Hadoop(四)—— Hadoop运行模式
文章目录
- 一、前言
- 二、完全分布式运行模式
-
- 1.编写集群分发脚本xsync
-
-
- 1)用scp命令将102上的jdk和hadoop拷贝到103和104上去
- 2)这里还有一个问题就是,我的jdk放在/usr下面,为了统一起来,我还是把jdk搬回/opt/module下面吧(如果你的JDK配置好了,请跳过这一堆跟JDK有关的内容)
- 3)拷贝
- 4)rsync命令
- 5) xsync命令
-
一、前言
1.支持2000多个服务器结点,目前最多可支持4000~5000个结点
2.Hadoop官网网址 http://hadoop.apache.org/
3. hadoop有三种运行模式
- 本地模式:单机运行,只是用来演示一下官方案例。
生产环境不用 - 伪分布模式:单机运行,具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。
个别缺钱的公司用来测试,生产环境不用。 - 完全分布式模式!(五颗星):多台服务器组成分布式环境。
生产环境使用。
企业中用的都是完全分布式模式,所以只学习完全分布式模式就可以了
二、完全分布式运行模式
要完成下面的工作,其中前5个已经在hadoop102做过了,下面只需要将102上的拷贝到103和104上去,然后再进行 6,7,8,9 步
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
1.编写集群分发脚本xsync
1)用scp命令将102上的jdk和hadoop拷贝到103和104上去
前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、 /opt/software两个目录,并且已经把这两个目录修改为cj:cj
[cj@hadoop102 ~]$ sudo chown cj:cj -R /opt/module
2)这里还有一个问题就是,我的jdk放在/usr下面,为了统一起来,我还是把jdk搬回/opt/module下面吧(如果你的JDK配置好了,请跳过这一堆跟JDK有关的内容)
mv /usr/jdk1.8.0_311/ /opt/module/jdk1.8.0_311
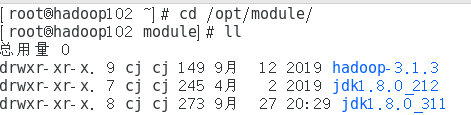
对应的环境变量也要改,因为发现之前在这里
配置的PATH好像不太对(HOME写成了HOMR,但是也没影响什么),所以我决定删掉以前写的环境变量,重新配置一次。
然后我决定还是跟教程用一样版本的JDK,所以下面配置jdk1.8.0_212的环境变量
① 新建/etc/profile.d/my_env.sh文件
$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
②保存后退出
:wq
③source一下/etc/profile文件,让新的环境变量PATH生效
$ source /etc/profile
然后再次运行elasticsearch的时候,报错了。。
Exception in thread "main" SettingsException[Failed to load settings from /usr/local/elasticsearch/config/elasticsearch.yml]; nested: AccessDeniedException[/usr/local/elasticsearch/config/elasticsearch.yml];
at org.elasticsearch.node.InternalSettingsPreparer.prepareEnvironment(InternalSettingsPreparer.java:74)
at org.elasticsearch.cli.EnvironmentAwareCommand.createEnv(EnvironmentAwareCommand.java:89)
at org.elasticsearch.cli.EnvironmentAwareCommand.createEnv(EnvironmentAwareCommand.java:80)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:114)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:95)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:114)
at org.elasticsearch.cli.Command.main(Command.java:79)
at org.elasticsearch.common.settings.KeyStoreCli.main(KeyStoreCli.java:32)
Caused by: java.nio.file.AccessDeniedException: /usr/local/elasticsearch/config/elasticsearch.yml
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214)
at java.nio.file.Files.newByteChannel(Files.java:361)
at java.nio.file.Files.newByteChannel(Files.java:407)
at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:384)
at java.nio.file.Files.newInputStream(Files.java:152)
at org.elasticsearch.common.settings.Settings$Builder.loadFromPath(Settings.java:1082)
at org.elasticsearch.node.InternalSettingsPreparer.prepareEnvironment(InternalSettingsPreparer.java:72)
... 8 more
Exception in thread "main" java.nio.file.AccessDeniedException: /usr/local/elasticsearch/config/jvm.options.d
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixFileSystemProvider.newDirectoryStream(UnixFileSystemProvider.java:427)
at java.nio.file.Files.newDirectoryStream(Files.java:525)
at org.elasticsearch.tools.launchers.JvmOptionsParser.readJvmOptionsFiles(JvmOptionsParser.java:157)
at org.elasticsearch.tools.launchers.JvmOptionsParser.jvmOptions(JvmOptionsParser.java:124)
at org.elasticsearch.tools.launchers.JvmOptionsParser.main(JvmOptionsParser.java:86)
根据提示“AccessDeniedException”,应该是权限不够的问题,不要用root去运行,要切换回elk运行。
测试了一下,成功了,所以JDK配置成功。
既然102这样改了JDK,所以103和104都要和上面一样改一下。
3)拷贝
[cj@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 cj@hadoop103:/opt/module
[cj@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 cj@hadoop104:/opt/module
[cj@hadoop102 ~]$ scp -r /opt/module/hadoop-3.1.3 cj@hadoop103:/opt/module
[cj@hadoop102 ~]$ scp -r /opt/module/hadoop-3.1.3 cj@hadoop104:/opt/module
拷贝的时候要求两个服务器都开着,但是我的电脑内存崩了,所以还是手动给103和104安装的JDK和Hadoop以及配置环境变量。无语
4)rsync命令
如果后续对102进行了更改,想要同步到103和104上去的话,用下面的命令
rsync -av /opt/module/hadoop-3.1.3/ cj@hadoop103:/opt/module/hadoop-3.1.3/
5) xsync命令
写一个Linux脚本,修改rsync的功能,产生新命令xsync,用法
xsync a.txt
作用:把102中的a.txt分发到103,104的相同目录下。
需要脚本放在声明了全局环境变量的路径下,所以首先查看PATH
$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/cj/.local/bin:/home/cj/bin:/opt/module/jdk1.8.0_212/bin
就用这个吧“/home/cj/bin”
在/home/cj/bin目录下创建xsync文件
[@hadoop102 opt]$ cd /home/cj
[@hadoop102 ~]$ mkdir bin
[@hadoop102 ~]$ cd bin
[@hadoop102 bin]$ vim xsync
写入一下脚本,保存退出
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本 xsync 具有执行权限
@hadoop102 bin]$ chmod +x xsync
测试脚本(因为我无法同时开启两台虚拟机,所以xsync这个命令对我来说不适用,也没法测试)
@hadoop102 ~]$ xsync /home/cj/bin
注意:如果用了sudo,那么xsync一定要给它的路径补全。
将脚本复制到/bin中,以便全局调用
@hadoop102 bin]$ sudo cp xsync /bin/