腾讯云云原生数据湖DLC重磅推出免运维、零成本、高性能spark shuffle manager
导语
腾讯云云原生数据湖产品DLC,作为腾讯云上第一款全托管的云原生湖产品,让用户不再需要关心其底层资源配置、部署、适应性调试等繁重的集群运维问题,而是用户可按需配置集群特性使用。在DLC计算内核中我们对spark shuffle进行深度定制来满足云场景下存算分离、免运维低成本、高稳定性且兼顾性能的特点。相比目前业内方案,具有不需要额外服务部署、低运营成本、高稳定性且兼顾性能等特点。
背景介绍
在DLC高性能、低成本、免运维的需求场景下,以往大数据计算框架中share-nothing架构模式将不再适用。首先云上计算集群在常规场景需求下能根据集群规模通常会分配有限的磁盘空间。其次对象存储系统相比传统分布式文件系统也展现出了巨大的成本优势。怎么设计和实现DLC的计算内核以使其既能在常规情况使用其本地磁盘,同时又能在数据量突增或数据倾斜等场景下支撑其稳定性的低成本方案DLC湖仓平台面对的一个的挑战。
一方面原生spark采用share-nothing架构对于本地磁盘非常依赖,包括shuffle、broadcast、rdd persist等操作都需要使用本地磁盘;另一方面用户运行的任务数据量和类型多种多样、提前预估难度高且很难长期使用,例如用户运行etl任务因数据量增长等导致的资源调整在之前需要很痛苦的调整经历;这里一个关键算子shuffle,它消耗了集群大概30%的计算资源,且使用的本地存储资源变化很大且运行时iops负载很高,是能否实现DLC存算分离、低成本、提高稳定性的关键因素。
业内方案参考
目前业界的主流shuffle实现方案参考:

Magnet
LinkedIn Magnet(2021)融合了本地Shuffle+ Push to External Shuffle,以"best-effort"方式让Mapper写完本地shuffle数据后再尽量异步推给远端的ESS做聚合。这种方案能受益于本地Shuffle,在容错和AQE的支持上的表现更好(失败会直接Fallback到传统Shuffle)。但Magnet仍会受本地磁盘,数据合并会依赖单独的shuffle服务增加了运营部署成本。
Dataflow
Goolge Cloud Dataflow(2018)实现了Shuffle跟计算的解耦,采用两层存储(内存+磁盘)并依托内部高性能的网络框架支撑起PB级Shuffle。
Cosco
Facebook Cosco(2019)参考早年 yahool! 基于Hadoop的Sailfish的方案,保留了Push Shuffle + Parititon数据聚合的核心方法来改善原生shuffle的随机写磁盘问题。其服务端采用 M-S架构,使用内存两副本做数据可靠性,并使用DFS做数据持久化。Cosco基本上定义了近几年Remote Shuffle的架构形态。
AliYun-RSS
阿里的RSS(EMR Remote Shuffle Service)主要是为了解决其所面临的计算存储分离问题,使得Spark能够适配云原生环境。主要还是参考Cosco和Sailfish进行架构实现,但是其存储会使用本地磁盘,这样相较Cosco性能会有一定的提升。
Aws-shuffle
Aws的shuffle方案比较简单,通过spark可扩展性接口实现自己的shuffle manager。集群启动时可选shuffle 数据写本地磁盘还是写到其对象存储S3上,如果要写本地磁盘那需要考虑磁盘空间是否充足,如果选择写S3则要忍受其低性能。
仔细思考可发现目前shuffle主要三种技术方向:
以Cosco为代表的push+partition merge这种优化原生spark随机写磁盘为顺序写的技术优化,但需要独立部署的shuffle服务。他们主要面对的场景是超大规模集群的超大shuffle量,包括(AliYun-RSS、Google DataFlow、Tencent-Firesorm、京东、Oppo、百度等)国内外大厂的不同方案。特点是单独的shuffle集群+高部署运维成本来支撑起超大规模数据集的shuffle场景。
以Aws-GlueShuffleManager为代表的云上shuffleManager解决方案。特点是支持原生spark或spill to s3这样用户独立配置的可选方案。
以LinkIn-Magnet为代表的支持兼容原生和push + partition merge的方案。特点是同时写本地磁盘和merge partition这样希望能同时利用本地磁盘和推远程这样提升数据可靠性又支持性能提升的方案。
总体方案
对我们来讲本地磁盘在我们看来仍是必须的,除了shuffle溢写外还有broadcat小表、rdd持久化等场景都需要磁盘空间。所以我们的理想方案是能在常规情况下充分利用原生spark 写本地磁盘这样性能相对不错的原生shuffle方案,且在特殊情况下磁盘不足时能自动溢写远程存储服务来提升任务稳定性这样一套具备自适应能力的方案。
总体流程

