【模型压缩】(四)——知识蒸馏
一、概述
一句话概括:将一个复杂模型的预测能力转移到一个较小的网络上;
(复杂模型称为教师模型,较小模型称为学生模型)
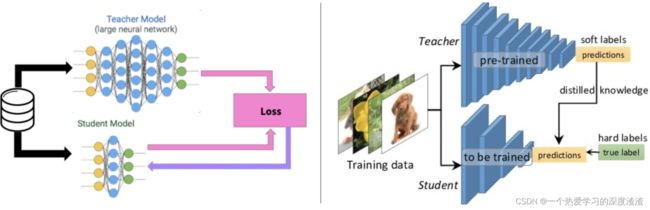
Teacher and Student的概念:
- 对大网络学习的知识进行"蒸馏",并将其转移到小网络上,同时小网络的性能能够接近大网络;
- 蒸馏模型(Student)被训练模仿大网络(Teacher)的输出,而不仅仅是直接在原始数据上训练,通过这种方式让小网络学习到大网络的抽象特征能力和泛化能力;

二、流程详解
方法一
简单流程如下:
1、数据集上训练一个teacher网络;
2、训练一个student网络"模仿"teacher网络;
3、让小网络模拟大网络的logits(后续讲解);
优点:Teacher可以帮助过滤一些噪声标签,对于Student来说,学习一个连续值比0、1标签的学习效率更高,学到的信息量更大;
logits是指什么?
利用大模型生成的概率作为小模型的"soft target",可以将大模型的泛化能力转移到小模型,在这个迁移阶段可以使用相同的训练集或单独的数据集来训练大模型;
当soft target熵很高的时候,训练时能够比hard targets提供更多的信息和更少的梯度方差,所以小模型通常可以使用更少的训练样本和更大的学习率;
注意:这里的soft target表示具体的概率值,通常将0、1值的输出称为hard target;
下面看一张训练过程图:
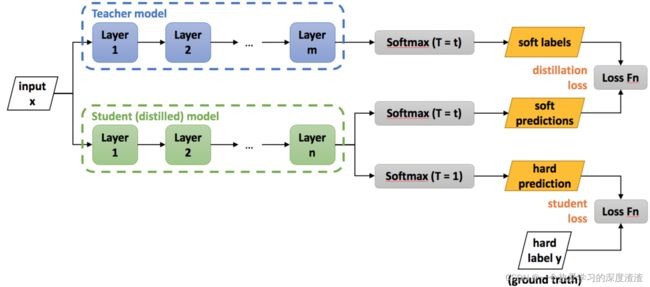
说明:
1、teacher网络的输出作为student网络的soft label,也就是软标签,输出的值是连续值;
2、student网络的输出有两个分支,一个为soft predictions,一个为hard predictions,其中hard表示硬标签的意思,输出的值为one-hot形式;
3、最终的Loss为student网络的输出分别与teacher网络的soft labels、实际的hard labels计算损失值,最终将二者的Loss值进行结合;
关于softmax的一个trick:
针对知识蒸馏这个任务,对于softmax输出函数公式进行改进;

说明:增加了一个权重T变量,当T较大时,所有类别的概率几乎相同,概率会更加soft,当T较小时,具有最高期望奖励的类别概率趋近于1;在蒸馏的过程中,提高T的值直到teacher模型产生合适的soft target集合,然后在训练student模型时使用相同的T值匹配这些soft target;
下图是一个实际的例子:

方法二
FitNets:
原理:student使用来自teacher的中间隐藏层信息,来得到更好的表现能力;
FitNets是一种student网络,比teacher网络更窄但更深,在student网络中加入"引导层",也就是从teacher网络中的一个隐层学习;
下面看看实验的效果:

三、现状分析
1、知识蒸馏的研究在某些领域已经变得广泛和专一,以至于很难对一个方法的泛化性能进行评估;
2、与其他模型压缩技术不同,蒸馏不需要与原始网络具有相似的结构,也意味着知识的提炼是非常灵活的,理论上可以适应广泛的任务;
优缺点分析:
优点:如果有一个训练好的teacher网络,训练较小的student网络所需要的训练数据就更少,并且网络越少速度越快;Teacher和Student网络之间也不需要保持结构统一;
缺点:如果没有预先训练好的teacher网络,需要更大的数据集和更多的时间来进行蒸馏;
四、代码案例
首先我们先计算下数据集的均值和方差,这也是Normal中经常用到的值;
代码案例:
def get_mean_and_std(dataset):
"""计算数据集(训练集)的均值和标准差"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=2)
# 创建两个矩阵保存均值和标准差
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for inputs, targets in dataloader:
# 这里要注意是三个通道,所以要遍历三次
for i in range(3):
mean[i] += inputs[:, i, :, :].mean()
std[i] += inputs[:, i, :, :].std()
# 最后用得到的总和除以数据集数量即可
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std
下面讲解知识蒸馏的简单案例;
背景:
teacher模型:VGG16;
student模型:自定义模型,相比于VGG16减少了一些层;
数据集:cifar10数据集;
蒸馏过程中加载两个模型的步骤就不在这展示了,具体在于损失函数的定义:
# 默认交叉熵损失
def _make_criterion(alpha=0.5, T=4.0, mode='cse'):
# targets为teacher网络的输出,labels为student网络的输出
def criterion(outputs, targets, labels):
# 根据传入模式用不同的损失函数
if mode == 'cse':
_p = F.log_softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = -torch.mean(torch.sum(_q * _p, dim=1))
elif mode == 'mse':
_p = F.softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = nn.MSELoss()(_p, _q) / 2
else:
raise NotImplementedError()
# 还原原始的soft_loss
_soft_loss = _soft_loss * T * T
# 用softmax交叉熵计算hard的loss值
_hard_loss = F.cross_entropy(outputs, labels)
# 将soft的loss值和hard的loss值加权相加
loss = alpha * _soft_loss + (1. - alpha) * _hard_loss
return loss
return criterion
上述代码就是知识蒸馏中最重要的部分,
五、拓展
可参考近些年来知识蒸馏的总结论文:论文
总结
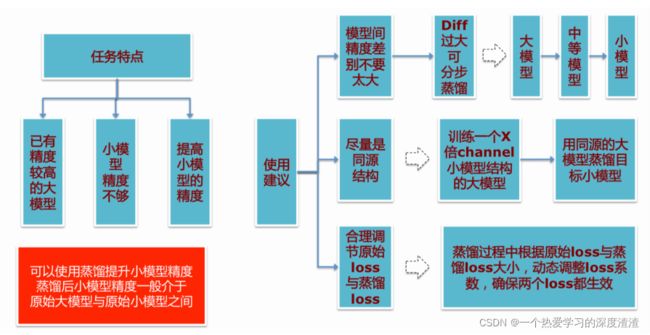
使用知识蒸馏的一些建议: