区的查找性能还是非常高的。
八、散列表查找的实现
1.除留余数法+开放定址法
//散列表
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12
#define NULLKEY -32768
typedef struct {
int* arr;//数组存储
int count;//存储的元素个数
}HashTable;
void HashInit(HashTable* HT);
int Hash(int key);//哈希函数采用除留余数法
void HashInsert(HashTable* HT, keyType key);
bool HashSearch(HashTable* HT, keyType key, int* addr);
//addr表示返回查找到的下标
bool HashDelete(HashTable* HT, keyType key);
bool HashEmpty(HashTable* HT);
bool HashFull(HashTable* HT);
void Hashdestroy(HashTable* HT);
int m = 0;
void HashInit(HashTable* HT)
{
assert(HT);
m = HASHSIZE;
keyType* tmp = (keyType*)malloc(sizeof(keyType) * m);
if (tmp == NULL)
{
printf("malloc fault\n");
exit(-1);
}
HT->arr = tmp;
HT->count = m;
for (int i = 0; i < m; i++)
HT->arr[i] = NULLKEY;
}
//哈希函数采用除留余数法
int Hash(int key)
{
return key % m;
}
void HashInsert(HashTable* HT, keyType key)
{
assert(HT);
assert(!HashFull(HT));
int addr = Hash(key);
int fkey = Hash(key);
//当散列冲突的时候
//while (HT->arr[addr] != NULLKEY)
//{
// addr = (addr + 1) % m;//开放定址法的线性探测
//}
//int sgn = 1;
//int d = 1;
//while (HT->arr[addr] != NULLKEY && d <= m/2)//开放定址法平方探测
//{
// addr = (fkey + sgn * d * d + m * m) % m;
// sgn = -sgn;
// if (sgn == 1)
// d++;
//}
//开放定址法随机探测
int i = 1;
while (HT->arr[addr] != NULLKEY)
{
srand(i);
i++;
int d = rand() % m;
addr = (fkey + d) % m;
}
HT->arr[addr] = key;
}
bool HashSearch(HashTable* HT, keyType key, int* addr)
{
assert(HT);
*addr = Hash(key);
int fkey = Hash(key);
//开放定址法线性探测的搜索
//while (HT->arr[*addr] != key)
//{
// *addr = (*addr + 1) % m;
// //如果查到的位置是NULLKEY或者回到了原来开始的位置 说明查找失败了
// if (HT->arr[*addr] == NULLKEY || *addr == Hash(key))
// return UNSUCCESS;
//}
//开放定址法平方探测的搜索
//int sgn = 1;
//int d = 1;
//while (HT->arr[*addr] != key && d <= m/2)
//{
// *addr = (fkey + sgn * d * d + m * m) % m;
// sgn = -sgn;
// if (sgn == 1)
// d++;
// if (HT->arr[*addr] == NULLKEY || d > m / 2)
// return UNSUCCESS;
//}
//随机探测的搜索
int used[HASHSIZE] = { 0 };
int count = 0;
int i = 1;
while (HT->arr[*addr] != key)
{
if (used[*addr] == 0)
{
used[*addr] = 1;
count++;
}
srand(i);
i++;
int d = rand() % m;
*addr = (fkey + d) % m;
if (HT->arr[*addr] == NULLKEY || count == 12)
return UNSUCCESS;
}
return SUCCESS;
}
bool HashDelete(HashTable* HT, keyType key)
{
assert(HT);
assert(!HashEmpty(HT));
int addr;
if (HashSearch(HT, key, &addr) == SUCCESS)
{
HT->arr[addr] = NULLKEY;
return true;
}
else
{
return false;
}
}
bool HashFull(HashTable* HT)
{
assert(HT);
for (int i = 0; i < m; i++)
{
if (HT->arr[i] == NULLKEY)
return false;
}
return true;
}
bool HashEmpty(HashTable* HT)
{
assert(HT);
int n = 0;
for (int i = 0; i < m && HT->arr[i] == NULLKEY; i++)
{
n++;
}
if (n == m)
return true;
else
return false;
}
void Hashdestroy(HashTable* HT)
{
assert(HT);
free(HT->arr);
HT->count = 0;
}
void test3()
{
HashTable H;
HashInit(&H);
int l;
HashSearch(&H, 44, &l);
int a[] = { 12,67,56,16,25,37,22,29,15,47,48,34 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
HashInsert(&H, a[i]);
}
int addr;
bool b = HashSearch(&H, 66, &addr);
