卷积神经网络识别验证码
活动地址:CSDN21天学习挑战赛
tensorflow零基础入门学习_重邮研究森的博客-CSDN博客_tensorflow 学习 https://blog.csdn.net/m0_60524373/article/details/124143223>- 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw) 中的学习记录博客
https://blog.csdn.net/m0_60524373/article/details/124143223>- 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw) 中的学习记录博客
>- 参考文章地址: [深度学习100例-卷积神经网络(CNN)识别 验证码| 第12天](深度学习100例-卷积神经网络(CNN)识别验证码 | 第12天_K同学啊的博客-CSDN博客)
目录
1.跑通代码
2.代码分析
2.1
2.2
2.3
2.4
2.5
2.6
本文开发环境:tensorflowgpu2.5,pycharm
1.跑通代码
我这个人对于任何代码,我都会先去跑通之和才会去观看内容,哈哈哈,所以第一步我们先不管37=21,直接把博主的代码复制黏贴一份运行结果。(PS:做了一些修改,因为原文是jupyter,而我在pycharm)
1.model文件(用来训练模型)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签#运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#运行配置参数总的轴(axes)正常显示正负号(minus)
import os,PIL,random,pathlib
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
# data_dir = "D:/jupyter notebook/DL-100-days/datasets/captcha"
data_dir ="E:/2021_Project_YanYiXia/AI/21/卷积神经网络识别验证码/dataset/captcha"
data_dir = pathlib.Path(data_dir)
print(data_dir)
all_image_paths = list(data_dir.glob('*'))#获取所有文件,例如WindowsPath('E:/2021_Project_YanYiXia/AI/21/cnn/dataset/captcha/226md.png
all_image_paths = [str(path) for path in all_image_paths]#把文件存入列表
# 打乱数据
random.shuffle(all_image_paths)
# 获取数据标签
all_label_names = [path.split("\\")[7].split(".")[0] for path in all_image_paths]#根据列表中的数据按格式划分
image_count = len(all_image_paths)
print("图片总数为:",image_count)
plt.figure(figsize=(10, 5))
for i in range(20):
plt.subplot(5, 4, i + 1)
plt.xticks([])#不显示横坐标
plt.yticks([])
plt.grid(False)#不显示网格线
# 显示图片
images = plt.imread(all_image_paths[i])
plt.imshow(images)#负责对图像进行处理,并显示其格式
# 显示标签
plt.xlabel(all_label_names[i])
plt.show()#显示图片
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])
#
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
#把之前标签例如 6awcn变为了六个列表,分别是:【0,0,0,0,0,0,1,0.。。。。】,【0,0,0,0,0,0,0,0,0,0,1,0,0.。。】,也就是对应位置的数为1,其他为0
all_labels = [text2vec(i) for i in all_label_names]
#修改图片格式函数
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=1)#输出的image通道是什么什么,channels=1输出灰色图像,3是输出RGB图像
image = tf.image.resize(image, [50, 200])
return image/255.0
#加载图片函数
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
#
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)#创建一个dataset类
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)
#
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))#通过将给定的数据集压缩在一起创建一个“数据集”。
image_label_ds
#
train_ds = image_label_ds.take(1000) # 前1000个batch
val_ds = image_label_ds.skip(1000) # 跳过前1000,选取后面的
print("----")
print(train_ds)
#
BATCH_SIZE = 16
#数据一次性按16进行测试
train_ds = train_ds.batch(BATCH_SIZE)
print(train_ds)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
from tensorflow.keras import datasets, layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)), # 卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(1000, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(label_name_len * char_set_len),
layers.Reshape([label_name_len, char_set_len]),#5x36,5是标签大小,36是0-z
layers.Softmax() # 输出层,输出预期结果
])
# 打印网络结构
model.summary()
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=['accuracy'])
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 保存模型
model.save('model_data/12_model.h5')
2.main文件(用来加载模型,预测结果)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签#运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#运行配置参数总的轴(axes)正常显示正负号(minus)
import os,PIL,random,pathlib
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
# data_dir = "D:/jupyter notebook/DL-100-days/datasets/captcha"
data_dir ="E:/2021_Project_YanYiXia/AI/21/卷积神经网络识别验证码/dataset/captcha"
data_dir = pathlib.Path(data_dir)
print(data_dir)
all_image_paths = list(data_dir.glob('*'))#获取所有文件,例如WindowsPath('E:/2021_Project_YanYiXia/AI/21/cnn/dataset/captcha/226md.png
all_image_paths = [str(path) for path in all_image_paths]#把文件存入列表
# 打乱数据
random.shuffle(all_image_paths)
# 获取数据标签
all_label_names = [path.split("\\")[7].split(".")[0] for path in all_image_paths]#根据列表中的数据按格式划分
image_count = len(all_image_paths)
print("图片总数为:",image_count)
plt.figure(figsize=(10, 5))
for i in range(20):
plt.subplot(5, 4, i + 1)
plt.xticks([])#不显示横坐标
plt.yticks([])
plt.grid(False)#不显示网格线
# 显示图片
images = plt.imread(all_image_paths[i])
plt.imshow(images)#负责对图像进行处理,并显示其格式
# 显示标签
plt.xlabel(all_label_names[i])
plt.show()#显示图片
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])
#
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
#把之前标签例如 6awcn变为了六个列表,分别是:【0,0,0,0,0,0,1,0.。。。。】,【0,0,0,0,0,0,0,0,0,0,1,0,0.。。】,也就是对应位置的数为1,其他为0
all_labels = [text2vec(i) for i in all_label_names]
#修改图片格式函数
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=1)#输出的image通道是什么什么,channels=1输出灰色图像,3是输出RGB图像
image = tf.image.resize(image, [50, 200])
return image/255.0
#加载图片函数
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
#
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)#创建一个dataset类
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)
#
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))#通过将给定的数据集压缩在一起创建一个“数据集”。
image_label_ds
#
train_ds = image_label_ds.take(1000) # 前1000个batch
val_ds = image_label_ds.skip(1000) # 跳过前1000,选取后面的
print("----")
print(train_ds)
#
BATCH_SIZE = 16
#数据一次性按16进行测试
train_ds = train_ds.batch(BATCH_SIZE)
print(train_ds)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
from tensorflow.keras import datasets, layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)), # 卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(1000, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(label_name_len * char_set_len),
layers.Reshape([label_name_len, char_set_len]),#5x36,5是标签大小,36是0-z
layers.Softmax() # 输出层,输出预期结果
])
# 打印网络结构
model.summary()
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=['accuracy'])
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 保存模型
model.save('model_data/12_model.h5')
首先运行model文件,看是否生成了模型,再运行main文件即可运行出最后的预测结果!