Spark driver协调map 任务、reduce 任务和shuffle 服务之间的整个shuffle 操作,保存使用到的元数据。
Shuffle map 任务处理其物化 shuffle 数据,进行本地磁盘预判,并在达到本地磁盘阈值时自动切换到写远程存储。
Shuffle reduce 任务执行时首先从driver获取到分区数据文件的位置元数据信息。
Shuffle reduce 任务根据元数据信息从对应exeutor节点拉取mapper数据。
Shuffle map 的executor在判断如果存在远程数据时从远程拉取数据,并以代理的方式融合本地数据返回给reducer。
遇到的挑战
怎么设计一套弹性支持扩展的数据存储方式?
怎么在写数据过程中实现高效的磁盘使用量预判?
通常来讲COS操作速度会慢于本地磁盘,怎么优化读写对象存储速度?
数据拉取时怎么拼合分散在不同存储的数据?
在读取数据过程中存在磁盘不足怎么办?
自适应写入
写入概述
从spark1.6以后shuffle写过程逐渐演化出三种方式ByPass、Sort、Unsafe分别应对(快速、排序和性能优化等)不同shuffle场景。我们以相对简单的ByPass方式为例来看看具体写数据的过程。
Bypass方案适用于处理分区数较少且没有map端排序聚合场景,会先根据分区数创建临时文件,迭代过程中根据分区计算写入对应临时文件。详细的写入过程中会将流经过层层包装才最后落盘,详情可参见下图。

图-1 shuffle数据写入过程流的多层封装
但对于shuffle数据量大时,设想如果一个stage中有M个task,且每个task有N个分区(通常M和N会比较大)那一个stage最终将生成的M*N个shuffle文件。这么多的shuffle数据文件会占用文件描述符给文件系统管理带来压力,另一方面在读取时需要频繁切换扫描的文件。为此在spark 将多个分区文件合并成一个文件,并以每个分区的数据偏移量作为隔离标志生成索引文件。

图-2 shuffle数据写入由每分区一个文件转向合并分区文件
在实际实现时也会有很多技术优化点,比如,分区数据文件合并过程中默认会优先使用文件系统缓存降低性能消耗,相比流间循环copy方式会更高效。
对原生spark写入过程有了了解后,接下来看看怎么自适应的写入到远程存储。我们的主要思路是在写入迭代过程间歇性的检查磁盘使用量,当达到阈值后便开始写远程,同样也是先写临时文件,然后进行合并。
弹性数据结构
为避免本地磁盘用尽,我们需要设计弹性的数据结构以满足本地磁盘不足时切换到远程COS存储。原生spark shuffle 数据结构由索引和对应的数据文件构成,索引文件中一个一个的值指示实际文件中数据分区的偏移量(图-1)。

图-3 shuffle 数据有索引和分区数据构成
首先直观的想法肯定是能支持分层存储的能力,即当本地磁盘存储空间不足时便开始切换到写远程COS存储。这样的处理方式能满足小shuffle数据量下完全使用本地磁盘,当面对大shuffle 或者数据倾斜场景能主动使用远程COS存储(解决任务稳定性)。另一个要考虑的问题是怎么在读取数据时方便快速的判断存储在了哪些层。兼顾扩展性和简单性的原则下我们选取了以下方案:

图-4 可扩展的弹性数据结构由本地索引和远程数据构成
本地磁盘仍会使用原生索引+数据文件的存储结构
对于需要存储到远程的Shuffle数据其数据文件写到远程
将远程的索引文件保存在本地磁盘
这样可以快速的通过判断本地索引文件来确定shuffle 数据的具体位置
使用量预判
根据上述思考需要在写入shuffle数据的同时检查磁盘使用量,当达到设定的阈值就改变写入方式使用远程存储写入。常用的检查使用量的方式是使用oshi调用shell命令,但根据测试其性能不是很理想(千次执行耗时7.9S)。直到我们了解到可以通过JNI方式直接调用底层操作系统函数。其在FileChannel JVM实现如下,在ifelse判断中我们可以看到在类unix系统下非macosx系统情况会调用Linux的statvfs64函数--返回挂载文件系统的统计信息。此命令据我们测试性能颇为高效,每百万次执行仅耗时3.7S(性能相差三个数量级),满足我们需求。
JNIEXPORT jlong JNICALLJava_java_io_UnixFileSystem_getSpace(JNIEnv *env, jobject this,
jobject file, jint t){
jlong rv = 0L;
WITH_FIELD_PLATFORM_STRING(env, file, ids.path, path) {#ifdef MACOSX
struct statfs fsstat;#else
struct statvfs64 fsstat;
int res;#endif
memset(&fsstat, 0, sizeof(fsstat));#ifdef MACOSX
if (statfs(path, &fsstat) == 0) {
switch(t) {
// omitted
}
}#else
RESTARTABLE(statvfs64(path, &fsstat), res);
if (res == 0) {
switch(t) {
// omitted
}
}#endif
} END_PLATFORM_STRING(env, path);
return rv;}
// statvfs64
The function statvfs() returns information about a mounted filesystem. path is the pathname of any file within the mounted filesystem. buf is a pointer to a statvfs structure defined approximately。临时文件优化
要注意的是分区临时文件我们先写本地,只在最终合并时将数据写入远程。相比shuffle数据,分区临时文件的生命周期很短,在合并完成后将会被删除,它不会长久占用磁盘空间。另一方面如果我们考虑对磁盘使用的极限限制,直接写远程然后在合并时从远程拉取,虽然限制了磁盘增量但这将会是一个非常耗时的操作,权衡来看暂时没有这个必要。

图-5 先写临时文件,再合并到远程存储
这里磁盘预判时使用阈值的预留需要考虑一下几点:broadcast占用;rdd持久化;和这里的分区临时文件或spil临时文件(临时文件在任务完成后将被删除)
COS使用优化
在来讲这部分之前先大概了解下COS对象存储和我们平常使用的ext3、nfs、hdfs等文件系统的一些区别。首先COS并不是一个文件系统,它的数据组织方式也不是以树状结构存储,而是以hash映射方式寻找文件。
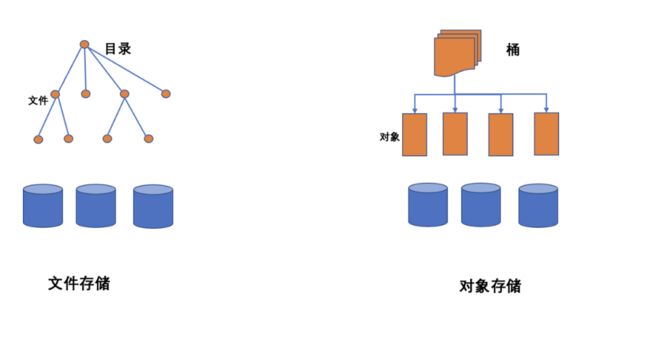
图-6 文件存储对象存储对比
那这就导致了它并不像hdfs或者ext3这样可以快速的进行rename操作,它所提供的rename操作通常是变通的使用copy+delete方式实现。这就导致其操作性能会比较差。原生spark最终的shuffle数据生成需要通过rename实现最终数据的可见性,在这里使用原生数据处理方式就不太合适。
同时COS受限于元数据管理的单进程限制通常QPS不会开很高,实际使用中list等操作多了就会被限流。在hadoop-cos的实现中在创建文件、检查文件状态等hdfs协议中大多需要调用list命令,所以在实际使用远程对象存储是也会尽量避免此类操作。
在我们的实现中,相比原生合并数据文件和索引过程,在COS上我们会直接写到最终的数据文件,再通过本地磁盘索引文件控制其可见性。
自适应拉取
数据拉取概述
spark原生数据拉取通过reducer询问driver获取对应元数据和位置信息,再请求相应的executor由块管理器(BlockManager)拿到数据传给reducer。通常会根据数据所处位置分三种情况:
reducer和mapper属于同一executor,可以根据块管理器获取的对应文件并创建流进行计算处理
reducer和mapper属于同一node上不同executor,是通过executor间通信获取到物理文件路径也可获得文件数据
reducer和mapper位于不同node上,需要通过网络通信来获取对应数据
同时对应上边提到的不同情况,数据视图提供了不同方式来创建数据流:
通过流的方式读取数据
通过nio方式读取数据
通过netty进行网络传输
零拷贝封装
如果不属于同一台机器那原生spark对于通过基于netty网络框架的传输方案进行数据传输,这里在其传输实现方案中就会涉及到零拷贝。由于通常传输过程是数据需要先从磁盘读取然后传给操作系统内核空间的页缓存,在用户进程操作时从内核空间copy到用户空间,接着进行网络传输需要再从用户空间传输到内核态Socket缓冲区,最后发送由Socket缓冲区传输给网络设备。整个过程需要经过四次拷贝四次上下文切换。

