写在WCF实现RESTFul Web Service之前(三):RESTful WebService VS SOAP WebService
本文主要是转载,感谢原文出处的人月神话(http://blog.sina.com.cn/s/blog_493a845501012566.html)和Diggbag(http://www.blogjava.net/diggbag/articles/361703.html)。
SOAP
SOAP最早是针对RPC的一种解决方案,简单对象访问协议,很轻量,同时作为应用协议可以基于多种传输协议来传递消息(Http,SMTP等)。但是随着SOAP作为WebService的广泛应用,不断地增加附加的内容,使得现在开发人员觉得SOAP很重,使用门槛很高。在SOAP后续的发展过程中,WS-*一系列协议的制定,增加了SOAP的成熟度,也给SOAP增加了负担。
REST
REST其实并不是什么协议也不是什么标准,而是将Http协议的设计初衷作了诠释,在Http协议被广泛利用的今天,越来越多的是将其作为传输协议,而非原先设计者所考虑的应用协议。SOAP类型的WebService就是最好的例子,SOAP消息完全就是将Http协议作为消息承载,以至于对于Http协议中的各种参数(例如编码,错误码等)都置之不顾。其实,最轻量级的应用协议就是Http协议。Http协议所抽象的get,post,put,delete就好比数据库中最基本的增删改查,而互联网上的各种资源就好比数据库中的记录(可能这么比喻不是很好),对于各种资源的操作最后总是能抽象成为这四种基本操作,在定义了定位资源的规则以后,对于资源的操作通过标准的Http协议就可以实现,开发者也会受益于这种轻量级的协议。
REST是一种架构风格,其核心是面向资源,REST专门针对网络应用设计和开发方式,以降低开发的复杂性,提高系统的可伸缩性。REST提出设计概念和准则为:
1.网络上的所有事物都可以被抽象为资源(resource)
2.每一个资源都有唯一的资源标识(resource identifier),对资源的操作不会改变这些标识
3.所有的操作都是无状态的
REST简化开发,其架构遵循CRUD原则,该原则告诉我们对于资源(包括网络资源)只需要四种行为:创建,获取,更新和删除就可以完成相关的操作和处理。您可以通过统一资源标识符(Universal Resource Identifier,URI)来识别和定位资源,并且针对这些资源而执行的操作是通过 HTTP 规范定义的。其核心操作只有GET,PUT,POST,DELETE。 由于REST强制所有的操作都必须是stateless的,这就没有上下文的约束,如果做分布式,集群都不需要考虑上下文和会话保持的问题。极大的提高系统的可伸缩性。
对于SOAP Webservice和Restful Webservice的选择问题
首先需要理解就是SOAP偏向于面向活动,有严格的规范和标准,包括安全,事务等各个方面的内容,同时SOAP强调操作方法和操作对象的分离,有WSDL文件规范和XSD文件分别对其定义。而REST强调面向资源,只要我们要操作的对象可以抽象为资源即可以使用REST架构风格。如果从这个意义上讲,是否使用REST就需要考虑资源本身的抽象和识别是否困难,如果本身就是简单的类似增删改查的业务操作,那么抽象资源就比较容易,而对于复杂的业务活动抽象资源并不是一个简单的事情。比如校验用户等级,转账,事务处理等,这些往往并不容易简单的抽象为资源。
其次如果有严格的规范和标准定义要求,而且前期规范标准需要指导多个业务系统集成和开发的时候,SOAP风格由于有清晰的规范标准定义是明显有优势的。我们可以在开始和实现之前就严格定义相关的接口方法和接口传输数据。
简单数据操作,无事务处理,开发和调用简单这些是使用REST架构风格的优势。而对于较为复杂的面向活动的服务,如果我们还是使用REST,很多时候都是仍然是传统的面向活动的思想通过转换工具再转换得到REST服务,这种使用方式是没有意义的。
REST核心是url和面向资源,url代替了原来复杂的操作方法。REST允许我们通过url设计系统,就像测试驱动开发使用测试用例设计类接口一样。所有可以被抽象为资源的东西都可以使用RESTful的url。使用REST的关键是如何抽象资源,抽象的越精确,对REST的应用越好。如何进行抽象,面向资源的设计和传统的面向结构和对象设计区别,资源和对象,数据库表之间的差别是另外一个在分析设计时候要考虑的问题。在REST分析设计中如何改变传统的SOAP分析设计思想又是一个重要问题。
