关于信贷评分卡模型,看这篇就够了!
风险并不是所有人都能轻松看到,信贷公司同样如此。
8月4日下午15:00,顶象研发总监就评分卡模型展开分享,详细介绍了评分卡模型的原理、评分卡模型的构建过程、评分卡模型的开发投产以及顶象的评分卡模型实践。
评分卡模型原理
通常来说,我们把贷款分为抵押贷款和信用贷款。抵押贷款顾名思义需要贷款人以抵押物作担保向银行贷款,对银行来说这是一种“有保障”的贷款,而信用贷则不需要提供抵押或担保,仅凭自己的信誉就能取得贷款,这也在一定程度上加大了信用贷的利率和风险。
因而,信用贷对于金融机构和借贷公司来说是一个不小的风险。
那么,如何帮助金融机构和借贷公司来规避风险呢?业内的有效解决方法是建立评分卡模型来帮助金融机构和借贷公司来评估借贷人的风险。
评分卡模型是常用的金融风控手段之一,诞生于上世纪50年代,由FICO公司开发,经历了70多年依然在信用评估中不可替代,几乎每一家金融公司都在用评分卡模型来评估风险。

其原理是根据客户的各种属性和行为数据,利用信用评分模型,对客户的信用进行评分,从而决定是否给予授信,授信的额度和利率,减少在金融交易中存在的交易风险。
按照不同的业务阶段,可以划分为三种:
贷前:申请评分卡(Application score card),称为A卡;
贷中:行为评分卡(Behavior score card),称为B卡;
贷后:催收评分卡(Collection score card),称为C卡。
如何构建评分卡模型?
首先我们来初步认识下评分卡。
评分卡分为离散特征(性别、婚姻状况、学历)和连续特征(年龄、月收入),其中年龄和月收入又进行字段细分。

要构建一个评分卡,需要以下几个步骤:
首先是数据准备。一般来说,构建评分卡可用的数据也分为三类:
即个人在金融机构的账户与行为数据,包括交易行为、日常消费、存款信息、投资理财、逾期信息等;
个人在中国人民银行的征信报告,包括个人近5年内,在国内留下的所有信用信息、家庭住址、工作单位、配偶信息、手机号、公积金、社保信息、信贷记录、房贷车贷记录、历史逾期信息、违法行为、征信查询信息,基于人行征信,可以衍生出 “上千维” 特征,足以构建一个效果非常不错的贷前评分卡;
第三方公司提供的个人信用分,诸如芝麻分、微信支付分、京东信用分、百融分等。
本质上来说,中国人民银行的征信报告好于金融机构的账户与行为数据好于第三方公司提供的个人信用分。

其次是数据探索,包括数据的缺失情况、直方图分布、最大值、最小值、均值、分位数。
然后是数据预处理,包括数据清洗、缺失值处理、异常值处理。
特征筛选,通过统计学的方法,筛选出对违约状态影响最显著的指标。主要有单变量特征选择和基于机器学习的方法。
分箱,包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三个部分。
模型评估,评估模型的区分能力、预测能力、稳定性,并形成模型评估报告,得出模型是否可以使用的结论。
生成评分卡(信用评分),根据逻辑回归的系数和WOE等确定信用评分的方法,将Logistic模型转换为标准评分的形式。
建立评分系统(布置上线),根据生成的评分卡,建立自动信用评分系统。
最后通过评分卡模型收集违约信息,进行效果监控。

那么,如何对特征进行分箱(区间划分),为什么要分箱?每个分箱的得分,怎么确定的?
WOE、IV、PSI、KS,它们有什么含义?
我们先来看分箱。
分箱是对特征变量进行区间划分或者对不同枚举值进行合并的过程,它可以降低特征的复杂度,提升变量可解释性。

分箱的两个功能:
拆分:对 “连续变量” 进行分段离散化,使它变成 “离散变量”。比如:年龄、月收入。拆分分为等频拆分、等距拆分、信息熵分箱。
以信息熵分箱为例,这是一种监督的拆分方式,可衡量好坏样本的区分度。其方法是先对特征所有值进行排序遍历特征所有值 (连续值需要进行细粒度分组),以每个值做为划分点,计算 “条件熵”,选择 “条件熵最小” 的特征值作为分割点,将数据分成两部分,设置一些停止条件,重复以上步骤。

合并:减少离散变量的状态数,对 “离散变量” 进行合并。比如:地区、学历。合并又分为卡方检验和WOE值。
以卡方检验为例。卡方检验是一种假设检验方法,先提出两个变量没有相关性,然后对数据进行抽象证明他们是否有相关性。根据卡方检验的计算公式对比实际频数和理论频数是否具有显著差异,卡方值越小,实际频数与理论频数就越接近,也就证明卡方检验成立,也就可以证明分组与分类不相关。