2.代码分析
神经网络的整个过程我分为如下六部分,而我们也会对这六部分进行逐部分分析。那么这6部分分别是:
六步法:
1->import
2->train test(指定训练集的输入特征和标签)
3->class MyModel(model) model=Mymodel(搭建网络结构,逐层描述网络)
4->model.compile(选择哪种优化器,损失函数)
5->model.fit(执行训练过程,输入训练集和测试集的特征+标签,batch,迭代次数)
6->验证
2.1
导入:这里很容易理解,也就是导入本次实验内容所需要的各种库。在本案例中主要包括以下部分:
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签#运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#运行配置参数总的轴(axes)正常显示正负号(minus)
import os,PIL,random,pathlib
# 设置随机种子尽可能使结果可以重现
import numpy as np其中包括了GPU设置,绘图中文显示设置等。
对于这里的话我们可以直接复制黏贴,当需要一些其他函数时,只需要添加对应的库文件即可。
2.2
设置训练集和测试集:对于神经网络的训练包括了两种数据集合,一个是训练集,一个是测试集。其中训练集数据较多,测试集较少,因为训练一个模型数据越多相对的模型更准确。
本文中利用的数据集在文章下方,该数据集是一个验证码的灰色图像数据集合
本文中数据集处理较为复杂,包括了随机数,显示图片,数据集设置等,我们将分别对代码进行解释。