举例详细说明
RESTful Web 服务使用标准的 HTTP 方法 (GET/PUT/POST/DELETE) 来抽象所有 Web 系统的服务能力,而SOAP 应用都通过定义自己个性化的接口方法来抽象 Web 服务,这更像我们经常谈到的 RPC。例如本例中的 getUserList 与 getUserByName 方法。
RESTful Web 服务使用标准的 HTTP 方法优势,从大的方面来讲:标准化的 HTTP 操作方法,结合其他的标准化技术,如 URI,HTML,XML 等,将会极大提高系统与系统之间整合的互操作能力。尤其在 Web 应用领域,RESTful Web 服务所表达的这种抽象能力更加贴近 Web 本身的工作方式,也更加自然。
使用标准 HTTP 方法实现的 RRESTful Web 服务也带来的 HTTP 方法本身的一些优势和对比:
1. 无状态性(Stateless)
HTTP 协议从本质上说是一种无状态的协议,客户端发出的 HTTP 请求之间可以相互隔离,不存在相互的状态依赖。基于 HTTP 的 ROA,以非常自然的方式来实现无状态服务请求处理逻辑。对于分布式的应用而言,任意给定的两个服务请求 Request 1 与 Request 2, 由于它们之间并没有相互之间的状态依赖,就不需要对它们进行相互协作处理,其结果是:Request 1 与 Request 2 可以在任何的服务器上执行,这样的应用很容易在服务器端支持负载平衡 (load-balance)。
2. 安全操作与幂指相等特性(Safety /Idempotence)
HTTP 的 GET、HEAD 请求本质上应该是安全的调用,即:GET、HEAD 调用不会有任何的副作用,不会造成服务器端状态的改变。对于服务器来说,客户端对某一 URI 做 n 次的 GET、HAED 调用,其状态与没有做调用是一样的,不会发生任何的改变。
HTTP 的 PUT、DELTE 调用,具有幂指相等特性 , 即:客户端对某一 URI 做 n 次的 PUT、DELTE 调用,其效果与做一次的调用是一样的。HTTP 的 GET、HEAD 方法也具有幂指相等特性。
HTTP 这些标准方法在原则上保证你的分布式系统具有这些特性,以帮助构建更加健壮的分布式系统。
3. 安全控制
为了说明问题,基于上面的在线用户管理系统,我们给定以下场景:
参考一开始我们给出的用例图,对于客户端 Client2,我们只希望它能以只读的方式访问 User 和 User List 资源,而 Client1 具有访问所有资源的所有权限。
如何做这样的安全控制?通行的做法是:所有从客户端 Client2 发出的 HTTP 请求都经过代理服务器 (Proxy Server)。代理服务器制定安全策略:所有经过该代理的访问 User 和 User List 资源的请求只具有读取权限,即:允许 GET/HEAD 操作,而像具有写权限的 PUT/DELTE 是不被允许的。
如果对于 RESTful,我们看看这样的安全策略是如何部署的。如下图所示:
图1. REST 与代理服务器 (Proxy Servers):
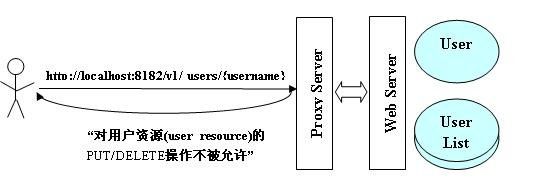
一般代理服务器的实现根据 (URI, HTTP Method) 两元组来决定 HTTP 请求的安全合法性。当发现类似于(http://localhost:8182/v1/users/{username},DELETE)这样的请求时,予以拒绝。
对于 SOAP,如果我们想借助于既有的代理服务器进行安全控制,会比较尴尬,如下图:
图2. SOAP 与代理服务器 (Proxy Servers)
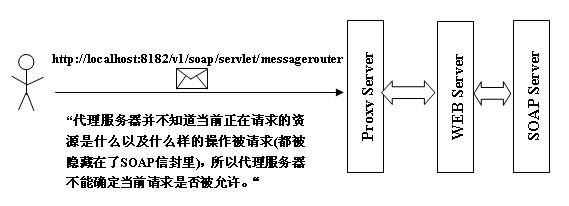
所有的 SOAP 消息经过代理服务器,只能看到(http://localhost:8182/v1/soap/servlet/messagerouter, HTTP POST)这样的信息,如果代理服务器想知道当前的 HTTP 请求具体做的是什么,必须对 SOAP 的消息体解码,这样的话,意味着要求第三方的代理服务器需要理解当前的 SOAP 消息语义,而这种 SOAP 应用与代理服务器之间的紧耦合关系是不合理的。
4. 缓存
众所周知,对于基于网络的分布式应用,网络传输是一个影响应用性能的重要因素。如何使用缓存来节省网络传输带来的开销,这是每一个构建分布式网络应用的开发人员必须考虑的问题。
HTTP 协议带条件的 HTTP GET 请求 (Conditional GET) 被设计用来节省客户端与服务器之间网络传输带来的开销,这也给客户端实现 Cache 机制 ( 包括在客户端与服务器之间的任何代理 ) 提供了可能。HTTP 协议通过 HTTP HEADER 域:If-Modified-Since/Last- Modified,If-None-Match/ETag 实现带条件的 GET 请求。REST 的应用可以充分地挖掘 HTTP 协议对缓存支持的能力。当客户端第一次发送 HTTP GET 请求给服务器获得内容后,该内容可能被缓存服务器 (Cache Server) 缓存。当下一次客户端请求同样的资源时,缓存可以直接给出响应,而不需要请求远程的服务器获得。而这一切对客户端来说都是透明的。
图3. REST 与缓存服务器 (Cache Server)
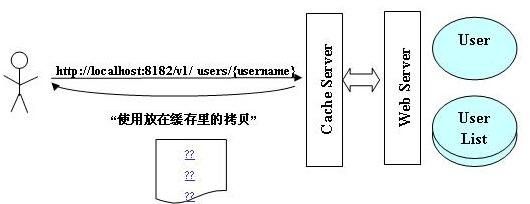
而对于 SOAP,情况又是怎样的呢?
使用 HTTP 协议的 SOAP,由于其设计原则上并不像 REST 那样强调与 Web 的工作方式相一致,所以,基于 SOAP 应用很难充分发挥 HTTP 本身的缓存能力。
图4. SOAP 与缓存服务器 (Cache Server)
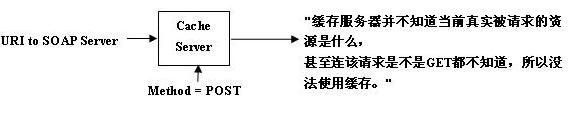
两个因素决定了基于 SOAP 应用的缓存机制要远比 REST 复杂:
1. 所有经过缓存服务器的 SOAP 消息总是 HTTP POST,缓存服务器如果不解码 SOAP 消息体,没法知道该 HTTP 请求是否是想从服务器获得数据。
2. SOAP 消息所使用的 URI 总是指向 SOAP 的服务器,如本文例子中的 http://localhost:8182/v1/soap/servlet/messagerouter,这并没有表达真实的资源 URI,其结果是缓存服务器根本不知道那个资源正在被请求,更不用谈进行缓存处理。
5. 连接性
在一个纯的 SOAP 应用中,URI 本质上除了用来指示 SOAP 服务器外,本身没有任何意义。与 REST 的不同的是,无法通过 URI 驱动 SOAP 方法调用。例如在我们的例子中,当我们通过getUserList SOAP 消息获得所有的用户列表后,仍然无法通过既有的信息得到某个具体的用户信息。唯一的方法只有通过 WSDL 的指示,通过调用 getUserByName 获得,getUserList 与 getUserByName 是彼此孤立的。
而对于 REST,情况是完全不同的:通过 http://localhost:8182/v1/users URI 获得用户列表,然后再通过用户列表中所提供的 LINK 属性,例如 <link>http://localhost:8182/v1/users/tester</link>获得 tester 用户的用户信息。这样的工作方式,非常类似于你在浏览器的某个页面上点击某个 hyperlink, 浏览器帮你自动定向到你想访问的页面,并不依赖任何第三方的信息。
总结
典型的基于 SOAP 的 Web 服务以操作为中心,每个操作接受 XML 文档作为输入,提供 XML 文档作为输出。在本质上讲,它们是 RPC 风格的。而在遵循 REST 原则的 ROA 应用中,服务是以资源为中心的,对每个资源的操作都是标准化的 HTTP 方法。
本文主要集中在以上的几个方面,对 SOAP 与 REST 进行了对比,可以看到,基于 REST 构建的系统其系统的扩展能力要强于 SOAP,这可以体现在它的统一接口抽象、代理服务器支持、缓存服务器支持等诸多方面。并且,伴随着 Web Site as Web Services 演进的趋势,基于 REST 设计和实现的简单性和强扩展性,有理由相信,REST 将会成为 Web 服务的一个重要架构实践领域。