已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、科技新闻速递,欢迎大家关注!!!
FightingCV交流群里每日会发送论文解析,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码学习:https://github.com/xmu-xiaoma...
【写在前面】
在本文中,作者提出了一个新的问题,称为视听分割(AVS),其目标是输出在图像帧产生声音时的对象的像素级map。为了促进这项研究,作者构建了第一个视听分割基准(AVSBench),为音频视频中的发声对象提供像素级注释。并使用该基准研究了两种设置:1) 单声源半监督音视频分割;2) 具有多个声源的全监督视听分割。为了解决AVS问题,作者提出了一种新方法,该方法使用时间像素级视听交互模块注入音频语义,作为视觉分割过程的指导。作者还设计了一种正则化损失,以鼓励在训练期间进行视听映射。在AVSBench上进行的定量和定性实验将本文的方法与相关任务中的几种现有方法进行了比较,表明该方法有望在音频和像素视觉语义之间建立桥梁。
1. 论文和代码地址

Audio−Visual Segmentation
论文地址:https://arxiv.org/pdf/2207.05042.pdf
代码地址:https://github.com/OpenNLPLab/AVSBench
2. Motivation
人类不仅可以根据物体的视觉外观,还可以根据物体发出的声音对其进行分类。例如,当听到狗吠声或警笛声时,人类知道声音分别来自狗或救护车。这些观察结果证实了音频和视频信息是相辅相成的。
到目前为止,研究人员已经从一些简化的场景中研究了这个问题。一些研究人员已经研究了视听对应(AVC)问题,其目的是确定音频信号和视觉图片是否描述相同的场景。AVC通常给予两个信号同时出现和发生的情况。一些工作研究了视听事件定位(AVEL),它将视频片段分类为预定义的事件标签。类似地,一些人也探索了视听视频解析(AVVP),其目标是将视频划分为几个事件,并将其分类为可听、可见或两者。由于缺乏像素级标注,所有这些场景都局限于帧/时间级,因此将问题降低到音频图像分类。
一个相关的问题为声源定位(SSL),旨在定位与声音对应的帧内的视觉区域。与AVC/AVEL/AVVP相比,SSL问题寻求patch级场景理解,即结果通常由热力图表示,热力图通过可视化音频特征和视觉特征图的相似矩阵或类激活映射(CAM)获得,而不考虑发声对象的实际形状。

在本文中,作者提出了像素级视听分割(AVS)问题,该问题要求网络密集预测每个像素是否对应于给定的音频,从而生成发声对象的掩码。上图说明了AVS和SSL之间的差异。AVS任务比以前的任务更具挑战性,因为它要求网络不仅定位可听帧,而且描绘发声物体的形状。
为了促进这项研究,作者提出了AVSBench,这是第一个像素级视听分割基准,为探测对象提供ground truth标签。根据视频中探测对象的数量(单源或多源),作者将AVSBench数据集分为两个子集。使用AVSBench,作者研究了两种视听分割设置:1) 半监督单声源分割(S4)和2)全监督多声源分割(MS3)。对于这两种设置,目标都是从产生声音的视觉帧中分割对象。作者从AVSBench上的相关任务出发测试了六种方法,提供了一种新的AVS方法作为强baseline。后者利用标准编码器-解码器架构,但具有新的时间像素级视听交互(TPAVI)模块,以更好地引入音频语义来指导视觉分割。作者还提出了一种损失函数来利用视听信号的相关性,从而进一步提高分割性能。
本文的贡献可以总结如下:
1)提出了AVS作为一种细粒度的视听场景理解任务,并提出了AVSBench,一种为AVS提供像素级注释的新数据集;
2) 为AVS设计了一个端到端框架,该框架采用新的TPAVI模块来编码时间像素级的视听交互,并采用正则化损耗来进一步利用视听相关性;
3)作者进行了大量实验,以验证将音频信号用于视觉分割的好处。作者还比较了几种相关方法,以表明本文提出的方法在这两种情况下的优越性。
3. 数据集
3.1 Dataset Statistics


AVSBench设计用于像素级的视听分割。作者使用VGGSound中介绍的技术收集视频,以确保音频和视频片段符合预期语义。AVSBench包含两个子集单源和多源,具体取决于探测对象的数量。所有视频都是从YouTube上下载的,并带有知识共享许可证,每段视频被缩短到5秒。单源子集包含23个类别的4932个视频,涵盖来自人类、动物、车辆和乐器的声音。在上图中,作者显示了每个类别的类别名称和视频编号。为了收集多源子集,作者选择了包含多个发声对象的视频,例如,婴儿笑、男人说话、然后女人唱歌的视频。具体来说,作者从单个音源子集中随机选择两到三个类别名称作为关键字来搜索在线视频,然后手动过滤视频,以确保1)每个视频都有多个音源,2)发声对象在帧中可见,以及3)没有欺骗性声音。总的来说,这一过程在6000多个候选视频中为多源子集生成了424个视频。两个子集的训练/验证/测试分割百分比的比率设置为70/15/15,如上表所示。下图显示了几个视频示例,其中红色文本表示发声对象的名称。