每个变量的分箱数,控制在十个以下,通常 5个左右是最佳的;分箱越多,模型过拟合的风险越高,模型的稳定性也会变差,在金融场景,风险可控与稳定至关重要。
WOE (Weight of Evidence) 是判断 “一个分箱区间”,区分好坏样本的能力。
其公式如下:
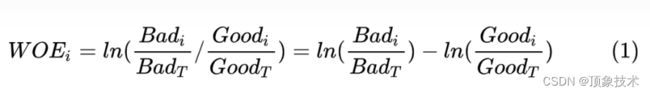
IV (Information Value) 是计算各分箱区间的 WOE 加权和,可以衡量 “一个特征”,区分好坏样本的能力。
其公式如下:
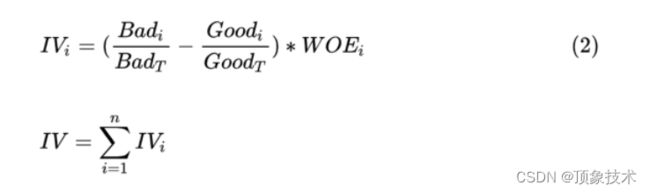
但事实上,分箱方法很多,顶象实现了一种简单可行的全自动分箱方法。
对于连续变量,可先进行等频拆分得到细分箱,对于离散变量可直接认为是细分箱,然后进行WOE合并,每次合并WOE值最接近的相邻细分箱或离散值,同时要满足以下条件:
1、每个分箱至少包含 5% 的样本;
2、每个分箱必须包含 正常样本与违约样本;
3、分箱数控制在 5个左右;
4、除了 age 外,其他变量尽可能保持单调性。

值得注意的是,特征分箱并不是完美的,但总体来说利大于弊。
比如连续变量分箱、离散变量合并,会 “降低特征变量的复杂度,降低模型过拟合的风险”;可以 “增强模型的稳定性”,对特征变量的异常波动不会反应太大,也利于适应更广泛的客群;将特征变量划分为有限的分箱,可以 “增强模型的可解释性”;可以更自然地将 “缺失值作为单独的分箱”。

目前,主流的评分卡模型仍以逻辑回归模型为主要模型。假设客户违约的概率为p,则正常的概率为1 − p。由此可以得到违约几率:
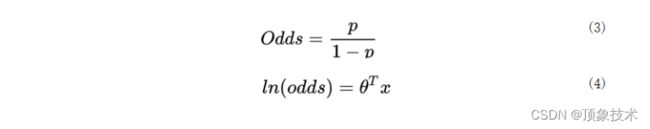
评分卡是 “将Odds赔率的对数,转变为分值的线性函数”,表示如下:

为了确定公式中的A与B值,需要定义2个条件:
1、基准分 P_0 ,在Odds赔率为 θ_0 时的得分 (例如,赔率为 1:50 时,基准分为 500)
2、PDO (point of double),Odds赔率翻倍时减少的分值 (赔率为 1:25 时,减少 20)

评分卡设定的分值刻度可以通过将分值表示为几率对数的线性表达式来定义,即:
A和B都是常数且(a>=0, b>=0)。当希望违约几率越低,得分越高时,取负号。通常情况下,这是分值的理想变动方向,即高分值代表低风险,低分值代表高风险。
逻辑回归算法相比于其他算法更优,一方面是因为其“可解释性强,易于理解”,可以追查每个变量的得分,变量的权重也可以从业务视角去交叉验证;一方面是其“简单,稳定”可配合分箱可以进一步增强稳定性,分箱本身也一定程度上解决了部分非线性问题;并且“易于跟踪,排查问题”,当模型衰退、客群发生变化时,通过分箱的 PSI 与 IV 可以快速定位出问题的原因。
评分卡模型如何评估、应用、跟踪?
评分卡模型评估分为效果评估和稳定性评估。
先来看效果评估。
模型输出的每个评分值,都可以作为阈值。如果小于阈值,我们可以预测为“违约”,如果大于等于阈值,则可以预测为“正常”,根据每个阈值,可以计算出混淆矩阵,然后根据混淆矩阵我们可以进一步计算出违约比率或正常比率,进而得出KS曲线或者ROC曲线。
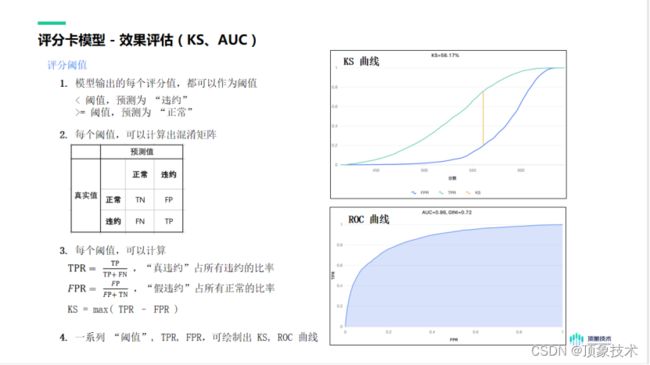
其中,KS曲线具备对好坏样本的区分能力,如果KS值小于0.20则不建议采用,大于0.75则可能存在错误。