图-7 常用传输过程于零拷贝
而零拷贝思想则不需要cpu全程参与操作,仅仅起到管理作用。能显著提升了性能,关于零拷贝的具体实现方式有很多,例如sendfile、mmap、direct io想详细了解的同学可异步参考文档。
这里对于我们的问题即要复用这种方式传输本地数据保证性能,又要能兼容的传输远程对应分区的数据。为此我们重新对spark的通过netty传输shuffle数据方式进行改写。传输时根据position判断,属于本地磁盘数据则需要先利用自身zero-copy实现方式完本地数据的传输。如果包含远程数据则要考虑怎么进行数据的拼接和融合了。
融合的流
我们知道spark使用netty进行通信和数据传输。实际过程是读取数据后进行编码并缓存,超过一定量会以网络包的方式发送。接收端接受数据后在进行解码恢复成原有样子,具体编解码实现和消息交互机制是spark内实现的。这里对于我们的实现由于涉及本地和远程数据,需要考虑怎么为netty框架拼接成有序的流。具体实现过程用到流合并的技术拼装本地和远端数据,默认优先读取本地文件当本地数据读取完后会接着从远程数据并将读取到的数据给到netty进行传输。

图-8 流的拼接合并
读取时的限制
上述我们提到写本地文件时会遇到磁盘空间不足,需要注意的是在读取过程中如果我们的算子中包含排序和聚合其实也会涉及落盘过程。那我们是怎么解决这个问题的呢?
spark中排序shuffle一般会使用到ExternalSorter等实现类。其实现原理是优先在内存排序(内存空间由TaskMemoryManager管理),当内存不足以支撑数据量是会将排好序的数据spill到本地磁盘上,而后通过优先队列的实现进行外部排序达到最终有序。这里我们的考虑优化点是当达到一定阈值时可以不再依赖本地磁盘转而依靠对象存储来暂存我们的spill数据,由此来降低磁盘压力提升稳定性。具体实现方案可参考图11

图-9 reducer拉取过程中磁盘不够
数据拉取优化
spark中利用netty构建了其网络传输通道,当前版本也正是通过以map executor作为代理节点的方式来拉取数据。但对于远程数据能不能不再依赖netty再做一边二次传输呢?这样理论上他将进一步带来以下好处。
减少集群间网络负载压力、降低出错风险
避免大分区数据传输异常
没有netty二次传输,进一步提升性能
远程数据拉取优化解耦,实现更灵活。
可以通过提升并发量读取数据过程