此外,作者将AVSBench与下表中其他流行的视听基准进行了比较。AVE数据集包含4143个视频,涵盖28个事件类别。LLP数据集由11849个YouTube视频片段组成,跨越25个类别,从AudioSet收集。AVE和LLP数据集都通过视听事件边界在帧级别进行标记。Flickr SoundNet数据集和VGGSS数据集用于声源定位(SSL),通过边界框在patch级别进行标记。

3.2 Annotation
作者将每个5秒钟的视频分成5个相等的1秒片段,并为每个片段的最后一帧提供手动像素级标注。对于该采样帧,ground truth标签是一个二进制掩码,根据相应时间的音频指示检测对象的像素。例如,在多源子集中,即使跳舞的人在空间上表现出剧烈的运动,只要没有发出声音,就不会对其进行标记。在物体不发声的片段中,不应mask物体,例如上图b最后一行前两个片段中的钢琴。类似地,当多个物体发出声音时,所有发出的物体都被标注,例如,上图b中第一行的吉他和四弦琴。此外,当视频中的发声对象动态变化时,难度进一步增加,例如,上图b中的第二、第三和第四行。目前,对于大型对象,作者仅标注其最具代表性的部分。例如,给钢琴的键盘贴上标签是因为它足够容易识别,而钢琴的橱柜部分往往变化太大。
基于单信源和多源子集之间的不同困难,作者使用了两种类型的标记策略。对于单信源训练分割中的视频,仅对第一个采样帧进行标注(假设来自单次标注的信息足够,因为单信源子集随时间具有单个且一致的发声对象)。
3.3 Two Benchmark Settings
作者为AVSBench数据集提供了两个基准设置:半监督单声源分割(S4)和全监督多声源分割(MS3)。为了便于表达,作者将视频序列表示为S,它由T个不重叠但连续的片段$\left\{S_{t}^{v}, S_{t}^{a}\right\}_{t=1}^{T}$组成,其中$S^{v}$和$S^{a}$是视觉和音频分量,T=5。实际上,作者在每秒钟结束时提取视频帧。
半监督S4对应于单信源子集。它被称为半监督,因为在训练期间只给出了部分ground truth值(即视频的第一个采样帧),但所有视频帧都需要在评估期间进行预测。作者将像素级别的标签表示为$\boldsymbol{Y}_{t=1}^{s} \in \mathbb{R}^{H \times W}$,其中H和W分别是帧高度和宽度。$Y_{t=1}^{s}$是一个二进制矩阵,其中1表示发声对象,而0对应于背景或无声对象。
全监督MS3处理多源子集,其中每个视频的所有五个采样帧的标签都可用于训练。ground truth表示为$\left\{\boldsymbol{Y}_{t}^{m}\right\}_{t=1}^{T}$,其中$\boldsymbol{Y}_{t}^{m} \in \mathbb{R}^{H \times W}$是第t个视频片段的二进制标签。
这两种设置的目标都是通过利用音频和视觉线索,即$S^{a}$和$\boldsymbol{S}^{v}$,正确分割每个视频片段的发声对象。通常,期望$S^{a}$指示目标对象,而$\boldsymbol{S}^{v}$为细粒度分割提供信息。预测表示为$\left\{\boldsymbol{M}_{t}\right\}_{t=1}^{T}, \boldsymbol{M}_{t} \in \mathbb{R}^{H} H \times W$。半监督和全监督设置均以类别无关的方式进行,因此模型适用于一般视频。
4. Baseline