HashSearch(&H, 48, &addr);
HashDelete(&H, 48);
HashSearch(&H, 66, &addr);
Hashdestroy(&H);
}
int main()
{
test3();
return 0;
}
2.除留余数法+链地址法
//除留余数法+链地址法
typedef struct LinkHashNode {
keyType data;
struct LinkHashNode* next;
}LHNode;
typedef struct {
LHNode* arr;
int count;
}LinkHashTable;
void LinkHashInit(LinkHashTable* LHT, int size);
void LHashInsert(LinkHashTable* LHT, keyType key);
bool LHashSearch(LinkHashTable* LHT, keyType key, LHNode** paddr, int* addr);
bool LHashDelete(LinkHashTable* LHT, keyType key);
bool LHashEmpty(LinkHashTable* LHT);
void LHashdestroy(LinkHashTable* LHT);
void LinkHashInit(LinkHashTable* LHT, int size)
{
assert(LHT);
LHT->arr = (LHNode*)malloc(sizeof(LHNode) * size);
for (int i = 0; i < size; i++)
{
LHT->arr[i].data = HEAD;
LHT->arr[i].next = NULL;
}
LHT->count = size;
m = size;
}
bool LHashEmpty(LinkHashTable* LHT)
{
assert(LHT);
for (int i = 0; i < LHT->count; i++)
{
if (LHT->arr[i].next != NULL)
return false;
}
return true;
}
void LHashInsert(LinkHashTable* LHT, keyType key)
{
assert(LHT);
int addr = Hash(key);
LHNode* p = LHT->arr[addr].next;
LHNode* q = p;
if (p != NULL)
{
while (p != NULL)
{
q = p;
p = p->next;
}
LHNode* newnode = (LHNode*)malloc(sizeof(LHNode));
if (newnode == NULL)
{
printf("malloc fault\n");
exit(-1);
}
newnode->data = key;
newnode->next = q->next;
q->next = newnode;
}
else
{
LHNode* newnode = (LHNode*)malloc(sizeof(LHNode));
if (newnode == NULL)
{
printf("malloc fault\n");
exit(-1);
}
newnode->data = key;
newnode->next = NULL;
LHT->arr[addr].next = newnode;
}
}
bool LHashSearch(LinkHashTable* LHT, keyType key, LHNode** paddr, int* addr)
{
assert(LHT);
int fkey = Hash(key);
*addr = fkey;
LHNode* p = LHT->arr[fkey].next;
if (p == NULL)
{
*paddr = NULL;
return UNSUCCESS;
}
while (p != NULL)
{
if (key == p->data)
{
*paddr = p;
return SUCCESS;
}
p = p->next;
}
*paddr = NULL;
return UNSUCCESS;
}
bool LHashDelete(LinkHashTable* LHT, keyType key)
{
assert(LHT);
assert(!LHashEmpty(LHT));
LHNode* pos;
int addr;
if (LHashSearch(LHT, key, &pos, &addr) == UNSUCCESS)
return UNSUCCESS;
LHNode* p = LHT->arr[addr].next;
if (p == pos)
{
LHT->arr[addr].next = p->next;
free(p);
return SUCCESS;
}
else
{
while (p->next != pos)
{
p = p->next;
}
p->next = (pos)->next;
free(pos);
pos = NULL;
return SUCCESS;
}
}
void LHashdestroy(LinkHashTable* LHT)
{
for (int i = 0; i < LHT->count; i++)
{
if (LHT->arr[i].next != NULL)
{
LHNode* q, * p;
p = LHT->arr[i].next;
while (p != NULL)
{
q = p;
p = p->next;
free(q);
}
}
}
free(LHT->arr);
LHT->arr = NULL;
LHT->count = 0;
}
void test4()
{
LinkHashTable H;
LinkHashInit(&H, 12);
int l;
LHNode* pos;
LHashSearch(&H, 44, &pos, &l);
int a[] = { 12,67,56,16,25,37,22,29,15,47,48,34 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
LHashInsert(&H, a[i]);
}
int addr;
bool b = LHashSearch(&H, 66, &pos, &addr);
LHashSearch(&H, 48, &pos, &addr);
LHashDelete(&H, 48);
LHashSearch(&H, 66, &pos, &addr);
LHashdestroy(&H);
}
int main()
{
test4();
return 0;
}
3.除留余数法+公共溢出区法
//除留余数法+公共溢出区法
typedef struct {
keyType* a;
keyType* ofl;
int count;
}OHashTable;
void OHashTableInit(OHashTable* OHT, int size);
bool OHashFull(OHashTable* OHT);
void OHashInsert(OHashTable* OHT, keyType key);
bool OHashEmpty(OHashTable* OHT);
bool OHashSearch(OHashTable* OHT, keyType key, bool* number, int* addr);
void OHashDelete(OHashTable* OHT);
void OHashTableInit(OHashTable* OHT, int size)
{
assert(OHT);
OHT->a = (keyType*)malloc(sizeof(keyType) * size);
if (OHT->a == NULL)
{
printf("malloc fault\n");
exit(-1);
}
OHT->ofl = (keyType*)malloc(sizeof(keyType) * size);
if (OHT->ofl == NULL)
{
printf("malloc fault\n");
exit(-1);
}
OHT->count = size;
m = size;
for (int i = 0; i < m; i++)
{
OHT->a[i] = OHT->ofl[i] = NULLKEY;
}
}
bool OHashFull(OHashTable* OHT)
{
assert(OHT);
for (int i = 0; i < m; i++)
{
if (OHT->ofl[i] == NULLKEY)
return false;
}
return true;
}
void OHashInsert(OHashTable* OHT, keyType key)
{
assert(OHT);
assert(!OHashFull(OHT));
keyType fkey = Hash(key);
if (OHT->a[fkey] == NULLKEY)
OHT->a[fkey] = key;
else
{
int i;
for (i = 0; i < m; i++)
{
if (OHT->ofl[i] == NULLKEY)
break;
}
OHT->ofl[i] = key;
}
}
bool OHashEmpty(OHashTable* OHT)
{
assert(OHT);
for (int i = 0; i < m; i++)
{
if (OHT->a[i] != NULLKEY)
return false;
}
return true;
}
bool OHashSearch(OHashTable* OHT, keyType key, bool* number, int* addr)
{
assert(OHT);
assert(!OHashEmpty(OHT));
keyType fkey = Hash(key);
if (OHT->a[fkey] == key)
{
*number = 0;
*addr = fkey;
return SUCCESS;
}
else
{
for (int i = 0; i < m; i++)
{
if (OHT->ofl[i] == key)
{
*number = 1;
*addr = i;
return SUCCESS;
}
}
return UNSUCCESS;
}
}
bool OHashDelete(OHashTable* OHT, keyType key)
{
assert(OHT);
bool number;
int addr;
if (OHashSearch(OHT, key, &number, &addr) == SUCCESS)
{
if (number == 0)
{
OHT->a[addr] = NULLKEY;
}
else
{
OHT->ofl[addr] = NULLKEY;
}
return SUCCESS;
}
return UNSUCCESS;
}
void OHashdestroy(OHashTable* OHT)
{
assert(OHT);
free(OHT->a);
free(OHT->ofl);
OHT->count = 0;
m = 0;
}
void test5()
{
OHashTable H;
OHashTableInit(&H, 12);
int l;
bool number;
//OHashSearch(&H, 44, &number, &l);
int a[] = { 12,67,56,16,25,37,22,29,15,47,48,34 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
OHashInsert(&H, a[i]);
}
int addr;
bool b = OHashSearch(&H, 66, &number, &l);
OHashSearch(&H, 48, &number, &l);
OHashDelete(&H, 48);
bool c = OHashSearch(&H, 34, &number, &l);
OHashdestroy(&H);
}
4.散列表查找的性能分析
如果不存在散列冲突的情况,散列表查找的时间复杂度是O(1),不过,理想终归是理想,实际中难免避免散列冲突的情况,我们退而求其次,在实际的应用中,散列查找的平均查找长度取决于那些因素呢?
-
散列函数是否均匀
散列函数的好坏直接影响了出现冲突的频繁程度,不过,由于不同的散列函数对同一组随机的关键字产生冲突的可能性是相同的,因此我们可以不考虑它对平均查找长度的影响。
-
处理冲突的办法
相同的关键字,相同的散列函数,但**处理冲突的方法不一样,会使得平均查找程度不同。**比如线性探测处理冲突会产生堆积,显然没有二次探测法好,而链地址法处理冲突不会产生任何堆积,因而具有更佳的平均查找性能。
-
散列表的装填因子
装 填 因 子 α = 填 入 表 的 记 录 个 数 散 列 表 长 度 装填因子\alpha=\frac{填入表的记录个数}{散列表长度} 装填因子α=散列表长度填入表的记录个数
a代表散列表的装满程度,填入表中的数据越多,a越大,产生冲突的可能性就越大。这也就是说,散列表的平均查找长度取决于装填因子,而不是取决于查找集合中记录的个数。因此,不管记录个数n有多大,我们总可以选择一个合适的装填因子以便将平均查找长度限定在一个范围之内,此时我们的散列查找的时间复杂度便是O(1)。为了做到这一点,常常我们把散列表的空间设置的比查找集合大,此时虽然浪费了一定的空间,但是换来的是查找效率的大大提升,总的来说,还是非常值的。