图-10 从mapper端只拉取远程数据的元数据
数据清理
在目前spark实现中shuffle数据的清理分两个阶段:RDD级别,即在rdd生命周期结束后通过gc触发其数据清理的事件;集群级别,在尝试关闭集群时其配置的shutdown_hook会发出消息,尝试先删除每个executor中的shuffle数据在关闭executor。
在实际执行spark sql过程中常常会发现shuffle数据并没有随着sql stage执行而被清理,而是随着任务执行shuffle数据量持续增加。我们发现RDD级别对shuffle数据的清理是通过创建ShuffleDependency依赖并将其注册到ContextCleanr的弱引用中,当对象生命周期结束会被push到弱引用队列由此触发shuffle的清理过程。但由于transform算子生成的RDD最终都会转换成一层层嵌套的、具有依赖关系的RDD,所以只有在整个RDD链执行完后并且触发gc时才会开始其清理shuffle的执行。那能不能随着stage的执行那些不再被使用到的Stage数据能被及时的清理呢?
stage级别清理
在我们的实现是以可配置的方式清理掉不再被依赖的stage中shuffle数据,这样一方面可以进一步降低存储成本缓解磁盘压力,另一方面减少spill到cos的数据量以提升性能。具体实现:如下图是一个sql中job的stage依赖关系图,依赖方向由下向上。我们看到从左到右执行状态图变化时,即stage4执行完后,stage2再没有被其他stage依赖。那此时stage2的数据便可清理以释放空间。
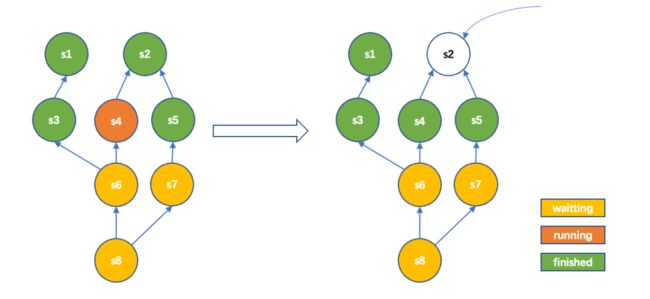
图-11 stage级别shuffle清理
其他性能优化
当然除了以上所述设计的方案,还设计多种优化手段限于篇幅暂不进行详细讲解。简单概要总结如下,如果感兴趣的同学们想深入了解欢迎私下交流。
缓存索引:索引文件包含多个分区的数据且数据量非常小,每次读分区是都需要加载读取。我们实现时可配置缓存索引文件到内存避免频繁读取索引文件以提升效率。
文件复用:由于mapper中分区数据最后都合并到一个文件中,在打开文件后可保存其文件描述符以避免频繁打开关闭文件。同时可使用内存映射技术快速定位到读取的数据段。
sorter spill to remote: 我们发现spark中MemoryConsumer进行sorter等操作也受磁盘量限制,同样我们对其spill也做了改造。那至此基于spark框架的比较重要的临时存储我们基本上都做了优化以适应存算分离架构并提升稳定性。
收益&效果
存储成本 目前实际运营中我们集群节点的磁盘挂载量进一步降低,一般规模集群每节点只要50G、大规模集群也不超200G。同时也没有额外的部署运营成本。
稳定性,对于shuffle数据量剧增或数据倾斜场景任务执行的稳定性不会再因本地磁盘限制而失败。
性能,典型tpcds场景性能测试场景如下:
TPCDS 测试 | 1T数据大小 | 集群规模 5C/19G * 11 | shuffle数据量94.84G
完全使用磁盘耗时 8min40s
使用部分磁盘+部分COS 耗时 10min30s (52.5 DISK、42.34G COS)。目前主要性能差距在数据拉取过程中,将来可进一步优化未来方向
当前阶段无论是本地存储还是分布式文件系统或对象存储对临时文件提出的要求其实都存在一定先局限性。
本地存储:分布式计算框架的本地写会造成随机io导致性能不佳,且集群节点间的数据传输也会导致比较高的带宽压力。
持久存储如HDFS、对象存储:临时文件通常生命周期很短且对数据可靠性的要求不如最终持久化结果数据那么高。而对临时文件来讲传统文件系统的多备份持久化实际造成了性能损失和不必要的存储成本负担(其数据持久性所保证的n个9即是临时数据所要付出的时间成本和存储成本)。且其保守的弹性扩缩逻辑也不利于优化成本。
我们知道软件系统的发展基本上是在不断分层、解耦中进行演进。而对于云上数据系统运行时所需要的shuffle、spill和缓存等这类临时数据当前的处理方法基本上是选择本地磁盘或者远程持久存储。实际上这类数据特点是需要高吞吐、高性能、低成本同时对数据可靠性的要求并不是那么高(基本都可以通过失败重试来恢复),适合此类数据存储的系统的必要性逐渐显现。目前根据snowflake的论文可以看到他们也在探索阶段、同时也有一些对临时文件的早期项目例如斯坦福的Pocket。相信未来几年一定会出现适合商用的临时文件系统。目前我们在这方面也有了一些思考和专利的布局,如果你很感兴趣可以考虑加入我们来一起fight it!

在分布式弹性临时文件存储系统中我们会聚焦以解决以下几个问题:
具备标准的接口。从而和计算框架解耦,作为临时存储系统使计算框架不用再考虑本地存储的相关限制。
具备灵活的扩缩策略。能够快速扩缩扩容满足高吞吐量的需求,能够有效的缩容使系统以低成本运行。
利用多层存储。能够综合使用多种现代存储资源DRAM、NVME、SSD、HDD,综合考虑资源计费成本和时间成本给出最合适的存储方案。
参考
Cosco: An Efficient Facebook-Scale Shuffle Service
Sailfish: A Framework For Large Scale Data Processing
How Distributed Shuffle improves scalability and performance in Cloud Dataflow pipelines
Magnet: Push-based Shuffle Service for Large-scale Data Processing
AWS Glue Spark shuffle manager with Amazon S3
https://tldp.org/HOWTO/SCSI-Generic-HOWTO/mmapio.html
https://en.wikipedia.org/wiki/Zero-copy
http://dockone.io/article/2434459
https://www.usenix.org/system/files/osdi18-klimovic.pdf
https://www.usenix.org/system/files/nsdi20-paper-vuppalapati.pdf
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/gfs-sosp2003.pdf
推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击“阅读原文”,了解相关产品最新动态
↓↓↓