深度学习模型压缩与加速技术(六):知识蒸馏
目录
-
-
- 总结
- 知识蒸馏
-
- 定义
- 特点
- 1.学生模型的网络架构
- 2.教师模型的学习信息
- 训练技巧
- 其他场景
- 参考文献
-
深度学习模型的压缩和加速是指利用神经网络参数的冗余性和网络结构的冗余性精简模型,在不影响任务完成度的情况下,得到参数量更少、结构更精简的模型。被压缩后的模型计算资源需求和内存需求更小,相比原始模型能够满足更加广泛的应用需求。在深度学习技术日益火爆的背景下,对深度学习模型强烈的应用需求使得人们对内存占用少、计算资源要求低、同时依旧保证相当高的正确率的“小模型”格外关注。利用神经网络的冗余性进行深度学习的模型压缩和加速引起了学术界和工业界的广泛兴趣,各种工作也层出不穷。
本文参考2021发表在软件学报上的《深度学习模型压缩与加速综述》进行了总结和学习。
相关链接:
深度学习模型压缩与加速技术(一):参数剪枝
深度学习模型压缩与加速技术(二):参数量化
深度学习模型压缩与加速技术(三):低秩分解
深度学习模型压缩与加速技术(四):参数共享
深度学习模型压缩与加速技术(五):紧凑网络
深度学习模型压缩与加速技术(六):知识蒸馏
深度学习模型压缩与加速技术(七):混合方式
总结
| 模型压缩与加速技术 | 描述 |
|---|---|
| 参数剪枝(A) | 设计关于参数重要性的评价准则,基于该准则判断网络参数的重要程度,删除冗余参数 |
| 参数量化(A) | 将网络参数从 32 位全精度浮点数量化到更低位数 |
| 低秩分解(A) | 将高维参数向量降维分解为稀疏的低维向量 |
| 参数共享(A) | 利用结构化矩阵或聚类方法映射网络内部参数 |
| 紧凑网络(B) | 从卷积核、特殊层和网络结构3个级别设计新型轻量网络 |
| 知识蒸馏(B) | 将较大的教师模型的信息提炼到较小的学生模型 |
| 混合方式(A+B) | 前几种方法的结合 |
A:压缩参数 B:压缩结构
知识蒸馏
定义
知识蒸馏最早由 Buciluǎ 等人[146]提出,用以训练带有伪数据标记的强分类器的压缩模型和复制原始分类器的输出。与其他压缩与加速方法只使用需要被压缩的目标网络不同。知识蒸馏法需要两种类型的网络:教师模型和学生模型
特点
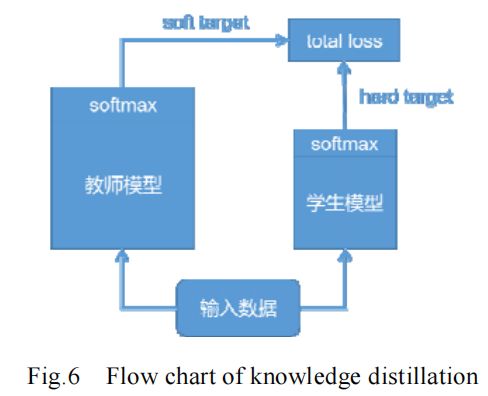
预先训练好的教师模型通常是一个大型的神经网络模型,具有很好的性能。如图 6 所示,将教师模型的 softmax 层输出作为 soft target 与学生模型的 softmax 层输出作为 hard target 一同送入 total loss 计算,指导学生模型训练,将教师模型的知识迁移到学生模型中,使学生模型达到与教师模型相当的性能。学生模型更加紧凑高效,起到模型压缩的目的。知识蒸馏法可使深层网络变浅,极大地降低了计算成本,但也存在其局限性。由于使用 softmax 层输出作为知识,所以一般多用于具有 softmax 损失函数的分类任务,在其他任务的泛化性不好;并且就目前来看,其压缩比与蒸馏后的模型性能还存在较大的进步空间。
1.学生模型的网络架构
知识蒸馏法的研究方向之一就是如何为学生模型选择合适的网络结构,帮助学生模型更好地学习教师模型的知识。
- Ba 等人[147]提出:在保证教师模型和学生模型网络参数数量相同的情况下,设计更浅的学生模型,每一层变得更宽。
- Romero 等人[148]与文献[147]的观点不同,他们认为更深的学生模型分类效果更好,提出Fitnets 使用教师网络的中间层输出 Hints,作为监督信息训练学生网络的前半部分。
- Chen 等人[149]提出使用生长式网络结构,以复制的方式重用预训练的网络参数,在此基础上进行结构拓展
- Li 等人[150]与文献[149]观点一致,提出分别从宽度和深度上进行网络生长。
- Crowley 等人[151]提出将知识蒸馏与设计更紧凑的网络结构相结合,将原网络作为教师模型,将使用简化卷积的网络作为学生模型。
- Zhu 等人[152]提出基于原始网络构造多分支结构,将每个分支作为学生网络,融合生成推理性能更强的教师网络。
2.教师模型的学习信息
除了使用 softmax层输出作为教师模型的学习信息以外,有研究者认为,可以使用教师模型中的其他信息帮助知识迁移。
- Hinton 等人[153]首先提出使用教师模型的类别概率输出计算 soft target,为了方便计算,还引入温度参数。
- Yim 等人[154]将教师模型网络层之间的数据流信息作为学习信息,定义为两层特征的内积。
- Chen 等人[155]将教师模型在某一类的不同样本间的排序关系作为学习信息传递给学生模型。
训练技巧
- Czarnecki 等人[156]提出了Sobolev 训练方法,将目标函数的导数融入到神经网络函数逼近器的训练中。
- 当训练数据由于隐私等问题对于学生模型不可用时,Lopes 等人[157]提出了如何通过 extra metadata 来加以解决的方法。
- Zhou 等人[158]的工作主要有两个创新点:第一,不用预训练教师模型,而是教师模型和学生模型同时训练;第二,教师模型和学生模型共享网络参数。
其他场景
- 由于 softmax 层的限制,知识蒸馏法被局限于分类任务的使用场景。但近年来,研究人员提出多种策略使其能够应用于其他深度学习场景。
- 在目标检测任务中,Li 等人[159]提出了匹配 proposal 的方法,Chen 等人[160]结合使用文献[148,153]提出的方法,提升多分类目标检测网络的性能。
- 在解决人脸检测任务时,Luo 等人[161]提出将更高隐层的神经元作为学习知识,其与类别输出概率信息量相同,但更为紧凑。Gupta 等人[162]提出了跨模态迁移知识的做法,将在 RGB 数据集学习到的知识迁移到深度学习的场景中。Xu 等人[163]提出一种多任务指导预测和蒸馏网络(PAD-net)结构,产生一组中间辅助任务,为学习目标任务提供丰富的多模态数据。
参考文献
主要参考:高晗,田育龙,许封元,仲盛.深度学习模型压缩与加速综述[J].软件学报,2021,32(01):68-92.DOI:10.13328/j.cnki.jos.006096.
[146] Buciluǎ C, Caruana R, Niculescu-Mizil A. Model compression. In: Proc. of the 12th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. 2006. 535541.
[147] Ba J, Caruana R. Do deep nets really need to be deep? In: Advances in Neural Information Processing Systems. 2014. 26542662.
[148] Romero A, Ballas N, Kahou SE, et al. Fitnets: Hints for thin deep nets. arXiv Preprint arXiv: 1412.6550, 2014.
[149] Chen T, Goodfellow I, Shlens J. Net2net: Accelerating learning via knowledge transfer. arXiv Preprint arXiv: 1511.05641, 2015.
[150] Li Z, Hoiem D. Learning without forgetting. IEEE Trans. on Pattern Analysis And Machine Intelligence, 2017,40(12):29352947.
[151] Crowley EJ, Gray G, Storkey AJ. Moonshine: Distilling with cheap convolutions. In: Advances in Neural Information Processing Systems. 2018. 28882898.
[152] Zhu X, Gong S. Knowledge distillation by on-the-fly native ensemble. In: Advances in Neural Information Processing Systems. \2018. 75177527.
[153] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv Preprint arXiv: 1503.02531, 2015.
[154] Yim J, Joo D, Bae J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2017. 41334141.
[155] Chen Y, Wang N, Zhang Z. Darkrank: Accelerating deep metric learning via cross sample similarities transfer. In: Proc. of the 32nd AAAI Conf. on Artificial Intelligence. 2018.
[156] Czarnecki WM, Osindero S, Jaderberg M, et al. Sobolev training for neural networks. In: Advances in Neural Information Processing Systems. 2017. 42784287.
[157] Lopes RG, Fenu S, Starner T. Data-free knowledge distillation for deep neural networks. arXiv Preprint arXiv: 1710.07535, 2017.
[158] Zhou G, Fan Y, Cui R, et al. Rocket launching: A universal and efficient framework for training well-performing light net. In: Proc. of the 32nd AAAI Conf. on Artificial Intelligence. 2018.
[159] Li Q, Jin S, Yan J. Mimicking very efficient network for object detection. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2017. 63566364.
[160] Chen G, Choi W, Yu X, et al. Learning efficient object detection models with knowledge distillation. In: Advances in Neural Information Processing Systems. 2017. 742751.
[161] Luo P, Zhu Z, Liu Z, et al. Face model compression by distilling knowledge from neurons. In: Proc. of the 30th AAAI Conf. on Artificial Intelligence. 2016.
[162] Gupta S, Hoffman J, Malik J. Cross modal distillation for supervision transfer. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2016. 28272836.
[163] Xu D, Ouyang W, Wang X, et al. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. 2018. 675684.