如上为随机数种子的设置,神经网络的方法起始我感觉就是扩展变量法,所以为了保证初始情况都一样,因此设置随机数种子。
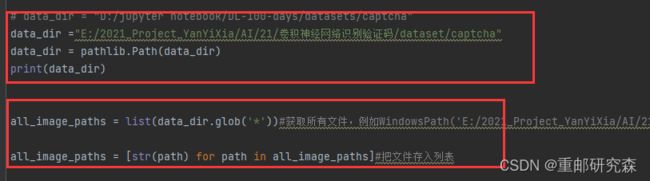
本文数据集和之前数字识别和服装识别利用的minist数据集不一样,是存在与本地文件夹中,因此这里数据集的调用方法也不一样。并且和之前的天气也不一样。
红框1:
这里利用了文件夹函数,首先找到数据集的路径,然后通过函数设置路径文件夹,相当于图中的data_dir就是数据集了
红框2:
这里把文件夹下方所有的图片名字保存之后,再转为字符串形容存入列表中
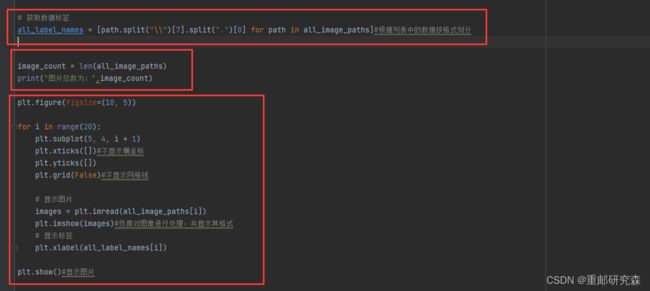
红框1:
这里利用了python的spilt切割函数,在前面我们提到,文件夹名字已经通过字符串形式存入,其格式如下:因此通过对 \\ 进行进行切割,可以得到name.png,再通过一个spilt切开name和png,得到我们的需要的结果,name
红框2:
这里把文件夹下方所有的图片数量进行了输出
红框3:
这里绘制了20个框,把图像与其标签进行了显示,内容如下

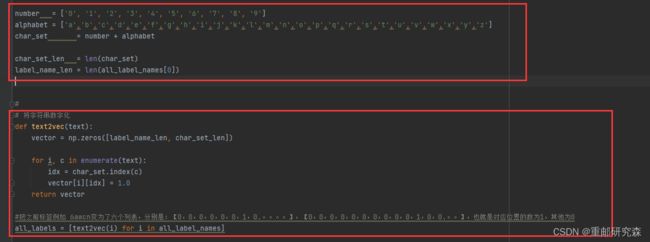
红框1:
由于验证码是数字+字母组合,因此创建了一个大小为10+26=36的列表
红框2:
定义了一个把字符串转为数字的函数,也就是说比如之前是数字1,那么在列表中就是:
【0,1,0,0,0,0,.......】
之前是字母a,那么在列表就是:
【0,0,0,0,0,0,0,0,0,0,1,0,0,0.....】
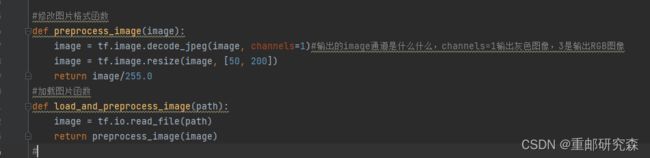
定义了两个函数,也就是数据加载和数据归一化和修改尺寸的函数

重点:!!!
任何数据集构造都是为了这个dataset类的数据。不管是minist这种官方的,或者之前天气识别自建的,都是要制作这个dataset类的结构,我们发现这里的构造方式和之前不一样,很大可能是因为数据保存方法不一样吧,其实我也不太清楚!!!。现在我们来对这部分进行解释。
1.这个是训练加速用的,意义不大
2.这里的all_image_paths包含了整个数据,因为它之前就是文件夹下面的所有东西
3.这里的map调用了加载函数,把之前的图片数据加载了并进行了数据处理(归一化,改尺寸)
4.这里的all_labels就是之前的标签数字列表,也做成了dataset类的结构
5.通过zip把图片和标签形成一对一关系。
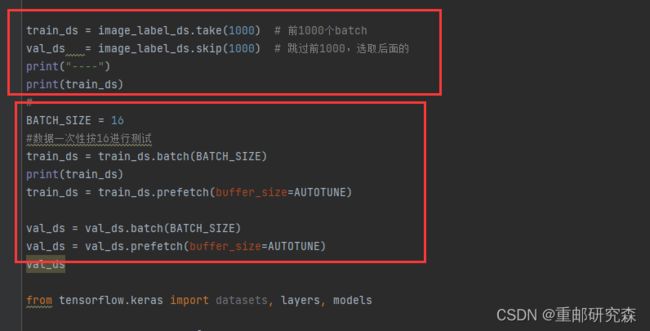
红框1:
把前1000个数据设置为训练集合,后面的为测试集
红框2:
这里的BATCH_SIZE要注意和epoch的区别。具体解释参考下面这个例子。

