高性能自动化协同设计平台在工业制造业中的应用
在工业制造业、天气预测、生命科学计算、高能物理数据分析等科研领域,问题的求解往往依赖复杂的计算和大量数据的分析。而随着问题的规模和复杂性的递增,这些计算可能包含数以千计的步骤,逻辑流程也越来越复杂,应用程序和数据可能还分布在不同的计算环境中。整合和管理如此复杂的分布式计算面临着诸多挑战。
大多数的端到端的分析或业务流程涉及多个时序要求严格的步骤和工具:
- 工程分析
- 财务报告
- 设备验证
- 数字呈现
- 商业智能
随着高性能计算的发展,工作流程的自动化已成为核心:
- 作业需要在正确的时间以正确的顺序运行
- 关键任务流程运行失败的零容忍
- 在机器之间有相互依赖关系的步骤
- 不可能手动地有效地处理
- 依赖外部的、分布式的事件
- 很难诊断操作失败的原因
- 资源分散、极少的可视化过程
- 累加的、多样化和非结构化的数据集
以某赛车设计为例,原始的赛车设计的工作流是用简单的成千上万行代码的perl脚写的,基本上只有设计者本人知道它是如何工作的,随着这个员工离职或者其他的变故,公司业务会受到很大的影响。同样的,修改脚本也是令人惊恐的,因为即便是简单的一行代码的改动也很难搞清楚会引起什么样的问题。
如果把赛车的设计流程模块化,也就是把整个的设计流程分解成关键模块和一些子流程,由成千上万的步骤和子流程来展现关键的制造流程。用户可以摆脱潜在的复杂性,使复杂过程简单化,提高生产力和减少培训和支持的必要性。
从产品战略设计-〉参数化建模(Pro/E)-〉网格化分(ICEM)–〉计算(Fluent)-〉优化。不同阶段和工具,有不同的数据格式。这是一个PLM(产品生命周期管理)的概念。

整个流程是在训练模型数据的精确性,Pro/E的模型文件(比如车轮)是基于参数建模的,以车轮设计为例,它所能接受的就是你给它的参数文件,可以按照“原始值”、“输入值”和“外部参数文件的方式产生再生效果。通过调用外部参数文件来产生再生效果,这就简化了工作流程。
当运行一个工作流的时候,你不需要知道任何一个第三方软件,比如Pro/E、Ansys ICEM、Fluent、Nastran等等是如何工作的,这些软件对你来说是透明的,从而极大地缩短了培训时间,你不需要访问其中的关键制造流程,业务不会随着员工的离开受到影响,也不必担心核心技术和产品信息泄露,知识产权得以保障。通过对多个工具软件的集成,实现产品设计优化流程跨平台、分布式执行。
IBM Platform Process Manager简介
IBM Platform Process Manager(简称PPM)是一款工作负载管理工具,用户可以在分布式计算环境中自动化工作流程,帮助用户设计、运行并管理计算密集型业务的关键的HPC工作流。
用户在轻松地设计和自动化计算分析过程的同时捕捉和保护可重复的最佳实践。用一个直观的图形化界面来记录工作流步骤和依赖关系,还可以利用IBM Process Manager进行作业调度。图形化的界面简单友好,用户无需一些脚本的编码能力,就可以很容易地设计工作流程,从而大大提高了工作效率,减少运行时间,提高整个流程的可靠性。使用户的业务处理更加灵活敏捷。IBM的工作流管理软件Platform Process Manager使用户能够在共享的、分布式的计算环境中运行和管理关键业务的工作流,实现提高效率、缩短运行时间、改善可靠性的目标。
- 摒弃令人乏味的手工操作步骤,无需复杂的编程知识,设计人员可以利用图形界面来快速设计和部署复杂的业务流程。工作流的运行状态也以可视化的方式呈现给用户,运行结果更加直观。
- 通过自定义各个任务之间的依赖关系,以及基于用户自定义变量的条件逻辑,方便地描述任意复杂的业务流程。基于时间和事件的调度系统,使得工作流和任务的触发、运行更加灵活。
- 提供基于各种不同的异常和事件的通知,以及先进的异常处理逻辑,确保无需人工干预,保证计算任务能够按照计划完成,业务流程更加可靠。
- 整个工作流可以被封装成一个计算步骤,嵌入其他的工作流,描述更加复杂的业务逻辑。提高可重用性,更易于工作流的扩展和维护。
- 用户可以将Platform Process Manager和Platform Application Center结合使用,在任意的设备上通过浏览器监控工作流的运行。
复杂的工作流可以被视为一个“黑盒子”。用户不需要知道细节,只对输入和输出感兴趣!
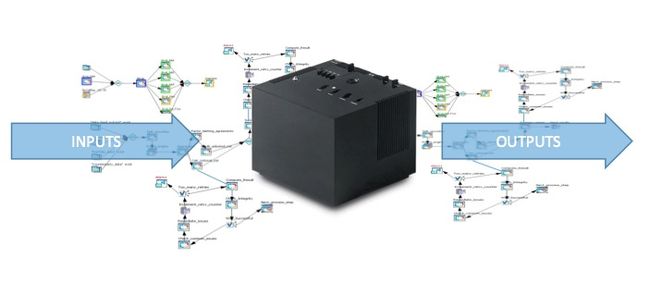
工作流隐藏在用户定制的提交表单中 - 选择哪个版本的机翼、底盘、悬浮等;选择底盘的高度、发动机、油箱、轨道和天气条件以及大气压强等等。工作流会对任何一个部位进行网格划分。以车轮设计为例:
- 按轮辐结构:可分为辐板式车轮和辐条式车轮
- 按车轮材质:可分为钢制、铝合金、镁合金等车轮
- 按车轴一端安装一个或两个轮胎:可分为单式车轮和双式车轮
PPM应用实例
通过在工作流中的输入变量实现车轮设计的自动灵活性,选择什么样的轮辐、什么材质的车轮?
PPM支持动态的子工作流和动态的工作流集合,用户可以重用和共享工作流集合。一个动态的子工作流或者工作流集合可以引用一个已经发布的目标工作流,当用户修改这个目标工作流定义的时候,所引用它的子工作流和工作流集合可以获得所引用的目标工作流的最新版本加以引用。其中一个重要的方面就是输入变量。使用输入变量来定义一个清晰的允许参数化运行的工作流的界面。
下面描述一下动态子工作流结合输入变量的使用。同样的适用于动态的工作流集合。
动态的子工作流和输入变量的使用类似于编程语言中的函数(见图1)。
| 动态的子工作流 | 函数 |
|---|---|
| 提交并发布一个目标工作流 | 定义一个函数 |
| 在主工作流中包含一个动态的子工作流 | 函数调用 |
| 输入变量 | 输入参数 |
| 对动态的子工作流指定输入变量值 | 使用输入参数来调用一个函数 |
通过动态的子工作流和输入变量,用户可以实现真正的工作流的重用,可以在工作流定义中轻松转化脚本。
使用动态的子工作流和输入变量的步骤
1.定义一个目标数据流和声明输入变量
假设你有一个工作流A,它会被其它的工作流共享和重用(这个数据流就称之为目标工作流)。定义一个目标工作流的时候,你要指定这个工作流的输入变量,在工作流运行的时候会给这些用户变量赋值,就像编程语言中的函数中的形参。你可以在工作流属性对话窗中声明输入变量。在Genernal标签页,在输入变量字段(Input Variables)输入变量。你可以选择性地对任何一个输入变量指定一个默认值。
例如,在工作流A中,你使用许多内部的用户变量,但是在工作流A的界面,你只需给两个用户变量myvar1和myvar2赋值,所以可以声明myvar1和myvar2作为工作流A的输入变量 (见图2)。