但需要注意的是,单独从KS训练样本评估出的KS值还不足以评估模型的好坏,一定要做长期的验证来证明KS值是稳定的,确保模型在验证集上的 KS 与 训练样本上的 KS,不出现大幅度下降,如果下降幅度超过10% (比如: 训练集 KS = 0.50,4个月后 KS_4 = 0.45, 下降幅度为10%),说明模型衰退明显,也就进一步说明其稳定性是有问题的。

接下来看下稳定性评估。
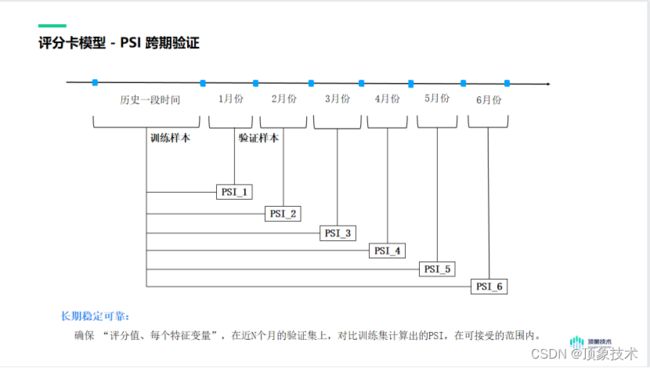
PSI (Population Stability Index)称为群体稳定性指标,用来 “对比2个数据集的分布,是否发生比较大的偏差”,对比一定要有参照物,对评分卡模型来说,参照物是模型训练时的 “训练样本” (期望分布),而评估对象称为 “验证样本”(实际分布)。
PSI 越小则说明稳定性越好,如果PSI大于0.50则需要进一步分析特征变量。

PSI 可从两个计算维度来看,即评分 PSI和特征变量 PSI。
评分 PSI对 “模型的输出分值” 进行分箱,在验证集与训练集上做 PSI 对比,判断是否发生大的变化。如下图,期望分布代表训练集,实际分布代表验证集。

特征变量 PSI对 “入模的每个特征变量” 进行分箱,在验证集与训练集 上做 PSI 对比,判断是否发生大的变化。
同样的,PSI 也需要做跨期验证。确保 “评分值、每个特征变量”,在近N个月的验证集上,对比训练集计算出的PSI,在可接受的范围内。
接下来看下模型的应用。
当模型评估合格后,此时我们需要权衡违约率与通过率,确定自动通过阈值。如果阈值在0.2%~0.8%之间则可自动通过阈值,如果在0.8%~3.0%之间则需要人工审核阈值,如果大于3.0%则会直接拒绝。

评分越高,违约率与通过率也是逐步提升,此时我们就需要权衡违约率与通过率,设定阈值来区分样本好坏。

最后我们来看下模型跟踪。
当模型应用后,可能会出现衰退甚至不可用,其原因主要有三:
一是客群变化:模型开发阶段选取的人群,与应用阶段的人群,发生大的偏差。业务在应用的过程中,有可能在某个渠道引入新人群。
二是特征变量的含义或加工逻辑发生变化:入模的特征变量,在某个时间点,技术人员不小心更改了字段的加工逻辑,比如:字段的时间窗口,过滤条件等逻辑变化。
三是社会环境发生变化:同样的客群,在不同时期不同的社会经济环境下,模型的效果表现可能也会不同,比如:新冠疫情、俄乌冲突等社会问题,会导致经济衰退、失业率升高,进而影响客户的还款能力。
而发现模型衰退时,可通过 “评分 PSI” 可以发现问题,但其根本原因是特征变量,模型监控与分析,一定要深入到 “特征变量”,通过 “特征变量 PSI” 找出根本原因 。
模型跟踪也分为PSI 和KS。
PSI 可做月度监控,当月的 “申请样本” 与 “模型训练样本” 进行对比,计算出 “评分PSI” 与 “每个特征变量的PSI”。

同样的,KS 也可做月度监控:收集月度内的 “申请样本” 以及 “违约标签”,计算出 “评分KS” 与 “每个特征变量的IV”。

整体来看,评分卡模型是统计学的创新应用,分箱与WOE编码降低了数据的复杂度,降低了特征的灵敏度,提升了模型的稳定性,同时可进行跨期验证,确保验证模型的长期稳定可靠,并且具备配套的跟踪监控体系,根据评分PSI、参数PSI、评分KS、参数IV快速分析模型衰退的原因。
下期我们业务安全大讲堂将由顶象技术总监杜威为大家带来《业务安全平台核心模块解析——设备指纹》的主题课程,敬请期待!