彻底搞懂Spring的循环依赖
前言:
Spring在我们实际开发过程中真的太重要了,当你在公司做架构升级、沉淀工具等都会多多少少用到Spring,本人也一样,在研习了好几遍Spring源码之后,产生一系列的问题, 也从网上翻阅了各种资料,最近说服了自己,觉得还是得整理一下,有兴趣的朋友可以一起讨论沟通一波。回到标题,我们要知道以下几点:
(1)什么是循环依赖?
(2)Spring如何解决循环依赖
(3)只用一级缓存会存在什么问题
(4)只用二级缓存会存在什么问题
(5)Spring 为什么不用二级缓存来解决循环依赖问题
什么是循环依赖
很直接的一张图:
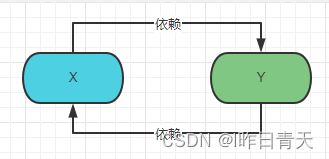
循环依赖分为三种:构造器注入方式的循环依赖、setter注入方式的循环、属性注入方式的循环依赖;
其中构造器注入方式造成的循环依赖Spring无法解决,这一点可以通过调试Spring源码得到结论。
(ps:X和Y都是构造器注入彼此,严谨一点)
Spring如何处理的循环依赖
Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。
当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束,上源码:
第一次创建A时

截图处代码不成立,直接返回,进行A的创建过程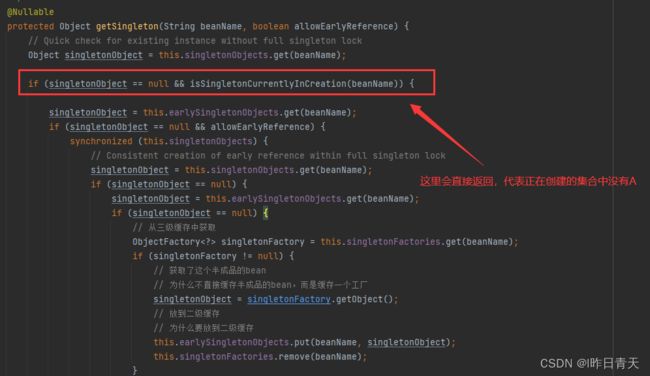
真正触发去创建A的地方
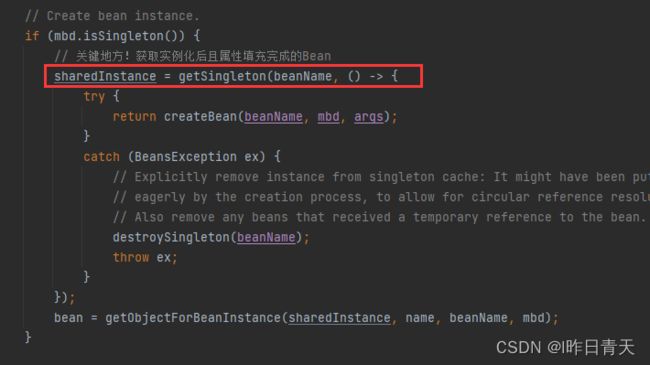
这里将A加入正在创建的一个集合,代表A正在创建当中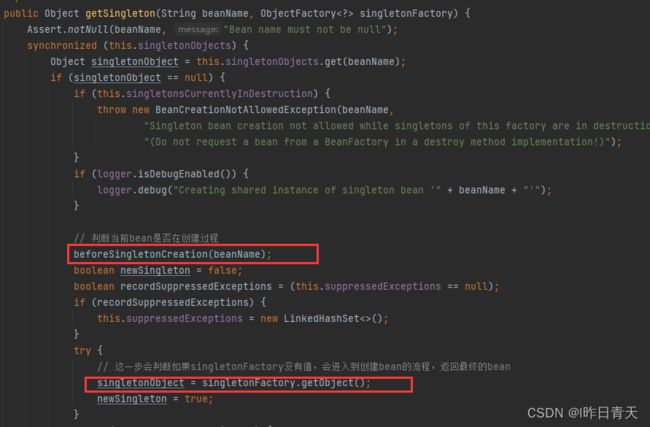
暴露早期A的半成品对象,如果A被AOP代理,那就是暴露A的代理对象,将改对象的创建工厂添加至三级缓存中,那么什么会去用呢?