提交这个目标数据流A到PPM服务器以后,确保PPM管理员把它发布了以备重用。
2.包含一个动态的子数据流和指定输入变量值
现在你可以在其它的工作流中重用目标工作流A。例如,你有一个工作流B,你想运行工作流A两次对myvar1和myvar2分别用不同的变量值.你可以在工作流B中加两个动态的子工作流dsf1和dsf2在数据流B中作为两个步骤(见图3)。当数据流B运行到步骤dsf1和dsf2的时候,它们会分别展开到数据A的定义中, 并且以指定的myvar1和myvar2值运行。

指定工作流A,嵌入dsf1和dsf2, 并且视情况而定给dsf1和dsf2指定不同的输入变量值 。图4显示了动态子工作流dsf1的定义, 带有myvar1=200, myvar2=left

当定义工作流B的时候不知道输入变量的值,只能在运行的时候获得,那么你可以选择在定义动态子工作流的时候不指定值。可以在dsf1前加一个作业J1去给#{myvar1} 和#{myvar2}计算分配值。或者,可以在指定输入变量值的时候使用用户变量。例如,对dsf1, 指定myvar1=#{varA}, 对dsf2, 指定myvar1=#{varB}。那么可以用作业在运行的时候去给varA和varB分配值。这样就避免了多于一个的动态子工作流引用同一个目标工作流,并且需要输入变量值的时候名字冲突问题(见图5)。

在动态的子工作流dsf1, 给输入变量myvar1赋一个变量值#{varA}, 通过作业J1在运行的时候给#{varA}赋值。在这个例子中,dsf1 会以myvar1=300,myvar2=left来运行。dsf2一样,myvar1赋一个变量值#{varB}, dsf2会以myvar1=100,myvar2=right来运行。
输入变量和环境变量
另外,输入变量也常用来给工作流和它的作业指定环境变量。可以通过操作系统的环境变量来直接访问输入变量(例如,myvar2)。普通用户变量不能声明用作输入变量,它只能通过用户变量语法(例如,#{varA})在作业定义的命令行中使用。如果你的作业运行一个脚本,在这个脚本里你可以直接使用$myvar1(因为它被作为一个操作系统的环境变量来提供给用户使用),但是不能用#{varA}。在作业定义中,#{varA}可以用于命令行或其它支持变量的字段。
结束语
在工业制造业,大多数HPC应用程序的核心要求是自动化数据移动和重复的过程等, 无论是需要更灵活的方法来简化业务流程的脚本编写工作,还是想要减轻管理负担并确保按时完成关键任务,一个自动化设计与制造平台是非常有帮助的,通过对多个工具软件的集成,实现产品设计优化流程跨平台、分布式执行。
作者:高扬([email protected]), 2005年7月毕业于西安交通大学,硕士研究生,2006年1月加入IBM至今,主要从事高性能计算环境下的自动化工作流管理的研发工作。
责编:周建丁([email protected])