Conditional DETR浅析
文章目录
- 一:创新点
- 二:源码实现
一:创新点
这篇论文首次提出了对content_q和pos_q的解耦运算,为DAB-DETR和DN-DETR打下了基础。
论文主要解决Detr收敛速度慢的原因,故作者首先分析导致其收敛慢的可能原因是啥:encoder只涉及图像特征向量提取;decoder中的self-attn只涉及query之间的交互去重;而最有可能发生在cross attn。原始Detr论文中query=content query + object query,而原始论文发现在第二层layer去掉object query基本不掉点,故收敛慢是content query引起的。

分析原始Detr的交叉注意力计算方式,注意使用的是加法,即cq同时和ck和pk交互容易使得网络产生困惑,故考虑将c和p解耦即可:

作者使用的方法就是解耦:

首先将object query:[N,256]映射成2d的参考点s:[N,2],之后通过下式子来将s映射成和pk一致的sin编码得到Ps。
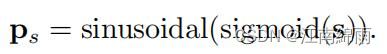
在有了Ps之后,作者考虑到cq中蕴含了物体的边界信息,于是将cq经过FFN得到T,和Ps做了点积,得到Pq。
![]()
然后和经过self-attn的cq拼接送入cross-attn即可。

在最终预测阶段,借助参考点s和预测出偏移量即可。

二:源码实现
所有的流程和传统DETR完全一致,只有以下几个区别:
- 设置了
reference_points,主要是为生成query_sine_embed服务的,同时预测Head的pred是对于reference_points的offset - 对query的解耦
下面我展示一下源码,细节就藏在里面:
首先看一下conditional_detr主模块:
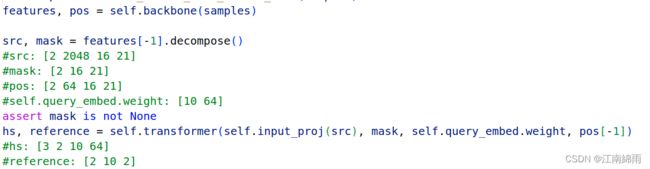
有上图可见,中规中矩,下面主要看一看transformer中的细节:

依然中规中矩,encoder就是几个encoderLayer层利用MultiAttention()进行的基本self-attention,更新src后生成最终的memory,代码如下:

可见,重头戏就在decoder中,下面我们先来看一下源码:


首先利用了query_pos生成了reference_points,然后转换成obj_center的形式,生成query_sine_embed。
同时,考虑到cq中蕴含了物体的边界信息,在每一层decoderLayer中利用更新后的output生成pos_transformation,与query_sine_embed做点积,微调一下query_sine_embed蕴含的边界信息。
注意!!!!每一层的query_sine_embed都是不同的,obj_center是不变的。
下面,来看一看decoderLayer中的源码细节:

对于self-attention,发现依然通过加法进行非解耦运算,只是分别对tgt和query_pos进行了proj投影,分别生成了q_content和q_pos,然后相加传入self_atten = MultiheadAttention(d_model, nhead, dropout=dropout, vdim=d_model)做自注意力机制运算,更新了tgt,接着进入下面的cross-attention。



可见,对于cross-attention,进行了解耦运算。cat了q和query_sine_embed,变为了2*hidden_dim,计算出attention_weight后通过hiddend_dim维的v更新,最终得到tgt并返回 。具体细节见上述源码。
至此,self.transformer()中全部运行结束,返回的是一个output列表和reference_points。对reference_points进行反sigmoid化,得到中心点实际坐标,然后加上pred中bbox的中心点偏移值,得到真正的center坐标。最后再sigmoid一下,得到最后的结果。具体见下图:
