深度学习正则化方法总结
机器学习模型为了提高模型的泛化性能、减少过拟合,通常都会采用一些正则化方法来控制模型的复杂度。深度学习模型比普通的机器学习模型更复杂,更容易过拟合,因此更需要进行正则化处理,本文总结下深度学习常用的14种正则化方法,提供一些参考。
1、对权重参数增加L1、L2正则项


L1正则化主要是对损失函数增加权重参数w的绝对值项,权重服从Laplace分布,得到的参数通常比较稀疏,常用于特征选择。
L2正则化对损失函数增加权重参数w的平方项,权重服从高斯分布,得到的模型参数通常比较小。
2、扩充数据集
通常来说更多的数据训练出来的模型泛化性更好,但是通常训练数据是有限的,需要通过一定的方法来扩充数据集。对于分类问题,通常包含非常多的特征,通过这些特征来推断类别标签,对数据集的变化一般不是很敏感,因此扩充数据集相对更加容易。
扩充数据集效果最好的一个领域是目标识别(图像识别、语音识别),图像通常包含高维特征和大量的形变,实践表明,通过对图像进行旋转变换以及缩放来扩充数据集,图像识别效果得到了比较大的提升。
另一种扩充数据集的方法是对神经网络输入添加随机噪音,实践表明,只要控制噪音添加的幅度,识别效果通常有较大的提升。
3、添加鲁棒性噪音
通过对网络权重添加噪音,常用在RNN网络中,可以被看成是对权重贝叶斯推断的一种随机实现,贝叶斯学习认为权重是不确定的,并且能通过一定的概率分布来反映这种不确定性。
因为大部分的数据集存在一些类别标签误标的情况,因此用这些数据训练出来的模型是有问题的,一种解决方法就是对类别标签添加随机噪音,使标签以一定的概率成立。
4、半监督学习
半监督学习结合了监督学习和无监督学习,无监督学习通常会将样本聚类,相似的样本属于同一个类别,监督学习可以利用无监督学习的聚类结果,例如融合聚类标签作为监督学习的一个新特征来训练监督学习。
5、多任务学习

如上图所示,对于输入x,多任务之间共享一部分权重![]() ,每个任务有一些特定的权重
,每个任务有一些特定的权重![]() 、
、![]() ,最后每个任务会有不同的输出y1,y2。
,最后每个任务会有不同的输出y1,y2。
因为相对单任务训练,共享权重的训练样本是原来的3倍,得到的共享权重泛化能力更强。从深度学习的角度来理解,对于不同任务学习出的模型影响因子中,有很多相同的因子。
6、Early Stopping

如上图所示,一般模型训练过程中,训练集误差会越来越小,验证集误差先变小,后面越来越大,说明模型开始过拟合了。

Early Stopping执行步骤如上图所示:验证集误差减少时会记下模型参数和最后迭代次数,误差增大时会记下次数,当次数超过p时,训练停止,返回记下的模型参数和最后迭代次数。
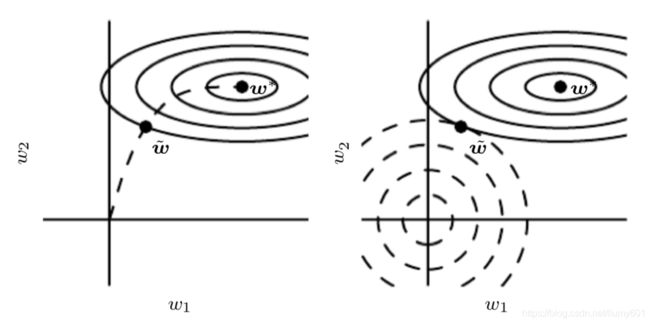
Early Stopping的原理解释:如上图所示,左图为early stopping过程,寻找最优参数w的过程沿着负最大似然方向,不是返回误差最小的点,而是返回附近的点,这跟L2正则化过程类似,不是返回全局最小值点,而是返回跟正则化约束的交点。
7、参数共享
参数共享应用最多的是CNN网络,图像从统计上来说对位置变换不敏感,因此CNN网络通过参数共享来减少参数数量,加快训练速度,从而提高网络大小,并且不需要增加训练样本。
8、稀疏表达
稀疏表达通过对神经网络激活函数输出结果增加惩罚项,使激活输出更加稀疏(大部分为0),通过这种方式来对模型参数间接地增加惩罚项。
常用的稀疏化方法包括L1正则化、t分布先验、KL散度惩罚等。
9、集成学习
Bagging通过融合多种模型,能够减少模型方差,从而减小泛化误差。首先需要对数据集进行有返回采样,生成k份训练样本,然后训练k个模型,最后对k个预测结果进行投票或者取平均值。
10、Dropout
Dropout是模型正则化的一种比较高效的方法,通过以一定概率删除神经网络输入层、隐含层单元,从而生成大量具有不同结构的神经网络集成模型。
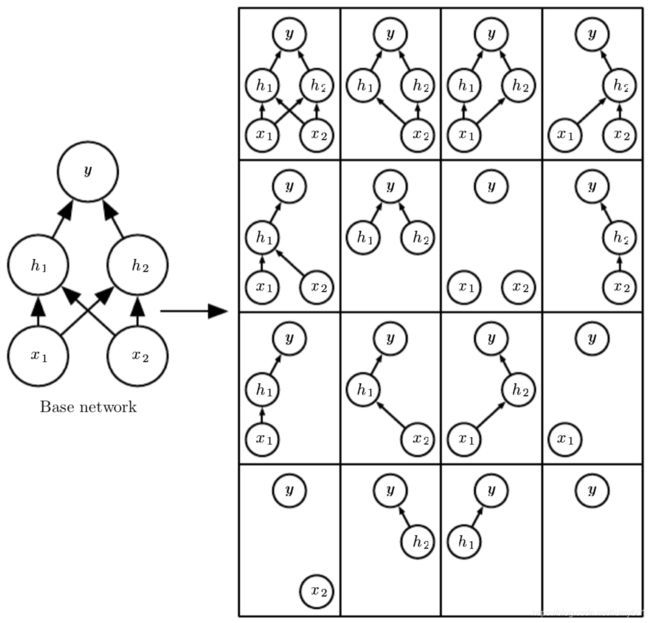
如上图所示,左图为一个包含2个输入单元、2个隐含单元、1个输出单元的神经网络,右图包含了对2个输入单元、2个隐含单元以一定概率删除后的16个神经网络。