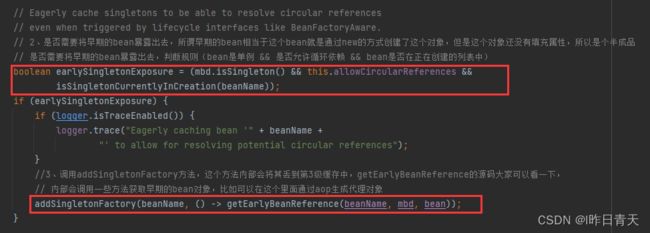 进行属性注入,在这里发现需要注入B,然后进行B的创建
进行属性注入,在这里发现需要注入B,然后进行B的创建
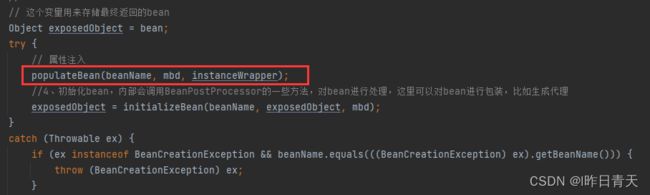
B的创建同A一样,此时就不截图了。
然后在进行B的属性注入时,发现需要注入A,再次回到A的创建,回到第一次创建的那个地方:
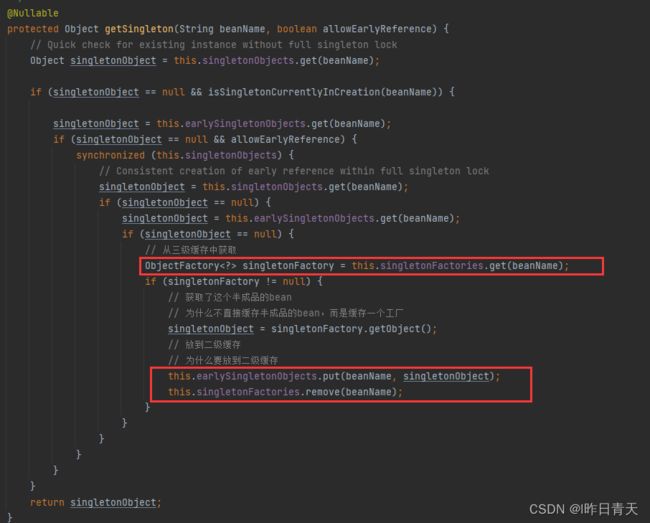
从三级缓存中获取A的半成品对象,添加至二级缓存中。
此时将这个半成品对象给到B,让B完成初始化,然后再次回到A的创建过程,上图中触发createBean的那个地方:
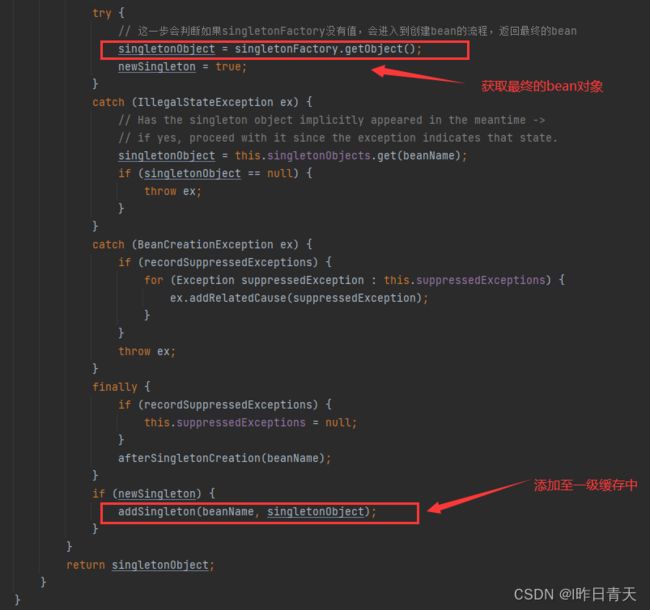
生成最终的A对象,放入一级缓存中。
只用一级缓存会存在什么问题
只使用一级缓存,也就是将所有的 bean 的实例都放在同一个 Map 容器中。其中就包括已经初始化好的 bean 和未初始化好的 bean。
已经初始化好的 bean: 指经过了 bean 创建的三个阶段之后的 bean 对象
未初始化好的 bean : 指经过了 bean 创建的第一个阶段,只将 bean 实例创建出来了
bean 的创建过程分三个阶段:
1 创建实例 createBeanInstance
2 填充依赖 populateBean
3 initializeBean
假设 bean 是需要 AOP 增强的,那么最终放到缓存中的应该是一个代理 bean。而代理 bean 的产生是在 initializeBean(第三阶段) 的时候。所以,我们推导出:如果只使用一级缓存的话,缓存的插入应该放在 initializeBean 之后。
如果在 initializeBean 的时候记录缓存,那么碰到循环依赖的情况,需要在 populateBean(第二阶段) 的时候再去注入循环依赖的 bean,此时,缓存中是没有循环依赖的 bean 的,就会导致 bean 重新创建实例。
这样显然是不行的。
反例:循环依赖场景:A–>B–>A
A 在 createBeanInstance 时,创建了 bean 实例,接着 populateBean 会填充依赖的 bean B,从而触发 B 的加载;
B 在 populateBean 时,发现要注入依赖的 bean A,先从缓存中获取 bean A,获取不到,就会重新创建 bean A。
这样违背了 bean 的单例性,所以只使用一级缓存是不行的。
理论上使用一级缓存是可以解决普通场景下的循环依赖的,因为对于普通场景,从始至终 bean 的对象引用始终都是不变的。
但是,如果被循环依赖的 bean 是一个 AOP 增强的代理 bean 的话,bean 的原始引用和最终产生的 AOP 增强 bean 的引用是不一样的,一级缓存就搞不定了。
疑问:如果在 createBeanInstance 之后就生成代理对象放入一级缓存呢?
我们或许会有疑问,如果不按 spring 原本的设计,我们在 bean 创建的第一步createBeanInstance 之后就判断是否生成代理对象,并将要暴露的对象放入一级缓存是不是就可以解决所有场景的循环依赖问题呢?
分析:
再利用上面的反例来分析一遍,放入一级缓存的 bean 与暴露到容器中的 bean (不管是否有代理)始终是同一个 bean,看似好像是没有问题的,好像是可以解决循环依赖的问题。
但是这里忽略了一个问题:bean 创建的第二步中 populateBean 的底层实现是将原始 bean 对象包装成 BeanWrapper,然后通过 BeanWrapper 利用反射设置值的。
如果在 populateBean 之前生成的是一个代理对象的话,就带来了另外一个问题 :jdk proxy 产生的代理对象是实现的目标类的接口,jdk proxy 的代理类通过 BeanWrapper 去利用反射设置值时会因为找不到相应的属性或者方法而报错。
所以,如果在 createBeanInstance 之后就生成代理对象放入一级缓存,也是行不通的。
只用二级缓存会存在什么问题
使用二级缓存也可以分为两种:使用singletonObjects和earlySingletonObjects,或者使用singletonObjects和singletonFactories。
①使用singletonObjects和earlySingletonObjects
成品放在singletonObjects中,半成品放在earlySingletonObjects中
流程可以这样走:实例化A ->将半成品的A放入earlySingletonObjects中 ->填充A的属性时发现取不到B->实例化B->将半成品的B放入earlySingletonObjects中->从earlySingletonObjects中取出A填充B的属性->将成品B放入singletonObjects,并从earlySingletonObjects中删除B->将B填充到A的属性中->将成品A放入singletonObjects并删除earlySingletonObjects。
这样的流程是线程安全的,不过如果A上加个切面(AOP),这种做法就没法满足需求了,因为earlySingletonObjects中存放的都是原始对象,而我们需要注入的其实是A的代理对象。
②使用singletonObjects和singletonFactories
成品放在singletonObjects中,半成品通过singletonFactories来获取
流程是这样的:实例化A ->创建A的对象工厂并放入singletonFactories中 ->填充A的属性时发现取不到B->实例化B->创建B的对象工厂并放入singletonFactories中->从singletonFactories中获取A的对象工厂并获取A填充到B中->将成品B放入singletonObjects,并从singletonFactories中删除B的对象工厂->将B填充到A的属性中->将成品A放入singletonObjects并删除A的对象工厂。
同样,这样的流程也适用于普通的IOC已经有并发的场景,但如果A上加个切面(AOP)的话,这种情况也无法满足需求,因为当A和多个对象发生循环依赖时,其他对象拿到的都是A的不同的代理对象。
疑问:如果在createBeanInstance之后就生成代理对象放入二级缓存呢?
我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候当A完成实例化后还是会进入下面这段代码:
// A是单例的,mbd.isSingleton()条件满足
// allowCircularReferences:这个变量代表是否允许循环依赖,默认是开启的,条件也满足
// isSingletonCurrentlyInCreation:正在在创建A,也满足
boolean earlySingletonExposure = (mbd.isSingleton() &&this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
// 所以earlySingletonExposure=true
// 还是会进入到这段代码中
if(earlySingletonExposure) {
// 还是会通过三级缓存提前暴露一个工厂对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}看到了吧,即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
Spring 为什么不用二级缓存来解决循环依赖问题?
Spring 原本的设计是,bean 的创建过程分三个阶段:
1 创建实例 createBeanInstance – 创建出 bean 的原始对象
2 填充依赖 populateBean – 利用反射,使用 BeanWrapper 来设置属性值
3 initializeBean – 执行 bean 创建后的处理,包括 AOP 对象的产生
在没有循环依赖的场景下:第 1,2 步都是 bean 的原始对象,第 3 步 initializeBean 时,才会生成 AOP 代理对象。
循环依赖属于一个特殊的场景,如果在第 3 步 initializeBean 时才去生成 AOP 代理 bean 的话,那么在第 2 步 populateBean 注入循环依赖 bean 时就拿不到 AOP 代理 bean 进行注入。
所以,循环依赖打破了 AOP 代理 bean 生成的时机,需要在 populateBean 之前就生成 AOP 代理 bean。
而且,生成 AOP 代理需要执行 BeanPostProcessor,而 Spring 原本的设计是在第 3 步 initializeBean 时才去调用 BeanPostProcessor 的。
并不是每个 bean 都需要进行这样的处理,所以, Spring 没有直接在 createBeanInstance 之后直接生成 bean 的早期引用,而是将 bean 的原始对象包装成了一个 ObjectFactory 放到了三级缓存 Map
当需要用到 bean 的早期引用的时候,才通过三级缓存 Map
如果只使用二级缓存来解决循环依赖的话,那么每个 bean 的创建流程中都需要插入一个流程——创建 bean 的早期引用放入二级缓存。
其实,在真实的开发中,绝大部分的情况下都不涉及到循环依赖,而且 createBeanInstance --> populateBean --> initializeBean 这个流程也更加符合常理。
所以,猜想 Spring 不用二级缓存来解决循环依赖问题,是为了保证处理时清晰明了,bean 的创建就是三个阶段: createBeanInstance --> populateBean --> initializeBean
只有碰到 AOP 代理 bean 被循环依赖时的场景,才去特殊处理,提前生成 AOP 代理 bean。
总结:
如果没有循环依赖的情况的话,一级缓存就可以搞定所有的情况,只需要在 bean 完全初始化好之后将其放入一级缓存即可。
但是一级缓存解决不了循环依赖的情况,所以,Spring 使用三级缓存来解决了循环依赖问题。如果使用二级缓存的话,理论上是可行的,但是 Spring 选择了三级缓存来实现,让 bean 的创建流程更加符合常理,更加清晰明了。