作者提出了一种新的用于像素级视听分割(AVS)任务的baseline方法,如上图所示。作者在半监督和完全监督的环境中使用相同的框架。根据语义分割方法的惯例,本文的方法采用了编码器-解码器架构。
The Encoder
作者独立提取音频和视频特征。给定一个音频片段,作者首先通过短时傅立叶变换将其处理为频谱图,然后将其发送到卷积神经网络VGGish。作者使用在AudioSet上预训练的权重来提取音频特征$A \in \mathbb{R}^{T \times d}$,其中d=128是特征尺寸。对于视频帧$S^{v}$,作者使用流行的基于卷积或基于视觉Transformer的主干提取视觉特征。作者在实验中尝试了这两种选择,它们显示出相似的性能趋势。这些主干在编码过程中产生分层视觉特征图,如上图所示。将特征表示为$\bar{F}_{i} \in \mathbb{R}^{T \times h_{i} \times w_{i} \times C_{i}}$,其中$\left(h_{i}, w_{i}\right)=(H, W) / 2^{i+1}, i=1, \ldots, n$。在所有实验中,level数设置为n=4。
Cross-Modal Fusion
作者使用空洞空间金字塔池(ASPP)模块进一步后处理视觉特征$\boldsymbol{F}_{i}$到$V_{i} \in \mathbb{R}^{T \times h_{i} \times w_{i} \times C}$,其中C=256。这些模块采用多个具有不同rate的并行滤波器,因此有助于识别具有不同感受野的视觉对象,例如不同大小的运动对象。然后,作者考虑引入音频信息来构建视听映射,以帮助识别发声对象。这对于有多个动态声源的MS3设置尤其重要。作者的直觉是,虽然声源的听觉和视觉信号可能不会同时出现,但它们通常存在于多个视频帧中。因此,聚合整个视频的音频和视觉信号是有意义的。受非局部块编码时空关系的启发,作者采用了类似的模块来编码时间像素级视听交互(TPAVI)。如上图所示,整个视频的当前视觉特征图V和音频特征A被发送到TPAVI模块。具体来说,首先通过线性层将音频特征A转换为与视觉特征$V_{i}$具有相同维度的特征空间。然后在空间上复制$h_{i} w_{i}$次,并将其reshape为与$V_i$相同的大小。将此类处理后的音频特征表示为$\hat{\boldsymbol{A}}$。接下来,期望在整个视频中找到对音频对应物$\hat{\boldsymbol{A}}$具有高响应的视觉特征图$V_i$的像素。

这种视听交互可以通过点积测量,然后在第i阶段更新的特征图$Z_{i}$可以计算为:

其中$\theta, \phi, g$和µ是1×1×1卷积,$N=T \times h_{i} \times w_{i}$是归一化因子,$\alpha_{i}$表示视听相似性,$Z_{i} \in \mathbb{R}^{T \times h_{i} \times w_{i} \times C}$。每个视觉像素通过TPAVI模块与所有音频交互。作者在下图提供了TPAVI中视听注意力的可视化,它显示了与SSL方法预测类似的“外观”,因为它构建了像素到音频的映射。

The Decoder
作者在这项工作中采用了全景FPN的解码器,因为它具有灵活性和有效性。简而言之,在第j级,其中j=2、3、4,来自第$\boldsymbol{Z}_{5-j}$级和上一阶段$\mathbf{Z}_{6-j}$编码器的输出j用于解码过程。然后将解码的特征上采样到下一阶段。解码器的最终输出为$\boldsymbol{M} \in \mathbb{R}^{T \times H \times W}$,由Sigmoid激活。
Objective function
给定预测M和像素级标签Y,作者采用二进制交叉熵(BCE)损失作为主要监督函数。此外,使用额外的正则化项$\mathcal{L}_{\mathrm{AVM}}$来强制进行视听映射。具体来说,作者使用Kullback-Leibler(KL)散度来确保mask的视觉特征与相应的音频特征具有相似的分布。换句话说,如果某些帧的音频特征在特征空间中接近,则相应的发声对象在特征空间中有望接近。总目标函数L可计算如下:
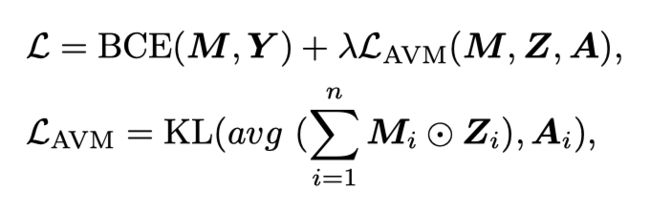
其中λ是平衡权重,⊙ 表示元素乘法,avg表示平均池化运算。在每个阶段,作者通过平均池化对预测$\boldsymbol{M}$到$\boldsymbol{M}_{i}$进行下采样,使其具有与$\boldsymbol{Z}_{i}$相同的形状。向量$\boldsymbol{A}_{i}$是与$\boldsymbol{Z}_{i}$具有相同特征维数的A的线性变换。对于半监督S4设置,作者发现视听正则化损失没有帮助,因此作者在此设置中设置λ=0。
5.实验

上表展示了与相关任务的方法进行比较。

上图展示了在完全监督的MS3设置下,SSL方法和本文的AVS框架的定性示例。

上图展示了在完全监督的MS3设置下,VOS、SOD和本文的AVS方法的定性示例。

AVS任务可以分为两个阶段:第一阶段,使用现成的分割模型,例如COCO数据集上预训练的Mask R-CNN来提取实例分割图。然后,将第一阶段的这些对象图和视觉特征与音频连接起来,并输入到PVT-v2结构中,以预测最终结果。上表展示了本文方法和这些二阶段方法的对比。
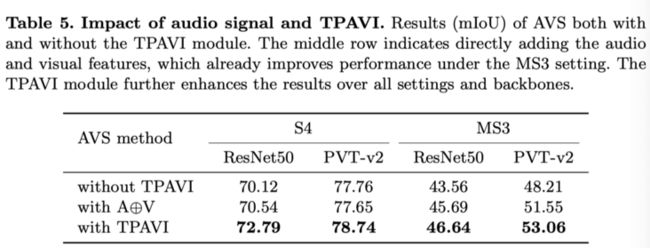
上表展示了声音信号的影响,可以看出本文提出的TPAVI可以有效的提取出声音特征,并促进分割任务。

上图展示了半监督S4设置下的定性结果。
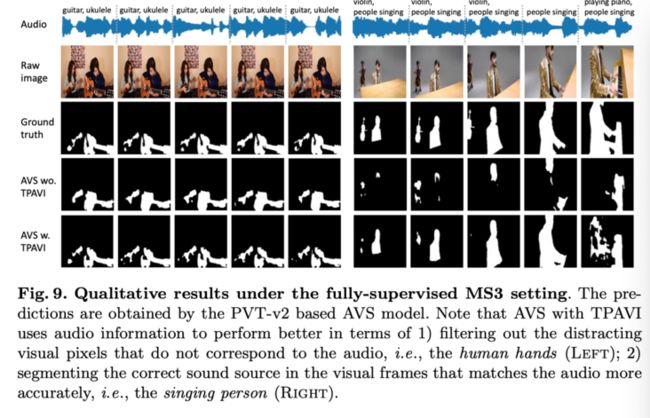
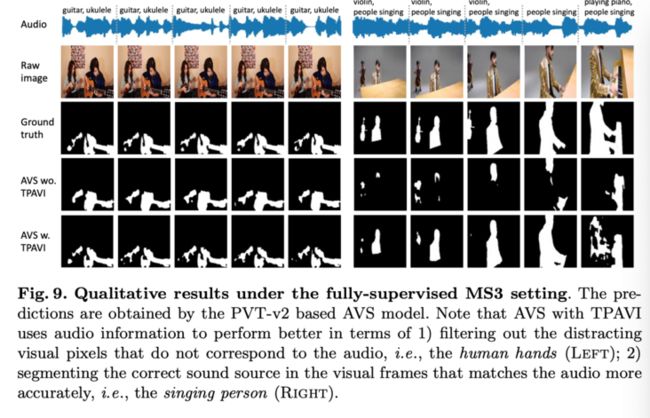
上图展示了全监督MS3设置下的定性结果。
上表研究了$\mathcal{L}_{\mathrm{AVM}}$损失的两种变体的实验结果。

上表展示了在不同阶段进行跨模态融合的实验结果。

上图为在有或没有音频的情况下进行训练时,T-SNE视觉特征的可视化。这些结果来自多源子集的测试分割。作者首先使用主成分分析(PCA)将音频特征划分为K=20个簇。然后,将音频簇标签分配给相应的视觉特征,并进行t-SNE可视化。具有相同颜色的点共享相同的音频簇标签。可以看出,当训练伴随音频信号时(右),视觉特征与音频特征分布呈现更紧密的趋势,即具有相同颜色的点聚集在一起,这表明已经学习了视听相关性。

上图展示了将预训练AVS模型应用于没见过视频的定性示例。
6. 总结
本文提出了一个称为AVS的新任务,该任务旨在为音频视频中的发声对象生成像素级二进制分割掩码。为了促进这一领域的研究,作者收集了第一个视听分割基准(称为AVSBench)。根据检测对象的数量,作者探索了AVS的两种设置:半监督单源(S4)和全监督多源(MS3)。作者提出了一种新的像素级AVS方法作为强baseline,该方法包括一个TPAVI模块,用于对时序视频序列中的像素级视听交互进行编码,以及一个正则化损失,以帮助模型学习视听相关性。作者将本文的方法与AVSBench数据集上相关任务的几种现有最先进方法进行了比较,并进一步证明了本文的方法可以在声音和对象外观之间建立联系。
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、科技新闻速递,欢迎大家关注!!!
FightingCV交流群里每日会发送论文解析,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码学习:https://github.com/xmu-xiaoma...

本文由mdnice多平台发布