到这里,数据集的设置就结束了。我们可以发现相对于来说,代码多了很多,而这是因为数据集来源不一样,以及对于数据显示我们多显示了一下。但核心内容还是设置数据集
2.3
网络模型搭建:这里也是神经网络的重点了!废话不多说,直接开始!
本文的神经网络的结构图如下:
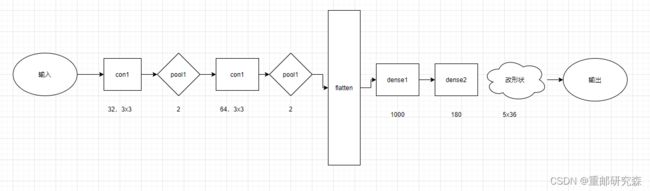
在搭建模型的时候,我们将按照这个图片进行模型的搭建。
卷积层1:32通道,3x3尺寸,步长1的卷积核
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1))注意事项:这里是网络模型的第一层,因此要加上输入
池化层1:该池化层为2x2
layers.MaxPooling2D((2, 2))卷积层2:64通道,3x3尺寸,步长1的卷积核
layers.Conv2D(64, (3, 3), activation='relu')注意事项:这里是网络模型的第一层,因此要加上输入
池化层2:该池化层为2x2
layers.MaxPooling2D((2, 2))重点:
现在我们来分析一下图片中经过每层后数据的维度怎么来的
经过卷积层1之后,原数据50x200x1变为48x198x32,其中1->32是因为通道数50->48是因为(50-3)/stride+1=48.200->198也同理。
经过池化层1之后,48->24,198->99是因为池化核=2,所以数据÷了2.
经过卷积层2之后,数据还是按卷积层1的处理方式变为22x97x64,其中64是因为通道数
经过池化池2之后,数据还是÷2变为11x48x64
经过flatten层之后,数据数量=11*48*64=33792
而后续全连接层的输出是根据全连接层代码设置。需要注意的是因为数据集是5x36类型,因此最后dense为5x36=180
到此,我们便把网络模型设置的原因以及网络模型的输出结果进行了对应,我们可以看到网络模型的输出和我们分析的一致。

到此,网络模型我们变分析完了。
注意事项:我们发现这里的卷积层每一次的引入了激活函数,这是因为输入是彩色图像,引入激活函数可以更好的提取特征,而正是因为提取特征相对较多,我们又引入了防止过拟合。对于越复杂是数据越要引入激活函数,但是激活函数过多容易过拟合
2.4
该部分也同样重要,主要完成模型训练过程中的优化器,损失函数,准确率的设置。
我们结合本文来看。

其中:对于这三个内容的含义可以参考我的文章开头的另外一篇基础博文进行了详细的介绍
2.5
该部分就是执行训练了,那么执行训练肯定需要设置训练集数据及其标签,测试集数据及其标签,训练的epoch

2.6
当训练执行完毕,我们就可以拿一个测试集合中或者其他满足格式的数据进行验证了
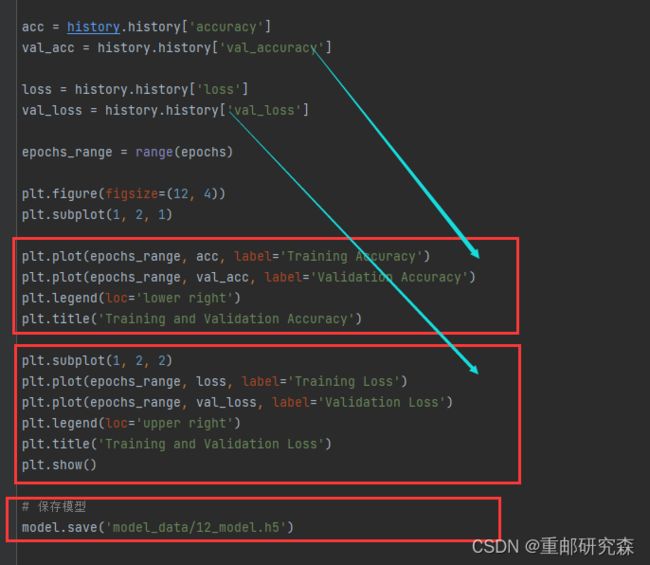
这里就是绘制训练集和测试集的准确率和损失函数图像以及模型保存

对于测试集,我们单独写了文件main,在文章开头代码已经给了,这是因为方便我们测试的时候不用每次都再训练浪费时间。这里代码如下,我们简单解释一下。

红框1:
定义了一个 函数,该函数可以返回该数据且带上序号
2.把val_ds通过take函数拿出一个,最大应该是16,因为之前设置了,取第一组的前6个进行显示,最终结果如下:
